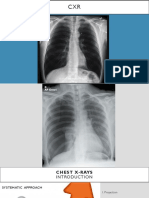
Download as pdf or txt
You might also like
- Human Biology 16th Mader Test Bank PDFDocument28 pagesHuman Biology 16th Mader Test Bank PDFkuldeep saini100% (1)
- 2010 CC 3.6 Engine Schematic R36Document19 pages2010 CC 3.6 Engine Schematic R36Dungani AllanNo ratings yet
- Basic of Thorax Imaging - 10 September 2013 - by Robby HermawanDocument126 pagesBasic of Thorax Imaging - 10 September 2013 - by Robby HermawanenriNo ratings yet
- Handle Large Messages in Apache KafkaDocument59 pagesHandle Large Messages in Apache KafkaBùi Văn KiênNo ratings yet
- Library Management SystemDocument58 pagesLibrary Management SystemPurushottam Choudhary100% (9)
- Lung Ultrasound Made Easy Step-By-Step GuideDocument48 pagesLung Ultrasound Made Easy Step-By-Step GuideEL SHITA100% (1)
- Interpreting A Chest X-RayDocument5 pagesInterpreting A Chest X-Rayrodolfo gorveñaNo ratings yet
- Chest X - Ray: Physiotherapy in Cardio-Respiratory Disorders & Intensive Care ManagementDocument25 pagesChest X - Ray: Physiotherapy in Cardio-Respiratory Disorders & Intensive Care ManagementSravan SNo ratings yet
- Gambaran Radiologis Pada Kegawatan Paru: Farah Fatma WatiDocument42 pagesGambaran Radiologis Pada Kegawatan Paru: Farah Fatma WatisabariaNo ratings yet
- Chest X-Ray Interpretation A Structured Approach Radiology OSCEDocument1 pageChest X-Ray Interpretation A Structured Approach Radiology OSCEValentina SepúlvedaNo ratings yet
- Radiology Lecture 4th Year 2022 Part 2Document44 pagesRadiology Lecture 4th Year 2022 Part 2Abubakar JallohNo ratings yet
- Coursebook-Echocardiography ch33Document21 pagesCoursebook-Echocardiography ch33ghina athirah100% (1)
- Imaging - Lecture 2 (Chest Radiography)Document8 pagesImaging - Lecture 2 (Chest Radiography)Adham MohamedNo ratings yet
- Thoracic Ultrasonography A Narrative ReviewDocument12 pagesThoracic Ultrasonography A Narrative ReviewJHONATAN MATA ARANDANo ratings yet
- Chest Xray BasicsDocument47 pagesChest Xray BasicsPartha GanesanNo ratings yet
- 2 1 Diseases of The Respiratory System Radiological Pathology DRDocument43 pages2 1 Diseases of The Respiratory System Radiological Pathology DRNatnael GetahunNo ratings yet
- Chest Anatomy. Chest AnatomyDocument70 pagesChest Anatomy. Chest AnatomydrelvNo ratings yet
- En Aop06912Document9 pagesEn Aop06912Dian Putri NingsihNo ratings yet
- Dr. Dicky SP.P Materi Gawat Darurat ParuDocument41 pagesDr. Dicky SP.P Materi Gawat Darurat ParuYuni SaviraNo ratings yet
- Use of Ultrasound in The ICU BestPracResearAnest 2009Document13 pagesUse of Ultrasound in The ICU BestPracResearAnest 2009RicardoNo ratings yet
- Posteroanterior Chest X-Ray For The Diagnosis of Pneumothorax: Methods, Usage, and ResolutionDocument6 pagesPosteroanterior Chest X-Ray For The Diagnosis of Pneumothorax: Methods, Usage, and ResolutionShaeli MalikNo ratings yet
- Chest X-Ray Fundamentals: Dr. Emad EfatDocument241 pagesChest X-Ray Fundamentals: Dr. Emad EfatRutvik Shah100% (1)
- Echocardiography Dissertation IdeasDocument8 pagesEchocardiography Dissertation IdeasWhoCanWriteMyPaperForMeCanada100% (1)
- How To Auscultate For Heart Sounds in Adults: Evidence & PracticeDocument3 pagesHow To Auscultate For Heart Sounds in Adults: Evidence & Practiceangela mamauagNo ratings yet
- Blue Protocol. Lung Ultrasound in The Critically IllDocument12 pagesBlue Protocol. Lung Ultrasound in The Critically IllRomina Alfonsina Decap CarrascoNo ratings yet
- 0256 Version 2019Document66 pages0256 Version 2019vanessa armeliaNo ratings yet
- Application Note - Pulmonary Hypertension and The VevoDocument5 pagesApplication Note - Pulmonary Hypertension and The VevoVisualSonicsNo ratings yet
