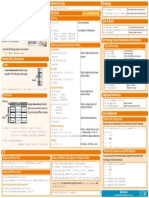
Download as pdf or txt
You might also like
- Agile & ScrumDocument18 pagesAgile & ScrumVimleshNo ratings yet
- Pandas Python For Data ScienceDocument1 pagePandas Python For Data Sciencechowdamhemalatha100% (1)
- Pyspark RDD Cheat Sheet Python For Data ScienceDocument1 pagePyspark RDD Cheat Sheet Python For Data ScienceAngel ChirinosNo ratings yet
- PySpark Cheat Sheet PythonDocument1 pagePySpark Cheat Sheet PythonsreedharNo ratings yet
- PySpark Cheat Sheet Spark in Python PDFDocument1 pagePySpark Cheat Sheet Spark in Python PDFram179No ratings yet
- PySpark RDD Basics PDFDocument1 pagePySpark RDD Basics PDFCOCONo ratings yet
- CS226 06 RDDDocument29 pagesCS226 06 RDDchenna kesavaNo ratings yet
- Numpy Cheat Sheet Python For Data Science: Inspecting Your Array Sorting ArraysDocument1 pageNumpy Cheat Sheet Python For Data Science: Inspecting Your Array Sorting ArraysLourdes Victoria UrrutiaNo ratings yet
- Ex 4.1 Adding ForcesDocument3 pagesEx 4.1 Adding ForcesAtith TananchaiNo ratings yet
- Partition Decoding For Reed-Solomon Codes Based On Bit ReliabilityDocument4 pagesPartition Decoding For Reed-Solomon Codes Based On Bit ReliabilityRAJKUMAR SAMIKKANNUNo ratings yet
- Potensial ListrikDocument3 pagesPotensial Listrikbanana twellzNo ratings yet
- PySpark Cheat Sheet For RDD OperationsDocument1 pagePySpark Cheat Sheet For RDD OperationsZyad AhmedNo ratings yet
- PW Math Five Year Pyq FullbookDocument846 pagesPW Math Five Year Pyq Fullbookc8850269No ratings yet
- Cs2200 DiagnosticDocument1 pageCs2200 DiagnosticJorge RamirezNo ratings yet
- Exercises Section 3orlisDocument3 pagesExercises Section 3orlisDANIEL ESTEBAN GONZALEZ TAMAYONo ratings yet
- Part 3: R Questions: Please Write Proper R Code Using Functions For The Below QuestionsDocument1 pagePart 3: R Questions: Please Write Proper R Code Using Functions For The Below Questionsstudent loginNo ratings yet
- SparkDocument12 pagesSparkPRAMOTH KJNo ratings yet
- Numpy Cheat SheetDocument1 pageNumpy Cheat SheetKevin ChalcoNo ratings yet
- PySpark CheatSheet EdurekaDocument1 pagePySpark CheatSheet EdurekaBL PipasNo ratings yet
- Numpy Cheat Sheet Python For Data Science: Inspecting Your Array Sorting ArraysDocument1 pageNumpy Cheat Sheet Python For Data Science: Inspecting Your Array Sorting ArraysSuhas PrabhuNo ratings yet
- Adobe Scan 08 Feb 2024Document24 pagesAdobe Scan 08 Feb 2024sandhyasandhya10675No ratings yet
- AMC8 Area and Perimeter 01 21-10-28Document4 pagesAMC8 Area and Perimeter 01 21-10-28RobertNo ratings yet
- Bayesian Net B HBNDocument31 pagesBayesian Net B HBNG JNo ratings yet
- TreeDocument9 pagesTreeDev TyagiNo ratings yet
- Register Device Type Range Format Notes: Recipe DataDocument2 pagesRegister Device Type Range Format Notes: Recipe DataAlberto MolinaNo ratings yet
- MongoDB CheatSheetDocument1 pageMongoDB CheatSheetGoogle UserNo ratings yet
- Basics of RDDDocument84 pagesBasics of RDDjustin maxtonNo ratings yet
- WinDbg CheatSheetDocument1 pageWinDbg CheatSheetM. temNo ratings yet
- Chapter 2Document35 pagesChapter 2AceNo ratings yet
- Comp 12 Ms-RevisedDocument6 pagesComp 12 Ms-RevisedVinoth Tamil SelvanNo ratings yet
- RMaria DBDocument14 pagesRMaria DBPedroM.F.NakashimaNo ratings yet
- PySpark Transformations TutorialDocument58 pagesPySpark Transformations Tutorialravikumar lanka100% (1)
- Cheat PythonDocument8 pagesCheat PythonhectordelosriosdiazNo ratings yet
- Pandas Python For Data ScienceDocument1 pagePandas Python For Data ScienceaaaaNo ratings yet
- Determinant & MatricesDocument74 pagesDeterminant & MatricesSanmika SinghNo ratings yet
- R Structures & ObjectsDocument5 pagesR Structures & ObjectsShantilal BhayalNo ratings yet
- BITS Pilani, Hyderabad Campus CSF212, Database Systems : (2M) (2M) (2M) (2M) (2M)Document8 pagesBITS Pilani, Hyderabad Campus CSF212, Database Systems : (2M) (2M) (2M) (2M) (2M)Jui PradhanNo ratings yet
- Chapter 2Document35 pagesChapter 2amirNo ratings yet
- c1b4 - Below PLDocument19 pagesc1b4 - Below PLSheikh Muhammad Muhtashim AbidNo ratings yet
- P13 - P21 - Paper + Answer - Print - 150Document16 pagesP13 - P21 - Paper + Answer - Print - 150Aanand TrivediNo ratings yet
- Task SparkDocument4 pagesTask SparkAzza A. AzizNo ratings yet
