
The Box-Jenkins Practical
The Box-Jenkins Practical
You might also like
- Stat 331 Course NotesDocument79 pagesStat 331 Course NotesthemanzamanNo ratings yet
- ARIMADocument8 pagesARIMAgibe bullyNo ratings yet
- Chapter Four 4.0 Data AnalysisDocument6 pagesChapter Four 4.0 Data AnalysisSMART ROBITONo ratings yet
- Covid-19 GraphDocument7 pagesCovid-19 GraphJudeNo ratings yet
- Time-Series, ForecastingDocument12 pagesTime-Series, ForecastingRiska AristiNo ratings yet
- Eview Chương 7Document3 pagesEview Chương 7caotri34342001No ratings yet
- RF ImpedanceDocument7 pagesRF ImpedancesrybsantosNo ratings yet
- IndahDocument4 pagesIndahAndini PratiwiNo ratings yet
- My FileDocument19 pagesMy FileThufail AlghifaryNo ratings yet
- Using Excel'S Rand FunctionDocument239 pagesUsing Excel'S Rand FunctionSyed Ameer Ali ShahNo ratings yet
- Cuadro 1. Isotermas de Adsorción-GAB: #AW % Humedad DireccionDocument18 pagesCuadro 1. Isotermas de Adsorción-GAB: #AW % Humedad DireccionJarise Laban CastilloNo ratings yet
- Cu EstaDocument2 pagesCu EstaNando YarangaNo ratings yet
- Lampiran 2 Hingga Daftar Riwayat HidupDocument12 pagesLampiran 2 Hingga Daftar Riwayat HidupRaja Maulana SidabutarNo ratings yet
- Short Circuit CalculationsDocument28 pagesShort Circuit CalculationsSchaum001No ratings yet
- Tugas 3 EKOMET Muh RAFIDocument5 pagesTugas 3 EKOMET Muh RAFIdaffa luthfianNo ratings yet
- Business Forecasting Assignment: Name: Mansi Sharma SAP Id: 80011220277 Roll No: A016 Group: 10Document6 pagesBusiness Forecasting Assignment: Name: Mansi Sharma SAP Id: 80011220277 Roll No: A016 Group: 10MANSI SHARMANo ratings yet
- Inflasi ARIMA ModelDocument7 pagesInflasi ARIMA ModelAnto TomodachiRent SusiloNo ratings yet
- MLR-handson - Jupyter NotebookDocument5 pagesMLR-handson - Jupyter NotebookAnzal MalikNo ratings yet
- Case: Winter Park Hotel (Current System) : Queuing Model M/M/s (Exponential Service Times)Document35 pagesCase: Winter Park Hotel (Current System) : Queuing Model M/M/s (Exponential Service Times)Gajendra SinghNo ratings yet
- VLE - Paralel B - Sesi B1 - Grup FDocument17 pagesVLE - Paralel B - Sesi B1 - Grup FMegawati Setiawan PutriNo ratings yet
- Determinants of The Bank PerformanceDocument8 pagesDeterminants of The Bank Performancelucksia thayanithyNo ratings yet
- E: Se Dió Un Cambio Estructural Yr: Tiene Una Tendencia CrecienteDocument3 pagesE: Se Dió Un Cambio Estructural Yr: Tiene Una Tendencia CrecienteMarielly Palomino MartinezNo ratings yet
- REGRESSIONDocument2 pagesREGRESSIONUtkarsh VikramNo ratings yet
- Assignment# 01 Resaerch Techniques in Finance: 1. StationaryDocument6 pagesAssignment# 01 Resaerch Techniques in Finance: 1. StationaryNida KhanNo ratings yet
- AR 303 Vol 1 DDocument968 pagesAR 303 Vol 1 DAnonymous gM6RZL5lYdNo ratings yet
- 410 - ShubhiGupta - TSA - 2 - Shubhi GuptaDocument12 pages410 - ShubhiGupta - TSA - 2 - Shubhi Guptaaman guptaNo ratings yet
- Hafizd Achmad Ekonometrika 1910115075Document12 pagesHafizd Achmad Ekonometrika 1910115075Hafizd AchmadNo ratings yet
- Book 1Document60 pagesBook 1Evi diah phitalokANo ratings yet
- PreviewDocument8 pagesPreviewGoldy ThariqNo ratings yet
- R Rec P.838 2Document6 pagesR Rec P.838 2Madeline CurryNo ratings yet
- Hasil Jihan BucinDocument4 pagesHasil Jihan BucinRiniNo ratings yet
- C B 01 Ta3 WingconfigurationDocument30 pagesC B 01 Ta3 WingconfigurationKrizelle LaoNo ratings yet
