
Practise Questions
Practise Questions
You might also like
- Airline Passenger Data AnalysisDocument9 pagesAirline Passenger Data AnalysisAdeel ManafNo ratings yet
- Libro 1Document14 pagesLibro 1Victor ReyesNo ratings yet
- Iñigo Joaquin D. Relucio Activity 1 1Document2 pagesIñigo Joaquin D. Relucio Activity 1 1Iñigo Joaquin RelucioNo ratings yet
- Procesos Industriales - T4 Curva de AprendizajeDocument4 pagesProcesos Industriales - T4 Curva de AprendizajeKenneth MosqueraNo ratings yet
- Zadatak 1. - Rješenje: Od Y X Do Y XDocument21 pagesZadatak 1. - Rješenje: Od Y X Do Y XOsman BeganovićNo ratings yet
- Tugas 4 Titik Berat Dan Inersia: 1. Ac 2. CT 3. CB 4. Ic 5. ST 6. SB 7. R 2Document11 pagesTugas 4 Titik Berat Dan Inersia: 1. Ac 2. CT 3. CB 4. Ic 5. ST 6. SB 7. R 2Naufal Azmi AmrullahNo ratings yet
- SolutionsDocument2 pagesSolutionsHritik LalNo ratings yet
- Polinoame' PDFDocument3 pagesPolinoame' PDFBercea Paul CatalinNo ratings yet
- Assignment 2 - Excel ExerciseDocument8 pagesAssignment 2 - Excel ExerciseCarter A KellyNo ratings yet
- Analysis and ResultsDocument7 pagesAnalysis and ResultsBriselda BaNo ratings yet
- Python Course Cheat SheetDocument30 pagesPython Course Cheat SheetVinayNo ratings yet
- Comp 328 - Research MethodsDocument6 pagesComp 328 - Research Methodsongeragodfrey254No ratings yet
- StatsDocument9 pagesStatsعلی رضاNo ratings yet
- Comp 328 - Research MethodsDocument5 pagesComp 328 - Research Methodsongeragodfrey254No ratings yet
- MEProject 11Document25 pagesMEProject 11Kumar GauravNo ratings yet
- Data AnalysisDocument9 pagesData Analysissalekeen sakibNo ratings yet
- Soal PTK Par 2016Document6 pagesSoal PTK Par 2016Anton PrayogaNo ratings yet
- Presupuesto de Ventas Varios ProductosDocument9 pagesPresupuesto de Ventas Varios ProductosEvilLordMuMexNo ratings yet
- 01.WBLFF & BasementDocument92 pages01.WBLFF & Basementbuloque 86No ratings yet
- TrayDocument66 pagesTraydesignbylilacNo ratings yet
- Lecture 5Document14 pagesLecture 5Waseem AbbasNo ratings yet
- AGB 321 Agribusiness Managerial Economics - Assignment Oct 2023Document6 pagesAGB 321 Agribusiness Managerial Economics - Assignment Oct 2023covertessaysNo ratings yet
- Republican Democrat Independent Total Men Women Total Fij Efij (Fij-Efij) 2/efijDocument5 pagesRepublican Democrat Independent Total Men Women Total Fij Efij (Fij-Efij) 2/efijmohitvyas972No ratings yet
- Fluid Assignment 2016Document8 pagesFluid Assignment 2016TlhologeloNo ratings yet
- My Smart Book of Math 3Document15 pagesMy Smart Book of Math 3sumbul memonNo ratings yet
- Exp 4Document9 pagesExp 4Supriyo DNo ratings yet
- University of Jordan School of Engineering Department of Mechanical Engineering Mechanical Vibrations Lab Mass-Spring SystemDocument9 pagesUniversity of Jordan School of Engineering Department of Mechanical Engineering Mechanical Vibrations Lab Mass-Spring Systemmazen ashaNo ratings yet
- Informe de LaboratorioDocument12 pagesInforme de Laboratorioana palaciosNo ratings yet
- Individual Assignment 2: Harvested Area Production of Dry Cocoa (Hectare) (Tonne)Document4 pagesIndividual Assignment 2: Harvested Area Production of Dry Cocoa (Hectare) (Tonne)raanNo ratings yet
