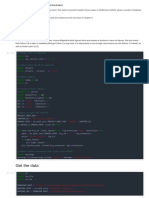
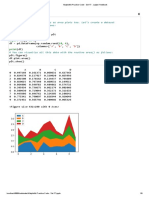
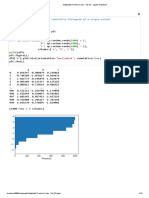
Download as pdf or txt
You might also like
- Setup: Chapter 2 - End-To-End Machine Learning ProjectDocument31 pagesSetup: Chapter 2 - End-To-End Machine Learning ProjectAmitNo ratings yet
- CSZ Sfi Standard v4Document7 pagesCSZ Sfi Standard v4Shingirai PfumayarambaNo ratings yet
- Financial Modeling BenningaDocument17 pagesFinancial Modeling BenningaBeatriz Montoya17% (6)
- Advertising - Paulina Frigia Rante (34) - PPBP 1 - ColaboratoryDocument7 pagesAdvertising - Paulina Frigia Rante (34) - PPBP 1 - ColaboratoryPaulina Frigia RanteNo ratings yet
- S9 Regresión Simple y Múltiple Al - ColaboratoryDocument14 pagesS9 Regresión Simple y Múltiple Al - ColaboratorySebastian CallesNo ratings yet
- Correlation and Regression (TP)Document4 pagesCorrelation and Regression (TP)Hiimay ChannelNo ratings yet
- Sklearn Tutorial: DNN On Boston DataDocument9 pagesSklearn Tutorial: DNN On Boston DatahopkeinstNo ratings yet
- Data SciDocument29 pagesData Sciketisi2987No ratings yet
- PembelajaranMesin - Ipynb - ColaboratoryDocument6 pagesPembelajaranMesin - Ipynb - ColaboratoryKhaerul RijalNo ratings yet
- Linear RegressionDocument10 pagesLinear RegressionWONDYE DESTANo ratings yet
- Ash RegressionDocument11 pagesAsh Regressionsarpateashish5No ratings yet
- Load Dataset: Import AsDocument8 pagesLoad Dataset: Import AsZESTYNo ratings yet
- Train Test SplitDocument4 pagesTrain Test Splitjaymehta1444No ratings yet
- Data Munging - Ipynb - Colaboratory - Yodhi Adhi SanjayaDocument4 pagesData Munging - Ipynb - Colaboratory - Yodhi Adhi SanjayaadhiNo ratings yet
- Project 8 Predictive Analytics - Ipynb - ColaboratoryDocument8 pagesProject 8 Predictive Analytics - Ipynb - ColaboratoryaadityadeolalikarNo ratings yet
- Logistic Pima Indians - Ipynb - ColaboratoryDocument4 pagesLogistic Pima Indians - Ipynb - ColaboratorySHEKHAR SWAMINo ratings yet
- Linear - Regression - Ipynb - ColaboratoryDocument4 pagesLinear - Regression - Ipynb - Colaboratoryavnimote121No ratings yet
- Basit Doğrusal Regresyon KodlarDocument5 pagesBasit Doğrusal Regresyon KodlarRamazan AcarNo ratings yet
- Pca Implementation NotebookDocument4 pagesPca Implementation NotebookWalid SassiNo ratings yet
- Analysing Ad BudgetDocument4 pagesAnalysing Ad BudgetSrikanth100% (1)
- Self Study Assignment Python IIDocument4 pagesSelf Study Assignment Python IIjuhik2007No ratings yet
- ADS 3.ipynb - ColaboratoryDocument5 pagesADS 3.ipynb - ColaboratoryMahesh BadgujarNo ratings yet
- ModelDocument164 pagesModelSanjayNo ratings yet
- ML Project - Jupyter NotebookDocument5 pagesML Project - Jupyter NotebookJAISURYA S B.Sc.AIDANo ratings yet
- Using Tensorflow To Predict Jet Numbers in Cern Proton Collisions (Evaluator-Omid-Baghcheh-Saraei)Document29 pagesUsing Tensorflow To Predict Jet Numbers in Cern Proton Collisions (Evaluator-Omid-Baghcheh-Saraei)David EsparzaArellanoNo ratings yet
- TrabajoDocument5 pagesTrabajoJAVIER OCHOANo ratings yet
- Supervised Learning With Scikit-Learn: Preprocessing DataDocument32 pagesSupervised Learning With Scikit-Learn: Preprocessing DataNourheneMbarekNo ratings yet
- Practical-5 - Jupyter NotebookDocument8 pagesPractical-5 - Jupyter NotebookHarsha Gohil100% (1)
- Regression DemoDocument8 pagesRegression Demorxn114392No ratings yet