- Opencv CheatsheetDocument2 pagesOpencv CheatsheetJ.Simon GoodallNo ratings yet
- NumpyGUIA PYTHON-03Document1 pageNumpyGUIA PYTHON-03Danilo ZanichelliNo ratings yet
- Pandas: Learn Python For Data Science InteractivelyDocument1 pagePandas: Learn Python For Data Science InteractivelySofia HerreraNo ratings yet
- Big Data For DummiesDocument8 pagesBig Data For DummiesfcodelpuertoNo ratings yet
- Class Test 2019-2020: Civil EngineeringDocument10 pagesClass Test 2019-2020: Civil EngineeringShivangi MishraNo ratings yet
- Class XII IP IMP Notes & Sample PapersDocument125 pagesClass XII IP IMP Notes & Sample PapersbadshahmohdtaazimNo ratings yet
- Batch Data Communication: ObjectiveDocument59 pagesBatch Data Communication: ObjectiveAshok GanasalaNo ratings yet
- KBDD Reference GuideDocument7 pagesKBDD Reference GuideParth SomkuwarNo ratings yet
- Opencv CheatsheetDocument2 pagesOpencv CheatsheetmartinakosNo ratings yet
- Uml Advanced ClassesDocument12 pagesUml Advanced ClassesSatish VarmaNo ratings yet
- Teodora Sorescu: Objective Core CompetenciesDocument2 pagesTeodora Sorescu: Objective Core CompetenciesTeodora SorescuNo ratings yet
- Software Development Model and Methodologies HW Kotenko LiudmylaDocument12 pagesSoftware Development Model and Methodologies HW Kotenko LiudmylaLyudmila KotenkoNo ratings yet
- Manage Tekla StructuresDocument426 pagesManage Tekla StructuresJoakim DesanerNo ratings yet
- Kunal Verma: Professional SummaryDocument2 pagesKunal Verma: Professional SummaryJagjiv VermaNo ratings yet
- New Microsoft Word DocumentDocument13 pagesNew Microsoft Word DocumentNiyem Al ZamanNo ratings yet
- Fdocuments - in - Oracle Otl Timecard Layout CustomicationDocument43 pagesFdocuments - in - Oracle Otl Timecard Layout CustomicationMaheshNo ratings yet
- Autofac Integration MVC Csproj FileListAbsoluteDocument5 pagesAutofac Integration MVC Csproj FileListAbsolutenikNo ratings yet
- Automated Tests With Webdriverio: João Casalta NabaisDocument14 pagesAutomated Tests With Webdriverio: João Casalta NabaisAdriana CastelblancoNo ratings yet
- Tugas Praktikum Modul 10Document15 pagesTugas Praktikum Modul 10Widia WahyuningsihNo ratings yet
- Dzone Microservicesguide 2017 PDFDocument49 pagesDzone Microservicesguide 2017 PDFAbstractSoftNo ratings yet
- Concepts of Concurrent Programming by David W. BustardDocument51 pagesConcepts of Concurrent Programming by David W. BustardCrack360No ratings yet
- Exercise 08Document2 pagesExercise 08•-• VũuuNo ratings yet
- To Change The Color of Dashboard TabsDocument18 pagesTo Change The Color of Dashboard TabsPagada VasthalaNo ratings yet
- Vim Editor in LinuxDocument12 pagesVim Editor in LinuxSazal KhanNo ratings yet
- Lab 6Document6 pagesLab 6Matthew GomezNo ratings yet
- Android Unit 2Document4 pagesAndroid Unit 2prajwalchin123No ratings yet
- Practical 1: Aim: A) Write A Program To Print "Hello World". CodeDocument19 pagesPractical 1: Aim: A) Write A Program To Print "Hello World". CodeCharudatt PalviNo ratings yet
- 25 GareportDocument15 pages25 GareportParitala RamanjiNo ratings yet
- MotoHawk Mototune PSDocument3 pagesMotoHawk Mototune PSPiotr SokołowskiNo ratings yet
- SDLC QuestionsDocument2 pagesSDLC QuestionsGadadhar Tiwary100% (1)
- 10.question Bank With AnswersDocument156 pages10.question Bank With Answersnirav_modhNo ratings yet
- 5 Ways To Download Files From Scribd Without Login 2022 - TechnadviceDocument1 page5 Ways To Download Files From Scribd Without Login 2022 - TechnadviceMakiNo ratings yet
- Bibliographic RepositoryDocument9 pagesBibliographic Repository20EUIT125- SAKTHI ISWARYA SNo ratings yet
- Ava Questions & Answers - Exceptions TypesDocument5 pagesAva Questions & Answers - Exceptions TypesBelayneh TadesseNo ratings yet
- Call A MethodDocument9 pagesCall A MethodRumana BegumNo ratings yet
- Lab 6 DSADocument7 pagesLab 6 DSAmuhammad arslanNo ratings yet
- Principles of Programming Using C: Answer Any FIVE Full Questions, Choosing at Least ONE Question From Each MODULEDocument2 pagesPrinciples of Programming Using C: Answer Any FIVE Full Questions, Choosing at Least ONE Question From Each MODULEKeerthana SNo ratings yet
- PySpark+Slides v1Document458 pagesPySpark+Slides v1ravikumar lankaNo ratings yet