Download as pdf or txt
You might also like
- (Machine Learning Mastery) Jason Brownlee - Statistical Methods For Machine LearningDocument291 pages(Machine Learning Mastery) Jason Brownlee - Statistical Methods For Machine LearningNitin Dahiya87% (15)
- Biostatistics and Research MethodsDocument2 pagesBiostatistics and Research MethodsOsama Javed100% (1)
- Gutierrez 2002 Parametric Frailty and Shared Frailty Survival ModelsDocument23 pagesGutierrez 2002 Parametric Frailty and Shared Frailty Survival Modelsauto.change.nameNo ratings yet
- Frailty Models FinalDocument5 pagesFrailty Models Finalsarathkumar sebastinNo ratings yet
- Nadin 2017Document45 pagesNadin 2017baky traorrNo ratings yet
- A Simulation Study of A Parametric Mixture Model of Three Different Distributions To Anlayze Heterogeneous Survival DataDocument9 pagesA Simulation Study of A Parametric Mixture Model of Three Different Distributions To Anlayze Heterogeneous Survival DatatempNo ratings yet
- Bayesian Analysis: of Mixed Survival ModelstDocument25 pagesBayesian Analysis: of Mixed Survival ModelstY YNo ratings yet
- Hindrances Bistable FrontDocument33 pagesHindrances Bistable Frontbaky traorrNo ratings yet
- Part 3Document22 pagesPart 3Lo SimonNo ratings yet
- Bayesian Latent Variable Models For Mixed Discrete OutcomesDocument15 pagesBayesian Latent Variable Models For Mixed Discrete OutcomesAnonymous 4gOYyVfdfNo ratings yet
- Timevarying in RDocument10 pagesTimevarying in RAldo BraidaNo ratings yet
- A Tutorial On Frailty ModelsDocument31 pagesA Tutorial On Frailty Modelss2126002No ratings yet
- Chaos, Solitons and Fractals: Xiaosong Tang, Yongli SongDocument12 pagesChaos, Solitons and Fractals: Xiaosong Tang, Yongli SongNur Suci RamadhaniNo ratings yet
- A Compounded Probability Model For Decreasing Hazard and Its Inferential PropertiesDocument16 pagesA Compounded Probability Model For Decreasing Hazard and Its Inferential PropertiesLiban Ali MohamudNo ratings yet
- Dissertation Cox RegressionDocument5 pagesDissertation Cox RegressionWhitePaperWritingServicesCanada100% (1)
- 1986 - Random Walk Models of MovementDocument6 pages1986 - Random Walk Models of MovementmarioNo ratings yet
- Counter Examples in ProbabilityDocument12 pagesCounter Examples in ProbabilityRemi A. SamadNo ratings yet
- Uncertainty in Counts and Operationg Time For Poisson RatesDocument5 pagesUncertainty in Counts and Operationg Time For Poisson RatesHelton SantanaNo ratings yet
- Rcihards 1993 Spurius CorrelationDocument14 pagesRcihards 1993 Spurius CorrelationFlorencia StelzerNo ratings yet
- Keogh Et Al 2018 BiometricsDocument12 pagesKeogh Et Al 2018 BiometricsPanagiotis KarathymiosNo ratings yet
- Gamma and Inverse Gaussian Frailty Models: A Comparative StudyDocument5 pagesGamma and Inverse Gaussian Frailty Models: A Comparative StudyinventionjournalsNo ratings yet
- Discrete Bilal Distribution With Right-Censored DaDocument20 pagesDiscrete Bilal Distribution With Right-Censored DaAtif AvdovićNo ratings yet
- Oxford Three NotesDocument40 pagesOxford Three NotesBIRUKNo ratings yet
- On The Critical Behavior of The General Epidemic Process and Dynamical PercolationDocument16 pagesOn The Critical Behavior of The General Epidemic Process and Dynamical PercolationlealmiNo ratings yet