- Assumption of Linear RegressionDocument6 pagesAssumption of Linear RegressionKagade AjinkyaNo ratings yet
- KMeans Clustering Bidimensional Daniel Ames CamayoDocument15 pagesKMeans Clustering Bidimensional Daniel Ames CamayoEl RusnderNo ratings yet
- Data Vizualization - Jupyter NotebookDocument20 pagesData Vizualization - Jupyter Notebookdimple mahaduleNo ratings yet
- From Import: Image Image (Filename, Height, Width)Document10 pagesFrom Import: Image Image (Filename, Height, Width)Trishala KumariNo ratings yet
- Marvel Vs DCDocument1 pageMarvel Vs DCManoj MNo ratings yet
- BS SRR-3Document20 pagesBS SRR-3anveshvarma365No ratings yet
- Import As Import As Import AsDocument8 pagesImport As Import As Import AsDavid EsparzaArellanoNo ratings yet
- Stock Prediction Web App - Jupyter NotebookDocument12 pagesStock Prediction Web App - Jupyter Notebookashutosh312004No ratings yet
- Python Code To Implement Linear RegressionDocument5 pagesPython Code To Implement Linear RegressionDreaming Boy0% (1)
- K MedoidsDocument10 pagesK Medoidsprerna sharmaNo ratings yet
- FDS Solved SlipsDocument63 pagesFDS Solved Slipsyashm4071100% (1)
- Lab10 Regression Evaluation MethodsDocument5 pagesLab10 Regression Evaluation Methodsiffi khanNo ratings yet
- 27 Jupyter NotebookDocument42 pages27 Jupyter NotebookJonathan VillanuevaNo ratings yet
- Practica 9Document24 pagesPractica 92marlenehh2003No ratings yet
- ML Lab6.Ipynb - ColaboratoryDocument5 pagesML Lab6.Ipynb - ColaboratoryAvi Srivastava100% (1)
- Matplotlib 1652960400Document13 pagesMatplotlib 1652960400Washington AzevedoNo ratings yet
- LAB14Document12 pagesLAB14Yuvraj WaleNo ratings yet
- Miles Per GallonDocument11 pagesMiles Per Gallonvince.lachicaNo ratings yet
- Saurabh Verma 9919102005Document11 pagesSaurabh Verma 9919102005Yogendra pratap Singh100% (1)
- Technologyname Phase2Document20 pagesTechnologyname Phase2vasusam300No ratings yet
- Tabla de Frecuencias Del Agua: EstadísticaDocument3 pagesTabla de Frecuencias Del Agua: EstadísticaWalter Paulino Quispe TicseNo ratings yet
- 2 and 3Document6 pages2 and 3Radhika KhandelwalNo ratings yet
- 21BECE30036 Prac 1Document10 pages21BECE30036 Prac 1NimishaNo ratings yet
- Praktikum6 - Wildan Supriatna - 11122471Document4 pagesPraktikum6 - Wildan Supriatna - 11122471sealmobilee99No ratings yet
- Chapter 8 - ForecastingDocument17 pagesChapter 8 - ForecastinganshitaNo ratings yet
- Coding Tugas Besar Analitika DataDocument7 pagesCoding Tugas Besar Analitika Datarizqullahm14No ratings yet
- Series4 - Renata Putri HenessaDocument12 pagesSeries4 - Renata Putri HenessaPerfect DarksideNo ratings yet
- E21CSEU0770 Lab4Document4 pagesE21CSEU0770 Lab4kumar.nayan26No ratings yet
- Pronosticos - Ipynb - ColaboratoryDocument13 pagesPronosticos - Ipynb - ColaboratoryFrancisco Javier RESTREPO GRANOBLESNo ratings yet
- AirbnbspDocument9 pagesAirbnbspBHAI LOGNo ratings yet
- Merging - Scaled - 1D - & - Trying - Different - CLassification - ML - Models - .Ipynb - ColaboratoryDocument16 pagesMerging - Scaled - 1D - & - Trying - Different - CLassification - ML - Models - .Ipynb - Colaboratorygirishcherry12100% (1)
- Multilinerregression - Jupyter NotebookDocument4 pagesMultilinerregression - Jupyter Notebookankitasonawane9988No ratings yet
- GTDocument2 pagesGTSourabh YadavNo ratings yet
- VS Code Cheatsheet PDFDocument12 pagesVS Code Cheatsheet PDFSourabh YadavNo ratings yet