- Acceleration of a geared system experiment: ω (j) / ω (i) = t (i) / t (j)Document11 pagesAcceleration of a geared system experiment: ω (j) / ω (i) = t (i) / t (j)jihad hasanNo ratings yet
- Frictional Loss in Straight Pipe - 14-21Document8 pagesFrictional Loss in Straight Pipe - 14-21musarrat.halim99No ratings yet
- Time Series: Y 1, B (Y 2-Y 1) /NDocument5 pagesTime Series: Y 1, B (Y 2-Y 1) /Nwijanaimade8753No ratings yet
- FIZ2Document10 pagesFIZ2Andreea RaduNo ratings yet
- Title: Particle Size Analysis Via Mechanical Sieve: CEE 346L - Geotechnical Engineering I LabDocument6 pagesTitle: Particle Size Analysis Via Mechanical Sieve: CEE 346L - Geotechnical Engineering I LabAbhishek RayNo ratings yet
- Book1 PresentasiDocument6 pagesBook1 PresentasiMiming SuryaniNo ratings yet
- Log (T-To) Γ Τ Logγ: 0 10400 15 12650 50 17800 100 25010 150 28990 270 37000 (S) (Mpa) (S)Document2 pagesLog (T-To) Γ Τ Logγ: 0 10400 15 12650 50 17800 100 25010 150 28990 270 37000 (S) (Mpa) (S)Brando Kevin Palomino MorenoNo ratings yet
- GRAVEDADDocument3 pagesGRAVEDADVictor MarroquinNo ratings yet
- Calculo DiferencialDocument6 pagesCalculo DiferencialOscarBenavidesNo ratings yet
- SAMPLE EXAM QUESTIONS #2 1. in A Time-Series Forecasting ProblemDocument3 pagesSAMPLE EXAM QUESTIONS #2 1. in A Time-Series Forecasting Problemapi-2588840486% (7)
- Chapter 9: Tutorial 1 Midpoint and Trapezoid RulesDocument6 pagesChapter 9: Tutorial 1 Midpoint and Trapezoid RulesAhmed AliNo ratings yet
- Activity 4. RegressionDocument12 pagesActivity 4. RegressionJuliet RosarioNo ratings yet
- Yarmouk University Civil Engineering Department Fluid Mechanics and Hydraulic Laboratory CE 354Document10 pagesYarmouk University Civil Engineering Department Fluid Mechanics and Hydraulic Laboratory CE 354Mohammed MigdadyNo ratings yet
- Tercer Metodo: Curva Exponencial IDocument11 pagesTercer Metodo: Curva Exponencial Idavid calle alamoNo ratings yet
- Weibull FinalDocument10 pagesWeibull FinalJorge Paul Ortiz NuñezNo ratings yet
- Thermo TD 2Document2 pagesThermo TD 2Brahim ABAGHOUGHNo ratings yet
- CLASE5Document6 pagesCLASE5Tania MorenoNo ratings yet
- VND - Openxmlformats Officedocument - Spreadsheetml.sheet&rendition 1Document12 pagesVND - Openxmlformats Officedocument - Spreadsheetml.sheet&rendition 1patilom0009No ratings yet
- Chapter 3 Answers To Assigned Supplementary ProblemsDocument8 pagesChapter 3 Answers To Assigned Supplementary Problemswife_of_itachiNo ratings yet
- Caculation Lab5Document8 pagesCaculation Lab5AriffDyamimNo ratings yet
- Polynomial RegressionDocument5 pagesPolynomial RegressionAhmed IsmailNo ratings yet
- Stud Bolts DIN 976-1: 2002-12: 1. ScopeDocument6 pagesStud Bolts DIN 976-1: 2002-12: 1. ScopejayNo ratings yet
- Task DescriptionDocument6 pagesTask DescriptionSulman ShahzadNo ratings yet
- GraficasDocument2 pagesGraficasKathe Faustino MolinaNo ratings yet
- Exercises On ELECTRICAL MACHINESDocument29 pagesExercises On ELECTRICAL MACHINESDavide100% (1)
- DSSDSDSDDocument4 pagesDSSDSDSDLenin Arnold Reyes SalvatierraNo ratings yet
- HW Week 8 NBDocument14 pagesHW Week 8 NBUrsula TrigosNo ratings yet
- Mlr-Ii Practical 4.3Document3 pagesMlr-Ii Practical 4.3Pooja ChauhanNo ratings yet