- ملف التانيDocument3 pagesملف التانيmondialismepubNo ratings yet
- IEEE 10 Generator 39 Bus System: General OutlineDocument7 pagesIEEE 10 Generator 39 Bus System: General Outlineadau100% (1)
- Analisis Sistem Dinamik ... (13 HLM)Document7 pagesAnalisis Sistem Dinamik ... (13 HLM)Rico IndraNo ratings yet
- LevitationDocument5 pagesLevitationcdsiegertNo ratings yet
- Cross TuberiaDocument18 pagesCross TuberiaBlinderMNo ratings yet
- NACA Profile Data AvdDocument221 pagesNACA Profile Data AvdrickbunnellNo ratings yet
- MN 2-1ecuatii - 1ExeRezolvateDocument3 pagesMN 2-1ecuatii - 1ExeRezolvatecristian_framNo ratings yet
- LEVELINGDocument25 pagesLEVELINGabdulgenius123No ratings yet
- Askaria f1051151052 Modul UjiDocument27 pagesAskaria f1051151052 Modul UjiAskaria FahrezaNo ratings yet
- Hasil Uji DataDocument9 pagesHasil Uji DatapalupiclaraNo ratings yet
- Homework #1Document21 pagesHomework #1симона златковаNo ratings yet
- Database For AssignmentDocument2,238 pagesDatabase For AssignmentbinduNo ratings yet
- Tugas 2Document9 pagesTugas 2Adi PrasetyoNo ratings yet
- Group A - Exp 7 - RTD - CSTRDocument8 pagesGroup A - Exp 7 - RTD - CSTRAkhilesh ChauhanNo ratings yet
- FDocument48 pagesFBEN BENNo ratings yet
- Kingrynormalized Data Set AssignmentDocument24 pagesKingrynormalized Data Set Assignment20013122-001No ratings yet
- Lab2 2 8Document7 pagesLab2 2 8duelgodgaming007No ratings yet
- Florensia Kristaveren 102316028 / CE1 Tugas Nanomaterial (Gambar 11)Document8 pagesFlorensia Kristaveren 102316028 / CE1 Tugas Nanomaterial (Gambar 11)Florensia KristaverenNo ratings yet
- Lampiran Output EviewsDocument11 pagesLampiran Output EviewsGreynaldi GasraNo ratings yet
- Crecimiento Economico de Los Paises de Los Paises Más Importantes de Latinoamerica (Argentina)Document8 pagesCrecimiento Economico de Los Paises de Los Paises Más Importantes de Latinoamerica (Argentina)soli apaza mamaniNo ratings yet
- Table: Base Reactions Outputcase Casetype Globalfx Globalfy Globalfz Globalmx Globalmy GlobalmzDocument5 pagesTable: Base Reactions Outputcase Casetype Globalfx Globalfy Globalfz Globalmx Globalmy GlobalmzyaquiycjNo ratings yet
- Flow Meter Orifice CalculationDocument27 pagesFlow Meter Orifice CalculationLaksono BudiNo ratings yet
- 0809 Sem 1Document22 pages0809 Sem 1Kent Choo100% (1)
- Eviews KennyDocument3 pagesEviews KennyVeyrazzNo ratings yet
- Nama: Moh Zaenal Abidin NIM: A1A018086 Tugas: Uji Multilikolinieritas DanDocument3 pagesNama: Moh Zaenal Abidin NIM: A1A018086 Tugas: Uji Multilikolinieritas DanZaenal AbidinNo ratings yet
- Wahyu Ardi SriDocument6 pagesWahyu Ardi Srifadli rijaldiNo ratings yet
- Cumulative Standard Normal DistributionDocument2 pagesCumulative Standard Normal DistributionSALINGA MARK ANDREWNo ratings yet
- United States Census Figures Back to 1630From EverandUnited States Census Figures Back to 1630No ratings yet
- 7739 14817 1 SMDocument16 pages7739 14817 1 SMAry Surya PurnamaNo ratings yet
- Deforestation and Agricultural Productivity in Ivory Coast: A Dynamic AnalysisDocument21 pagesDeforestation and Agricultural Productivity in Ivory Coast: A Dynamic AnalysisNéstor Astecker YuptonNo ratings yet
- Correlation AnalysisDocument30 pagesCorrelation AnalysisAshish kumar ThapaNo ratings yet
- Fundamentals of Business Statistics: 6E John LoucksDocument40 pagesFundamentals of Business Statistics: 6E John LoucksHafsah Ahmad najibNo ratings yet
