
Predictive Modelling Project 2
Predictive Modelling Project 2
You might also like
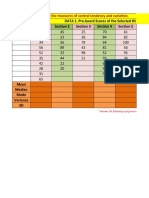
- DATA 1. Pre-Board Scores of The Selected BS Education Students (Per Section) Section 1 Section 2 Section 3 Section 4 Section 5Document10 pagesDATA 1. Pre-Board Scores of The Selected BS Education Students (Per Section) Section 1 Section 2 Section 3 Section 4 Section 5ariane galeno100% (1)
- Decision Making: Submitted By-Ankita MishraDocument20 pagesDecision Making: Submitted By-Ankita MishraAnkita MishraNo ratings yet
- Clustering Clean Ads - DataDocument1,657 pagesClustering Clean Ads - Dataaman gautam0% (1)
- E-Commerce Revenue Management - Python For Data Science - Great LearningDocument4 pagesE-Commerce Revenue Management - Python For Data Science - Great LearningSuchi S Bahuguna100% (1)
- MRA Project Milestone2 PDFDocument1 pageMRA Project Milestone2 PDFRekha Rajaram100% (1)
- DM Gopala Satish Kumar Business Report G8 DSBADocument26 pagesDM Gopala Satish Kumar Business Report G8 DSBASatish Kumar100% (2)
- Asphalt Shingles Data Analysis PDFDocument4 pagesAsphalt Shingles Data Analysis PDFsonali PradhanNo ratings yet
- Assignment ClusteringDocument22 pagesAssignment ClusteringNetra RainaNo ratings yet
- Factor-Hair RV PDFDocument23 pagesFactor-Hair RV PDFRamachandran VenkataramanNo ratings yet
- One Way AnovaDocument35 pagesOne Way AnovaNinuca ChanturiaNo ratings yet
- VaibhavKumar Extendedproject PDFDocument10 pagesVaibhavKumar Extendedproject PDFAnshul Dyundi100% (2)
- Predictive Model: Submitted byDocument27 pagesPredictive Model: Submitted byAnkita Mishra100% (2)
- Girish Chadha - 29th December 2022Document35 pagesGirish Chadha - 29th December 2022Girish Chadha100% (3)
- Anshul Dyundi Predictive Modelling Alternate Project July 2022Document11 pagesAnshul Dyundi Predictive Modelling Alternate Project July 2022Anshul DyundiNo ratings yet
- Predictive Modeling Business Report Seetharaman Final Changes PDFDocument28 pagesPredictive Modeling Business Report Seetharaman Final Changes PDFAnkita Mishra100% (1)
- State Wise Health Income Clustering 18th December 2021 PDFDocument29 pagesState Wise Health Income Clustering 18th December 2021 PDFAnkita Mishra100% (1)
- Business Report: Predictive ModellingDocument37 pagesBusiness Report: Predictive Modellinghepzi selvam100% (1)
- Mini Project - Factor Hair Analysis: Sravanthi.MDocument24 pagesMini Project - Factor Hair Analysis: Sravanthi.MSweety Sekhar100% (1)
- Shivani Pandey TSFDocument32 pagesShivani Pandey TSFShivich10100% (1)
- Project QuestionsDocument3 pagesProject QuestionsravikgovinduNo ratings yet
- Predictive ModellingDocument58 pagesPredictive ModellingPranav Viswanathan100% (1)
- Data Mining Clustering PDFDocument15 pagesData Mining Clustering PDFSwing TradeNo ratings yet
- Predictive Modelling Alternative Firm Level PDFDocument26 pagesPredictive Modelling Alternative Firm Level PDFAnkita Mishra100% (4)
- Clustering ProjectDocument44 pagesClustering Projectkirti sharma100% (1)
- Predictive Modelling Report - ReshmaDocument20 pagesPredictive Modelling Report - Reshmareshma ajithNo ratings yet
- Suresh-Rose Time Series Forecasting Project ReportDocument75 pagesSuresh-Rose Time Series Forecasting Project ReportARCHANA R100% (1)
- Business Report Data MiningDocument29 pagesBusiness Report Data Mininghepzi selvamNo ratings yet
- SQL Quiz ResultsDocument17 pagesSQL Quiz ResultsJram MarjNo ratings yet
- Project Predictive Modeling PDFDocument58 pagesProject Predictive Modeling PDFAYUSH AWASTHI100% (1)
- DATA MINING PROJECT PAVITHRAA GOVINDARAJAN 24 OCT 2021 Jupyter Notebook PDFDocument49 pagesDATA MINING PROJECT PAVITHRAA GOVINDARAJAN 24 OCT 2021 Jupyter Notebook PDFGURUPADA PATI100% (2)
