
Ijcse10 02 03 108
Ijcse10 02 03 108
You might also like
- The DAMA Dictionary of Data Management, 2nd Edition: Over 2,000 Terms Defined For IT and Business ProfessionalsDocument1 pageThe DAMA Dictionary of Data Management, 2nd Edition: Over 2,000 Terms Defined For IT and Business ProfessionalsMedia Penelitian Dan Pengembangan Kesehatan100% (1)
- ROSES Flow Diagram For Systematic ReviewsDocument1 pageROSES Flow Diagram For Systematic Reviewswhy daNo ratings yet
- Configuracion Ancho de Banda Servicios Eth HUAWEIDocument8 pagesConfiguracion Ancho de Banda Servicios Eth HUAWEIDidier Sepulveda0% (1)
- An Empirical Study of Data Warehouse Implementation EffectivenessDocument10 pagesAn Empirical Study of Data Warehouse Implementation EffectivenessCarolina López CostaNo ratings yet
- Narrative ReportDocument6 pagesNarrative ReportEricka Genove50% (2)
- Study of ETL Process and Its Testing TechniquesDocument9 pagesStudy of ETL Process and Its Testing TechniquesIJRASETPublicationsNo ratings yet
- Extraction Transformation and Loading (ETL) of Data Using ETL ToolsDocument8 pagesExtraction Transformation and Loading (ETL) of Data Using ETL ToolsIJRASETPublicationsNo ratings yet
- Extract, Transform and Load (Etl) Performance Improved by Query CacheDocument20 pagesExtract, Transform and Load (Etl) Performance Improved by Query CacheannamyemNo ratings yet
- An Efficent Hybrid Optimization of ETL Process in Data Warehouse of Cloud ArchitectureDocument13 pagesAn Efficent Hybrid Optimization of ETL Process in Data Warehouse of Cloud ArchitectureRenzo HerediaNo ratings yet
- A Comparative Analysis of ETL and Hyper ETLDocument7 pagesA Comparative Analysis of ETL and Hyper ETLInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Design and Analysis of DWH and BI in Education DomDocument8 pagesDesign and Analysis of DWH and BI in Education Domsatyanarayanamurthy yerrapragadaNo ratings yet
- Enhancing Data Staging As A Mechanism For Fast Data AccessDocument9 pagesEnhancing Data Staging As A Mechanism For Fast Data AccessWho Am INo ratings yet
- Chapter 6Document45 pagesChapter 6Prudhvinadh KopparapuNo ratings yet
- Microproject On ETL Process For Data AnalyticsDocument6 pagesMicroproject On ETL Process For Data Analytics15-Sayyad Arslaan ANNo ratings yet
- 2266 ArticleText 9891 1 10 20230124Document7 pages2266 ArticleText 9891 1 10 20230124MariaNo ratings yet
- Data Integration and The Extraction, Transformation and Loading ProcessesDocument5 pagesData Integration and The Extraction, Transformation and Loading ProcessesPoet CruzNo ratings yet
- Agile ETLDocument7 pagesAgile ETLWagner TorresNo ratings yet
- Analysis and Design of ETL in Hospital Performance Appraisal SystemDocument6 pagesAnalysis and Design of ETL in Hospital Performance Appraisal SystemTushar Kant GuptaNo ratings yet
- (IJCT-V2I5P3) Author :mr. Nilesh Mali, MR - SachinBojewarDocument8 pages(IJCT-V2I5P3) Author :mr. Nilesh Mali, MR - SachinBojewarIjctJournalsNo ratings yet
- Data - Mining - and - Data by ManyindoDocument3 pagesData - Mining - and - Data by ManyindoStevenNo ratings yet
- V3i11 0016 PDFDocument9 pagesV3i11 0016 PDFPavankumar KaredlaNo ratings yet
- Experiment No. 04: Real-Life ETL CycleDocument4 pagesExperiment No. 04: Real-Life ETL Cyclesayali nazareNo ratings yet
