
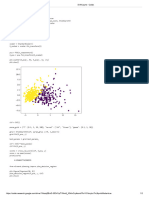
Codes
Codes
You might also like
- MachineDocument45 pagesMachineGagan Sharma100% (1)
- ML Lab ProgramsDocument23 pagesML Lab ProgramsRoopa 18-19-36No ratings yet
- Import Pandas As PD DF PD - Read - CSV ("Titanic - Train - CSV") DF - HeadDocument20 pagesImport Pandas As PD DF PD - Read - CSV ("Titanic - Train - CSV") DF - HeadSaloni TuliNo ratings yet
- Machine LearninDocument23 pagesMachine LearninManoj Kumar 1183100% (2)
- Simple Linear RegressionDocument11 pagesSimple Linear Regressionshivkumar620400No ratings yet
- Linearregression SVMDocument3 pagesLinearregression SVM4023 KeerthanaNo ratings yet
- 20MIS1025 - DecisionTree - Ipynb - ColaboratoryDocument4 pages20MIS1025 - DecisionTree - Ipynb - ColaboratorySandip DasNo ratings yet
- ML Experiments ListDocument12 pagesML Experiments Listb1974No ratings yet
- Aiml Record From 1 To 10Document10 pagesAiml Record From 1 To 10avsworld1234No ratings yet
- Naive - Bayes - Ipynb - ColabDocument3 pagesNaive - Bayes - Ipynb - ColabAgi TasyaNo ratings yet
- Support Vector Machine A) ClassificationDocument3 pagesSupport Vector Machine A) Classification4NM20IS003 ABHISHEK ANo ratings yet
- Email Spam ClassifierDocument22 pagesEmail Spam Classifierphenomenal beastNo ratings yet
- Quick StatementDocument7 pagesQuick StatementHarshit ChudiwalNo ratings yet
- Binary MulticlassDocument3 pagesBinary MulticlassNikhil PNo ratings yet
- Raj Practical File (ML)Document16 pagesRaj Practical File (ML)RajNo ratings yet
- 2_Logistic RegressionDocument4 pages2_Logistic Regressiontasya lopaNo ratings yet
- AI Lab 2Document5 pagesAI Lab 221b-039-csNo ratings yet
- Cancer Disease ClassificationDocument6 pagesCancer Disease ClassificationBARATH PNo ratings yet
- ML Lab RecordDocument15 pagesML Lab Recordrr3870044No ratings yet
- Classification Algorithm Python Code 1567761638Document4 pagesClassification Algorithm Python Code 1567761638Awanit KumarNo ratings yet
- Lab - 8 - 21130616 - TranThanhVu - Ipynb - ColabDocument4 pagesLab - 8 - 21130616 - TranThanhVu - Ipynb - Colabnguyennhutoan722003No ratings yet
- FML File FinalDocument36 pagesFML File FinalKunal SainiNo ratings yet
- 2020 CS 95.pyDocument1 page2020 CS 95.pyQazi MaazNo ratings yet
- Unit2 ML ProgramsDocument7 pagesUnit2 ML Programsdiroja5648No ratings yet
- Ai Last 5Document4 pagesAi Last 5Bad BoyNo ratings yet
- Exp 6Document6 pagesExp 6jayNo ratings yet
- Practical File of Machine Learning 1905388Document42 pagesPractical File of Machine Learning 1905388DevanshNo ratings yet
- SL Classification For Data Science..Document4 pagesSL Classification For Data Science..shivaybhargava33No ratings yet
- OhkkwellDocument1 pageOhkkwellshivkumar620400No ratings yet
- KRAI PracticalDocument14 pagesKRAI PracticalContact VishalNo ratings yet
- Import As Import As Import As: 'Social - Network - Ads - CSV'Document2 pagesImport As Import As Import As: 'Social - Network - Ads - CSV'lucansitumeang21No ratings yet
- CorrectionDocument3 pagesCorrectionbougmazisoufyaneNo ratings yet