- Developing A Predictive Model About Bankruptcy in The Rural Areas of IndonesiaDocument7 pagesDeveloping A Predictive Model About Bankruptcy in The Rural Areas of IndonesiaOka WidanaNo ratings yet
- The Impact of Irrigation On Agricultural Productivity: Evidence From IndiaDocument39 pagesThe Impact of Irrigation On Agricultural Productivity: Evidence From IndiaSambit PatriNo ratings yet
- Session 1 Theory Hai Zaroori N23 Pranav PopatDocument17 pagesSession 1 Theory Hai Zaroori N23 Pranav Popatgaxovi4187No ratings yet
- Final Task XDocument17 pagesFinal Task XDirty RajanNo ratings yet
- Jurnal Bahasa InggrisDocument6 pagesJurnal Bahasa InggrisAgrifina HelgaNo ratings yet
- Tutorial 02 Probabilistic AnalysisDocument13 pagesTutorial 02 Probabilistic AnalysisAnonymous BxEP3QtNo ratings yet
- The Four-Day Work WeekDocument6 pagesThe Four-Day Work Week21MBA BARATH M.100% (1)
- Feng2012 ImportanteDocument7 pagesFeng2012 ImportanteeswaynedNo ratings yet
- 22.a Study On Effect of Welfare Measures On Employee MoraleDocument55 pages22.a Study On Effect of Welfare Measures On Employee MoralekumbojukumarNo ratings yet
- 5 - 3. Estimating The Gravity Model - 0Document22 pages5 - 3. Estimating The Gravity Model - 0Fahrul Rizky HakikiNo ratings yet
- Data Science For BeginnersDocument354 pagesData Science For BeginnersVimlesh Baghel100% (3)
- Elbethel DargeDocument66 pagesElbethel DargeHailuNo ratings yet
- Revised Course Outline MKT 470Document5 pagesRevised Course Outline MKT 470Sabine RahmanNo ratings yet
- Mainga Wise - Published Paper - 30-9-2020Document34 pagesMainga Wise - Published Paper - 30-9-2020Wise MaingaNo ratings yet
- Syllabi - Cognitive AnalyticsDocument4 pagesSyllabi - Cognitive AnalyticsRAHUL DHANOLANo ratings yet
- The Effect of Working Environment Compensation and Working Ethos Towards Employee Performance On Mariso Districts Office in MakassarDocument4 pagesThe Effect of Working Environment Compensation and Working Ethos Towards Employee Performance On Mariso Districts Office in MakassarAbu RijalNo ratings yet
- V. Nonlinear Regression by Modified Gauss-Newton Method: TheoryDocument39 pagesV. Nonlinear Regression by Modified Gauss-Newton Method: Theoryutsav_koshtiNo ratings yet
- Productivity Estimation of Bulldozers Using Generalized Linear Mixed ModelsDocument11 pagesProductivity Estimation of Bulldozers Using Generalized Linear Mixed ModelsDenny TegarNo ratings yet
- Ridge RegressionDocument82 pagesRidge RegressionSuvirNo ratings yet
- Which Preschool Children With Specific Language Impairment Receive Language Intervention?Document13 pagesWhich Preschool Children With Specific Language Impairment Receive Language Intervention?Paul AsturbiarisNo ratings yet
- PUBG: A Guide To Free Chicken Dinner: Wenxin Wei, Xin Lu, Yang Li December 13, 2018Document6 pagesPUBG: A Guide To Free Chicken Dinner: Wenxin Wei, Xin Lu, Yang Li December 13, 2018Maanikya SharmaNo ratings yet
- Skin Penetration SurrogateDocument4 pagesSkin Penetration SurrogateScott McCullaghNo ratings yet
- Stability StudiesDocument61 pagesStability StudiesSiddarth PalletiNo ratings yet
- Effects of Employees Training On The Organizational Competitive AdvantageDocument15 pagesEffects of Employees Training On The Organizational Competitive AdvantageYaw LamNo ratings yet
- BOK Six Sigma Black BeltDocument8 pagesBOK Six Sigma Black Belthans_106No ratings yet








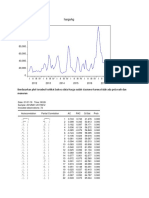



















