Download as pdf or txt
You might also like
- Toshiba Case 3Document4 pagesToshiba Case 3Deta Detade100% (1)
- HJB EquationsDocument38 pagesHJB EquationsbobmezzNo ratings yet
- Amado Carrillo Fuentes - The Killer Across The River by Charles BowdenDocument16 pagesAmado Carrillo Fuentes - The Killer Across The River by Charles BowdenChad B Harper100% (1)
- Mastering Apache SparkDocument1,044 pagesMastering Apache SparkArjun Singh100% (6)
- COGS 118 Homework 3 Supervised Machine Learning AlgorithmsDocument7 pagesCOGS 118 Homework 3 Supervised Machine Learning AlgorithmsVeronica LinNo ratings yet
- Stochastic Optimization For Machine LearningDocument59 pagesStochastic Optimization For Machine LearningjsprchinaNo ratings yet
- Logistic Regression LossDocument7 pagesLogistic Regression Lossmohammed.elbakkalielammariNo ratings yet
- Tutorial 8 QuestionsDocument3 pagesTutorial 8 QuestionsEvan DuhNo ratings yet
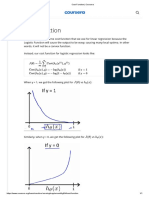
- Cost Function - Coursera Week3Document1 pageCost Function - Coursera Week3Mr. KNo ratings yet
- Lecture4_ECO521_webDocument21 pagesLecture4_ECO521_webAnjorin AdedapoNo ratings yet
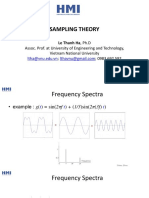
- Digital Image Processing - Sampling TheoryDocument56 pagesDigital Image Processing - Sampling TheoryLong Đặng HoàngNo ratings yet
- Info 159/259 HW 2Document3 pagesInfo 159/259 HW 2Yvonne Yifan ZhouNo ratings yet
- Logistic RegressionDocument34 pagesLogistic RegressionĐức Lại AnhNo ratings yet
- Applied Linear Algebra 1st Edition Olver Solutions ManualDocument18 pagesApplied Linear Algebra 1st Edition Olver Solutions Manualthioxenegripe.55vd100% (22)
- Dwnload Full Applied Linear Algebra 1st Edition Olver Solutions Manual PDFDocument35 pagesDwnload Full Applied Linear Algebra 1st Edition Olver Solutions Manual PDFeyepieceinexact.4h0h100% (16)
- AOI Past Papers QuestionsDocument15 pagesAOI Past Papers QuestionsMehrin fNo ratings yet
- Quantum Mechanics Example: U C S C B S C E CMPE 240: I L D SDocument9 pagesQuantum Mechanics Example: U C S C B S C E CMPE 240: I L D SSuhailUmarNo ratings yet
- 1 Dot Product and Cross Product: A) (Angle Between Two Vectors)Document3 pages1 Dot Product and Cross Product: A) (Angle Between Two Vectors)KelLYSNo ratings yet
- CHAP 02eDocument10 pagesCHAP 02eNolan castisimoNo ratings yet
- Applied Linear Algebra 1st Edition Olver Solutions ManualDocument25 pagesApplied Linear Algebra 1st Edition Olver Solutions ManualDavidBrownjrzf100% (63)
- AC-ED L03 - RegressionDocument83 pagesAC-ED L03 - RegressionAbel EspinNo ratings yet
- Script 2Document62 pagesScript 2michaelNo ratings yet
- Sat Comp0142Document4 pagesSat Comp0142Musa AsadNo ratings yet
- Unconstrained Optimization III: Topics We'll CoverDocument3 pagesUnconstrained Optimization III: Topics We'll CoverMohammadAliNo ratings yet
- (Rosenberger, 1997) - Functional Analysis Introduction To Spectral Theory in Hilbert SpacesDocument62 pages(Rosenberger, 1997) - Functional Analysis Introduction To Spectral Theory in Hilbert SpacesclearcastingNo ratings yet
- F5 - Ch03.4 Transformation WS - 230927 - 085417Document10 pagesF5 - Ch03.4 Transformation WS - 230927 - 085417s321012No ratings yet
- Lec 16Document15 pagesLec 16Thiago SallesNo ratings yet
- Cost Functions: Ntroduction To The OST UnctionDocument29 pagesCost Functions: Ntroduction To The OST UnctionChandrachuda nayakNo ratings yet