- Machinelearning - Alisya Athirah Binti Mohd Huzzainny (Updated)Document26 pagesMachinelearning - Alisya Athirah Binti Mohd Huzzainny (Updated)Alisya AthirahNo ratings yet
- Tous Les Algo de MLDocument7 pagesTous Les Algo de MLJadlaoui AsmaNo ratings yet
- EXP 08 (ML) - ShriDocument2 pagesEXP 08 (ML) - ShriDSE 04. Chetana BhoirNo ratings yet
- InternalDocument3 pagesInternalShyamaprasad MSNo ratings yet
- Data ScienceDocument8 pagesData ScienceGeetha A LNo ratings yet
- 2020 CS 64Document1 page2020 CS 64Qazi MaazNo ratings yet
- ML Lab 4Document2 pagesML Lab 4trismatthew1234No ratings yet
- Exp 5Document8 pagesExp 5jayNo ratings yet
- 16BCB0126 VL2018195002535 Pe003Document40 pages16BCB0126 VL2018195002535 Pe003MohitNo ratings yet
- C1 W2 Lab05 Sklearn GD SolnDocument3 pagesC1 W2 Lab05 Sklearn GD SolnSrinidhi PNo ratings yet
- DL JOURNAL_mergedDocument27 pagesDL JOURNAL_mergedxayzh123No ratings yet
- MLDocument2 pagesMLwovova9230No ratings yet
- project 1Document2 pagesproject 1gireshmittalNo ratings yet
- Machine Learning With SQLDocument12 pagesMachine Learning With SQLprince krish100% (1)
- Machine Learning LAB: Practical-1Document24 pagesMachine Learning LAB: Practical-1Tsering Jhakree100% (2)
- Machine Learning Hands-On Programs Program 1: Linear Regression - Single Variable Linear RegressionDocument22 pagesMachine Learning Hands-On Programs Program 1: Linear Regression - Single Variable Linear RegressionKANTESH kantesh100% (1)
- Decision TreeDocument3 pagesDecision TreesabaNo ratings yet
- Linearregression 4Document3 pagesLinearregression 4api-559045701No ratings yet
- FML LabFile 7expsDocument37 pagesFML LabFile 7expsKunal SainiNo ratings yet
- Import Pandas as PdDocument21 pagesImport Pandas as Pdcaptainsaad838No ratings yet
- Machine Learning Hands-OnDocument18 pagesMachine Learning Hands-OnVivek JD100% (1)
- K-Nearest Neighbor On Python Ken OcumaDocument9 pagesK-Nearest Neighbor On Python Ken OcumaAliyha Dionio100% (2)
- My CodeDocument7 pagesMy Codeoyelekeayomide1No ratings yet
- ML Ex8Document2 pagesML Ex8yefigoh133No ratings yet
- Online Payment Fraud Detection Using Machine LearningDocument2 pagesOnline Payment Fraud Detection Using Machine LearningDev Ranjan RautNo ratings yet
- LAB-4 ReportDocument21 pagesLAB-4 Reportjithentar.cs21No ratings yet
- SML - Week 3Document5 pagesSML - Week 3szho68No ratings yet
- CHR MethodDocument9 pagesCHR Methodsanyo0612No ratings yet
- Speaking IndicatorDocument3 pagesSpeaking IndicatorFatihah100% (3)
- Mental Illness Prediction Using Deep LearningDocument58 pagesMental Illness Prediction Using Deep Learningsanjeev dhatterwalNo ratings yet
- Number Plate RecognitionDocument10 pagesNumber Plate RecognitionKrishna BasutkarNo ratings yet
- Toward Human-Centered AI:: A Perspective From Human-Computer InteractionDocument5 pagesToward Human-Centered AI:: A Perspective From Human-Computer InteractionNathenNo ratings yet
- COMP3314 A2 G17 ReportDocument4 pagesCOMP3314 A2 G17 ReportnrdsnkeNo ratings yet
- Control Engineering MCQDocument4 pagesControl Engineering MCQZahid Yousuf50% (2)