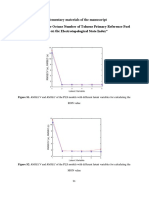





















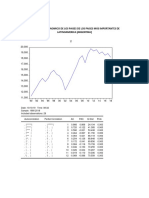






































Download as docx, pdf, or txt
You might also like
- Stat 331 Course NotesDocument79 pagesStat 331 Course NotesthemanzamanNo ratings yet
- ARIMADocument8 pagesARIMAgibe bullyNo ratings yet
- Chapter Four 4.0 Data AnalysisDocument6 pagesChapter Four 4.0 Data AnalysisSMART ROBITONo ratings yet
- Covid-19 GraphDocument7 pagesCovid-19 GraphJudeNo ratings yet
- Time-Series, ForecastingDocument12 pagesTime-Series, ForecastingRiska AristiNo ratings yet
- Eview Chương 7Document3 pagesEview Chương 7caotri34342001No ratings yet
- RF ImpedanceDocument7 pagesRF ImpedancesrybsantosNo ratings yet
- IndahDocument4 pagesIndahAndini PratiwiNo ratings yet
- My FileDocument19 pagesMy FileThufail AlghifaryNo ratings yet
- Using Excel'S Rand FunctionDocument239 pagesUsing Excel'S Rand FunctionSyed Ameer Ali ShahNo ratings yet
- Cuadro 1. Isotermas de Adsorción-GAB: #AW % Humedad DireccionDocument18 pagesCuadro 1. Isotermas de Adsorción-GAB: #AW % Humedad DireccionJarise Laban CastilloNo ratings yet
- Cu EstaDocument2 pagesCu EstaNando YarangaNo ratings yet
- Lampiran 2 Hingga Daftar Riwayat HidupDocument12 pagesLampiran 2 Hingga Daftar Riwayat HidupRaja Maulana SidabutarNo ratings yet
- Short Circuit CalculationsDocument28 pagesShort Circuit CalculationsSchaum001No ratings yet
- Tugas 3 EKOMET Muh RAFIDocument5 pagesTugas 3 EKOMET Muh RAFIdaffa luthfianNo ratings yet
- Business Forecasting Assignment: Name: Mansi Sharma SAP Id: 80011220277 Roll No: A016 Group: 10Document6 pagesBusiness Forecasting Assignment: Name: Mansi Sharma SAP Id: 80011220277 Roll No: A016 Group: 10MANSI SHARMANo ratings yet
- Inflasi ARIMA ModelDocument7 pagesInflasi ARIMA ModelAnto TomodachiRent SusiloNo ratings yet
- MLR-handson - Jupyter NotebookDocument5 pagesMLR-handson - Jupyter NotebookAnzal MalikNo ratings yet
- Case: Winter Park Hotel (Current System) : Queuing Model M/M/s (Exponential Service Times)Document35 pagesCase: Winter Park Hotel (Current System) : Queuing Model M/M/s (Exponential Service Times)Gajendra SinghNo ratings yet
- VLE - Paralel B - Sesi B1 - Grup FDocument17 pagesVLE - Paralel B - Sesi B1 - Grup FMegawati Setiawan PutriNo ratings yet
- Determinants of The Bank PerformanceDocument8 pagesDeterminants of The Bank Performancelucksia thayanithyNo ratings yet
- E: Se Dió Un Cambio Estructural Yr: Tiene Una Tendencia CrecienteDocument3 pagesE: Se Dió Un Cambio Estructural Yr: Tiene Una Tendencia CrecienteMarielly Palomino MartinezNo ratings yet
- REGRESSIONDocument2 pagesREGRESSIONUtkarsh VikramNo ratings yet
- Assignment# 01 Resaerch Techniques in Finance: 1. StationaryDocument6 pagesAssignment# 01 Resaerch Techniques in Finance: 1. StationaryNida KhanNo ratings yet
- AR 303 Vol 1 DDocument968 pagesAR 303 Vol 1 DAnonymous gM6RZL5lYdNo ratings yet
- 410 - ShubhiGupta - TSA - 2 - Shubhi GuptaDocument12 pages410 - ShubhiGupta - TSA - 2 - Shubhi Guptaaman guptaNo ratings yet
- Hafizd Achmad Ekonometrika 1910115075Document12 pagesHafizd Achmad Ekonometrika 1910115075Hafizd AchmadNo ratings yet
- Book 1Document60 pagesBook 1Evi diah phitalokANo ratings yet
- PreviewDocument8 pagesPreviewGoldy ThariqNo ratings yet
- R Rec P.838 2Document6 pagesR Rec P.838 2Madeline CurryNo ratings yet
- Hasil Jihan BucinDocument4 pagesHasil Jihan BucinRiniNo ratings yet
