Download as pdf or txt
You might also like
- Gov Acc Quiz 2, BeltranDocument3 pagesGov Acc Quiz 2, Beltranbruuhhhh0% (3)
- 关于视频游戏人工智能开发的深度学习最新技术Document8 pages关于视频游戏人工智能开发的深度学习最新技术meiwanlanjunNo ratings yet
- Knowledge Acquisition For Adaptive Game A 2007 Science of Computer ProgrammiDocument17 pagesKnowledge Acquisition For Adaptive Game A 2007 Science of Computer ProgrammiVector StrikeNo ratings yet
- Counter-Strike Deathmatch With Large-Scale Behavioural CloningDocument24 pagesCounter-Strike Deathmatch With Large-Scale Behavioural CloningМихаил ПетровNo ratings yet
- Behaviour Oriented Design For Real-Time PDFDocument8 pagesBehaviour Oriented Design For Real-Time PDFFergus1986No ratings yet
- Portfolio Greedy Search and Simulation For Large-Scale Combat in StarcraftDocument8 pagesPortfolio Greedy Search and Simulation For Large-Scale Combat in StarcraftMichaelaŠtolováNo ratings yet
- Fast Heuristic Search For RTS Game Combat Scenarios: David ChurchillDocument6 pagesFast Heuristic Search For RTS Game Combat Scenarios: David ChurchillRuben SantiagoNo ratings yet
- Topographical Accuracy and Performance of Procedurally-Generated Virtual LandscapesDocument80 pagesTopographical Accuracy and Performance of Procedurally-Generated Virtual LandscapesAnonymous YDo4MsNo ratings yet
- Genetic Algorithm in Counter-StrikeDocument7 pagesGenetic Algorithm in Counter-StrikeAko Si CsmasterNo ratings yet
- Toward Affordable Full Game Real-Time Strategy Games Research With Deep Reinforcement LearningDocument19 pagesToward Affordable Full Game Real-Time Strategy Games Research With Deep Reinforcement LearningHansNo ratings yet
- AI ML ExplainedDocument26 pagesAI ML ExplainedHeet ShahNo ratings yet
- Integrating Command Control With Modelling Simulation To Evaluate Courses of Action Systematic PDocument11 pagesIntegrating Command Control With Modelling Simulation To Evaluate Courses of Action Systematic Pkako083No ratings yet
- CS158-2 Activity #7 InstructionsDocument7 pagesCS158-2 Activity #7 InstructionsAngelique AlabadoNo ratings yet
- Artificial IntelligenceMachine Learning Explained v4Document27 pagesArtificial IntelligenceMachine Learning Explained v4xaviNo ratings yet
- The Application of Reinforcement Learning in Video GamesDocument10 pagesThe Application of Reinforcement Learning in Video GamesasdNo ratings yet
- Learning Micro-Management Skills in RTS Games by Imitating ExpertsDocument7 pagesLearning Micro-Management Skills in RTS Games by Imitating ExpertsVibhav SinghNo ratings yet
- Explainable AI in Manufacturing: A Predictive Maintenance Case StudyDocument9 pagesExplainable AI in Manufacturing: A Predictive Maintenance Case Study1DA20IM021Yashas GanapathiNo ratings yet
- Human Resource Management by Machine Learning AlgorithmsDocument6 pagesHuman Resource Management by Machine Learning AlgorithmsIJRASETPublicationsNo ratings yet
- Embedded System Design IssuesDocument12 pagesEmbedded System Design IssuesSudhanshu Singh RajputanaNo ratings yet
- 26 - Ron Larham PaperDocument4 pages26 - Ron Larham Papermoslem vesaliNo ratings yet
- 20 Architecturing C4i System of SystemsDocument2 pages20 Architecturing C4i System of SystemsAbhijeet TripathiNo ratings yet
- LAB Manual Part A: Experiment No.8Document5 pagesLAB Manual Part A: Experiment No.8BiatchNo ratings yet
- FYP ProposalDocument13 pagesFYP ProposalaleevibesNo ratings yet
- My SeminarDocument8 pagesMy Seminarprovidence8899No ratings yet
- ImprovinImproving Adaptive Game AI With Evolutionary Learningg Adaptive Game AI With Evolutionary LearningDocument8 pagesImprovinImproving Adaptive Game AI With Evolutionary Learningg Adaptive Game AI With Evolutionary LearningJared HesterNo ratings yet