- PPT12-W12-Big Data VisualizationDocument29 pagesPPT12-W12-Big Data Visualizationannisaaam72No ratings yet
- CS403 Mcqs Mid Term by Vu Topper RM-1-1Document56 pagesCS403 Mcqs Mid Term by Vu Topper RM-1-1modmotNo ratings yet
- Chapter 9 Design Via Root LocusDocument4 pagesChapter 9 Design Via Root LocusAnonymous 5JyxK22PQyNo ratings yet
- Interlanguage in SLA PDFDocument35 pagesInterlanguage in SLA PDFSana NadeemNo ratings yet
- A Introduction To Advanced Process ControlDocument5 pagesA Introduction To Advanced Process Controlsandeep lal100% (1)
- Adaptive Control Design and AnalysisDocument45 pagesAdaptive Control Design and Analysishind90No ratings yet
- Traffic Signal Recognition System Using Deep LearningDocument4 pagesTraffic Signal Recognition System Using Deep LearningFarouk BoumehrezNo ratings yet
- I M. Tech. - I Sem. (CSE) L T C 3 0 3 Program Elective I (16CS5010) Course ObjectivesDocument8 pagesI M. Tech. - I Sem. (CSE) L T C 3 0 3 Program Elective I (16CS5010) Course ObjectivesManjunath KV Assistant Professor (CSE)No ratings yet
- Matrix On Communication ModelsDocument3 pagesMatrix On Communication ModelsChristianne Joy Del RosarioNo ratings yet
- Teme Pentru Referate La Cursul "Retele Neuronale"Document3 pagesTeme Pentru Referate La Cursul "Retele Neuronale"cernatandNo ratings yet
- Unit 1-Nature and Elements of CommunicationDocument5 pagesUnit 1-Nature and Elements of CommunicationMa.robelleF. PapaNo ratings yet
- Ilovepdf MergedDocument44 pagesIlovepdf Mergedranga thukaramNo ratings yet
- Automated Visual Inspection For Bottle Caps Using Fuzzy LogicDocument7 pagesAutomated Visual Inspection For Bottle Caps Using Fuzzy LogicThong NguyenNo ratings yet
- 1 Lab Manual-Final-Control-System-1Document35 pages1 Lab Manual-Final-Control-System-1Shimalis RetaNo ratings yet
- Multi Layer Perceptron Neural NetworksDocument30 pagesMulti Layer Perceptron Neural NetworkssubbuniNo ratings yet
- New Approach To Similarity Detection by Combining Technique Three-Patch Local Binary Patterns (TP-LBP) With Support Vector MachineDocument10 pagesNew Approach To Similarity Detection by Combining Technique Three-Patch Local Binary Patterns (TP-LBP) With Support Vector MachineIAES IJAINo ratings yet
- System Design 10 - Time Domain AnalysisDocument14 pagesSystem Design 10 - Time Domain AnalysisSanjay RaajNo ratings yet
- Hidden Markov Models: A Simple Markov ChainDocument46 pagesHidden Markov Models: A Simple Markov Chainv123321No ratings yet
- IATF 16949 - 2016 ITALIANO - Da SitoDocument22 pagesIATF 16949 - 2016 ITALIANO - Da Sitolucaturra69No ratings yet
- Modern Control Systems (MCS) : Lecture-30-31 Design of Control Systems in Sate SpaceDocument42 pagesModern Control Systems (MCS) : Lecture-30-31 Design of Control Systems in Sate SpaceBelayneh Tadesse100% (2)
- Quiz 11Document6 pagesQuiz 11thao nguyenNo ratings yet
- What Is Fuzzy Logic?: Natural Language BinaryDocument3 pagesWhat Is Fuzzy Logic?: Natural Language BinaryAshagre MekuriaNo ratings yet
- Machine LearningDocument8 pagesMachine Learningramayanta0% (1)
























































































