Download as pdf or txt
You might also like
- PLC Webb Reis-246 PDFDocument246 pagesPLC Webb Reis-246 PDFAditya Chaturvedi75% (4)
- Vahl Davis BenchmarkDocument16 pagesVahl Davis BenchmarkAjith Kumar ArumughamNo ratings yet
- Boundary Element and Finite Element MethodsDocument73 pagesBoundary Element and Finite Element MethodsticoncoolzNo ratings yet
- G1888-90009 Headspace SamplerDocument74 pagesG1888-90009 Headspace Samplerpoeta_oscuroNo ratings yet
- Final Report RSADocument27 pagesFinal Report RSAMounesh Panchal67% (3)
- Lithium I On IncidentsDocument12 pagesLithium I On IncidentsM8R-fsx9faNo ratings yet
- Principles of TurbomachineryDocument276 pagesPrinciples of TurbomachineryNavneet PAndeNo ratings yet
- Johannsen 2002Document8 pagesJohannsen 2002ALEJANDRO GANCEDO TORALNo ratings yet
- 1) Linearization and Iteration: Contributions by B. Kirby, R. Bhaskaran, and S. SantanaDocument2 pages1) Linearization and Iteration: Contributions by B. Kirby, R. Bhaskaran, and S. SantanaCehanNo ratings yet
- Meshless - Science DirectDocument13 pagesMeshless - Science Directenatt2012No ratings yet
- MIMS Ep2017 7Document95 pagesMIMS Ep2017 7Cavia PorcellusNo ratings yet
- Helen PDFDocument14 pagesHelen PDFمرتضى عباسNo ratings yet
- Benchmark On Discretization Schemes For Anisotropic Diffusion Problems On General GridsDocument16 pagesBenchmark On Discretization Schemes For Anisotropic Diffusion Problems On General GridsPaulo LikeyNo ratings yet
- Received 10 April 1997. Read 16 March 1997. Published 30 December 1998.Document18 pagesReceived 10 April 1997. Read 16 March 1997. Published 30 December 1998.Tg WallasNo ratings yet
- Pdes Mod 5 SummaryDocument11 pagesPdes Mod 5 SummaryTasha TanNo ratings yet
- Journal of Computational Physics: K. Lipnikov, G. ManziniDocument26 pagesJournal of Computational Physics: K. Lipnikov, G. ManzinidwstephensNo ratings yet
- Stability Analysis of Quadrature Methods For Two-Dimensional Singular Integral EquationsDocument33 pagesStability Analysis of Quadrature Methods For Two-Dimensional Singular Integral EquationsHuynh Khac TuanNo ratings yet
- Solving Systems of Algebraic Equations: Daniel LazardDocument27 pagesSolving Systems of Algebraic Equations: Daniel LazardErwan Christo Shui 廖No ratings yet
- Assignment On Metal FormingDocument11 pagesAssignment On Metal Formingladi11bawaNo ratings yet
- Numerical Solution of Regularized Long-Wave EquationDocument8 pagesNumerical Solution of Regularized Long-Wave EquationNavdeep GoelNo ratings yet
- 1 Modified Taylor Solution of Equation of Oxygen in A Spherical Cell With Michaelis Menten Uptake KineticsDocument6 pages1 Modified Taylor Solution of Equation of Oxygen in A Spherical Cell With Michaelis Menten Uptake Kineticsmario sandovalNo ratings yet
- Numerical Simulation of 2D Square Driven Cavity Using Fourth Order Compact Finite Dierence SchemesDocument16 pagesNumerical Simulation of 2D Square Driven Cavity Using Fourth Order Compact Finite Dierence SchemesAaron FultonNo ratings yet
- 1 s2.0 S0096300316302673 MainDocument16 pages1 s2.0 S0096300316302673 Mainjoginder singhNo ratings yet
- D 001 DownloadDocument14 pagesD 001 DownloadAnkit ShrivastavaNo ratings yet
- E Cient Solution of The SCHR Odinger-Poisson Equations in Semiconductor Device SimulationsDocument8 pagesE Cient Solution of The SCHR Odinger-Poisson Equations in Semiconductor Device SimulationsthedeadlordNo ratings yet
- U + 6 U + 6 UU + U 3 U .: XT 2 X XX XXXX YyDocument5 pagesU + 6 U + 6 UU + U 3 U .: XT 2 X XX XXXX YymichaelNo ratings yet
- IMAC XIII 13th 13-13-2 A Tutorial Complex EigenvaluesDocument6 pagesIMAC XIII 13th 13-13-2 A Tutorial Complex EigenvaluesmghgolNo ratings yet
- 1998 RS Zounes RH Rand Transition Curves For The Quasi-Periodic Mathieu Equation SIM J Appl Math 58Document22 pages1998 RS Zounes RH Rand Transition Curves For The Quasi-Periodic Mathieu Equation SIM J Appl Math 58TheodoraNo ratings yet
- 1 s2.0 S0895717701000486 MainDocument10 pages1 s2.0 S0895717701000486 MainJulee ShahniNo ratings yet