- Designing A Data Warehouse System For Sales and Distribution CompanyDocument7 pagesDesigning A Data Warehouse System For Sales and Distribution CompanyNitin ShelkeNo ratings yet
- 3813 10753 1 PBDocument9 pages3813 10753 1 PBkhanhly80000No ratings yet
- Business Intelligence ToolsDocument16 pagesBusiness Intelligence ToolsGurdeep KaurNo ratings yet
- FPT-HandBookData Engineer (11123)Document160 pagesFPT-HandBookData Engineer (11123)Thien Ly100% (1)
- Design and Implementation of The Web (Extract, Transform, Load) Process in Data Warehouse ApplicationDocument11 pagesDesign and Implementation of The Web (Extract, Transform, Load) Process in Data Warehouse ApplicationIAES IJAINo ratings yet
- Lectura 2Document8 pagesLectura 2antonia1997No ratings yet
- Data Integration Best PracticesDocument17 pagesData Integration Best PracticesSNo ratings yet
- Heterogeneous Data Transfer and LoaderDocument3 pagesHeterogeneous Data Transfer and LoaderInternational Journal of Research in Engineering and TechnologyNo ratings yet
- Accounting Information System Discussion Notes 2Document11 pagesAccounting Information System Discussion Notes 2johnpenoniaNo ratings yet
- ETL Testing Interview Questions and AnswersDocument9 pagesETL Testing Interview Questions and AnswersKancharlaNo ratings yet
- Survey On ETL ProcessesDocument11 pagesSurvey On ETL ProcessesBruno OliveiraNo ratings yet
- To Build and Optimize ETL PipelineDocument10 pagesTo Build and Optimize ETL PipelineIJRASETPublicationsNo ratings yet
- Performance and Analyses Using Two ETL Extraction Software SolutionsDocument4 pagesPerformance and Analyses Using Two ETL Extraction Software SolutionsVanya SinghalNo ratings yet
- Reading Material Mod 4 Data Integration - Data WarehouseDocument33 pagesReading Material Mod 4 Data Integration - Data WarehousePrasad TikamNo ratings yet
- Unit 6 Data Extraction: StructureDocument24 pagesUnit 6 Data Extraction: StructuregaardiNo ratings yet
- Data Warehouse Concept and Its Usage: April 2021Document10 pagesData Warehouse Concept and Its Usage: April 2021Brij RaiNo ratings yet
- JVP 42019Document10 pagesJVP 42019dineshwar sdNo ratings yet
- System Analysis and DesignDocument24 pagesSystem Analysis and DesignNwachinaere NnamdiNo ratings yet
- An Approach of RDD Optimization in Big Data AnalytDocument9 pagesAn Approach of RDD Optimization in Big Data Analytmary maryNo ratings yet
- FGFGDocument6 pagesFGFGameenkhan64656No ratings yet
- SE TusharDocument22 pagesSE TusharShashank KumarNo ratings yet
- Data Mining - Unit 1Document45 pagesData Mining - Unit 1csumant94No ratings yet
- Business Intelligence: S.D.M College of Engineering and TechnologyDocument11 pagesBusiness Intelligence: S.D.M College of Engineering and TechnologyYilikal MengeduNo ratings yet
- A Novel Approach For Understanding Ideology Behind Managing DataDocument11 pagesA Novel Approach For Understanding Ideology Behind Managing DataGustotaNo ratings yet
- Improving System Predictability and Performance VIDocument10 pagesImproving System Predictability and Performance VIdevi noor endrawatiNo ratings yet
- Jasper Soft ETL.v4 enDocument5 pagesJasper Soft ETL.v4 enharoonobNo ratings yet
- Data Profiling ScreenDocument4 pagesData Profiling ScreenzipzapdhoomNo ratings yet
- DWM Unit-I NotesDocument10 pagesDWM Unit-I NotesAnkita PawarNo ratings yet
- Data Engineering - Beginner's GuideDocument9 pagesData Engineering - Beginner's GuideSRINIVAS RAO100% (1)
