
t04 Nested Evaluation
t04 Nested Evaluation
You might also like
- A Detailed Lesson Plan in Science 10Document6 pagesA Detailed Lesson Plan in Science 10Roldan Ormilla96% (50)
- Soalan Tugasan Jan 2023Document19 pagesSoalan Tugasan Jan 2023NURUL AIN BINTI RAPIAN STUDENTNo ratings yet
- Prelims StatsDocument39 pagesPrelims StatsSergioNo ratings yet
- 330 Lecture15 2014Document53 pages330 Lecture15 2014PiNo ratings yet
- 330 Lecture11 2014Document61 pages330 Lecture11 2014PETERNo ratings yet
- ExamplesR Power LawDocument12 pagesExamplesR Power LawKen MatsudaNo ratings yet
- pt4 Adv Regression Models PDFDocument170 pagespt4 Adv Regression Models PDFVishwajit kumarNo ratings yet
- Regression Analysis - From Statistics To Machine Learning: Ronald Hochreiter Sensational - AiDocument50 pagesRegression Analysis - From Statistics To Machine Learning: Ronald Hochreiter Sensational - AithcNo ratings yet
- Sim RDocument6 pagesSim Rsipho23No ratings yet
- 0E+00 2E+06 4E+06 6E+06 8E+06 1E+07 Purchtermlifeins$IncomeDocument1 page0E+00 2E+06 4E+06 6E+06 8E+06 1E+07 Purchtermlifeins$IncomedavidNo ratings yet
- Chapter 8Document4 pagesChapter 8Alain Michel KouiNo ratings yet
- HX 4Document1 pageHX 4drassuss45No ratings yet
- Week05 NotesDocument16 pagesWeek05 NoteshasankaraborkNo ratings yet
- C2 Statistical LearningDocument37 pagesC2 Statistical LearningLluïsa GualNo ratings yet
- Q Q Plot of Residuals: Batch# 1 Batch# 2 Batch# 3Document2 pagesQ Q Plot of Residuals: Batch# 1 Batch# 2 Batch# 3apsara karkiNo ratings yet
- Intro To Statistical LearningDocument46 pagesIntro To Statistical LearningalvinNo ratings yet
- 2014 TestDocument13 pages2014 TestAnonymous gUySMcpSqNo ratings yet
- Normal Q Q Plot (Sepal - Length) Normal Q Q Plot (Sepal - Width)Document1 pageNormal Q Q Plot (Sepal - Length) Normal Q Q Plot (Sepal - Width)Carlos MunozNo ratings yet
- ClusteringDocument62 pagesClusteringRichard RichieNo ratings yet
- Model Visualisation: (With Ggplot2)Document25 pagesModel Visualisation: (With Ggplot2)api-14814295No ratings yet
- LocalGLMnet: A Deep Learning Architecture For ActuariesDocument35 pagesLocalGLMnet: A Deep Learning Architecture For Actuariespapatest123No ratings yet
- 0 200 400 600 800 1000 1200 1400 Try2$Operating - Days (Try2$Well - Num "Wellnum 17963")Document4 pages0 200 400 600 800 1000 1200 1400 Try2$Operating - Days (Try2$Well - Num "Wellnum 17963")Luthfi SaifudinNo ratings yet
- MRT 3020 Vantage Galan 3T V6 Brochure MCAMR0170EADocument21 pagesMRT 3020 Vantage Galan 3T V6 Brochure MCAMR0170EAminhhoangtranvpNo ratings yet
- 330 Lecture9 2014Document40 pages330 Lecture9 2014Anonymous gUySMcpSqNo ratings yet
- Lecture 07Document16 pagesLecture 07Deepak Kumar YadavNo ratings yet
- MRT 1550 Vantage Orian Brochure MCAMR0143EADocument19 pagesMRT 1550 Vantage Orian Brochure MCAMR0143EASarpras RumkitNo ratings yet
- 2.lecture2 AteDocument61 pages2.lecture2 AteMarc RomaníNo ratings yet
- RplotsDocument8 pagesRplotsveyeho1025No ratings yet
- K-Means Vs Mini Batch K-Means: A ComparisonDocument12 pagesK-Means Vs Mini Batch K-Means: A Comparisonrather AarifNo ratings yet
- Week 4, Solution: Exercise 4.38Document15 pagesWeek 4, Solution: Exercise 4.38John SmithNo ratings yet