- Anshul Dyundi Machine Learning July 2022Document46 pagesAnshul Dyundi Machine Learning July 2022Anshul Dyundi50% (2)
- Time Series Rose Shehroz ArfeenDocument42 pagesTime Series Rose Shehroz ArfeenShehroz Khan100% (1)
- Business Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means ClusteringDocument28 pagesBusiness Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means Clusteringcrispin anthonyNo ratings yet
- Data Mining Assignment: Sudhanva SaralayaDocument16 pagesData Mining Assignment: Sudhanva SaralayaSudhanva S100% (1)
- Business Report Pradeep Chauhan 11june'23Document25 pagesBusiness Report Pradeep Chauhan 11june'23Pradeep ChauhanNo ratings yet
- SMDM-Project Report (Madhur Dhananiwala)Document43 pagesSMDM-Project Report (Madhur Dhananiwala)madhur dhananiwala100% (1)
- Week 1 Graded Quiz On Solution PDFDocument2 pagesWeek 1 Graded Quiz On Solution PDFlikhith krishnaNo ratings yet
- DataMining Aug2021Document49 pagesDataMining Aug2021sakshi narang100% (2)
- Project Time Series ForecastingDocument53 pagesProject Time Series Forecastingharish kumar100% (1)
- Machine Learning SolutionDocument12 pagesMachine Learning Solutionprabu2125100% (1)
- Shoe SalesDocument105 pagesShoe SalesRemyaRS100% (3)
- Data Mining Business ReportDocument38 pagesData Mining Business ReportThaku SinghNo ratings yet
- Rahulsharma - 03 12 23Document25 pagesRahulsharma - 03 12 23Rahul GautamNo ratings yet
- SMDM - Project Report - LakshmiDocument26 pagesSMDM - Project Report - LakshmiKannan NNo ratings yet
- SMDM Project ReportDocument19 pagesSMDM Project ReportSANJAY ANANDAN100% (1)
- Answer Book - Rose WinesDocument11 pagesAnswer Book - Rose WinesAshish Agrawal100% (1)
- VARUNSAINI - 11 Dec 2022Document16 pagesVARUNSAINI - 11 Dec 2022Varun SainiNo ratings yet
- Business Report MLDocument36 pagesBusiness Report MLSomnath Kumbhar100% (1)
- Revised Clustering Business ReportDocument5 pagesRevised Clustering Business ReportPratigya pathakNo ratings yet
- Answer Report: Data MiningDocument32 pagesAnswer Report: Data MiningChetan SharmaNo ratings yet
- Assignment MLDocument21 pagesAssignment MLManish Verma100% (2)
- Project - Time Series Forecasting (Sparkling - CSV) & (Rose - CSV)Document15 pagesProject - Time Series Forecasting (Sparkling - CSV) & (Rose - CSV)guillermo coco100% (1)
- Project Predictive ModelingDocument69 pagesProject Predictive Modelingyuktha50% (2)
- Machine Learning Business Report - Compress (AutoRecovered)Document69 pagesMachine Learning Business Report - Compress (AutoRecovered)Deepanshu Parashar100% (2)
- Education - Post 12th Standard - CSVDocument11 pagesEducation - Post 12th Standard - CSVRuhee's KitchenNo ratings yet
- Advance Statistics-Project ReportDocument17 pagesAdvance Statistics-Project ReportJimmi Pranami50% (2)
- Executive Sumary - Rajarshi Das (Data Visualization Using Tableau Project)Document11 pagesExecutive Sumary - Rajarshi Das (Data Visualization Using Tableau Project)Rajarshi DasNo ratings yet
- SMDM Project: Submitted By: Tina DasDocument15 pagesSMDM Project: Submitted By: Tina DasTina100% (1)
- Predictive Modelling ProjectDocument29 pagesPredictive Modelling ProjectPranjal SinghNo ratings yet
- ML Quiz 2Document1 pageML Quiz 2Ruwayda IbraheemNo ratings yet
- Pranjal - Singh - 30.10.2022 SMDM PROJECT REPORTDocument9 pagesPranjal - Singh - 30.10.2022 SMDM PROJECT REPORTPranjal SinghNo ratings yet
- Assignment Report - Predictive Modelling - Rahul DubeyDocument18 pagesAssignment Report - Predictive Modelling - Rahul DubeyRahulNo ratings yet