- Jupyter Notebook Yardlenis Sánchez Act2Document1 pageJupyter Notebook Yardlenis Sánchez Act2NASLYNo ratings yet
- Uber AnalysisDocument11 pagesUber AnalysisshilpaNo ratings yet
- Bagged Decision TreeDocument1 pageBagged Decision TreeshilpaNo ratings yet
- SITHCCC038 - V1.0 - Student Assessment Tools.v1.0Document22 pagesSITHCCC038 - V1.0 - Student Assessment Tools.v1.0shilpaNo ratings yet
- Neetu PaperDocument2 pagesNeetu PapershilpaNo ratings yet
- CSR ReportDocument2 pagesCSR ReportshilpaNo ratings yet
- NanomedicineDocument10 pagesNanomedicineshilpaNo ratings yet
- SIT30821 - SITHCCC037 - V1.0 - Student Assessment.v1.0Document28 pagesSIT30821 - SITHCCC037 - V1.0 - Student Assessment.v1.0shilpaNo ratings yet
- ChatbotDocument3 pagesChatbotshilpaNo ratings yet
- SIT30821 - SITHKOP015 - V1.0 - Standard Recipe Card SRC Template.v1.0Document2 pagesSIT30821 - SITHKOP015 - V1.0 - Standard Recipe Card SRC Template.v1.0shilpaNo ratings yet
- PCA FileDocument7 pagesPCA FileshilpaNo ratings yet
- 5 THDocument22 pages5 THshilpaNo ratings yet
- A Design of Single Axis Sun Tracking System: July 2011Document5 pagesA Design of Single Axis Sun Tracking System: July 2011shilpaNo ratings yet
- A Survey of Named Entity Recognition TechniquesDocument8 pagesA Survey of Named Entity Recognition TechniquesshilpaNo ratings yet
- Sarkar, Dipayan. - Natarajan, Vijayalakshmi. - Ensemble Machine Learning Cookbook-Packt Publishing (2019)Document476 pagesSarkar, Dipayan. - Natarajan, Vijayalakshmi. - Ensemble Machine Learning Cookbook-Packt Publishing (2019)omegapoint077609100% (2)
- DSBDA Lab ManualDocument155 pagesDSBDA Lab ManualNeha KardileNo ratings yet
- Deep Learning-Based Modeling of Second-Hand Ship Prices in South KoreaDocument9 pagesDeep Learning-Based Modeling of Second-Hand Ship Prices in South KoreaIAES IJAINo ratings yet
- CS 461 - Fall 2021 - Neural Networks - Machine LearningDocument5 pagesCS 461 - Fall 2021 - Neural Networks - Machine LearningVictor RutoNo ratings yet
- Python Sklearn Linear RegressionDocument45 pagesPython Sklearn Linear RegressionSurya Pranav AnnadanamNo ratings yet
- Internship Report Sakshi BarapatreDocument36 pagesInternship Report Sakshi BarapatreSakshi BarapatreNo ratings yet
- P04 The Regression Pipeline - Preprocessing AnsDocument19 pagesP04 The Regression Pipeline - Preprocessing AnsYONG LONG KHAWNo ratings yet
- Verilog FAQ Interview QuestionsDocument11 pagesVerilog FAQ Interview QuestionsputhalapattupavansaiNo ratings yet
- Data Preparation For Machine Learning Mini CourseDocument19 pagesData Preparation For Machine Learning Mini CourseLavanya EaswarNo ratings yet
- Lecture 05: Feature Engineering: Ms. Mehroz SadiqDocument69 pagesLecture 05: Feature Engineering: Ms. Mehroz SadiquxamaNo ratings yet
- Machine Learning Pipeline: Created by Arbaz AliDocument32 pagesMachine Learning Pipeline: Created by Arbaz AliGeorge IskanderNo ratings yet
- BA Sakip SulejmaniDocument52 pagesBA Sakip Sulejmanibadasahirpesaj0906No ratings yet
- BA Project - Team17Document13 pagesBA Project - Team17Jyotirmaya MohapatraNo ratings yet
- Lab Assignment 1 Title: Data Wrangling I: Problem StatementDocument12 pagesLab Assignment 1 Title: Data Wrangling I: Problem StatementMr. LegendpersonNo ratings yet