Download as docx, pdf, or txt
You might also like
- MachineDocument45 pagesMachineGagan Sharma100% (1)
- ML Lab ProgramsDocument23 pagesML Lab ProgramsRoopa 18-19-36No ratings yet
- Import Pandas As PD DF PD - Read - CSV ("Titanic - Train - CSV") DF - HeadDocument20 pagesImport Pandas As PD DF PD - Read - CSV ("Titanic - Train - CSV") DF - HeadSaloni TuliNo ratings yet
- Machine LearninDocument23 pagesMachine LearninManoj Kumar 1183100% (2)
- Simple Linear RegressionDocument11 pagesSimple Linear Regressionshivkumar620400No ratings yet
- Linearregression SVMDocument3 pagesLinearregression SVM4023 KeerthanaNo ratings yet
- 20MIS1025 - DecisionTree - Ipynb - ColaboratoryDocument4 pages20MIS1025 - DecisionTree - Ipynb - ColaboratorySandip DasNo ratings yet
- ML Experiments ListDocument12 pagesML Experiments Listb1974No ratings yet
- Aiml Record From 1 To 10Document10 pagesAiml Record From 1 To 10avsworld1234No ratings yet
- Naive - Bayes - Ipynb - ColabDocument3 pagesNaive - Bayes - Ipynb - ColabAgi TasyaNo ratings yet
- Support Vector Machine A) ClassificationDocument3 pagesSupport Vector Machine A) Classification4NM20IS003 ABHISHEK ANo ratings yet
- Email Spam ClassifierDocument22 pagesEmail Spam Classifierphenomenal beastNo ratings yet
- Quick StatementDocument7 pagesQuick StatementHarshit ChudiwalNo ratings yet
- Binary MulticlassDocument3 pagesBinary MulticlassNikhil PNo ratings yet
- Raj Practical File (ML)Document16 pagesRaj Practical File (ML)RajNo ratings yet
- 2_Logistic RegressionDocument4 pages2_Logistic Regressiontasya lopaNo ratings yet
- AI Lab 2Document5 pagesAI Lab 221b-039-csNo ratings yet
- Cancer Disease ClassificationDocument6 pagesCancer Disease ClassificationBARATH PNo ratings yet
- ML Lab RecordDocument15 pagesML Lab Recordrr3870044No ratings yet
- Classification Algorithm Python Code 1567761638Document4 pagesClassification Algorithm Python Code 1567761638Awanit KumarNo ratings yet
- Lab - 8 - 21130616 - TranThanhVu - Ipynb - ColabDocument4 pagesLab - 8 - 21130616 - TranThanhVu - Ipynb - Colabnguyennhutoan722003No ratings yet
- FML File FinalDocument36 pagesFML File FinalKunal SainiNo ratings yet
- 2020 CS 95.pyDocument1 page2020 CS 95.pyQazi MaazNo ratings yet
- Unit2 ML ProgramsDocument7 pagesUnit2 ML Programsdiroja5648No ratings yet
- Ai Last 5Document4 pagesAi Last 5Bad BoyNo ratings yet
- Exp 6Document6 pagesExp 6jayNo ratings yet
- Practical File of Machine Learning 1905388Document42 pagesPractical File of Machine Learning 1905388DevanshNo ratings yet
- SL Classification For Data Science..Document4 pagesSL Classification For Data Science..shivaybhargava33No ratings yet
- OhkkwellDocument1 pageOhkkwellshivkumar620400No ratings yet
- KRAI PracticalDocument14 pagesKRAI PracticalContact VishalNo ratings yet
- Import As Import As Import As: 'Social - Network - Ads - CSV'Document2 pagesImport As Import As Import As: 'Social - Network - Ads - CSV'lucansitumeang21No ratings yet
- CorrectionDocument3 pagesCorrectionbougmazisoufyaneNo ratings yet