- Lateral Chest Radiograph Feigin2010Document7 pagesLateral Chest Radiograph Feigin2010A.h.MuradNo ratings yet
- Chest X-Ray InterpretationDocument30 pagesChest X-Ray InterpretationNuru99100% (19)
- Topic 20. X-RayDocument4 pagesTopic 20. X-RayMadeline WanhartNo ratings yet
- Ecografia Toracica PDFDocument12 pagesEcografia Toracica PDFCristinaLucanNo ratings yet
- (The Chest X-Ray)Document13 pages(The Chest X-Ray)RD Dha mhmdNo ratings yet
- Radiography of The Thorax: BY Abubakar ADocument70 pagesRadiography of The Thorax: BY Abubakar AJameeluh TijjanyNo ratings yet
- Basic of Thorax Imaging - 10 September 2013 - by Robby HermawanDocument126 pagesBasic of Thorax Imaging - 10 September 2013 - by Robby HermawanDwi putri PermatasariNo ratings yet
- Chest X-Ray GuideDocument26 pagesChest X-Ray GuideRizky Ayu WirdaningsiNo ratings yet
- Surgery Cases: CASE 2: Chest Abdominal TraumaDocument3 pagesSurgery Cases: CASE 2: Chest Abdominal TraumaGio Tamaño BalisiNo ratings yet
- Basic Chest RadDocument112 pagesBasic Chest Radtesfayegermame95.tgNo ratings yet
- X-Ray Interpretation PDFDocument41 pagesX-Ray Interpretation PDFNaveen Koval100% (2)
- Radiological Assessment of Lung Disease in Small Animals 1. Bronchial and Vascular PatternsDocument9 pagesRadiological Assessment of Lung Disease in Small Animals 1. Bronchial and Vascular PatternsSamantha Orozco PinedaNo ratings yet
- Chest RadiographyDocument65 pagesChest RadiographyMunish Dogra100% (1)
- Basic Chest Imaging and Heart FailureDocument57 pagesBasic Chest Imaging and Heart FailureKiaa auliaNo ratings yet
- ABC ChestDocument4 pagesABC ChestSintounNo ratings yet
- Thoracic Imaging Radiographic BasicsDocument130 pagesThoracic Imaging Radiographic BasicsIsak ShatikaNo ratings yet
- Resistance Index in Mediastinal Lymph Nodes: A Feasibility StudyDocument3 pagesResistance Index in Mediastinal Lymph Nodes: A Feasibility StudyAl RawdhaNo ratings yet
- IImage Critique &pattern Recognition-1Document52 pagesIImage Critique &pattern Recognition-1Rabiu Salisu yunusaNo ratings yet
- Diagnosis of Traumatic Pneumothorax - Comparison Between Lung Ultrasound and Supine Chest RadiographsDocument5 pagesDiagnosis of Traumatic Pneumothorax - Comparison Between Lung Ultrasound and Supine Chest RadiographssepputriNo ratings yet
- RadioDocument58 pagesRadioMohSallakNo ratings yet
- Cardiac Imaging Sept 2016tDocument254 pagesCardiac Imaging Sept 2016tColeen Joyce NeyraNo ratings yet
- Basic of Thorax Imaging - 10 September 2013 - by Robby HermawanDocument126 pagesBasic of Thorax Imaging - 10 September 2013 - by Robby HermawannuradilahyasminNo ratings yet
- Echo KibuddeDocument54 pagesEcho KibuddeTrevor Ishmael SiakambaNo ratings yet
- Potential Bene Fits of Crawl Position For Prone Radiation Therapy in Breast CancerDocument6 pagesPotential Bene Fits of Crawl Position For Prone Radiation Therapy in Breast CancerBambang YulikNo ratings yet
- Medical Investigations PDFDocument136 pagesMedical Investigations PDFFathy ElsheshtawyNo ratings yet
- Differences in Left Ventricular and Left Atrial FuDocument10 pagesDifferences in Left Ventricular and Left Atrial FueugeniaNo ratings yet
- Concept Mapping - FullDocument24 pagesConcept Mapping - Fulliamlibertarian100% (3)
- Assessment of Left Ventricular Volumes and Primary Mitral Regurgitation Severity by 2D Echocardiography and Cardiovascular Magnetic ResonanceDocument7 pagesAssessment of Left Ventricular Volumes and Primary Mitral Regurgitation Severity by 2D Echocardiography and Cardiovascular Magnetic ResonancePanfilAlinaNo ratings yet