- What - Why: Dummy VariablesDocument4 pagesWhat - Why: Dummy VariablesNaing NaingNo ratings yet
- Word 2 VecDocument6 pagesWord 2 Vecalihamda535No ratings yet
- Flipkart Training: Exploratory Data AnalysisDocument9 pagesFlipkart Training: Exploratory Data AnalysisHPot PotTechNo ratings yet
- Chatbot IRJET-V8I4626Document8 pagesChatbot IRJET-V8I4626AJITH KUMAR GNo ratings yet
- 8 Ejercicio - Optimización y Guardado de Modelos - Training - Microsoft Learn InglesDocument13 pages8 Ejercicio - Optimización y Guardado de Modelos - Training - Microsoft Learn Inglesacxel david castillo casasNo ratings yet
- Dsbda Lab ManualDocument167 pagesDsbda Lab Manualsm3815749No ratings yet
- Hyp DataDocument3 pagesHyp DataSubhaNo ratings yet
- DS&BD Lab ManulDocument98 pagesDS&BD Lab ManulAjeet GuptaNo ratings yet
- Data Pre ProcessingDocument2 pagesData Pre Processingrk73462002No ratings yet
- Word Embeddings NotesDocument9 pagesWord Embeddings NotesAbhimanyuNo ratings yet
- D P Lab ManualDocument54 pagesD P Lab Manualsanketwakde100No ratings yet
- One-Hot Encoded Finite State MachinesDocument27 pagesOne-Hot Encoded Finite State MachinesmahdichiNo ratings yet
- Week #6 - Verilog Behavioural Modeling (Part 4) FSMDocument21 pagesWeek #6 - Verilog Behavioural Modeling (Part 4) FSMKhayrinNajmiNo ratings yet
- StarterNotebook - Jupyter NotebookDocument12 pagesStarterNotebook - Jupyter NotebookTosin GeorgeNo ratings yet
- Feature EngineeringDocument43 pagesFeature EngineeringAnjali AgarwalNo ratings yet




























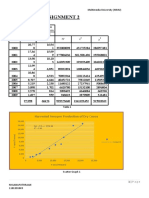















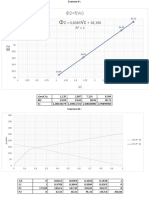







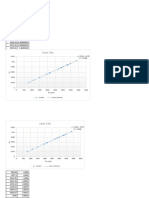


















































Download as docx, pdf, or txt
You might also like
- Airline Passenger Data AnalysisDocument9 pagesAirline Passenger Data AnalysisAdeel ManafNo ratings yet
- Libro 1Document14 pagesLibro 1Victor ReyesNo ratings yet
- Iñigo Joaquin D. Relucio Activity 1 1Document2 pagesIñigo Joaquin D. Relucio Activity 1 1Iñigo Joaquin RelucioNo ratings yet
- Procesos Industriales - T4 Curva de AprendizajeDocument4 pagesProcesos Industriales - T4 Curva de AprendizajeKenneth MosqueraNo ratings yet
- Zadatak 1. - Rješenje: Od Y X Do Y XDocument21 pagesZadatak 1. - Rješenje: Od Y X Do Y XOsman BeganovićNo ratings yet
- Tugas 4 Titik Berat Dan Inersia: 1. Ac 2. CT 3. CB 4. Ic 5. ST 6. SB 7. R 2Document11 pagesTugas 4 Titik Berat Dan Inersia: 1. Ac 2. CT 3. CB 4. Ic 5. ST 6. SB 7. R 2Naufal Azmi AmrullahNo ratings yet
- SolutionsDocument2 pagesSolutionsHritik LalNo ratings yet
- Polinoame' PDFDocument3 pagesPolinoame' PDFBercea Paul CatalinNo ratings yet
- Assignment 2 - Excel ExerciseDocument8 pagesAssignment 2 - Excel ExerciseCarter A KellyNo ratings yet
- Analysis and ResultsDocument7 pagesAnalysis and ResultsBriselda BaNo ratings yet
- Python Course Cheat SheetDocument30 pagesPython Course Cheat SheetVinayNo ratings yet
- Comp 328 - Research MethodsDocument6 pagesComp 328 - Research Methodsongeragodfrey254No ratings yet
- StatsDocument9 pagesStatsعلی رضاNo ratings yet
- Comp 328 - Research MethodsDocument5 pagesComp 328 - Research Methodsongeragodfrey254No ratings yet