- C B 01 Ta3 WingconfigurationDocument30 pagesC B 01 Ta3 WingconfigurationKrizelle LaoNo ratings yet
- ملف التانيDocument3 pagesملف التانيmondialismepubNo ratings yet
- IEEE 10 Generator 39 Bus System: General OutlineDocument7 pagesIEEE 10 Generator 39 Bus System: General Outlineadau100% (1)
- Analisis Sistem Dinamik ... (13 HLM)Document7 pagesAnalisis Sistem Dinamik ... (13 HLM)Rico IndraNo ratings yet
- LevitationDocument5 pagesLevitationcdsiegertNo ratings yet
- Cross TuberiaDocument18 pagesCross TuberiaBlinderMNo ratings yet
- NACA Profile Data AvdDocument221 pagesNACA Profile Data AvdrickbunnellNo ratings yet
- MN 2-1ecuatii - 1ExeRezolvateDocument3 pagesMN 2-1ecuatii - 1ExeRezolvatecristian_framNo ratings yet
- LEVELINGDocument25 pagesLEVELINGabdulgenius123No ratings yet
- Askaria f1051151052 Modul UjiDocument27 pagesAskaria f1051151052 Modul UjiAskaria FahrezaNo ratings yet
- Hasil Uji DataDocument9 pagesHasil Uji DatapalupiclaraNo ratings yet
- Homework #1Document21 pagesHomework #1симона златковаNo ratings yet
- Database For AssignmentDocument2,238 pagesDatabase For AssignmentbinduNo ratings yet
- Tugas 2Document9 pagesTugas 2Adi PrasetyoNo ratings yet
- Group A - Exp 7 - RTD - CSTRDocument8 pagesGroup A - Exp 7 - RTD - CSTRAkhilesh ChauhanNo ratings yet
- FDocument48 pagesFBEN BENNo ratings yet
- Kingrynormalized Data Set AssignmentDocument24 pagesKingrynormalized Data Set Assignment20013122-001No ratings yet
- Lab2 2 8Document7 pagesLab2 2 8duelgodgaming007No ratings yet
- Florensia Kristaveren 102316028 / CE1 Tugas Nanomaterial (Gambar 11)Document8 pagesFlorensia Kristaveren 102316028 / CE1 Tugas Nanomaterial (Gambar 11)Florensia KristaverenNo ratings yet
- Lampiran Output EviewsDocument11 pagesLampiran Output EviewsGreynaldi GasraNo ratings yet
- Crecimiento Economico de Los Paises de Los Paises Más Importantes de Latinoamerica (Argentina)Document8 pagesCrecimiento Economico de Los Paises de Los Paises Más Importantes de Latinoamerica (Argentina)soli apaza mamaniNo ratings yet
- Table: Base Reactions Outputcase Casetype Globalfx Globalfy Globalfz Globalmx Globalmy GlobalmzDocument5 pagesTable: Base Reactions Outputcase Casetype Globalfx Globalfy Globalfz Globalmx Globalmy GlobalmzyaquiycjNo ratings yet
- Flow Meter Orifice CalculationDocument27 pagesFlow Meter Orifice CalculationLaksono BudiNo ratings yet
- 0809 Sem 1Document22 pages0809 Sem 1Kent Choo100% (1)
- Eviews KennyDocument3 pagesEviews KennyVeyrazzNo ratings yet
- Nama: Moh Zaenal Abidin NIM: A1A018086 Tugas: Uji Multilikolinieritas DanDocument3 pagesNama: Moh Zaenal Abidin NIM: A1A018086 Tugas: Uji Multilikolinieritas DanZaenal AbidinNo ratings yet
- Wahyu Ardi SriDocument6 pagesWahyu Ardi Srifadli rijaldiNo ratings yet
- Cumulative Standard Normal DistributionDocument2 pagesCumulative Standard Normal DistributionSALINGA MARK ANDREWNo ratings yet
- United States Census Figures Back to 1630From EverandUnited States Census Figures Back to 1630No ratings yet
- 7739 14817 1 SMDocument16 pages7739 14817 1 SMAry Surya PurnamaNo ratings yet
- Deforestation and Agricultural Productivity in Ivory Coast: A Dynamic AnalysisDocument21 pagesDeforestation and Agricultural Productivity in Ivory Coast: A Dynamic AnalysisNéstor Astecker YuptonNo ratings yet
- Correlation AnalysisDocument30 pagesCorrelation AnalysisAshish kumar ThapaNo ratings yet
- Fundamentals of Business Statistics: 6E John LoucksDocument40 pagesFundamentals of Business Statistics: 6E John LoucksHafsah Ahmad najibNo ratings yet