- Report 7Document39 pagesReport 7pulkit sharmaNo ratings yet
- System Analysis and DesignDocument24 pagesSystem Analysis and DesignNahar Sabirah100% (1)
- Data Warehouse & Erp: A Combined ApproachDocument3 pagesData Warehouse & Erp: A Combined ApproachvanpointNo ratings yet
- Query Optimization Based On Heuristic Rules IJERTV3IS070992Document6 pagesQuery Optimization Based On Heuristic Rules IJERTV3IS070992Nadeen AhmedNo ratings yet
- Isas Etl FinalDocument70 pagesIsas Etl FinaluoopNo ratings yet
- Utilization Extract Transform Load For DevelopingDocument9 pagesUtilization Extract Transform Load For Developingalison filgueirasNo ratings yet
- Ipl Matches DocumentationDocument28 pagesIpl Matches DocumentationNitish Kumar MohantyNo ratings yet
- The Design of The Information Hub: Denise RogersDocument4 pagesThe Design of The Information Hub: Denise RogersBalachandraKSNo ratings yet
- A Review On Python Libraries and Ides For Data Science: November 2021Document19 pagesA Review On Python Libraries and Ides For Data Science: November 20219920102030No ratings yet
- Improvement of K-Means Clustering Algorithm: March 2012Document6 pagesImprovement of K-Means Clustering Algorithm: March 2012David MorenoNo ratings yet
- MedicalDocument3 pagesMedicalddNo ratings yet
- The Challenges of Extract, Transform and Load (Etl) For Data Integration in Near Realtime EnvironmentDocument9 pagesThe Challenges of Extract, Transform and Load (Etl) For Data Integration in Near Realtime EnvironmentJJAGUILARNo ratings yet
- Fundamentals of Data Engineering: Designing and Building Scalable Data Systems for Modern ApplicationsFrom EverandFundamentals of Data Engineering: Designing and Building Scalable Data Systems for Modern ApplicationsNo ratings yet
- Formarea Diasporei ArmeneștiDocument13 pagesFormarea Diasporei ArmeneștigumenaiNo ratings yet
- Oracle® Common Application Components: API Reference Guide Release 11iDocument174 pagesOracle® Common Application Components: API Reference Guide Release 11idebasarangiNo ratings yet
- Week 2 Teradata Practice Exercises GuideDocument7 pagesWeek 2 Teradata Practice Exercises GuideFelicia Cristina Gune50% (2)
- DFD, ERD and UML DiagramsDocument32 pagesDFD, ERD and UML Diagramsroomigillani26No ratings yet
- Assignment-W11 Updated July2022Document7 pagesAssignment-W11 Updated July2022Dev Narayan KushwahaNo ratings yet
- 1.hum - Impact of Information Literacy Skills On The Academic Achievement of The StudentsDocument16 pages1.hum - Impact of Information Literacy Skills On The Academic Achievement of The StudentsImpact JournalsNo ratings yet
- Oracle Database For SAPDocument12 pagesOracle Database For SAPImtiaz AnwarNo ratings yet
- Literature Review UtsDocument4 pagesLiterature Review Utsea5zjs6a100% (1)
- Data Architecture For SAP HANADocument52 pagesData Architecture For SAP HANASepideh JaliliNo ratings yet
- Instant Download Ebook PDF Encyclopedia of Bioinformatics and Computational Biology ABC of Bioinformatics PDF ScribdDocument41 pagesInstant Download Ebook PDF Encyclopedia of Bioinformatics and Computational Biology ABC of Bioinformatics PDF Scribdhoward.linkovich475100% (53)
- SAP S/4 HANA Legacy Transfer Migration CockpitDocument13 pagesSAP S/4 HANA Legacy Transfer Migration CockpitSwapNo ratings yet