- Using The Gibbs Sampler For Conditional Simulation of Gaussian-Based Random FieldsDocument16 pagesUsing The Gibbs Sampler For Conditional Simulation of Gaussian-Based Random FieldshaibinbnNo ratings yet
- Wald Tests When Restrictions Are Locally SingularDocument48 pagesWald Tests When Restrictions Are Locally SingularMasudul ICNo ratings yet
- Bivariate Poissson CountDocument18 pagesBivariate Poissson Countray raylandeNo ratings yet
- Time-To-Event Prediction With Neural Networks and Cox RegressionDocument30 pagesTime-To-Event Prediction With Neural Networks and Cox RegressionCristóbal Miño MoralesNo ratings yet
- Nardi Et Al-2003-Statistics in MedicineDocument14 pagesNardi Et Al-2003-Statistics in MedicineThomas MpherwaneNo ratings yet
- Testing For Correlation in The Presence of Spatial Autocorrelation in Insect Count DataDocument8 pagesTesting For Correlation in The Presence of Spatial Autocorrelation in Insect Count DataSimson MuliaNo ratings yet
- Assessing Microdata Disclosure Risk Using The Poisson-Inverse Gaussian DistributionDocument16 pagesAssessing Microdata Disclosure Risk Using The Poisson-Inverse Gaussian DistributionAnbumani BalakrishnanNo ratings yet
- AppendixDocument12 pagesAppendixbewareofdwarvesNo ratings yet
- Total CorrelationDocument3 pagesTotal Correlationdev414No ratings yet
- Appendix Cox RegressionDocument19 pagesAppendix Cox RegressionJuan Carlos Lopez MesaNo ratings yet
- PaperSubmit FinDocument19 pagesPaperSubmit Finhemanta.saikiaNo ratings yet
- Multiple Stages PDFDocument43 pagesMultiple Stages PDFKenneth Emeka OnumaNo ratings yet
- The Stochastic ModelDocument5 pagesThe Stochastic ModelBoffin Access LimitedNo ratings yet
- Survival Analysis Using Split Plot in Time Models: Omar Hikmat Abdulla, Khawla Mustafa SadikDocument4 pagesSurvival Analysis Using Split Plot in Time Models: Omar Hikmat Abdulla, Khawla Mustafa SadikInternational Journal of Engineering Inventions (IJEI)No ratings yet
- Reference 46Document12 pagesReference 46deepNo ratings yet
- TMP CEEADocument54 pagesTMP CEEAFrontiersNo ratings yet
- Polyhazard Models For Lifetime DataDocument15 pagesPolyhazard Models For Lifetime Datacuentaapps1234No ratings yet
- Howard (Howie) Weiss: Sir Ronald RossDocument17 pagesHoward (Howie) Weiss: Sir Ronald RossFdWork0% (1)
- Process Leading To Quasi-Fixation of Genes in Natural Populations Due To Random Fluctuation of Selection IntensitiesDocument16 pagesProcess Leading To Quasi-Fixation of Genes in Natural Populations Due To Random Fluctuation of Selection IntensitiesMarcelino SoteloNo ratings yet
- Tweedie DistributionDocument16 pagesTweedie Distributionkeisha555No ratings yet
- Patil Biometrics 1978Document11 pagesPatil Biometrics 1978Feñita Isabêl Arce NuñezNo ratings yet
- Median Absolute DeviationDocument4 pagesMedian Absolute DeviationSimone WeillNo ratings yet
- 12 Stability - Analysis - of - A - Host - Parasite - ModelDocument8 pages12 Stability - Analysis - of - A - Host - Parasite - Modelppg.lidyaayu00330No ratings yet
- Emation of Survival Based On Proportional Hazards When Cure Is A Possibility-A - TSODIKOV - 2001Document10 pagesEmation of Survival Based On Proportional Hazards When Cure Is A Possibility-A - TSODIKOV - 2001Ali HamliliNo ratings yet