- Echo Guidelines For Chamber QuantificationDocument24 pagesEcho Guidelines For Chamber QuantificationOnon EssayedNo ratings yet
- Transthoracic Right Heart Echocardiography For The IntensivistDocument12 pagesTransthoracic Right Heart Echocardiography For The IntensivistAyong DamaledoNo ratings yet
- Interpretation of Chest RadiographDocument7 pagesInterpretation of Chest RadiographhengkileonardNo ratings yet
- CTTN Radiology Cibinong 1Document5 pagesCTTN Radiology Cibinong 1arikamanjayaNo ratings yet
- Duplex and Color Doppler Imaging of the Venous SystemFrom EverandDuplex and Color Doppler Imaging of the Venous SystemGerhard H. MostbeckNo ratings yet
- Pulmonary Functional Imaging: Basics and Clinical ApplicationsFrom EverandPulmonary Functional Imaging: Basics and Clinical ApplicationsYoshiharu OhnoNo ratings yet
- Telergon CosDocument20 pagesTelergon CosDicky FirmansyahNo ratings yet
- 1 Design Thinking Renato BragaDocument68 pages1 Design Thinking Renato BragaLv AHNo ratings yet
- Cell Theory PowerPointDocument17 pagesCell Theory PowerPointTrinna AbrigoNo ratings yet
- Kargil Diwas Script - 230712 - 224828Document4 pagesKargil Diwas Script - 230712 - 224828kashyapakarshanaNo ratings yet
- Service Sheet - Mercedes Benz W211Document8 pagesService Sheet - Mercedes Benz W211Pedro ViegasNo ratings yet
- Wtt12L-B2562: PowerproxDocument7 pagesWtt12L-B2562: PowerproxJCNo ratings yet
- Mcdonald 39 S Delivering A Streamlined Payroll SolutionDocument2 pagesMcdonald 39 S Delivering A Streamlined Payroll SolutionVarun GoswamiNo ratings yet
- Antibiogram of Bacterial Isolates From Cervico-Vaginal Mucus (CVM) of Endometritic CowsDocument5 pagesAntibiogram of Bacterial Isolates From Cervico-Vaginal Mucus (CVM) of Endometritic CowsY.rajuNo ratings yet
- Frank Kitson Warfare WholeDocument96 pagesFrank Kitson Warfare WholeDaniel RubinsteinNo ratings yet
- UntitledDocument20 pagesUntitledErica FieldNo ratings yet
- Read Online Textbook Ana Maria and The Fox Liana de La Rosa Ebook All Chapter PDFDocument22 pagesRead Online Textbook Ana Maria and The Fox Liana de La Rosa Ebook All Chapter PDFkristina.burton396100% (6)
- Av IndustryDocument1 pageAv IndustryMitochiNo ratings yet
- MTTRAPD Huaweii2000 cl2Document3,295 pagesMTTRAPD Huaweii2000 cl2Muhammad AdnanNo ratings yet
- Manta Ray: © 2008 Brigitte Read. All Rights Reserved To Report Errors With This Pattern ContactDocument2 pagesManta Ray: © 2008 Brigitte Read. All Rights Reserved To Report Errors With This Pattern ContactMarta Lobo100% (2)
- Childrens Health First McKinsey Report 2006Document64 pagesChildrens Health First McKinsey Report 2006Rachel LavinNo ratings yet
- ATO SubstitutionDocument1 pageATO SubstitutionMaggie VillacortaNo ratings yet
- English ReviewerDocument11 pagesEnglish ReviewerShinjiNo ratings yet
- Compressor Dry Gas SealsDocument12 pagesCompressor Dry Gas SealsRajeev Domble100% (3)
- 3p. IS 8910 - 1998 - OLDDocument17 pages3p. IS 8910 - 1998 - OLDhhr2412No ratings yet
- The World Is An Apple (Script)Document8 pagesThe World Is An Apple (Script)armandNo ratings yet
- ME PED-Scheme & Syllabus 2018Document21 pagesME PED-Scheme & Syllabus 2018Angamuthu AnanthNo ratings yet
- Ch4 BootstrapDocument90 pagesCh4 BootstrapDaniels PicturesNo ratings yet
- Business Studies 2021 HSC Exam Pack NSW Education StandardsDocument3 pagesBusiness Studies 2021 HSC Exam Pack NSW Education Standardsmxstiia10No ratings yet
- Eng3-Sim Q1M6Document20 pagesEng3-Sim Q1M6Shekinah GrumoNo ratings yet
- Astm A573Document2 pagesAstm A573akhilsyam21No ratings yet
- Air Models Full CatalogDocument64 pagesAir Models Full CatalogErnesto de la TorreNo ratings yet