- Periodical TestDocument2 pagesPeriodical TestEvaNo ratings yet
- Access 2016 Module 1: Getting Started With Access 2016Document20 pagesAccess 2016 Module 1: Getting Started With Access 2016AndresileNo ratings yet
- APACHE REDIS Training: Trainer:David JosephDocument3 pagesAPACHE REDIS Training: Trainer:David JosephDavid JosephNo ratings yet
- Requirements For Distributed File SystemsDocument4 pagesRequirements For Distributed File SystemsmyatNo ratings yet
- Fin Irjmets1686300982Document10 pagesFin Irjmets1686300982botplusnoob97No ratings yet
- RdbmsDocument25 pagesRdbmsfarihamohammad1998No ratings yet
- Module - Ii Notes Dbms - 15Cs53 V Sem Cse/IseDocument21 pagesModule - Ii Notes Dbms - 15Cs53 V Sem Cse/IsevenkatNo ratings yet
- How To Display Costom DB View Talen Profile-1Document12 pagesHow To Display Costom DB View Talen Profile-1Sivasekar NarayananNo ratings yet
- Stakeholder QuestionnaireDocument6 pagesStakeholder QuestionnaireDeepak Daya MattaNo ratings yet
- Diccionario de Psicologia - Ander EggDocument144 pagesDiccionario de Psicologia - Ander EggFantasmita ChanNo ratings yet
- Mis Advantage and DisadvantageDocument1 pageMis Advantage and DisadvantageharrycreNo ratings yet
- Data AnalyticsDocument5 pagesData AnalyticsVivek MunjayasraNo ratings yet
- Data Mining and BIDocument4 pagesData Mining and BI20dshivanshupandeyNo ratings yet
- B Ve Inst GuideDocument134 pagesB Ve Inst GuideSAMSUNGGROUP3gmail.com DenisNo ratings yet
- Department of Computer Science and Engineering: A Mini Project ReportDocument31 pagesDepartment of Computer Science and Engineering: A Mini Project ReportBhanuranjan S BNo ratings yet

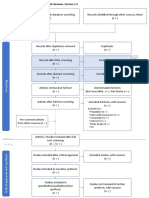




















































































Download as pdf or txt
You might also like
- The DAMA Dictionary of Data Management, 2nd Edition: Over 2,000 Terms Defined For IT and Business ProfessionalsDocument1 pageThe DAMA Dictionary of Data Management, 2nd Edition: Over 2,000 Terms Defined For IT and Business ProfessionalsMedia Penelitian Dan Pengembangan Kesehatan100% (1)
- ROSES Flow Diagram For Systematic ReviewsDocument1 pageROSES Flow Diagram For Systematic Reviewswhy daNo ratings yet
- Configuracion Ancho de Banda Servicios Eth HUAWEIDocument8 pagesConfiguracion Ancho de Banda Servicios Eth HUAWEIDidier Sepulveda0% (1)
- An Empirical Study of Data Warehouse Implementation EffectivenessDocument10 pagesAn Empirical Study of Data Warehouse Implementation EffectivenessCarolina López CostaNo ratings yet
- Narrative ReportDocument6 pagesNarrative ReportEricka Genove50% (2)
- Study of ETL Process and Its Testing TechniquesDocument9 pagesStudy of ETL Process and Its Testing TechniquesIJRASETPublicationsNo ratings yet
- Extraction Transformation and Loading (ETL) of Data Using ETL ToolsDocument8 pagesExtraction Transformation and Loading (ETL) of Data Using ETL ToolsIJRASETPublicationsNo ratings yet
- Extract, Transform and Load (Etl) Performance Improved by Query CacheDocument20 pagesExtract, Transform and Load (Etl) Performance Improved by Query CacheannamyemNo ratings yet
- An Efficent Hybrid Optimization of ETL Process in Data Warehouse of Cloud ArchitectureDocument13 pagesAn Efficent Hybrid Optimization of ETL Process in Data Warehouse of Cloud ArchitectureRenzo HerediaNo ratings yet