- SOCOM Plans New Artificial Intelligence Strategy: TAMPA, Fla.Document3 pagesSOCOM Plans New Artificial Intelligence Strategy: TAMPA, Fla.Dragomir FlorentinaNo ratings yet
- Grsim - RoboCup Small Size Robot Soccer Simulator PDFDocument11 pagesGrsim - RoboCup Small Size Robot Soccer Simulator PDFTan Tien NguyenNo ratings yet
- Institutional Market Analysis in Stock MarketDocument5 pagesInstitutional Market Analysis in Stock MarketIJRASETPublications100% (1)
- Vaishnavi P - 1JS19EC155 - AI in Defence SectorDocument1 pageVaishnavi P - 1JS19EC155 - AI in Defence SectorVaishnaviNo ratings yet
- Simulation in Manufacturing Systems: ObjectivesDocument5 pagesSimulation in Manufacturing Systems: ObjectivesPrakash MNo ratings yet
- Paule A7Document7 pagesPaule A7tristan pauleNo ratings yet
- Apne 17Document5 pagesApne 17DDCTCNo ratings yet
- Li 2010Document3 pagesLi 2010Dr. Hari Sivasri Phanindra KNo ratings yet
- Automatic Logo Detection With Deep Region-Based Convolutional NetworksDocument10 pagesAutomatic Logo Detection With Deep Region-Based Convolutional NetworksIJRASETPublicationsNo ratings yet
- 可解释的人工智能:理解、 可视化和解释深度学习模型Document11 pages可解释的人工智能:理解、 可视化和解释深度学习模型meiwanlanjunNo ratings yet
- Abhishek TiwariDocument10 pagesAbhishek TiwariAbhishek TiwariNo ratings yet
- Coevolving Build-Orders For RTS Games: Christopher A. Ballinger, Member, IEEE, Sushil J. Louis, Member, IEEEDocument4 pagesCoevolving Build-Orders For RTS Games: Christopher A. Ballinger, Member, IEEE, Sushil J. Louis, Member, IEEETelegraphNo ratings yet
- Dagmawi ReportDocument5 pagesDagmawi ReportHaben GirmayNo ratings yet
- Artificial Intelligence The Time To Act Is Now - McKinseyDocument12 pagesArtificial Intelligence The Time To Act Is Now - McKinseyYTNo ratings yet
- Machine Learning Applied On Video GamesDocument48 pagesMachine Learning Applied On Video GamesJuanNo ratings yet
- Application of Artificial Intelligence TechnologyDocument9 pagesApplication of Artificial Intelligence TechnologyCoach-NeilKhayechNo ratings yet
- Face Recognition For Criminal DetectionDocument7 pagesFace Recognition For Criminal DetectionIJRASETPublicationsNo ratings yet
- AI StefanWeijersDocument8 pagesAI StefanWeijersBruno VintilaNo ratings yet
- Automatically Generating Game Tactics Through Evolutionary LearningDocument10 pagesAutomatically Generating Game Tactics Through Evolutionary LearningAndreas KarasNo ratings yet
- Virtual Reality Simulation Technology For Military and Industry Skill Improvement and Training ProgramsDocument8 pagesVirtual Reality Simulation Technology For Military and Industry Skill Improvement and Training ProgramsKEEP CALM studiosNo ratings yet
- METODocument6 pagesMETOjoansalas1234No ratings yet
- The Role of Game Engines in Game Development and TDocument26 pagesThe Role of Game Engines in Game Development and Tsrs.2500shewaleNo ratings yet
- Course 1-AI NEP Notes (1) - 2Document54 pagesCourse 1-AI NEP Notes (1) - 2Ullas GowdaNo ratings yet
- Gerardo Rodríguez Barba Control Lectura 120224Document9 pagesGerardo Rodríguez Barba Control Lectura 120224Deya Alvarez VillajuanaNo ratings yet
- Professional Military Education (Pme) in 2020: UnclassifiedDocument23 pagesProfessional Military Education (Pme) in 2020: UnclassifiedeviemasnoNo ratings yet
- Algorithmic Trading Bot: Medha Mathur, Satyam Mhadalekar, Sahil Mhatre, Vanita ManeDocument9 pagesAlgorithmic Trading Bot: Medha Mathur, Satyam Mhadalekar, Sahil Mhatre, Vanita ManeTasty Feasty By PremiNo ratings yet
- Stock Market PredictionDocument8 pagesStock Market PredictionIJRASETPublications100% (1)
- Script HMT PSNDocument3 pagesScript HMT PSNtbj1990No ratings yet
- Data-Driven Manufacturing A Paradigm Shift in The Manufacturing IndustryDocument5 pagesData-Driven Manufacturing A Paradigm Shift in The Manufacturing IndustryIJRASETPublicationsNo ratings yet