- Appendix Cox RegressionDocument20 pagesAppendix Cox RegressionAnonymous gUySMcpSqNo ratings yet
- ARTICLE 3, Vol 1, No 3, Central Limit Theorem and Its ApplicationsDocument12 pagesARTICLE 3, Vol 1, No 3, Central Limit Theorem and Its ApplicationsJoséNo ratings yet
- Cox Regression ThesisDocument6 pagesCox Regression ThesisHowToFindSomeoneToWriteMyPaperSalem100% (2)
- (Bagdonavicius V.) Analysis of Survival Data WithDocument11 pages(Bagdonavicius V.) Analysis of Survival Data WithVerónica NaviaNo ratings yet
- Interacting Fisher (Wright Diusions in A Catalytic MediumDocument28 pagesInteracting Fisher (Wright Diusions in A Catalytic Mediumaliveli49501981No ratings yet
- Ecological-Niche Factor Analysis: How To Compute Habitat-Suitability Maps Without Absence Data?Document10 pagesEcological-Niche Factor Analysis: How To Compute Habitat-Suitability Maps Without Absence Data?Ahmad Zainul HasanNo ratings yet
- Xue Kunsong2000 PDFDocument16 pagesXue Kunsong2000 PDFhwNo ratings yet
- B. Hall Intro To Frailty ModelsDocument13 pagesB. Hall Intro To Frailty ModelsRoxanne CaruanaNo ratings yet
- Pnas 2007 Gerrish 6266 71Document6 pagesPnas 2007 Gerrish 6266 71api-211640838No ratings yet
- Cure Rate ModelDocument10 pagesCure Rate Modelcarlton smithNo ratings yet
- PSYCHOMETRIKA - VOL. 58, NO. 2, 315-330 JUNE 1993: Yijk Dijk Wit (X# - XKR) 2Document16 pagesPSYCHOMETRIKA - VOL. 58, NO. 2, 315-330 JUNE 1993: Yijk Dijk Wit (X# - XKR) 2Mariya PavlovaNo ratings yet
- The Biostatistics of Aging: From Gompertzian Mortality to an Index of Aging-RelatednessFrom EverandThe Biostatistics of Aging: From Gompertzian Mortality to an Index of Aging-RelatednessNo ratings yet
- 1 s2.0 S0047259X09001493 MainDocument9 pages1 s2.0 S0047259X09001493 Mainwill bNo ratings yet
- Final CH 7 InstrDocument320 pagesFinal CH 7 Instrwill bNo ratings yet
- Proving Areaof Triangle Using SeriesDocument9 pagesProving Areaof Triangle Using Serieswill bNo ratings yet
- General Study On Two-Dimensional Generalized Arithmetic ProgressionDocument13 pagesGeneral Study On Two-Dimensional Generalized Arithmetic Progressionwill bNo ratings yet
- Second Hhree Weeks Ap Review KeysDocument66 pagesSecond Hhree Weeks Ap Review Keyswill bNo ratings yet
- 1 s2.0 S0022247X12004787 MainDocument11 pages1 s2.0 S0022247X12004787 Mainwill bNo ratings yet
- 2 Flows Without Inertia: I I J IjDocument19 pages2 Flows Without Inertia: I I J Ijwill bNo ratings yet
- 2012SCIMAGArith GeoDocument137 pages2012SCIMAGArith Geowill bNo ratings yet
- Exploring Progressions: A Collection of Problems: ArticleDocument61 pagesExploring Progressions: A Collection of Problems: Articlewill bNo ratings yet
- Sum of The M-TH Powers of N Successive Terms of An Arithmetic Sequence: B + (A + B) + (2a + B) + + ( (N 1) A + B)Document10 pagesSum of The M-TH Powers of N Successive Terms of An Arithmetic Sequence: B + (A + B) + (2a + B) + + ( (N 1) A + B)will bNo ratings yet
- New Circular Model Induced by Inverse Stereographic Projection On Double Exponential Model - Application To Birds Migration DataDocument13 pagesNew Circular Model Induced by Inverse Stereographic Projection On Double Exponential Model - Application To Birds Migration Datawill bNo ratings yet