- A Comparative Analysis of ETL and Hyper ETLDocument7 pagesA Comparative Analysis of ETL and Hyper ETLInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Design and Analysis of DWH and BI in Education DomDocument8 pagesDesign and Analysis of DWH and BI in Education Domsatyanarayanamurthy yerrapragadaNo ratings yet
- Enhancing Data Staging As A Mechanism For Fast Data AccessDocument9 pagesEnhancing Data Staging As A Mechanism For Fast Data AccessWho Am INo ratings yet
- Chapter 6Document45 pagesChapter 6Prudhvinadh KopparapuNo ratings yet
- Microproject On ETL Process For Data AnalyticsDocument6 pagesMicroproject On ETL Process For Data Analytics15-Sayyad Arslaan ANNo ratings yet
- 2266 ArticleText 9891 1 10 20230124Document7 pages2266 ArticleText 9891 1 10 20230124MariaNo ratings yet
- Data Integration and The Extraction, Transformation and Loading ProcessesDocument5 pagesData Integration and The Extraction, Transformation and Loading ProcessesPoet CruzNo ratings yet
- Agile ETLDocument7 pagesAgile ETLWagner TorresNo ratings yet
- Analysis and Design of ETL in Hospital Performance Appraisal SystemDocument6 pagesAnalysis and Design of ETL in Hospital Performance Appraisal SystemTushar Kant GuptaNo ratings yet
- (IJCT-V2I5P3) Author :mr. Nilesh Mali, MR - SachinBojewarDocument8 pages(IJCT-V2I5P3) Author :mr. Nilesh Mali, MR - SachinBojewarIjctJournalsNo ratings yet
- Data - Mining - and - Data by ManyindoDocument3 pagesData - Mining - and - Data by ManyindoStevenNo ratings yet
- V3i11 0016 PDFDocument9 pagesV3i11 0016 PDFPavankumar KaredlaNo ratings yet
- Experiment No. 04: Real-Life ETL CycleDocument4 pagesExperiment No. 04: Real-Life ETL Cyclesayali nazareNo ratings yet
- Designing A Data Warehouse System For Sales and Distribution CompanyDocument7 pagesDesigning A Data Warehouse System For Sales and Distribution CompanyNitin ShelkeNo ratings yet
- 3813 10753 1 PBDocument9 pages3813 10753 1 PBkhanhly80000No ratings yet
- Business Intelligence ToolsDocument16 pagesBusiness Intelligence ToolsGurdeep KaurNo ratings yet
- FPT-HandBookData Engineer (11123)Document160 pagesFPT-HandBookData Engineer (11123)Thien Ly100% (1)
- Design and Implementation of The Web (Extract, Transform, Load) Process in Data Warehouse ApplicationDocument11 pagesDesign and Implementation of The Web (Extract, Transform, Load) Process in Data Warehouse ApplicationIAES IJAINo ratings yet
- Lectura 2Document8 pagesLectura 2antonia1997No ratings yet
- Data Integration Best PracticesDocument17 pagesData Integration Best PracticesSNo ratings yet
- Heterogeneous Data Transfer and LoaderDocument3 pagesHeterogeneous Data Transfer and LoaderInternational Journal of Research in Engineering and TechnologyNo ratings yet
- Accounting Information System Discussion Notes 2Document11 pagesAccounting Information System Discussion Notes 2johnpenoniaNo ratings yet
- ETL Testing Interview Questions and AnswersDocument9 pagesETL Testing Interview Questions and AnswersKancharlaNo ratings yet
- Survey On ETL ProcessesDocument11 pagesSurvey On ETL ProcessesBruno OliveiraNo ratings yet
- To Build and Optimize ETL PipelineDocument10 pagesTo Build and Optimize ETL PipelineIJRASETPublicationsNo ratings yet
- Performance and Analyses Using Two ETL Extraction Software SolutionsDocument4 pagesPerformance and Analyses Using Two ETL Extraction Software SolutionsVanya SinghalNo ratings yet