- CS 229, Autumn 2012 Problem Set #1 Solutions: Supervised LearningDocument16 pagesCS 229, Autumn 2012 Problem Set #1 Solutions: Supervised LearningAvinash JaiswalNo ratings yet
- QA20091 Em2 27 - 1Document4 pagesQA20091 Em2 27 - 1api-25895802No ratings yet
- cs188 Fa23 Note22Document3 pagescs188 Fa23 Note22Ali RahimiNo ratings yet
- Discretization and Simulation For A Class of Spdes With Applications To Zakai and Mckean-Vlasov EquationsDocument43 pagesDiscretization and Simulation For A Class of Spdes With Applications To Zakai and Mckean-Vlasov EquationspoojaNo ratings yet
- EC744 Lecture Note 4 Deterministic DP With Unbounded ReturnsDocument15 pagesEC744 Lecture Note 4 Deterministic DP With Unbounded ReturnsbinicleNo ratings yet
- Power Sys State EstimatnDocument6 pagesPower Sys State EstimatnAnonymous dJETDebGNo ratings yet
- Digital Assignment-2Document6 pagesDigital Assignment-2Adithya HariprakashNo ratings yet
- Exp 2 ADocument6 pagesExp 2 AAkshat SinghNo ratings yet
- HigherDimensionalNumericalRangeof - Xi LieProductsonBoundSelf AdjointoperatorsDocument15 pagesHigherDimensionalNumericalRangeof - Xi LieProductsonBoundSelf AdjointoperatorsismailNo ratings yet
- MA205 Midterm F2022Document9 pagesMA205 Midterm F2022234fold234No ratings yet
- Function Final SendDocument28 pagesFunction Final SendGimy InternationalNo ratings yet
- 337week0405 PDFDocument13 pages337week0405 PDFkjel reida jøssanNo ratings yet
- FUNCTIONS-2-Quadratic-Transformation-Absolute-HL-2022 2 Sıkıştırılmış 2Document56 pagesFUNCTIONS-2-Quadratic-Transformation-Absolute-HL-2022 2 Sıkıştırılmış 2tolga.tekinNo ratings yet
- Analysis On Steering Mechanics Model of Tracked Tank Cleaning RobotDocument5 pagesAnalysis On Steering Mechanics Model of Tracked Tank Cleaning RobotRacem LoukilNo ratings yet
- Support Vector Machines: Logisic RegressionDocument10 pagesSupport Vector Machines: Logisic Regressionahmadmanhal673No ratings yet
- Lecture03 FT 2DDocument68 pagesLecture03 FT 2DMd Nur-A-Adam DonyNo ratings yet
- Memory Aid 2Document2 pagesMemory Aid 2julsaujaNo ratings yet
- Limits and ContinuityDocument10 pagesLimits and ContinuityziafNo ratings yet
- Phy201 Lect8Document25 pagesPhy201 Lect8meidinania0No ratings yet
- Lecture-Note of Chapter 4 From LemmiDocument34 pagesLecture-Note of Chapter 4 From LemmiMustefa UsmaelNo ratings yet
- Computer Graphic - Chapter 04Document100 pagesComputer Graphic - Chapter 04Minh NguyenNo ratings yet
- Ps 1Document5 pagesPs 1Emre UysalNo ratings yet
- Assignment 3Document9 pagesAssignment 3lili aboudNo ratings yet
- Vietnam National UniversityDocument14 pagesVietnam National UniversityQuang VõNo ratings yet
- 9 Circle (@mrbeastjee)Document39 pages9 Circle (@mrbeastjee)I AM KIM TAEHYUNGNo ratings yet
- Lecture14 LogisticDocument25 pagesLecture14 Logisticmohammed.elbakkalielammariNo ratings yet
- Winkler FoundationDocument18 pagesWinkler Foundationdandy imam fauziNo ratings yet
- Module 4 - 2Document41 pagesModule 4 - 2AEC OFFICIALNo ratings yet
- Technical Report Multidimensional, Downsampled Convolution For Autoencoders PDFDocument9 pagesTechnical Report Multidimensional, Downsampled Convolution For Autoencoders PDFLeonNo ratings yet
- MTS102CALDocument21 pagesMTS102CALadalumohsandra2000No ratings yet