- Classical And. Modern Regression With Applications: DuxburyDocument7 pagesClassical And. Modern Regression With Applications: DuxburyrahsarahNo ratings yet
- Practice Exam Paper 1 - SolutionsDocument14 pagesPractice Exam Paper 1 - SolutionsMarcel JonathanNo ratings yet
- Tests of HypothesisDocument16 pagesTests of HypothesisDilip YadavNo ratings yet
- Zeon Auto Research Name: Akshay Sharma. Seat No: 24, Section GDocument5 pagesZeon Auto Research Name: Akshay Sharma. Seat No: 24, Section GAkshay SharmaNo ratings yet
- Problem Set VDocument7 pagesProblem Set VR Gandhimathi RajamaniNo ratings yet
- Lecture - 8-Statistical Inference - Single PopulationDocument25 pagesLecture - 8-Statistical Inference - Single PopulationTushar SohaleNo ratings yet
- PDF Econometrics 1St Edition K Nirmal Ravi Kumar Ebook Full ChapterDocument53 pagesPDF Econometrics 1St Edition K Nirmal Ravi Kumar Ebook Full Chapterandrea.carpenter531100% (3)
- Learning Activity Sheets: Mean and Variance of Discrete Random VariableDocument9 pagesLearning Activity Sheets: Mean and Variance of Discrete Random VariableCire HerreraNo ratings yet
- Tutorial: Rao-Blackwell Particle Filtering: The ModelDocument2 pagesTutorial: Rao-Blackwell Particle Filtering: The Modeljai_haas06No ratings yet
- MATH 1280-01 Assignment Unit 4Document6 pagesMATH 1280-01 Assignment Unit 4Julius OwuondaNo ratings yet
- Generalized Method of Moments Estimation: Econometrics C Lecture Note 8 Heino Bohn Nielsen November 20, 2013Document31 pagesGeneralized Method of Moments Estimation: Econometrics C Lecture Note 8 Heino Bohn Nielsen November 20, 2013lars32madsenNo ratings yet
- Math 102 Midterms Reviewer (With Mock Tests)Document3 pagesMath 102 Midterms Reviewer (With Mock Tests)Jirish RiveraNo ratings yet
- Chapter 2 Probability Concepts and ApplicationsDocument112 pagesChapter 2 Probability Concepts and Applicationsvita sarasiNo ratings yet
- 11-Measures of SkewnessDocument11 pages11-Measures of SkewnessPoojaNo ratings yet
- Hypothesis Testing: Ervin C. ReyesDocument15 pagesHypothesis Testing: Ervin C. ReyesReyes C. ErvinNo ratings yet
- Paired T-Test: A Project Report OnDocument19 pagesPaired T-Test: A Project Report OnTarun kumarNo ratings yet
- Homework1 AnswersDocument9 pagesHomework1 AnswersYagya Raj JoshiNo ratings yet
- StatisticsDocument7 pagesStatisticsNo NameNo ratings yet
- Min MaxDocument2 pagesMin MaxKashif KhalidNo ratings yet
- Exercises 4: Autocorrelated Processes ARIMA ModelsDocument45 pagesExercises 4: Autocorrelated Processes ARIMA ModelsGaurav VenkateshNo ratings yet
- ReliabilityHw1 R26104047Document4 pagesReliabilityHw1 R26104047Yen-Jen ChangNo ratings yet
- 4 Key Aspects To VariographyDocument14 pages4 Key Aspects To Variographysupri100% (2)
- Binomial and PoissonDocument45 pagesBinomial and PoissonjonatanNo ratings yet
- Statistics ReviewerDocument3 pagesStatistics ReviewerRenatoCosmeGalvanJunior100% (1)
- Part - 4 - Estimation - 1.ppt (Compatibility Mode)Document89 pagesPart - 4 - Estimation - 1.ppt (Compatibility Mode)đm đmNo ratings yet
- Lim PR Ob - 0: Convergence in ProbabilityDocument4 pagesLim PR Ob - 0: Convergence in ProbabilityRajendra GuptaNo ratings yet
- Coefficient Std. Error T-Ratio P-Value: Running OLS On DataDocument15 pagesCoefficient Std. Error T-Ratio P-Value: Running OLS On DataAadil ZamanNo ratings yet
- Multiple Regression - D. BoduszekDocument27 pagesMultiple Regression - D. Boduszekrebela29No ratings yet

























































































Download as pdf or txt
You might also like