- The Approximation of The Maxwell Eigenvalue Problem Using A Least-Squares MethodDocument24 pagesThe Approximation of The Maxwell Eigenvalue Problem Using A Least-Squares MethoddurgaraokamireddyNo ratings yet
- Achdou 2006Document30 pagesAchdou 2006Kevin D Silva PerezNo ratings yet
- A High Ord Altern Direct Method.Document25 pagesA High Ord Altern Direct Method.joginder singhNo ratings yet
- Numerical Methods For U Problems: Muhammad Aslam Noor and S.I.A. TirmiziDocument9 pagesNumerical Methods For U Problems: Muhammad Aslam Noor and S.I.A. TirmiziErick Sebastian PulleyNo ratings yet
- QM Meshes 1986Document20 pagesQM Meshes 1986TimKellerNo ratings yet
- Numerical Methods For U Problems: Muhammad Aslam Noor and S.I.A. TirmiziDocument9 pagesNumerical Methods For U Problems: Muhammad Aslam Noor and S.I.A. TirmiziSeyfe GezahgnNo ratings yet
- ISOGAT A 2D Tutorial MATLAB Code For Isogeometric AnalysisDocument12 pagesISOGAT A 2D Tutorial MATLAB Code For Isogeometric AnalysisnetkasiaNo ratings yet
- Analytical Solution For Finite Domain Laplacian Equation With Coexistent Boundary ConditionsDocument17 pagesAnalytical Solution For Finite Domain Laplacian Equation With Coexistent Boundary ConditionsYoyaa WllNo ratings yet
- Open Problems Around Exact Algorithms: Gerhard J. WoegingerDocument9 pagesOpen Problems Around Exact Algorithms: Gerhard J. WoegingerHesham HefnyNo ratings yet
- A Multiscale Finite ElementDocument21 pagesA Multiscale Finite ElementZeljko LazarevicNo ratings yet
- Section-3.8 Gauss JacobiDocument15 pagesSection-3.8 Gauss JacobiKanishka SainiNo ratings yet
- Matlab Examples and ExercisesDocument3 pagesMatlab Examples and ExercisesDhanraj Bachai0% (1)
- TMP 229 FDocument6 pagesTMP 229 FFrontiersNo ratings yet
- A Numerical Approach To The Analysis of Circular Cylindrical Water TanksDocument5 pagesA Numerical Approach To The Analysis of Circular Cylindrical Water TanksJosué Azurín RendichNo ratings yet
- Analysis of Fractional Differential Equations: Kai DiethelmDocument20 pagesAnalysis of Fractional Differential Equations: Kai DiethelmAbdella KarimeNo ratings yet
- Further Developments On GMLS: Plates On Elastic FoundationDocument6 pagesFurther Developments On GMLS: Plates On Elastic FoundationChristian ZoundjiNo ratings yet
- Numerical Methods For Coupled Systems (CPLED) : February 9, 2016Document5 pagesNumerical Methods For Coupled Systems (CPLED) : February 9, 2016gauravbmcNo ratings yet
- 1 s2.0 S0307904X13001911 Main PDFDocument13 pages1 s2.0 S0307904X13001911 Main PDFUli Urio-LegoNo ratings yet
- Numerical Integration by Using Local-Node Gauss-Hermite CubatureDocument9 pagesNumerical Integration by Using Local-Node Gauss-Hermite CubatureAnonymous 1Yc9wYDtNo ratings yet
- Monotone Iterative Techniques For Nonlinear Differential Equations, by G. SDocument3 pagesMonotone Iterative Techniques For Nonlinear Differential Equations, by G. SBoutiara AbdellatifNo ratings yet
- Final ReportDocument5 pagesFinal ReportMike BreskeNo ratings yet
- On The Large N Limit, Wilson Loops, Confinement and Composite Antisymmetric Tensor Field TheoriesDocument14 pagesOn The Large N Limit, Wilson Loops, Confinement and Composite Antisymmetric Tensor Field TheoriesKathryn WilsonNo ratings yet
- Julio Garralon, Francisco Rus and Francisco R. Villatora - Radiation in Numerical Compactons From Finite Element MethodsDocument6 pagesJulio Garralon, Francisco Rus and Francisco R. Villatora - Radiation in Numerical Compactons From Finite Element MethodsPomac232No ratings yet
- Zh. Vychisl. Mat. Mat. FizDocument7 pagesZh. Vychisl. Mat. Mat. FizBroNo ratings yet
- 488 Solutions To The XOR Problem: Frans M. Virginia L. StonickDocument7 pages488 Solutions To The XOR Problem: Frans M. Virginia L. StonickDanish RajaNo ratings yet
- Numerical Treatment of Nonlinear Third Order Boundary Value ProblemDocument6 pagesNumerical Treatment of Nonlinear Third Order Boundary Value Problemdebbie131313No ratings yet