- MEProject 11Document25 pagesMEProject 11Kumar GauravNo ratings yet
- Data AnalysisDocument9 pagesData Analysissalekeen sakibNo ratings yet
- Soal PTK Par 2016Document6 pagesSoal PTK Par 2016Anton PrayogaNo ratings yet
- Presupuesto de Ventas Varios ProductosDocument9 pagesPresupuesto de Ventas Varios ProductosEvilLordMuMexNo ratings yet
- 01.WBLFF & BasementDocument92 pages01.WBLFF & Basementbuloque 86No ratings yet
- TrayDocument66 pagesTraydesignbylilacNo ratings yet
- Lecture 5Document14 pagesLecture 5Waseem AbbasNo ratings yet
- AGB 321 Agribusiness Managerial Economics - Assignment Oct 2023Document6 pagesAGB 321 Agribusiness Managerial Economics - Assignment Oct 2023covertessaysNo ratings yet
- Republican Democrat Independent Total Men Women Total Fij Efij (Fij-Efij) 2/efijDocument5 pagesRepublican Democrat Independent Total Men Women Total Fij Efij (Fij-Efij) 2/efijmohitvyas972No ratings yet
- Fluid Assignment 2016Document8 pagesFluid Assignment 2016TlhologeloNo ratings yet
- My Smart Book of Math 3Document15 pagesMy Smart Book of Math 3sumbul memonNo ratings yet
- Exp 4Document9 pagesExp 4Supriyo DNo ratings yet
- University of Jordan School of Engineering Department of Mechanical Engineering Mechanical Vibrations Lab Mass-Spring SystemDocument9 pagesUniversity of Jordan School of Engineering Department of Mechanical Engineering Mechanical Vibrations Lab Mass-Spring Systemmazen ashaNo ratings yet
- Informe de LaboratorioDocument12 pagesInforme de Laboratorioana palaciosNo ratings yet
- Individual Assignment 2: Harvested Area Production of Dry Cocoa (Hectare) (Tonne)Document4 pagesIndividual Assignment 2: Harvested Area Production of Dry Cocoa (Hectare) (Tonne)raanNo ratings yet
- Acceleration of a geared system experiment: ω (j) / ω (i) = t (i) / t (j)Document11 pagesAcceleration of a geared system experiment: ω (j) / ω (i) = t (i) / t (j)jihad hasanNo ratings yet
- Frictional Loss in Straight Pipe - 14-21Document8 pagesFrictional Loss in Straight Pipe - 14-21musarrat.halim99No ratings yet
- Time Series: Y 1, B (Y 2-Y 1) /NDocument5 pagesTime Series: Y 1, B (Y 2-Y 1) /Nwijanaimade8753No ratings yet
- FIZ2Document10 pagesFIZ2Andreea RaduNo ratings yet
- Title: Particle Size Analysis Via Mechanical Sieve: CEE 346L - Geotechnical Engineering I LabDocument6 pagesTitle: Particle Size Analysis Via Mechanical Sieve: CEE 346L - Geotechnical Engineering I LabAbhishek RayNo ratings yet
- Book1 PresentasiDocument6 pagesBook1 PresentasiMiming SuryaniNo ratings yet
- Log (T-To) Γ Τ Logγ: 0 10400 15 12650 50 17800 100 25010 150 28990 270 37000 (S) (Mpa) (S)Document2 pagesLog (T-To) Γ Τ Logγ: 0 10400 15 12650 50 17800 100 25010 150 28990 270 37000 (S) (Mpa) (S)Brando Kevin Palomino MorenoNo ratings yet
- GRAVEDADDocument3 pagesGRAVEDADVictor MarroquinNo ratings yet
- Calculo DiferencialDocument6 pagesCalculo DiferencialOscarBenavidesNo ratings yet
- SAMPLE EXAM QUESTIONS #2 1. in A Time-Series Forecasting ProblemDocument3 pagesSAMPLE EXAM QUESTIONS #2 1. in A Time-Series Forecasting Problemapi-2588840486% (7)
- Chapter 9: Tutorial 1 Midpoint and Trapezoid RulesDocument6 pagesChapter 9: Tutorial 1 Midpoint and Trapezoid RulesAhmed AliNo ratings yet
- Activity 4. RegressionDocument12 pagesActivity 4. RegressionJuliet RosarioNo ratings yet