- Nandini Project ReportDocument55 pagesNandini Project Reportvijay kumar nNo ratings yet
- Sensors 19 02981Document47 pagesSensors 19 02981tresaNo ratings yet
- Assignment No 5Document10 pagesAssignment No 5darshan KeskarNo ratings yet
- SoC Challenge 2Document8 pagesSoC Challenge 2Hansaka CostaNo ratings yet
- Laptop Performance PredictionDocument7 pagesLaptop Performance PredictionIJRASETPublicationsNo ratings yet
- Game Engine ThesisDocument8 pagesGame Engine ThesisKaren Benoit100% (2)
- Smart Camera: Revolutionizing Visual Perception with Computer VisionFrom EverandSmart Camera: Revolutionizing Visual Perception with Computer VisionNo ratings yet
- Shortcut KeysDocument4 pagesShortcut KeysFawad AfzalNo ratings yet
- Structure AnswersDocument7 pagesStructure Answersbunshin AAANo ratings yet
- The Food Supply Chain of India The EcosystemDocument6 pagesThe Food Supply Chain of India The EcosystemMoksh SharmaNo ratings yet
- Electrical Engineering Sem-2 All Question BankDocument2,178 pagesElectrical Engineering Sem-2 All Question BankGAURAV GUPTANo ratings yet
- Hand-Book For Translator CandidatesDocument26 pagesHand-Book For Translator CandidatesNikolettNo ratings yet
- Jón Kristinsson: Edited by Andy Van Den DobbelsteenDocument17 pagesJón Kristinsson: Edited by Andy Van Den DobbelsteenWika NurikaNo ratings yet
- Lesson1: Cell, The Basic Unit of LifeDocument4 pagesLesson1: Cell, The Basic Unit of Lifedream kingNo ratings yet
- Dioscorea L. (PROSEA) - PlantUse EnglishDocument29 pagesDioscorea L. (PROSEA) - PlantUse Englishfortuna_dNo ratings yet
- Stategic Mgt. Unit - 1Document33 pagesStategic Mgt. Unit - 1Kiran S RaoNo ratings yet
- Overview of Active Deposit Systems Alpha GammaDocument1 pageOverview of Active Deposit Systems Alpha GammaEngels RamírezNo ratings yet
- AirpaxDocument2 pagesAirpaxkaru2275243No ratings yet
- DEH Study GuideDocument34 pagesDEH Study GuideRomán GerstmayerNo ratings yet
- Apache Trout ReportDocument7 pagesApache Trout Reportapi-460143281No ratings yet
- Snatch Theft Prevention TipsDocument1 pageSnatch Theft Prevention TipsDon McleanNo ratings yet
- Air SlidesDocument6 pagesAir SlidesMehmet C33% (3)
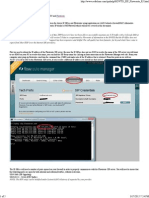
- Configuring IP Office 500 For SIPDocument5 pagesConfiguring IP Office 500 For SIPPhillip CasalegnoNo ratings yet
- Video Processing SyllabusDocument4 pagesVideo Processing SyllabusChandan PurohitNo ratings yet
- Craig-1977-The Structure of JacaltecDocument442 pagesCraig-1977-The Structure of JacaltecmaclbaisNo ratings yet
- The Bucket List: Activity TypeDocument3 pagesThe Bucket List: Activity TypeJESSIKA CALDERON CHAVEZNo ratings yet
- Liturgy Chapter 5Document41 pagesLiturgy Chapter 5Blue macchiatoNo ratings yet
- Internship Offer Letter - Software Development - AdarshDocument4 pagesInternship Offer Letter - Software Development - Adarshadd100% (1)
- BRM Lecture4Document12 pagesBRM Lecture4amrj27609No ratings yet
- Investment Management ProjectDocument8 pagesInvestment Management ProjectKiby AliceNo ratings yet
- Handbook - Curtin UniversityDocument12 pagesHandbook - Curtin UniversityJuni KasthakarNo ratings yet
- PaperAirplanes 16june2023Document2 pagesPaperAirplanes 16june2023Pedro Filipe de Sousa SilvaNo ratings yet
- Elk Consumer MathDocument7 pagesElk Consumer Mathapi-399013722No ratings yet
- AAM EnglishDocument7 pagesAAM EnglishYannick ÜzümNo ratings yet
- BotanyDocument98 pagesBotanyMikhail Landicho100% (1)
- Engineers, Part A: Journal of Power and Proceedings of The Institution of MechanicalDocument10 pagesEngineers, Part A: Journal of Power and Proceedings of The Institution of MechanicalwaleligneNo ratings yet