- 330 Lecture8 2014Document34 pages330 Lecture8 2014Anonymous gUySMcpSqNo ratings yet
- Clustering and The K - Means Algorithm: David M. BleiDocument128 pagesClustering and The K - Means Algorithm: David M. BleiasdasdNo ratings yet
- Midterm Test: Reaction Times Vs Caffeine IntakeDocument2 pagesMidterm Test: Reaction Times Vs Caffeine IntakeAnonymous gUySMcpSqNo ratings yet
- Week06 NotesDocument15 pagesWeek06 NoteshasankaraborkNo ratings yet
- Lect6 PDFDocument22 pagesLect6 PDF杜晓晚No ratings yet
- 5 Regression PDFDocument115 pages5 Regression PDFhawk91No ratings yet
- SLR NotesDocument96 pagesSLR NotesRafi DawarNo ratings yet
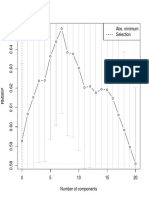
- Abs. Minimum SelectionDocument2 pagesAbs. Minimum SelectionAlejandro RomeroNo ratings yet
- 330 Lecture8 2015Document33 pages330 Lecture8 2015Anonymous gUySMcpSqNo ratings yet
- Chapter 2Document4 pagesChapter 2Alain Michel KouiNo ratings yet
- RQ RegsplineDocument1 pageRQ RegsplinerojasleopNo ratings yet
- Lpic Package - L TEX Over Graphics: Vinh Q. NguyenDocument4 pagesLpic Package - L TEX Over Graphics: Vinh Q. Nguyenvinhdizzo6130No ratings yet
- Ggplot2 Course2 ch5 SlidesDocument23 pagesGgplot2 Course2 ch5 SlidesSxk 333No ratings yet
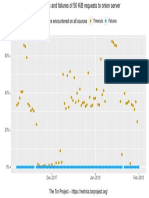
- Problems Encountered On All Sources: Timeouts FailuresDocument1 pageProblems Encountered On All Sources: Timeouts FailuresPatrick PerezNo ratings yet
- Seppo Pynn Onen Econometrics IDocument22 pagesSeppo Pynn Onen Econometrics Iorxanmeh100% (1)
- Attributes Skills Other Traits: Mental Health Merits Willpower Vitae Disciplines FlawsDocument4 pagesAttributes Skills Other Traits: Mental Health Merits Willpower Vitae Disciplines FlawsВладимир Иванович ЛебедевNo ratings yet
- MissingdataDocument10 pagesMissingdataAyaan ShahNo ratings yet
- V64i04 PDFDocument34 pagesV64i04 PDFElíGomaraGilNo ratings yet
- Matts Geist CharDocument4 pagesMatts Geist CharAnthony GowerNo ratings yet
- Pnas 1811269115 SappDocument25 pagesPnas 1811269115 Sappbahix27973No ratings yet
- RQ Mcycle1Document1 pageRQ Mcycle1rojasleopNo ratings yet
- Maya (Claire Jones) NPC Avatar Benefactor Survivor Questing Orphan NoneDocument4 pagesMaya (Claire Jones) NPC Avatar Benefactor Survivor Questing Orphan NoneAvatar_MagusNo ratings yet
- James Randolf Chambers - Wolf-Blooded Fetish CrafterDocument5 pagesJames Randolf Chambers - Wolf-Blooded Fetish CrafterJohn R LaytonNo ratings yet
- Introduction To Time Series Analysis: Welcome To The Course!Document20 pagesIntroduction To Time Series Analysis: Welcome To The Course!enrique gonzalez duranNo ratings yet
- Damion, Serial Killer ProphetDocument4 pagesDamion, Serial Killer ProphetAlan RideoutNo ratings yet
- Math 141: Lecture 18: Correlation and RegressionDocument26 pagesMath 141: Lecture 18: Correlation and RegressionCory DimagibaNo ratings yet
- Module3 Part5 Two Sample T ProcedureDocument42 pagesModule3 Part5 Two Sample T ProcedureDaniel RiosNo ratings yet
- Attributes: Second Edition The LostDocument4 pagesAttributes: Second Edition The Lostdarkwatchman932No ratings yet
- Lecture 21Document6 pagesLecture 21Lasme Ephrem DominiqueNo ratings yet
- Multivariate Statistics Principal Component Analysis (PCA)Document41 pagesMultivariate Statistics Principal Component Analysis (PCA)Axesh VamjaNo ratings yet