- DATA 1. Pre-Board Scores of The Selected BS Education Students (Per Section) Section 1 Section 2 Section 3 Section 4 Section 5Document10 pagesDATA 1. Pre-Board Scores of The Selected BS Education Students (Per Section) Section 1 Section 2 Section 3 Section 4 Section 5ariane galeno100% (1)
- Decision Making: Submitted By-Ankita MishraDocument20 pagesDecision Making: Submitted By-Ankita MishraAnkita MishraNo ratings yet
- Clustering Clean Ads - DataDocument1,657 pagesClustering Clean Ads - Dataaman gautam0% (1)
- E-Commerce Revenue Management - Python For Data Science - Great LearningDocument4 pagesE-Commerce Revenue Management - Python For Data Science - Great LearningSuchi S Bahuguna100% (1)
- MRA Project Milestone2 PDFDocument1 pageMRA Project Milestone2 PDFRekha Rajaram100% (1)
- DM Gopala Satish Kumar Business Report G8 DSBADocument26 pagesDM Gopala Satish Kumar Business Report G8 DSBASatish Kumar100% (2)
- Asphalt Shingles Data Analysis PDFDocument4 pagesAsphalt Shingles Data Analysis PDFsonali PradhanNo ratings yet
- Assignment ClusteringDocument22 pagesAssignment ClusteringNetra RainaNo ratings yet
- Factor-Hair RV PDFDocument23 pagesFactor-Hair RV PDFRamachandran VenkataramanNo ratings yet
- One Way AnovaDocument35 pagesOne Way AnovaNinuca ChanturiaNo ratings yet
- VaibhavKumar Extendedproject PDFDocument10 pagesVaibhavKumar Extendedproject PDFAnshul Dyundi100% (2)
- Predictive Model: Submitted byDocument27 pagesPredictive Model: Submitted byAnkita Mishra100% (2)
- Girish Chadha - 29th December 2022Document35 pagesGirish Chadha - 29th December 2022Girish Chadha100% (3)
- Anshul Dyundi Predictive Modelling Alternate Project July 2022Document11 pagesAnshul Dyundi Predictive Modelling Alternate Project July 2022Anshul DyundiNo ratings yet
- Predictive Modeling Business Report Seetharaman Final Changes PDFDocument28 pagesPredictive Modeling Business Report Seetharaman Final Changes PDFAnkita Mishra100% (1)
- State Wise Health Income Clustering 18th December 2021 PDFDocument29 pagesState Wise Health Income Clustering 18th December 2021 PDFAnkita Mishra100% (1)
- Business Report: Predictive ModellingDocument37 pagesBusiness Report: Predictive Modellinghepzi selvam100% (1)
- Mini Project - Factor Hair Analysis: Sravanthi.MDocument24 pagesMini Project - Factor Hair Analysis: Sravanthi.MSweety Sekhar100% (1)
- Shivani Pandey TSFDocument32 pagesShivani Pandey TSFShivich10100% (1)
- Project QuestionsDocument3 pagesProject QuestionsravikgovinduNo ratings yet
- Predictive ModellingDocument58 pagesPredictive ModellingPranav Viswanathan100% (1)
- Data Mining Clustering PDFDocument15 pagesData Mining Clustering PDFSwing TradeNo ratings yet
- Predictive Modelling Alternative Firm Level PDFDocument26 pagesPredictive Modelling Alternative Firm Level PDFAnkita Mishra100% (4)
- Clustering ProjectDocument44 pagesClustering Projectkirti sharma100% (1)
- Predictive Modelling Report - ReshmaDocument20 pagesPredictive Modelling Report - Reshmareshma ajithNo ratings yet
- Suresh-Rose Time Series Forecasting Project ReportDocument75 pagesSuresh-Rose Time Series Forecasting Project ReportARCHANA R100% (1)
- Business Report Data MiningDocument29 pagesBusiness Report Data Mininghepzi selvamNo ratings yet
- SQL Quiz ResultsDocument17 pagesSQL Quiz ResultsJram MarjNo ratings yet
- Project Predictive Modeling PDFDocument58 pagesProject Predictive Modeling PDFAYUSH AWASTHI100% (1)
- DATA MINING PROJECT PAVITHRAA GOVINDARAJAN 24 OCT 2021 Jupyter Notebook PDFDocument49 pagesDATA MINING PROJECT PAVITHRAA GOVINDARAJAN 24 OCT 2021 Jupyter Notebook PDFGURUPADA PATI100% (2)
- Anshul Dyundi Machine Learning July 2022Document46 pagesAnshul Dyundi Machine Learning July 2022Anshul Dyundi50% (2)