- Ashwin Chinnayya Et Al - A New Concept For The Modeling of Detonation Waves in Multiphase MixturesDocument10 pagesAshwin Chinnayya Et Al - A New Concept For The Modeling of Detonation Waves in Multiphase MixturesNikeShoxxxNo ratings yet
- Matlab Differentiation Matrix SuiteDocument55 pagesMatlab Differentiation Matrix SuiteRaghav VenkatNo ratings yet
- Variational Methods for Boundary Value Problems for Systems of Elliptic EquationsFrom EverandVariational Methods for Boundary Value Problems for Systems of Elliptic EquationsNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Harmonic Maps and Minimal Immersions with Symmetries (AM-130), Volume 130: Methods of Ordinary Differential Equations Applied to Elliptic Variational Problems. (AM-130)From EverandHarmonic Maps and Minimal Immersions with Symmetries (AM-130), Volume 130: Methods of Ordinary Differential Equations Applied to Elliptic Variational Problems. (AM-130)No ratings yet
- Method of Moments for 2D Scattering Problems: Basic Concepts and ApplicationsFrom EverandMethod of Moments for 2D Scattering Problems: Basic Concepts and ApplicationsNo ratings yet
- Aisi 1060Document3 pagesAisi 1060black_absynth0% (1)
- AE Smart Geared Prewired System Installation Manual v1 0Document20 pagesAE Smart Geared Prewired System Installation Manual v1 0ben omar HmidouNo ratings yet
- Properties of Moist AirDocument11 pagesProperties of Moist AirKarthik HarithNo ratings yet
- Energy Theorems and Structural Analysis PDFDocument88 pagesEnergy Theorems and Structural Analysis PDFjs kalyana rama100% (3)
- Comparison of Dissolved Air Flotation and Sedimentation PDFDocument5 pagesComparison of Dissolved Air Flotation and Sedimentation PDFPrie TeaNo ratings yet
- MODULE 5 - PRS Handling - UTMDocument32 pagesMODULE 5 - PRS Handling - UTMgavin.vedder1980No ratings yet
- Wittig ReactionDocument22 pagesWittig Reactionabubakar siddiqueNo ratings yet
- Math T STPM Semester 1 2014Document2 pagesMath T STPM Semester 1 2014tchinhuat82No ratings yet
- Resonant Converters-IIDocument68 pagesResonant Converters-IISONU KUMARNo ratings yet
- Assignment 1 Linear Equations: SC505 - Linear Algebra and Optimization Autumn 2021Document1 pageAssignment 1 Linear Equations: SC505 - Linear Algebra and Optimization Autumn 20212021 21004No ratings yet
- A Longitudinal Systematic Review of Credit Risk Assessment and Credit Default PredictorsDocument19 pagesA Longitudinal Systematic Review of Credit Risk Assessment and Credit Default PredictorsYanOnerNo ratings yet
- 4e HydraulischePressenDocument28 pages4e HydraulischePressenTirtheshwar Singh100% (1)
- Tara Balam... : How To Caluculate Tarabalam?Document6 pagesTara Balam... : How To Caluculate Tarabalam?krishnaNo ratings yet
- Preliminary Data Sheet: Product DescriptionDocument3 pagesPreliminary Data Sheet: Product Descriptionfar333No ratings yet
- Solving Multi-Dimensional Problems of Gas Dynamics Using MATLABDocument40 pagesSolving Multi-Dimensional Problems of Gas Dynamics Using MATLABMahmoud Abd El LateefNo ratings yet
- Designing Scenarios - Rebecca Wirfs-Brock PDFDocument8 pagesDesigning Scenarios - Rebecca Wirfs-Brock PDFAn Tran100% (1)
- Organic Chemistry PDFDocument40 pagesOrganic Chemistry PDFMax SinghNo ratings yet
- Hackerearth Online Judge: Prepared By: Mohamed AymanDocument21 pagesHackerearth Online Judge: Prepared By: Mohamed AymanPawan NaniNo ratings yet
- Bivariate AnalysisDocument19 pagesBivariate AnalysisMukteshwar Mishra100% (2)
- Benevolence of IslamDocument9 pagesBenevolence of IslamfirdousNo ratings yet
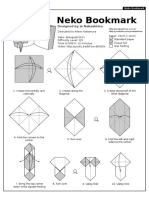
- Neko Bookmark: Designed by Jo NakashimaDocument4 pagesNeko Bookmark: Designed by Jo NakashimaEzra BlatzNo ratings yet
- Lotus Temple MagazineDocument34 pagesLotus Temple MagazineDivyata DhakalNo ratings yet
- PC-Sample QuestionsDocument24 pagesPC-Sample QuestionsHeather EllaineNo ratings yet
- Week 5 - Design For Sls 2Document28 pagesWeek 5 - Design For Sls 2Luqman NHNo ratings yet
- ch-9 Well FoundationDocument27 pagesch-9 Well FoundationRJ JordanNo ratings yet