- SallyDocument2 pagesSallyAlex McGintyNo ratings yet
- Department of Education: Republic of The PhilippinesDocument19 pagesDepartment of Education: Republic of The PhilippinesMark Nathaniel RevillaNo ratings yet
- Flexible Coupling AssemblyDocument1 pageFlexible Coupling AssemblybluebirdNo ratings yet
- Brushless DC Motor Project in An Introduction To Electrical Engineering Course PDFDocument9 pagesBrushless DC Motor Project in An Introduction To Electrical Engineering Course PDFArturoDellaMadalenaNo ratings yet
- Đ1ko ĐáDocument4 pagesĐ1ko ĐábestspadNo ratings yet
- Chapter #4 - Machine LearningDocument29 pagesChapter #4 - Machine Learningmzoon mohmmedNo ratings yet
- Delhi Public School Secunderabad Mahendra Hills/ Nacharam / Nadergul Nursery Log Sheet-March/April 2019-2020Document3 pagesDelhi Public School Secunderabad Mahendra Hills/ Nacharam / Nadergul Nursery Log Sheet-March/April 2019-2020Khushal ChoudharyNo ratings yet
- The Enlightenment, The Age of ReasonDocument40 pagesThe Enlightenment, The Age of ReasonRahma MohamedNo ratings yet
- Gawain 7 Pagkakabuo NG DaigdigDocument3 pagesGawain 7 Pagkakabuo NG DaigdigRudy ClariñoNo ratings yet
- Extraordinary Construction On GermanyDocument1 pageExtraordinary Construction On Germanyzainulmhd867No ratings yet
- Introduction To EarthquakesDocument13 pagesIntroduction To EarthquakesSheikh_MutaharNo ratings yet
- LC Vco ThesisDocument8 pagesLC Vco Thesissarareedannarbor100% (2)
- Numerology Basic CompressedDocument39 pagesNumerology Basic CompressedtouchvikrantNo ratings yet
- Clases 09 Avian EncephalomyelitisDocument31 pagesClases 09 Avian EncephalomyelitisMijael ChoqueNo ratings yet
- MiddleMagdalena Ramon&CrossDocument30 pagesMiddleMagdalena Ramon&CrossLaura Melendez RuedaNo ratings yet
- SUBMITTED-full - TRUESOILDocument103 pagesSUBMITTED-full - TRUESOILAndi Alfi SyahrinNo ratings yet
- ENGL 102 Mixed Tense Exercises (8 Tenses)Document22 pagesENGL 102 Mixed Tense Exercises (8 Tenses)na-labbadNo ratings yet
- Csc271 Exam 9Document5 pagesCsc271 Exam 9NabiLNo ratings yet
- Environmental LawDocument46 pagesEnvironmental LawRohit100% (1)
- Controller FIS134 19-22 EN PDFDocument4 pagesController FIS134 19-22 EN PDFrimce77No ratings yet
- Unit 1.editedDocument8 pagesUnit 1.editedasia sultanNo ratings yet
- Tecsis P3276Document4 pagesTecsis P3276benNo ratings yet
- Fenwick - The Failure of The League of NationsDocument5 pagesFenwick - The Failure of The League of NationsEmre CinarNo ratings yet
- Moral Sensitivity and The Limits of Artificial Moral Agents: Joris GraffDocument12 pagesMoral Sensitivity and The Limits of Artificial Moral Agents: Joris Graffcarbet_vrilNo ratings yet
- Automelt S33Document2 pagesAutomelt S33gopuvinu4uNo ratings yet
- Numerical Study On Application of CuO-Water NanoflDocument7 pagesNumerical Study On Application of CuO-Water NanoflvinodNo ratings yet
- Guidebook For Developing A Zero - or Low-Emissions Roadmap at AirportsDocument107 pagesGuidebook For Developing A Zero - or Low-Emissions Roadmap at AirportsTRUMPET OF GODNo ratings yet
- Tutorial 2 EOPDocument3 pagesTutorial 2 EOPammarNo ratings yet