- Reading Material Mod 4 Data Integration - Data WarehouseDocument33 pagesReading Material Mod 4 Data Integration - Data WarehousePrasad TikamNo ratings yet
- Unit 6 Data Extraction: StructureDocument24 pagesUnit 6 Data Extraction: StructuregaardiNo ratings yet
- Data Warehouse Concept and Its Usage: April 2021Document10 pagesData Warehouse Concept and Its Usage: April 2021Brij RaiNo ratings yet
- JVP 42019Document10 pagesJVP 42019dineshwar sdNo ratings yet
- System Analysis and DesignDocument24 pagesSystem Analysis and DesignNwachinaere NnamdiNo ratings yet
- An Approach of RDD Optimization in Big Data AnalytDocument9 pagesAn Approach of RDD Optimization in Big Data Analytmary maryNo ratings yet
- FGFGDocument6 pagesFGFGameenkhan64656No ratings yet
- SE TusharDocument22 pagesSE TusharShashank KumarNo ratings yet
- Data Mining - Unit 1Document45 pagesData Mining - Unit 1csumant94No ratings yet
- Business Intelligence: S.D.M College of Engineering and TechnologyDocument11 pagesBusiness Intelligence: S.D.M College of Engineering and TechnologyYilikal MengeduNo ratings yet
- A Novel Approach For Understanding Ideology Behind Managing DataDocument11 pagesA Novel Approach For Understanding Ideology Behind Managing DataGustotaNo ratings yet
- Improving System Predictability and Performance VIDocument10 pagesImproving System Predictability and Performance VIdevi noor endrawatiNo ratings yet
- Jasper Soft ETL.v4 enDocument5 pagesJasper Soft ETL.v4 enharoonobNo ratings yet
- Data Profiling ScreenDocument4 pagesData Profiling ScreenzipzapdhoomNo ratings yet
- DWM Unit-I NotesDocument10 pagesDWM Unit-I NotesAnkita PawarNo ratings yet
- Data Engineering - Beginner's GuideDocument9 pagesData Engineering - Beginner's GuideSRINIVAS RAO100% (1)
- Report 7Document39 pagesReport 7pulkit sharmaNo ratings yet
- System Analysis and DesignDocument24 pagesSystem Analysis and DesignNahar Sabirah100% (1)
- Data Warehouse & Erp: A Combined ApproachDocument3 pagesData Warehouse & Erp: A Combined ApproachvanpointNo ratings yet
- Query Optimization Based On Heuristic Rules IJERTV3IS070992Document6 pagesQuery Optimization Based On Heuristic Rules IJERTV3IS070992Nadeen AhmedNo ratings yet
- Isas Etl FinalDocument70 pagesIsas Etl FinaluoopNo ratings yet
- Utilization Extract Transform Load For DevelopingDocument9 pagesUtilization Extract Transform Load For Developingalison filgueirasNo ratings yet
- Ipl Matches DocumentationDocument28 pagesIpl Matches DocumentationNitish Kumar MohantyNo ratings yet
- The Design of The Information Hub: Denise RogersDocument4 pagesThe Design of The Information Hub: Denise RogersBalachandraKSNo ratings yet
- A Review On Python Libraries and Ides For Data Science: November 2021Document19 pagesA Review On Python Libraries and Ides For Data Science: November 20219920102030No ratings yet
- Improvement of K-Means Clustering Algorithm: March 2012Document6 pagesImprovement of K-Means Clustering Algorithm: March 2012David MorenoNo ratings yet
- MedicalDocument3 pagesMedicalddNo ratings yet
- The Challenges of Extract, Transform and Load (Etl) For Data Integration in Near Realtime EnvironmentDocument9 pagesThe Challenges of Extract, Transform and Load (Etl) For Data Integration in Near Realtime EnvironmentJJAGUILARNo ratings yet