- Developing A Predictive Model About Bankruptcy in The Rural Areas of IndonesiaDocument7 pagesDeveloping A Predictive Model About Bankruptcy in The Rural Areas of IndonesiaOka WidanaNo ratings yet
- The Impact of Irrigation On Agricultural Productivity: Evidence From IndiaDocument39 pagesThe Impact of Irrigation On Agricultural Productivity: Evidence From IndiaSambit PatriNo ratings yet
- Session 1 Theory Hai Zaroori N23 Pranav PopatDocument17 pagesSession 1 Theory Hai Zaroori N23 Pranav Popatgaxovi4187No ratings yet
- Final Task XDocument17 pagesFinal Task XDirty RajanNo ratings yet
- Jurnal Bahasa InggrisDocument6 pagesJurnal Bahasa InggrisAgrifina HelgaNo ratings yet
- Tutorial 02 Probabilistic AnalysisDocument13 pagesTutorial 02 Probabilistic AnalysisAnonymous BxEP3QtNo ratings yet
- The Four-Day Work WeekDocument6 pagesThe Four-Day Work Week21MBA BARATH M.100% (1)
- Feng2012 ImportanteDocument7 pagesFeng2012 ImportanteeswaynedNo ratings yet
- 22.a Study On Effect of Welfare Measures On Employee MoraleDocument55 pages22.a Study On Effect of Welfare Measures On Employee MoralekumbojukumarNo ratings yet
- 5 - 3. Estimating The Gravity Model - 0Document22 pages5 - 3. Estimating The Gravity Model - 0Fahrul Rizky HakikiNo ratings yet
- Data Science For BeginnersDocument354 pagesData Science For BeginnersVimlesh Baghel100% (3)
- Elbethel DargeDocument66 pagesElbethel DargeHailuNo ratings yet
- Revised Course Outline MKT 470Document5 pagesRevised Course Outline MKT 470Sabine RahmanNo ratings yet
- Mainga Wise - Published Paper - 30-9-2020Document34 pagesMainga Wise - Published Paper - 30-9-2020Wise MaingaNo ratings yet
- Syllabi - Cognitive AnalyticsDocument4 pagesSyllabi - Cognitive AnalyticsRAHUL DHANOLANo ratings yet
- The Effect of Working Environment Compensation and Working Ethos Towards Employee Performance On Mariso Districts Office in MakassarDocument4 pagesThe Effect of Working Environment Compensation and Working Ethos Towards Employee Performance On Mariso Districts Office in MakassarAbu RijalNo ratings yet
- V. Nonlinear Regression by Modified Gauss-Newton Method: TheoryDocument39 pagesV. Nonlinear Regression by Modified Gauss-Newton Method: Theoryutsav_koshtiNo ratings yet
- Productivity Estimation of Bulldozers Using Generalized Linear Mixed ModelsDocument11 pagesProductivity Estimation of Bulldozers Using Generalized Linear Mixed ModelsDenny TegarNo ratings yet
- Ridge RegressionDocument82 pagesRidge RegressionSuvirNo ratings yet
- Which Preschool Children With Specific Language Impairment Receive Language Intervention?Document13 pagesWhich Preschool Children With Specific Language Impairment Receive Language Intervention?Paul AsturbiarisNo ratings yet
- PUBG: A Guide To Free Chicken Dinner: Wenxin Wei, Xin Lu, Yang Li December 13, 2018Document6 pagesPUBG: A Guide To Free Chicken Dinner: Wenxin Wei, Xin Lu, Yang Li December 13, 2018Maanikya SharmaNo ratings yet
- Skin Penetration SurrogateDocument4 pagesSkin Penetration SurrogateScott McCullaghNo ratings yet
- Stability StudiesDocument61 pagesStability StudiesSiddarth PalletiNo ratings yet
- Effects of Employees Training On The Organizational Competitive AdvantageDocument15 pagesEffects of Employees Training On The Organizational Competitive AdvantageYaw LamNo ratings yet
- BOK Six Sigma Black BeltDocument8 pagesBOK Six Sigma Black Belthans_106No ratings yet