- Machinelearning - Alisya Athirah Binti Mohd Huzzainny (Updated)Document26 pagesMachinelearning - Alisya Athirah Binti Mohd Huzzainny (Updated)Alisya AthirahNo ratings yet
- Tous Les Algo de MLDocument7 pagesTous Les Algo de MLJadlaoui AsmaNo ratings yet
- EXP 08 (ML) - ShriDocument2 pagesEXP 08 (ML) - ShriDSE 04. Chetana BhoirNo ratings yet
- InternalDocument3 pagesInternalShyamaprasad MSNo ratings yet
- Data ScienceDocument8 pagesData ScienceGeetha A LNo ratings yet
- 2020 CS 64Document1 page2020 CS 64Qazi MaazNo ratings yet
- ML Lab 4Document2 pagesML Lab 4trismatthew1234No ratings yet
- Exp 5Document8 pagesExp 5jayNo ratings yet
- 16BCB0126 VL2018195002535 Pe003Document40 pages16BCB0126 VL2018195002535 Pe003MohitNo ratings yet
- C1 W2 Lab05 Sklearn GD SolnDocument3 pagesC1 W2 Lab05 Sklearn GD SolnSrinidhi PNo ratings yet
- DL JOURNAL_mergedDocument27 pagesDL JOURNAL_mergedxayzh123No ratings yet
- MLDocument2 pagesMLwovova9230No ratings yet
- project 1Document2 pagesproject 1gireshmittalNo ratings yet
- Machine Learning With SQLDocument12 pagesMachine Learning With SQLprince krish100% (1)
- Machine Learning LAB: Practical-1Document24 pagesMachine Learning LAB: Practical-1Tsering Jhakree100% (2)
- Machine Learning Hands-On Programs Program 1: Linear Regression - Single Variable Linear RegressionDocument22 pagesMachine Learning Hands-On Programs Program 1: Linear Regression - Single Variable Linear RegressionKANTESH kantesh100% (1)
- Decision TreeDocument3 pagesDecision TreesabaNo ratings yet
- Linearregression 4Document3 pagesLinearregression 4api-559045701No ratings yet
- FML LabFile 7expsDocument37 pagesFML LabFile 7expsKunal SainiNo ratings yet
- Import Pandas as PdDocument21 pagesImport Pandas as Pdcaptainsaad838No ratings yet
- Machine Learning Hands-OnDocument18 pagesMachine Learning Hands-OnVivek JD100% (1)
- K-Nearest Neighbor On Python Ken OcumaDocument9 pagesK-Nearest Neighbor On Python Ken OcumaAliyha Dionio100% (2)
- My CodeDocument7 pagesMy Codeoyelekeayomide1No ratings yet
- ML Ex8Document2 pagesML Ex8yefigoh133No ratings yet
- Online Payment Fraud Detection Using Machine LearningDocument2 pagesOnline Payment Fraud Detection Using Machine LearningDev Ranjan RautNo ratings yet
- LAB-4 ReportDocument21 pagesLAB-4 Reportjithentar.cs21No ratings yet
- SML - Week 3Document5 pagesSML - Week 3szho68No ratings yet
- CHR MethodDocument9 pagesCHR Methodsanyo0612No ratings yet
- Speaking IndicatorDocument3 pagesSpeaking IndicatorFatihah100% (3)
- Mental Illness Prediction Using Deep LearningDocument58 pagesMental Illness Prediction Using Deep Learningsanjeev dhatterwalNo ratings yet
- Number Plate RecognitionDocument10 pagesNumber Plate RecognitionKrishna BasutkarNo ratings yet
- Toward Human-Centered AI:: A Perspective From Human-Computer InteractionDocument5 pagesToward Human-Centered AI:: A Perspective From Human-Computer InteractionNathenNo ratings yet
- COMP3314 A2 G17 ReportDocument4 pagesCOMP3314 A2 G17 ReportnrdsnkeNo ratings yet
- Control Engineering MCQDocument4 pagesControl Engineering MCQZahid Yousuf50% (2)