- History of English LanguageDocument3 pagesHistory of English LanguageMary Madelene Armenta100% (1)
























































































Download as pdf or txt
You might also like
- A Detailed Lesson Plan in Science 10Document6 pagesA Detailed Lesson Plan in Science 10Roldan Ormilla96% (50)
- Soalan Tugasan Jan 2023Document19 pagesSoalan Tugasan Jan 2023NURUL AIN BINTI RAPIAN STUDENTNo ratings yet
- Prelims StatsDocument39 pagesPrelims StatsSergioNo ratings yet
- 330 Lecture15 2014Document53 pages330 Lecture15 2014PiNo ratings yet
- 330 Lecture11 2014Document61 pages330 Lecture11 2014PETERNo ratings yet
- ExamplesR Power LawDocument12 pagesExamplesR Power LawKen MatsudaNo ratings yet
- pt4 Adv Regression Models PDFDocument170 pagespt4 Adv Regression Models PDFVishwajit kumarNo ratings yet
- Regression Analysis - From Statistics To Machine Learning: Ronald Hochreiter Sensational - AiDocument50 pagesRegression Analysis - From Statistics To Machine Learning: Ronald Hochreiter Sensational - AithcNo ratings yet
- Sim RDocument6 pagesSim Rsipho23No ratings yet
- 0E+00 2E+06 4E+06 6E+06 8E+06 1E+07 Purchtermlifeins$IncomeDocument1 page0E+00 2E+06 4E+06 6E+06 8E+06 1E+07 Purchtermlifeins$IncomedavidNo ratings yet
- Chapter 8Document4 pagesChapter 8Alain Michel KouiNo ratings yet
- HX 4Document1 pageHX 4drassuss45No ratings yet
- Week05 NotesDocument16 pagesWeek05 NoteshasankaraborkNo ratings yet
- C2 Statistical LearningDocument37 pagesC2 Statistical LearningLluïsa GualNo ratings yet
- Q Q Plot of Residuals: Batch# 1 Batch# 2 Batch# 3Document2 pagesQ Q Plot of Residuals: Batch# 1 Batch# 2 Batch# 3apsara karkiNo ratings yet
- Intro To Statistical LearningDocument46 pagesIntro To Statistical LearningalvinNo ratings yet
- 2014 TestDocument13 pages2014 TestAnonymous gUySMcpSqNo ratings yet
- Normal Q Q Plot (Sepal - Length) Normal Q Q Plot (Sepal - Width)Document1 pageNormal Q Q Plot (Sepal - Length) Normal Q Q Plot (Sepal - Width)Carlos MunozNo ratings yet
- ClusteringDocument62 pagesClusteringRichard RichieNo ratings yet
- Model Visualisation: (With Ggplot2)Document25 pagesModel Visualisation: (With Ggplot2)api-14814295No ratings yet
- LocalGLMnet: A Deep Learning Architecture For ActuariesDocument35 pagesLocalGLMnet: A Deep Learning Architecture For Actuariespapatest123No ratings yet
- 0 200 400 600 800 1000 1200 1400 Try2$Operating - Days (Try2$Well - Num "Wellnum 17963")Document4 pages0 200 400 600 800 1000 1200 1400 Try2$Operating - Days (Try2$Well - Num "Wellnum 17963")Luthfi SaifudinNo ratings yet
- MRT 3020 Vantage Galan 3T V6 Brochure MCAMR0170EADocument21 pagesMRT 3020 Vantage Galan 3T V6 Brochure MCAMR0170EAminhhoangtranvpNo ratings yet
- 330 Lecture9 2014Document40 pages330 Lecture9 2014Anonymous gUySMcpSqNo ratings yet
- Lecture 07Document16 pagesLecture 07Deepak Kumar YadavNo ratings yet
- MRT 1550 Vantage Orian Brochure MCAMR0143EADocument19 pagesMRT 1550 Vantage Orian Brochure MCAMR0143EASarpras RumkitNo ratings yet
- 2.lecture2 AteDocument61 pages2.lecture2 AteMarc RomaníNo ratings yet
- RplotsDocument8 pagesRplotsveyeho1025No ratings yet
- K-Means Vs Mini Batch K-Means: A ComparisonDocument12 pagesK-Means Vs Mini Batch K-Means: A Comparisonrather AarifNo ratings yet
- Week 4, Solution: Exercise 4.38Document15 pagesWeek 4, Solution: Exercise 4.38John SmithNo ratings yet