- 10 32323-Ujma 406335-598993Document4 pages10 32323-Ujma 406335-598993عبد الله الخالدNo ratings yet
- F9 ACCA Summary - Revision Notes 2017Document96 pagesF9 ACCA Summary - Revision Notes 2017alihihai113No ratings yet
- 2022 2. VizeDocument12 pages2022 2. Vize247rxg9qr8No ratings yet
- Unit 4 - Linear RegressionDocument52 pagesUnit 4 - Linear RegressionshinjoNo ratings yet
- 5 Leadership LessonsDocument2 pages5 Leadership LessonsnyniccNo ratings yet
- Bio Drosophilia Mini Project 2 1Document15 pagesBio Drosophilia Mini Project 2 1jocyeo0% (1)
- Discussion Questions Activity NoDocument2 pagesDiscussion Questions Activity NoAngilene Lacson CabinianNo ratings yet
- Account Statement From 1 Jan 2017 To 30 Jun 2017Document2 pagesAccount Statement From 1 Jan 2017 To 30 Jun 2017Ujjain mpNo ratings yet
- English IV: 3 Partial Week 4Document17 pagesEnglish IV: 3 Partial Week 4Luis Manuel GonzálezNo ratings yet
- Lab 8 - PWMDocument4 pagesLab 8 - PWMlol100% (1)
- Database Systems, Eleventh Edition by Coronel Morris, Course Technology 2014Document5 pagesDatabase Systems, Eleventh Edition by Coronel Morris, Course Technology 2014LaluMohan KcNo ratings yet
- Housing and Land Use Regulatory Board: Lupong Nangangasiwa Sa Pabahay at Gamit NG LupaDocument36 pagesHousing and Land Use Regulatory Board: Lupong Nangangasiwa Sa Pabahay at Gamit NG LupaJoseph Raymund BautistaNo ratings yet
- Is 3594 Fire Safety of Industrial Buildings General-Storage Ware HouseDocument11 pagesIs 3594 Fire Safety of Industrial Buildings General-Storage Ware HouseRamakrishna AgumbeNo ratings yet
- Egyptian PPP Law 67 For 2010 EnglishDocument17 pagesEgyptian PPP Law 67 For 2010 EnglishReham El AbnoudyNo ratings yet
- SUBHIKSHADocument12 pagesSUBHIKSHAAkshat ChaturvediNo ratings yet
- Case Study Emirates AirlinesDocument4 pagesCase Study Emirates Airlinesuzzmapk33% (9)
- Hydrogen EconomyDocument19 pagesHydrogen EconomyEdgar Gabriel Sanchez DominguezNo ratings yet
- 5 ABB Cigre Jornadas Tecnicas FCLDocument35 pages5 ABB Cigre Jornadas Tecnicas FCLmayalasan1No ratings yet
- ABC - Suggested Answer - 0Document8 pagesABC - Suggested Answer - 0pam pamNo ratings yet
- Athabasca University Chemistry 350 Organic Chemistry IDocument921 pagesAthabasca University Chemistry 350 Organic Chemistry IAntonija JovanovskaNo ratings yet
- Standard Notes CBE29-3 Construction in Civil Engineering 20150222Document37 pagesStandard Notes CBE29-3 Construction in Civil Engineering 20150222Genie LoNo ratings yet
- Exp 7 Colloids ChemistryDocument8 pagesExp 7 Colloids ChemistryNur Fadhilah100% (1)
- Tc3yf en Manual 170905 He PDFDocument1 pageTc3yf en Manual 170905 He PDFJuan Manuel EscorihuelaNo ratings yet
- Astaro Security Gateway enDocument4 pagesAstaro Security Gateway enmaxbyzNo ratings yet
- Join The Club: C207 - Database Systems 2012Document237 pagesJoin The Club: C207 - Database Systems 2012hamzahNo ratings yet
- Problem Solving - WikipediaDocument23 pagesProblem Solving - WikipediaLUIS HEREDIANo ratings yet
- An 2013 1Document6 pagesAn 2013 1ashwinNo ratings yet
- Berg Danielle ResumeDocument2 pagesBerg Danielle Resumeapi-481770567No ratings yet
- Podman Part4Document5 pagesPodman Part4anbuchennai82No ratings yet
- Varistor Catalog PDFDocument254 pagesVaristor Catalog PDFsantosh_babar_26100% (1)
- Checklist of ADAC AuditDocument3 pagesChecklist of ADAC AuditMarieta AlejoNo ratings yet