Download as pdf or txt
You might also like
- O-Level Commerce PDFDocument8 pagesO-Level Commerce PDFClinton ChikengezhaNo ratings yet
- Electricians GuideDocument296 pagesElectricians Guidemaeid75% (4)
- Standard Template LibraryDocument21 pagesStandard Template LibraryKumar VaishnavNo ratings yet
- Standard Template LibraryDocument36 pagesStandard Template LibraryRubesh Rudra RamanNo ratings yet
- Standard Template LibraryDocument36 pagesStandard Template Librarymanjeshsingh0245No ratings yet
- Standard Template Library - HackerEarthDocument24 pagesStandard Template Library - HackerEarthSaurav ChandraNo ratings yet
- Day 2Document9 pagesDay 2lathaNo ratings yet
- Algo 3Document8 pagesAlgo 3Kudikala RishikeshNo ratings yet
- STL in C++Document24 pagesSTL in C++Ram BhardwajNo ratings yet
- Owen Astrachan and Dee Ramm November 19, 1996Document11 pagesOwen Astrachan and Dee Ramm November 19, 1996Gobara DhanNo ratings yet
- STL Complete NotesDocument19 pagesSTL Complete NotesArchit P. MeshramNo ratings yet
- C++ STL: CSCI 3110Document30 pagesC++ STL: CSCI 3110Suganya SelvarajNo ratings yet
- Standard Template LibraryDocument17 pagesStandard Template LibraryKshitij Aggarwal100% (1)
- Workshop 1Document21 pagesWorkshop 1deepakabhiramNo ratings yet
- The Standard Library 2011 Lecture NotesDocument13 pagesThe Standard Library 2011 Lecture NotesKristian ForestNo ratings yet
- C MethodsDocument4 pagesC MethodsAmina YahiaNo ratings yet
- Data Types and Data StructuresDocument26 pagesData Types and Data StructuresVijaykumar Dhotrad100% (1)
- Lecture 7Document10 pagesLecture 7api-241581181No ratings yet
- List, Dictionary, Tuple - Day 4Document6 pagesList, Dictionary, Tuple - Day 4Vijay KarthikNo ratings yet
- Unit 5-1Document22 pagesUnit 5-1vansh pundirNo ratings yet
- Standard Template LibraryDocument38 pagesStandard Template LibraryMonika SachanNo ratings yet
- Implementasi Link ListDocument11 pagesImplementasi Link ListDeni KurniawanNo ratings yet
- Python BasicsDocument73 pagesPython BasicsAniket ChauhanNo ratings yet
- VectorDocument15 pagesVectorMonalisa kanungoNo ratings yet
- Project Ideas For Data StructuresDocument42 pagesProject Ideas For Data StructuresAbdurezak ShifaNo ratings yet
- Review of Python BasicsDocument39 pagesReview of Python BasicsNamita SahuNo ratings yet
- Assignment 1 PythonDocument15 pagesAssignment 1 PythonSparsh ManoharNo ratings yet
- Lecture 6 - Advanced Class OperationsDocument28 pagesLecture 6 - Advanced Class OperationsHuayiLI1No ratings yet
- Document From Kathawde KomalDocument51 pagesDocument From Kathawde KomalkomalkathawdeNo ratings yet
- Python CheatsheetDocument22 pagesPython Cheatsheettrget0001No ratings yet
- Linked List and CursorsDocument7 pagesLinked List and CursorsSourav Kumar BiswalNo ratings yet
- CS301 Short Notes MidTerm by Vu Topper RMDocument21 pagesCS301 Short Notes MidTerm by Vu Topper RMSAIM ALI RASHIDNo ratings yet
- cs61b Fa02 mt1Document8 pagescs61b Fa02 mt1juggleninjaNo ratings yet
- CS202 Lab2submission LeTrungHieu 10ESDocument27 pagesCS202 Lab2submission LeTrungHieu 10ESLe HieuNo ratings yet
- 2021 - ECE391 - Ch3 - Vectors - Lists - and SequencesDocument11 pages2021 - ECE391 - Ch3 - Vectors - Lists - and SequencesHoang TranNo ratings yet
- Template Classes: STL Has Four ComponentsDocument37 pagesTemplate Classes: STL Has Four ComponentsAnu PriyaNo ratings yet