- 330 Lecture8 2014Document34 pages330 Lecture8 2014Anonymous gUySMcpSqNo ratings yet
- Clustering and The K - Means Algorithm: David M. BleiDocument128 pagesClustering and The K - Means Algorithm: David M. BleiasdasdNo ratings yet
- Midterm Test: Reaction Times Vs Caffeine IntakeDocument2 pagesMidterm Test: Reaction Times Vs Caffeine IntakeAnonymous gUySMcpSqNo ratings yet
- Week06 NotesDocument15 pagesWeek06 NoteshasankaraborkNo ratings yet
- Lect6 PDFDocument22 pagesLect6 PDF杜晓晚No ratings yet
- 5 Regression PDFDocument115 pages5 Regression PDFhawk91No ratings yet
- SLR NotesDocument96 pagesSLR NotesRafi DawarNo ratings yet
- Abs. Minimum SelectionDocument2 pagesAbs. Minimum SelectionAlejandro RomeroNo ratings yet
- 330 Lecture8 2015Document33 pages330 Lecture8 2015Anonymous gUySMcpSqNo ratings yet
- Chapter 2Document4 pagesChapter 2Alain Michel KouiNo ratings yet
- RQ RegsplineDocument1 pageRQ RegsplinerojasleopNo ratings yet
- Lpic Package - L TEX Over Graphics: Vinh Q. NguyenDocument4 pagesLpic Package - L TEX Over Graphics: Vinh Q. Nguyenvinhdizzo6130No ratings yet
- Ggplot2 Course2 ch5 SlidesDocument23 pagesGgplot2 Course2 ch5 SlidesSxk 333No ratings yet
- Problems Encountered On All Sources: Timeouts FailuresDocument1 pageProblems Encountered On All Sources: Timeouts FailuresPatrick PerezNo ratings yet
- Seppo Pynn Onen Econometrics IDocument22 pagesSeppo Pynn Onen Econometrics Iorxanmeh100% (1)
- Attributes Skills Other Traits: Mental Health Merits Willpower Vitae Disciplines FlawsDocument4 pagesAttributes Skills Other Traits: Mental Health Merits Willpower Vitae Disciplines FlawsВладимир Иванович ЛебедевNo ratings yet
- MissingdataDocument10 pagesMissingdataAyaan ShahNo ratings yet
- V64i04 PDFDocument34 pagesV64i04 PDFElíGomaraGilNo ratings yet
- Matts Geist CharDocument4 pagesMatts Geist CharAnthony GowerNo ratings yet
- Pnas 1811269115 SappDocument25 pagesPnas 1811269115 Sappbahix27973No ratings yet
- RQ Mcycle1Document1 pageRQ Mcycle1rojasleopNo ratings yet
- Maya (Claire Jones) NPC Avatar Benefactor Survivor Questing Orphan NoneDocument4 pagesMaya (Claire Jones) NPC Avatar Benefactor Survivor Questing Orphan NoneAvatar_MagusNo ratings yet
- James Randolf Chambers - Wolf-Blooded Fetish CrafterDocument5 pagesJames Randolf Chambers - Wolf-Blooded Fetish CrafterJohn R LaytonNo ratings yet
- Introduction To Time Series Analysis: Welcome To The Course!Document20 pagesIntroduction To Time Series Analysis: Welcome To The Course!enrique gonzalez duranNo ratings yet
- Damion, Serial Killer ProphetDocument4 pagesDamion, Serial Killer ProphetAlan RideoutNo ratings yet
- Math 141: Lecture 18: Correlation and RegressionDocument26 pagesMath 141: Lecture 18: Correlation and RegressionCory DimagibaNo ratings yet
- Module3 Part5 Two Sample T ProcedureDocument42 pagesModule3 Part5 Two Sample T ProcedureDaniel RiosNo ratings yet
- Attributes: Second Edition The LostDocument4 pagesAttributes: Second Edition The Lostdarkwatchman932No ratings yet
- Lecture 21Document6 pagesLecture 21Lasme Ephrem DominiqueNo ratings yet
- Multivariate Statistics Principal Component Analysis (PCA)Document41 pagesMultivariate Statistics Principal Component Analysis (PCA)Axesh VamjaNo ratings yet