- Sum of Geometric Series With Negative Exponents: April 2022Document2 pagesSum of Geometric Series With Negative Exponents: April 2022will bNo ratings yet
- Extended Weibull Burr XII Distribution: Properties and ApplicationsDocument13 pagesExtended Weibull Burr XII Distribution: Properties and Applicationswill bNo ratings yet
- New Family of The T Distributions For Modeling Semicircular DataDocument8 pagesNew Family of The T Distributions For Modeling Semicircular Datawill bNo ratings yet
- Visualize Geometric SeriesDocument7 pagesVisualize Geometric Serieswill bNo ratings yet
- Combinatorial Geometric Series: July 2022Document3 pagesCombinatorial Geometric Series: July 2022will bNo ratings yet
- Generalized Linear Failure Rate DistributionDocument23 pagesGeneralized Linear Failure Rate Distributionwill bNo ratings yet
- Kummer Beta Normal JDS FINALDocument27 pagesKummer Beta Normal JDS FINALwill bNo ratings yet
- Mythology: The TitansDocument30 pagesMythology: The Titanswill bNo ratings yet
- Electrodynamics of Radiation Processes: Practise, Practise, Practise...Document6 pagesElectrodynamics of Radiation Processes: Practise, Practise, Practise...will bNo ratings yet
- The Transmuted Generalized Gamma Distribution: Properties and ApplicationDocument12 pagesThe Transmuted Generalized Gamma Distribution: Properties and Applicationwill bNo ratings yet
- Symmetric Unimodal Models For Directional Data MotDocument18 pagesSymmetric Unimodal Models For Directional Data Motwill bNo ratings yet
- On A Bivariate Weibull Distribution: Advances and Applications in Statistics January 2011Document31 pagesOn A Bivariate Weibull Distribution: Advances and Applications in Statistics January 2011will bNo ratings yet
- 1 Billion Pages 1 Million Dollars Mining The Web TDocument10 pages1 Billion Pages 1 Million Dollars Mining The Web Twill bNo ratings yet
- A New Compound Lifetime Distribution: Model, Characterization, Estimation and ApplicationDocument13 pagesA New Compound Lifetime Distribution: Model, Characterization, Estimation and Applicationwill bNo ratings yet
- Projected Circular and Lll-Axial Skew-Normal Distributions: Han Son SeoDocument14 pagesProjected Circular and Lll-Axial Skew-Normal Distributions: Han Son Seowill bNo ratings yet
- Families of Distributions On The Circle A Review: Y OtoloDocument9 pagesFamilies of Distributions On The Circle A Review: Y Otolowill bNo ratings yet
- 10 5923 J Ajms 20180804 04 PDFDocument6 pages10 5923 J Ajms 20180804 04 PDFwill bNo ratings yet
- Some New Identities Involving Sheffer-Appell Polynomial Sequences Via Matrix ApproachDocument18 pagesSome New Identities Involving Sheffer-Appell Polynomial Sequences Via Matrix Approachwill bNo ratings yet
- A Forecast Model For Language Under The Influence of ImmigrationDocument9 pagesA Forecast Model For Language Under The Influence of Immigrationwill bNo ratings yet
- Confidence Intervals: Vocabulary: Point Estimate - Interval Estimate - Level of Confidence - Margin of ErrorDocument8 pagesConfidence Intervals: Vocabulary: Point Estimate - Interval Estimate - Level of Confidence - Margin of ErrorEmeril WilliamsNo ratings yet