- Data TypesDocument21 pagesData TypesPython GamingNo ratings yet
- Algorithms in The STL Are Procedures That Are AppliedDocument34 pagesAlgorithms in The STL Are Procedures That Are AppliedNeha VermaNo ratings yet
- Iterators: ArraysDocument5 pagesIterators: ArraysanandNo ratings yet
- Cursor & Content ValueDocument13 pagesCursor & Content ValueuttamraoNo ratings yet
- CollectionDocument31 pagesCollectionBhaeathNo ratings yet
- Python CodeDocument10 pagesPython Codeddpywi0pNo ratings yet
- THE STL - Function Object & Misc: AbilitiesDocument6 pagesTHE STL - Function Object & Misc: AbilitiesAlfonso De Miguel EsponeraNo ratings yet
- Part of The Collections FrameworkDocument22 pagesPart of The Collections FrameworkREEVAN SINGHNo ratings yet
- CS 319 Applied Programming Fall 2018 Programming Assignment # 1: Linked Lists, Stacks, QueuesDocument5 pagesCS 319 Applied Programming Fall 2018 Programming Assignment # 1: Linked Lists, Stacks, QueuesIIqra TToheedNo ratings yet
- Ipython in The Terminal. & Quit The Ipython Interpreter by Using CTRL + DDocument10 pagesIpython in The Terminal. & Quit The Ipython Interpreter by Using CTRL + DkauserNo ratings yet
- Scala Quick ReferenceDocument6 pagesScala Quick ReferenceJohn GodoiNo ratings yet
- Collection FrameworkDocument33 pagesCollection FrameworkKomal GhorpadeNo ratings yet
- Data STRCDocument7 pagesData STRCKlevi MehmetiNo ratings yet
- Xii Cs Unit I Part7 Data Structure 2020 21Document9 pagesXii Cs Unit I Part7 Data Structure 2020 21BEENA HASSINANo ratings yet
- Objects, and AlgorithmsDocument27 pagesObjects, and AlgorithmsGeorge NădejdeNo ratings yet
- Abstract Data Types Abstract Data Types: 1111 CPT S 223. School of EECS, WSUDocument52 pagesAbstract Data Types Abstract Data Types: 1111 CPT S 223. School of EECS, WSUsatya1401No ratings yet
- Red: What You'd Actually Put in Python File: Common Differences Between Python and MATLAB, Ways To Approach PythonDocument19 pagesRed: What You'd Actually Put in Python File: Common Differences Between Python and MATLAB, Ways To Approach PythonTesting GmailNo ratings yet
- STL List VectorDocument34 pagesSTL List VectorDasari HarithaNo ratings yet
- C++ STL (Quickest Way To Learn, Even For Absolute Beginners)Document19 pagesC++ STL (Quickest Way To Learn, Even For Absolute Beginners)aerNo ratings yet
- Functional Programming: Int DoubleDocument27 pagesFunctional Programming: Int Doublehoanganh200870No ratings yet
- Assignment No Title: Demonstration of STL Objectives: 1) To Learn and Understand Concepts of Standard Template LibraryDocument6 pagesAssignment No Title: Demonstration of STL Objectives: 1) To Learn and Understand Concepts of Standard Template LibraryRajendra PatilNo ratings yet
- Lab 3Document5 pagesLab 3Gump ForestNo ratings yet
- Scala ReferenceDocument6 pagesScala Referencemks32No ratings yet
- Lec15. Containers, Iterators, SequenceDocument36 pagesLec15. Containers, Iterators, SequenceMajd AL KawaasNo ratings yet
- Reference Operator (&) : Objects and LvaluesDocument7 pagesReference Operator (&) : Objects and Lvaluesavnika soganiNo ratings yet
- Raghavendran V Piping Supervisor: ResumeDocument5 pagesRaghavendran V Piping Supervisor: Resumeandi dipayadnyaNo ratings yet
- Transportation orDocument5 pagesTransportation orAaditya shahNo ratings yet