- SallyDocument2 pagesSallyAlex McGintyNo ratings yet
- Department of Education: Republic of The PhilippinesDocument19 pagesDepartment of Education: Republic of The PhilippinesMark Nathaniel RevillaNo ratings yet
- Flexible Coupling AssemblyDocument1 pageFlexible Coupling AssemblybluebirdNo ratings yet
- Brushless DC Motor Project in An Introduction To Electrical Engineering Course PDFDocument9 pagesBrushless DC Motor Project in An Introduction To Electrical Engineering Course PDFArturoDellaMadalenaNo ratings yet
- Đ1ko ĐáDocument4 pagesĐ1ko ĐábestspadNo ratings yet
- Chapter #4 - Machine LearningDocument29 pagesChapter #4 - Machine Learningmzoon mohmmedNo ratings yet
- Delhi Public School Secunderabad Mahendra Hills/ Nacharam / Nadergul Nursery Log Sheet-March/April 2019-2020Document3 pagesDelhi Public School Secunderabad Mahendra Hills/ Nacharam / Nadergul Nursery Log Sheet-March/April 2019-2020Khushal ChoudharyNo ratings yet
- The Enlightenment, The Age of ReasonDocument40 pagesThe Enlightenment, The Age of ReasonRahma MohamedNo ratings yet
- Gawain 7 Pagkakabuo NG DaigdigDocument3 pagesGawain 7 Pagkakabuo NG DaigdigRudy ClariñoNo ratings yet
- Extraordinary Construction On GermanyDocument1 pageExtraordinary Construction On Germanyzainulmhd867No ratings yet
- Introduction To EarthquakesDocument13 pagesIntroduction To EarthquakesSheikh_MutaharNo ratings yet
- LC Vco ThesisDocument8 pagesLC Vco Thesissarareedannarbor100% (2)
- Numerology Basic CompressedDocument39 pagesNumerology Basic CompressedtouchvikrantNo ratings yet
- Clases 09 Avian EncephalomyelitisDocument31 pagesClases 09 Avian EncephalomyelitisMijael ChoqueNo ratings yet
- MiddleMagdalena Ramon&CrossDocument30 pagesMiddleMagdalena Ramon&CrossLaura Melendez RuedaNo ratings yet
- SUBMITTED-full - TRUESOILDocument103 pagesSUBMITTED-full - TRUESOILAndi Alfi SyahrinNo ratings yet
- ENGL 102 Mixed Tense Exercises (8 Tenses)Document22 pagesENGL 102 Mixed Tense Exercises (8 Tenses)na-labbadNo ratings yet
- Csc271 Exam 9Document5 pagesCsc271 Exam 9NabiLNo ratings yet
- Environmental LawDocument46 pagesEnvironmental LawRohit100% (1)
- Controller FIS134 19-22 EN PDFDocument4 pagesController FIS134 19-22 EN PDFrimce77No ratings yet
- Unit 1.editedDocument8 pagesUnit 1.editedasia sultanNo ratings yet
- Tecsis P3276Document4 pagesTecsis P3276benNo ratings yet
- Fenwick - The Failure of The League of NationsDocument5 pagesFenwick - The Failure of The League of NationsEmre CinarNo ratings yet
- Moral Sensitivity and The Limits of Artificial Moral Agents: Joris GraffDocument12 pagesMoral Sensitivity and The Limits of Artificial Moral Agents: Joris Graffcarbet_vrilNo ratings yet
- Automelt S33Document2 pagesAutomelt S33gopuvinu4uNo ratings yet
- Numerical Study On Application of CuO-Water NanoflDocument7 pagesNumerical Study On Application of CuO-Water NanoflvinodNo ratings yet
- Guidebook For Developing A Zero - or Low-Emissions Roadmap at AirportsDocument107 pagesGuidebook For Developing A Zero - or Low-Emissions Roadmap at AirportsTRUMPET OF GODNo ratings yet
- Tutorial 2 EOPDocument3 pagesTutorial 2 EOPammarNo ratings yet
- History of English LanguageDocument3 pagesHistory of English LanguageMary Madelene Armenta100% (1)