- Digital (Iit Kharagpur)Document853 pagesDigital (Iit Kharagpur)Sourabh YadavNo ratings yet
- What Is Self Awareness 2795023Document7 pagesWhat Is Self Awareness 2795023Sourabh YadavNo ratings yet
- Bubble SortDocument6 pagesBubble SortSourabh YadavNo ratings yet
- Linear and Binary SearchDocument7 pagesLinear and Binary SearchSourabh YadavNo ratings yet
- Data StructuresDocument12 pagesData StructuresSourabh YadavNo ratings yet
- Statically Indeterminate Shaft-Bearing Systems: D Cos DDocument14 pagesStatically Indeterminate Shaft-Bearing Systems: D Cos DIvelin ValchevNo ratings yet
- Unit 1 Conduction Heat TransferDocument52 pagesUnit 1 Conduction Heat Transfer20MEB155 Abu BakrNo ratings yet
- Chapter 3 Linear ProgrammingDocument35 pagesChapter 3 Linear ProgrammingSaad ShaikhNo ratings yet
- GNL 05Document4 pagesGNL 05Mauricio Bustamante HuaquipaNo ratings yet
- AI Good NotesDocument68 pagesAI Good NotesSyaza Ibrahim0% (1)
- 1000 Aptitude Questions To Crack MNC & Competitive ExamsDocument580 pages1000 Aptitude Questions To Crack MNC & Competitive ExamsBHARAT PANWARNo ratings yet
- Tradu. SuelosDocument8 pagesTradu. SuelosMariaAngelicaRodriguezMarinNo ratings yet
- Sanet - ST Digital Control SystemsDocument583 pagesSanet - ST Digital Control SystemsManci PeterNo ratings yet
- 2.134 Estatica BeersDocument5 pages2.134 Estatica BeersluifrodriguezbNo ratings yet
- Development Length: Straight Bars in TensionDocument8 pagesDevelopment Length: Straight Bars in TensionIvan LajaraNo ratings yet
- Math Grade7 Quarter3 Module6 Week6Document3 pagesMath Grade7 Quarter3 Module6 Week6ALLYSSA MAE PELONIANo ratings yet
- Tự Học NX 5 - Offset, ScaleDocument37 pagesTự Học NX 5 - Offset, Scalenguyentrongchi.hpNo ratings yet
- Managerial Economics Book PDFDocument31 pagesManagerial Economics Book PDFHassan Abdulkadir Mohamed100% (1)
- Formula For Perimeter and AreaDocument19 pagesFormula For Perimeter and AreagaylebugayongNo ratings yet
- PDC BixioRimoldiDocument311 pagesPDC BixioRimoldiFrank211No ratings yet
- Topographic Surveying and MappingDocument18 pagesTopographic Surveying and Mappingbontu chalchisaNo ratings yet
- Speech Recognition System - A ReviewDocument10 pagesSpeech Recognition System - A ReviewAkmad Ali AbdulNo ratings yet
- Cart PDFDocument12 pagesCart PDFSteven FrayneNo ratings yet
- Math-Saya (Enjoying Mathematics For Life)Document2 pagesMath-Saya (Enjoying Mathematics For Life)Jolean D.CogononNo ratings yet
- Previous University Question PaperDocument3 pagesPrevious University Question Papersafu_117No ratings yet
- ch6 FollandDocument2 pagesch6 Follandchic19801041No ratings yet
- Recommendations of Fastener Flexibility Using FE p3Document16 pagesRecommendations of Fastener Flexibility Using FE p3Ludovic MoutienNo ratings yet
- GRD 6 Maths Paper 1Document11 pagesGRD 6 Maths Paper 1addyNo ratings yet
- Football Matches Count Compounding 1Document13 pagesFootball Matches Count Compounding 1Raph SunNo ratings yet
- XXX Wind XXX Pressures On Low-Slope Roofs ASCE 7-16Document14 pagesXXX Wind XXX Pressures On Low-Slope Roofs ASCE 7-16M. Murat ErginNo ratings yet
- H.C.F. & L.C.M (Amcat)Document6 pagesH.C.F. & L.C.M (Amcat)GauravNo ratings yet
- 11-A New Approach To Surface Crown Pillar DesignDocument9 pages11-A New Approach To Surface Crown Pillar DesignSANTIAGO NAVIA VÁSQUEZNo ratings yet