- Dental Plaque and CalculusDocument32 pagesDental Plaque and Calculus蔡長家No ratings yet
- Okra Group 3Document34 pagesOkra Group 3Vanessa Marie AgnerNo ratings yet
- Case Digests in PropertyDocument95 pagesCase Digests in PropertyRemelyn SeldaNo ratings yet
- AADE 05 NTCE 52 - PatilDocument8 pagesAADE 05 NTCE 52 - PatilAhmad Reza FarokhiNo ratings yet
- Patient NameDocument3 pagesPatient NameSmith91No ratings yet
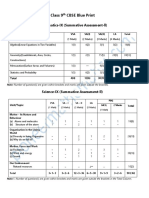
- Class 9th CBSE Blue PrintDocument2 pagesClass 9th CBSE Blue PrintYash BawiskarNo ratings yet
- Escrow Agreements For Application SoftwareDocument17 pagesEscrow Agreements For Application SoftwareHaris HamidovicNo ratings yet
- Home - SPECIAL BRANCH - Verification Related To Passport and Character & AntecedentsDocument5 pagesHome - SPECIAL BRANCH - Verification Related To Passport and Character & AntecedentsAbhiNo ratings yet
- Cate 825 6M33 WPG825 7 12M26Document3 pagesCate 825 6M33 WPG825 7 12M26Nicolas DodoricoNo ratings yet
- 19 670864alemitecls1000Document28 pages19 670864alemitecls1000papagoman100% (1)
- Institute of Food Security (Food Corporation of India) Gurgaon Management Trainee Batch:V/2010 Objective Test:Commercial (Sales&Export)Document2 pagesInstitute of Food Security (Food Corporation of India) Gurgaon Management Trainee Batch:V/2010 Objective Test:Commercial (Sales&Export)Swarup MukherjeeNo ratings yet
- User Manual IvmsDocument223 pagesUser Manual IvmsGerardo AltobelliNo ratings yet
- Peripheral Blood Smear Pathologist ToolDocument3 pagesPeripheral Blood Smear Pathologist ToolSimon HafeniNo ratings yet
- Winkler Test For Dissolved OxygenDocument3 pagesWinkler Test For Dissolved OxygenDOMINICNo ratings yet
- PPT-finalDocument21 pagesPPT-finalRamu KetkarNo ratings yet
- 6 - Telephone and Cable Networks For Data TransmissionDocument31 pages6 - Telephone and Cable Networks For Data TransmissionpranjalcrackuNo ratings yet
- Vxflex Data SheetDocument5 pagesVxflex Data SheetJesus SantiagoNo ratings yet
- Critical Care EEG Basics-Rapid Bedside EEG Reading For Acute Care Providers (Feb 29, 2024) - (1009261169) - (Cambridge University Press) JadejaDocument70 pagesCritical Care EEG Basics-Rapid Bedside EEG Reading For Acute Care Providers (Feb 29, 2024) - (1009261169) - (Cambridge University Press) Jadejazahajslamic100% (6)
- Waterworld201808 DLDocument56 pagesWaterworld201808 DLThiyagu ManogaranNo ratings yet
- Java Array: Logic Formulation and Intro. To ProgrammingDocument9 pagesJava Array: Logic Formulation and Intro. To ProgrammingklintNo ratings yet
- IETE Template JRDocument7 pagesIETE Template JRAshish Kumar0% (1)
- 2023 Lupong Tagapamayapa Incentives Awards (Ltia) Assessment FormDocument4 pages2023 Lupong Tagapamayapa Incentives Awards (Ltia) Assessment FormNicole Chupungco100% (1)
- Legend of The Galactic Heroes, Vol. 10 Sunset by Yoshiki Tanaka (Tanaka, Yoshiki)Document245 pagesLegend of The Galactic Heroes, Vol. 10 Sunset by Yoshiki Tanaka (Tanaka, Yoshiki)StafarneNo ratings yet
- DEEDofContribution - Individual AntonDocument4 pagesDEEDofContribution - Individual AntonLorelie YabutNo ratings yet
- Holding Companies: Problems and Solutions - AccountingDocument17 pagesHolding Companies: Problems and Solutions - AccountingVaibhav MaheshwariNo ratings yet
- Decontaminating Kit, SkinDocument36 pagesDecontaminating Kit, SkinChuck AchbergerNo ratings yet