- PPT12-W12-Big Data VisualizationDocument29 pagesPPT12-W12-Big Data Visualizationannisaaam72No ratings yet
- CS403 Mcqs Mid Term by Vu Topper RM-1-1Document56 pagesCS403 Mcqs Mid Term by Vu Topper RM-1-1modmotNo ratings yet
- Chapter 9 Design Via Root LocusDocument4 pagesChapter 9 Design Via Root LocusAnonymous 5JyxK22PQyNo ratings yet
- Interlanguage in SLA PDFDocument35 pagesInterlanguage in SLA PDFSana NadeemNo ratings yet
- A Introduction To Advanced Process ControlDocument5 pagesA Introduction To Advanced Process Controlsandeep lal100% (1)
- Adaptive Control Design and AnalysisDocument45 pagesAdaptive Control Design and Analysishind90No ratings yet
- Traffic Signal Recognition System Using Deep LearningDocument4 pagesTraffic Signal Recognition System Using Deep LearningFarouk BoumehrezNo ratings yet
- I M. Tech. - I Sem. (CSE) L T C 3 0 3 Program Elective I (16CS5010) Course ObjectivesDocument8 pagesI M. Tech. - I Sem. (CSE) L T C 3 0 3 Program Elective I (16CS5010) Course ObjectivesManjunath KV Assistant Professor (CSE)No ratings yet
- Matrix On Communication ModelsDocument3 pagesMatrix On Communication ModelsChristianne Joy Del RosarioNo ratings yet
- Teme Pentru Referate La Cursul "Retele Neuronale"Document3 pagesTeme Pentru Referate La Cursul "Retele Neuronale"cernatandNo ratings yet
- Unit 1-Nature and Elements of CommunicationDocument5 pagesUnit 1-Nature and Elements of CommunicationMa.robelleF. PapaNo ratings yet
- Ilovepdf MergedDocument44 pagesIlovepdf Mergedranga thukaramNo ratings yet
- Automated Visual Inspection For Bottle Caps Using Fuzzy LogicDocument7 pagesAutomated Visual Inspection For Bottle Caps Using Fuzzy LogicThong NguyenNo ratings yet
- 1 Lab Manual-Final-Control-System-1Document35 pages1 Lab Manual-Final-Control-System-1Shimalis RetaNo ratings yet
- Multi Layer Perceptron Neural NetworksDocument30 pagesMulti Layer Perceptron Neural NetworkssubbuniNo ratings yet
- New Approach To Similarity Detection by Combining Technique Three-Patch Local Binary Patterns (TP-LBP) With Support Vector MachineDocument10 pagesNew Approach To Similarity Detection by Combining Technique Three-Patch Local Binary Patterns (TP-LBP) With Support Vector MachineIAES IJAINo ratings yet
- System Design 10 - Time Domain AnalysisDocument14 pagesSystem Design 10 - Time Domain AnalysisSanjay RaajNo ratings yet
- Hidden Markov Models: A Simple Markov ChainDocument46 pagesHidden Markov Models: A Simple Markov Chainv123321No ratings yet
- IATF 16949 - 2016 ITALIANO - Da SitoDocument22 pagesIATF 16949 - 2016 ITALIANO - Da Sitolucaturra69No ratings yet
- Modern Control Systems (MCS) : Lecture-30-31 Design of Control Systems in Sate SpaceDocument42 pagesModern Control Systems (MCS) : Lecture-30-31 Design of Control Systems in Sate SpaceBelayneh Tadesse100% (2)
- Quiz 11Document6 pagesQuiz 11thao nguyenNo ratings yet
- What Is Fuzzy Logic?: Natural Language BinaryDocument3 pagesWhat Is Fuzzy Logic?: Natural Language BinaryAshagre MekuriaNo ratings yet
- Machine LearningDocument8 pagesMachine Learningramayanta0% (1)