- Fundamentals of Data Engineering: Designing and Building Scalable Data Systems for Modern ApplicationsFrom EverandFundamentals of Data Engineering: Designing and Building Scalable Data Systems for Modern ApplicationsNo ratings yet
- Formarea Diasporei ArmeneștiDocument13 pagesFormarea Diasporei ArmeneștigumenaiNo ratings yet
- Oracle® Common Application Components: API Reference Guide Release 11iDocument174 pagesOracle® Common Application Components: API Reference Guide Release 11idebasarangiNo ratings yet
- Week 2 Teradata Practice Exercises GuideDocument7 pagesWeek 2 Teradata Practice Exercises GuideFelicia Cristina Gune50% (2)
- DFD, ERD and UML DiagramsDocument32 pagesDFD, ERD and UML Diagramsroomigillani26No ratings yet
- Assignment-W11 Updated July2022Document7 pagesAssignment-W11 Updated July2022Dev Narayan KushwahaNo ratings yet
- 1.hum - Impact of Information Literacy Skills On The Academic Achievement of The StudentsDocument16 pages1.hum - Impact of Information Literacy Skills On The Academic Achievement of The StudentsImpact JournalsNo ratings yet
- Oracle Database For SAPDocument12 pagesOracle Database For SAPImtiaz AnwarNo ratings yet
- Literature Review UtsDocument4 pagesLiterature Review Utsea5zjs6a100% (1)
- Data Architecture For SAP HANADocument52 pagesData Architecture For SAP HANASepideh JaliliNo ratings yet
- Instant Download Ebook PDF Encyclopedia of Bioinformatics and Computational Biology ABC of Bioinformatics PDF ScribdDocument41 pagesInstant Download Ebook PDF Encyclopedia of Bioinformatics and Computational Biology ABC of Bioinformatics PDF Scribdhoward.linkovich475100% (53)
- SAP S/4 HANA Legacy Transfer Migration CockpitDocument13 pagesSAP S/4 HANA Legacy Transfer Migration CockpitSwapNo ratings yet
- Periodical TestDocument2 pagesPeriodical TestEvaNo ratings yet
- Access 2016 Module 1: Getting Started With Access 2016Document20 pagesAccess 2016 Module 1: Getting Started With Access 2016AndresileNo ratings yet
- APACHE REDIS Training: Trainer:David JosephDocument3 pagesAPACHE REDIS Training: Trainer:David JosephDavid JosephNo ratings yet
- Requirements For Distributed File SystemsDocument4 pagesRequirements For Distributed File SystemsmyatNo ratings yet
- Fin Irjmets1686300982Document10 pagesFin Irjmets1686300982botplusnoob97No ratings yet
- RdbmsDocument25 pagesRdbmsfarihamohammad1998No ratings yet
- Module - Ii Notes Dbms - 15Cs53 V Sem Cse/IseDocument21 pagesModule - Ii Notes Dbms - 15Cs53 V Sem Cse/IsevenkatNo ratings yet
- How To Display Costom DB View Talen Profile-1Document12 pagesHow To Display Costom DB View Talen Profile-1Sivasekar NarayananNo ratings yet
- Stakeholder QuestionnaireDocument6 pagesStakeholder QuestionnaireDeepak Daya MattaNo ratings yet
- Diccionario de Psicologia - Ander EggDocument144 pagesDiccionario de Psicologia - Ander EggFantasmita ChanNo ratings yet
- Mis Advantage and DisadvantageDocument1 pageMis Advantage and DisadvantageharrycreNo ratings yet
- Data AnalyticsDocument5 pagesData AnalyticsVivek MunjayasraNo ratings yet
- Data Mining and BIDocument4 pagesData Mining and BI20dshivanshupandeyNo ratings yet
- B Ve Inst GuideDocument134 pagesB Ve Inst GuideSAMSUNGGROUP3gmail.com DenisNo ratings yet
- Department of Computer Science and Engineering: A Mini Project ReportDocument31 pagesDepartment of Computer Science and Engineering: A Mini Project ReportBhanuranjan S BNo ratings yet