- Yarmouk University Civil Engineering Department Fluid Mechanics and Hydraulic Laboratory CE 354Document10 pagesYarmouk University Civil Engineering Department Fluid Mechanics and Hydraulic Laboratory CE 354Mohammed MigdadyNo ratings yet
- Tercer Metodo: Curva Exponencial IDocument11 pagesTercer Metodo: Curva Exponencial Idavid calle alamoNo ratings yet
- Weibull FinalDocument10 pagesWeibull FinalJorge Paul Ortiz NuñezNo ratings yet
- Thermo TD 2Document2 pagesThermo TD 2Brahim ABAGHOUGHNo ratings yet
- CLASE5Document6 pagesCLASE5Tania MorenoNo ratings yet
- VND - Openxmlformats Officedocument - Spreadsheetml.sheet&rendition 1Document12 pagesVND - Openxmlformats Officedocument - Spreadsheetml.sheet&rendition 1patilom0009No ratings yet
- Chapter 3 Answers To Assigned Supplementary ProblemsDocument8 pagesChapter 3 Answers To Assigned Supplementary Problemswife_of_itachiNo ratings yet
- Caculation Lab5Document8 pagesCaculation Lab5AriffDyamimNo ratings yet
- Polynomial RegressionDocument5 pagesPolynomial RegressionAhmed IsmailNo ratings yet
- Stud Bolts DIN 976-1: 2002-12: 1. ScopeDocument6 pagesStud Bolts DIN 976-1: 2002-12: 1. ScopejayNo ratings yet
- Task DescriptionDocument6 pagesTask DescriptionSulman ShahzadNo ratings yet
- GraficasDocument2 pagesGraficasKathe Faustino MolinaNo ratings yet
- Exercises On ELECTRICAL MACHINESDocument29 pagesExercises On ELECTRICAL MACHINESDavide100% (1)
- DSSDSDSDDocument4 pagesDSSDSDSDLenin Arnold Reyes SalvatierraNo ratings yet
- HW Week 8 NBDocument14 pagesHW Week 8 NBUrsula TrigosNo ratings yet
- Mlr-Ii Practical 4.3Document3 pagesMlr-Ii Practical 4.3Pooja ChauhanNo ratings yet
- Jupyter Notebook Yardlenis Sánchez Act2Document1 pageJupyter Notebook Yardlenis Sánchez Act2NASLYNo ratings yet
- Uber AnalysisDocument11 pagesUber AnalysisshilpaNo ratings yet
- Bagged Decision TreeDocument1 pageBagged Decision TreeshilpaNo ratings yet
- SITHCCC038 - V1.0 - Student Assessment Tools.v1.0Document22 pagesSITHCCC038 - V1.0 - Student Assessment Tools.v1.0shilpaNo ratings yet
- Neetu PaperDocument2 pagesNeetu PapershilpaNo ratings yet
- CSR ReportDocument2 pagesCSR ReportshilpaNo ratings yet
- NanomedicineDocument10 pagesNanomedicineshilpaNo ratings yet
- SIT30821 - SITHCCC037 - V1.0 - Student Assessment.v1.0Document28 pagesSIT30821 - SITHCCC037 - V1.0 - Student Assessment.v1.0shilpaNo ratings yet
- ChatbotDocument3 pagesChatbotshilpaNo ratings yet
- SIT30821 - SITHKOP015 - V1.0 - Standard Recipe Card SRC Template.v1.0Document2 pagesSIT30821 - SITHKOP015 - V1.0 - Standard Recipe Card SRC Template.v1.0shilpaNo ratings yet
- PCA FileDocument7 pagesPCA FileshilpaNo ratings yet
- 5 THDocument22 pages5 THshilpaNo ratings yet
- A Design of Single Axis Sun Tracking System: July 2011Document5 pagesA Design of Single Axis Sun Tracking System: July 2011shilpaNo ratings yet
- A Survey of Named Entity Recognition TechniquesDocument8 pagesA Survey of Named Entity Recognition TechniquesshilpaNo ratings yet
- Sarkar, Dipayan. - Natarajan, Vijayalakshmi. - Ensemble Machine Learning Cookbook-Packt Publishing (2019)Document476 pagesSarkar, Dipayan. - Natarajan, Vijayalakshmi. - Ensemble Machine Learning Cookbook-Packt Publishing (2019)omegapoint077609100% (2)