- Business Research Methods: Bivariate Analysis - Tests of DifferencesDocument56 pagesBusiness Research Methods: Bivariate Analysis - Tests of DifferencesNishat TasnimNo ratings yet
- Statistics: Umurgrup Pendidikan Jenis Kelamin N Valid MissingDocument8 pagesStatistics: Umurgrup Pendidikan Jenis Kelamin N Valid MissingRidho PangestuNo ratings yet
- Main Menu - The Hyperlinks Below Take You To The Appropriate WorksheetDocument97 pagesMain Menu - The Hyperlinks Below Take You To The Appropriate WorksheetDineshNo ratings yet
- Multivariate Analysis of Variance and CovarianceDocument3 pagesMultivariate Analysis of Variance and CovarianceDessy HapsariNo ratings yet
- Linear Regression With Gradient DescentDocument8 pagesLinear Regression With Gradient DescentGautam Kumar100% (1)
- Data Science With Machine Learning Curriculum 2021Document12 pagesData Science With Machine Learning Curriculum 2021AJAY SNo ratings yet
- Probability StaisticsDocument15 pagesProbability StaisticsBhavin PanchalNo ratings yet
- CTV BayesianDocument15 pagesCTV BayesiansumarjayaNo ratings yet
- Bty472 RegressionDocument22 pagesBty472 RegressionKrishna VamsiNo ratings yet
- Resume Ekonometrika Bab 2Document6 pagesResume Ekonometrika Bab 2Firsa AuliaNo ratings yet
- The Holt-Winters Forecasting ProcedureDocument17 pagesThe Holt-Winters Forecasting ProcedureHimeko UshioNo ratings yet
- STA301 Solved MCQs With ReferenceDocument22 pagesSTA301 Solved MCQs With ReferenceAhsan Khan KhanNo ratings yet
- Assignment 1Document12 pagesAssignment 1snazrul100% (1)
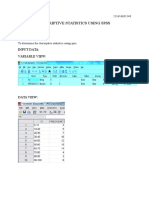
- Descriptive Statistics Using SPSS: Ex No: DateDocument5 pagesDescriptive Statistics Using SPSS: Ex No: Datepecmba11No ratings yet
- Lay Yoon Fah, Khoo Chwee Hoon, & Jenny Cheng Oi LeeDocument12 pagesLay Yoon Fah, Khoo Chwee Hoon, & Jenny Cheng Oi LeeawangbakhtiarNo ratings yet
- Module 1 QuizDocument7 pagesModule 1 QuizKrishnanjali VuNo ratings yet
- Research Paper - FinalDocument15 pagesResearch Paper - FinalCyril ScariaNo ratings yet
- ECN302E ProblemSet07 IntroductionToTSRAndForecastingPart1 SolutionsDocument5 pagesECN302E ProblemSet07 IntroductionToTSRAndForecastingPart1 SolutionsluluNo ratings yet
- Module in Assessment of Learning 2Document17 pagesModule in Assessment of Learning 2BRIDGETTE QUISMONDONo ratings yet
- Westgard RulesDocument2 pagesWestgard Rulescctb kabbogorNo ratings yet
- T Test 1Document23 pagesT Test 1Zyrill MachaNo ratings yet
- Econometrics Term PaperDocument8 pagesEconometrics Term PaperDhruvin PatelNo ratings yet
- Master Thesis Structural Equation ModelingDocument5 pagesMaster Thesis Structural Equation Modelingpbfbkxgld100% (3)
- Module - 4 - Analyze Phase - Oct 20Document210 pagesModule - 4 - Analyze Phase - Oct 20mohmedkelioy1No ratings yet
- Implementation of Exponential Smoothing For Forecasting Time Series DataDocument5 pagesImplementation of Exponential Smoothing For Forecasting Time Series DataLaxmikant KadamNo ratings yet
- Soal Uas Statistika Data Sains s3 BK - 2021-s3 BKDocument2 pagesSoal Uas Statistika Data Sains s3 BK - 2021-s3 BKSUAKANo ratings yet
- Data Set 1aDocument6 pagesData Set 1aSufyan AshrafNo ratings yet