- DSBDA Lab ManualDocument155 pagesDSBDA Lab ManualNeha KardileNo ratings yet
- Deep Learning-Based Modeling of Second-Hand Ship Prices in South KoreaDocument9 pagesDeep Learning-Based Modeling of Second-Hand Ship Prices in South KoreaIAES IJAINo ratings yet
- CS 461 - Fall 2021 - Neural Networks - Machine LearningDocument5 pagesCS 461 - Fall 2021 - Neural Networks - Machine LearningVictor RutoNo ratings yet
- Python Sklearn Linear RegressionDocument45 pagesPython Sklearn Linear RegressionSurya Pranav AnnadanamNo ratings yet
- Internship Report Sakshi BarapatreDocument36 pagesInternship Report Sakshi BarapatreSakshi BarapatreNo ratings yet
- P04 The Regression Pipeline - Preprocessing AnsDocument19 pagesP04 The Regression Pipeline - Preprocessing AnsYONG LONG KHAWNo ratings yet
- Verilog FAQ Interview QuestionsDocument11 pagesVerilog FAQ Interview QuestionsputhalapattupavansaiNo ratings yet
- Data Preparation For Machine Learning Mini CourseDocument19 pagesData Preparation For Machine Learning Mini CourseLavanya EaswarNo ratings yet
- Lecture 05: Feature Engineering: Ms. Mehroz SadiqDocument69 pagesLecture 05: Feature Engineering: Ms. Mehroz SadiquxamaNo ratings yet
- Machine Learning Pipeline: Created by Arbaz AliDocument32 pagesMachine Learning Pipeline: Created by Arbaz AliGeorge IskanderNo ratings yet
- BA Sakip SulejmaniDocument52 pagesBA Sakip Sulejmanibadasahirpesaj0906No ratings yet
- BA Project - Team17Document13 pagesBA Project - Team17Jyotirmaya MohapatraNo ratings yet
- Lab Assignment 1 Title: Data Wrangling I: Problem StatementDocument12 pagesLab Assignment 1 Title: Data Wrangling I: Problem StatementMr. LegendpersonNo ratings yet
- What - Why: Dummy VariablesDocument4 pagesWhat - Why: Dummy VariablesNaing NaingNo ratings yet
- Word 2 VecDocument6 pagesWord 2 Vecalihamda535No ratings yet
- Flipkart Training: Exploratory Data AnalysisDocument9 pagesFlipkart Training: Exploratory Data AnalysisHPot PotTechNo ratings yet
- Chatbot IRJET-V8I4626Document8 pagesChatbot IRJET-V8I4626AJITH KUMAR GNo ratings yet
- 8 Ejercicio - Optimización y Guardado de Modelos - Training - Microsoft Learn InglesDocument13 pages8 Ejercicio - Optimización y Guardado de Modelos - Training - Microsoft Learn Inglesacxel david castillo casasNo ratings yet
- Dsbda Lab ManualDocument167 pagesDsbda Lab Manualsm3815749No ratings yet
- Hyp DataDocument3 pagesHyp DataSubhaNo ratings yet
- DS&BD Lab ManulDocument98 pagesDS&BD Lab ManulAjeet GuptaNo ratings yet
- Data Pre ProcessingDocument2 pagesData Pre Processingrk73462002No ratings yet
- Word Embeddings NotesDocument9 pagesWord Embeddings NotesAbhimanyuNo ratings yet
- D P Lab ManualDocument54 pagesD P Lab Manualsanketwakde100No ratings yet
- One-Hot Encoded Finite State MachinesDocument27 pagesOne-Hot Encoded Finite State MachinesmahdichiNo ratings yet
- Week #6 - Verilog Behavioural Modeling (Part 4) FSMDocument21 pagesWeek #6 - Verilog Behavioural Modeling (Part 4) FSMKhayrinNajmiNo ratings yet
- StarterNotebook - Jupyter NotebookDocument12 pagesStarterNotebook - Jupyter NotebookTosin GeorgeNo ratings yet
- Feature EngineeringDocument43 pagesFeature EngineeringAnjali AgarwalNo ratings yet