- Time Series Rose Shehroz ArfeenDocument42 pagesTime Series Rose Shehroz ArfeenShehroz Khan100% (1)
- Business Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means ClusteringDocument28 pagesBusiness Report DSBA Data Mining Project - Part 2 Segmentation Using K-Means Clusteringcrispin anthonyNo ratings yet
- Data Mining Assignment: Sudhanva SaralayaDocument16 pagesData Mining Assignment: Sudhanva SaralayaSudhanva S100% (1)
- Business Report Pradeep Chauhan 11june'23Document25 pagesBusiness Report Pradeep Chauhan 11june'23Pradeep ChauhanNo ratings yet
- SMDM-Project Report (Madhur Dhananiwala)Document43 pagesSMDM-Project Report (Madhur Dhananiwala)madhur dhananiwala100% (1)
- Week 1 Graded Quiz On Solution PDFDocument2 pagesWeek 1 Graded Quiz On Solution PDFlikhith krishnaNo ratings yet
- DataMining Aug2021Document49 pagesDataMining Aug2021sakshi narang100% (2)
- Project Time Series ForecastingDocument53 pagesProject Time Series Forecastingharish kumar100% (1)
- Machine Learning SolutionDocument12 pagesMachine Learning Solutionprabu2125100% (1)
- Shoe SalesDocument105 pagesShoe SalesRemyaRS100% (3)
- Data Mining Business ReportDocument38 pagesData Mining Business ReportThaku SinghNo ratings yet
- Rahulsharma - 03 12 23Document25 pagesRahulsharma - 03 12 23Rahul GautamNo ratings yet
- SMDM - Project Report - LakshmiDocument26 pagesSMDM - Project Report - LakshmiKannan NNo ratings yet
- SMDM Project ReportDocument19 pagesSMDM Project ReportSANJAY ANANDAN100% (1)
- Answer Book - Rose WinesDocument11 pagesAnswer Book - Rose WinesAshish Agrawal100% (1)
- VARUNSAINI - 11 Dec 2022Document16 pagesVARUNSAINI - 11 Dec 2022Varun SainiNo ratings yet
- Business Report MLDocument36 pagesBusiness Report MLSomnath Kumbhar100% (1)
- Revised Clustering Business ReportDocument5 pagesRevised Clustering Business ReportPratigya pathakNo ratings yet
- Answer Report: Data MiningDocument32 pagesAnswer Report: Data MiningChetan SharmaNo ratings yet
- Assignment MLDocument21 pagesAssignment MLManish Verma100% (2)
- Project - Time Series Forecasting (Sparkling - CSV) & (Rose - CSV)Document15 pagesProject - Time Series Forecasting (Sparkling - CSV) & (Rose - CSV)guillermo coco100% (1)
- Project Predictive ModelingDocument69 pagesProject Predictive Modelingyuktha50% (2)
- Machine Learning Business Report - Compress (AutoRecovered)Document69 pagesMachine Learning Business Report - Compress (AutoRecovered)Deepanshu Parashar100% (2)
- Education - Post 12th Standard - CSVDocument11 pagesEducation - Post 12th Standard - CSVRuhee's KitchenNo ratings yet
- Advance Statistics-Project ReportDocument17 pagesAdvance Statistics-Project ReportJimmi Pranami50% (2)
- Executive Sumary - Rajarshi Das (Data Visualization Using Tableau Project)Document11 pagesExecutive Sumary - Rajarshi Das (Data Visualization Using Tableau Project)Rajarshi DasNo ratings yet
- SMDM Project: Submitted By: Tina DasDocument15 pagesSMDM Project: Submitted By: Tina DasTina100% (1)
- Predictive Modelling ProjectDocument29 pagesPredictive Modelling ProjectPranjal SinghNo ratings yet
- ML Quiz 2Document1 pageML Quiz 2Ruwayda IbraheemNo ratings yet
- Pranjal - Singh - 30.10.2022 SMDM PROJECT REPORTDocument9 pagesPranjal - Singh - 30.10.2022 SMDM PROJECT REPORTPranjal SinghNo ratings yet
- Assignment Report - Predictive Modelling - Rahul DubeyDocument18 pagesAssignment Report - Predictive Modelling - Rahul DubeyRahulNo ratings yet
- Classical And. Modern Regression With Applications: DuxburyDocument7 pagesClassical And. Modern Regression With Applications: DuxburyrahsarahNo ratings yet
- Practice Exam Paper 1 - SolutionsDocument14 pagesPractice Exam Paper 1 - SolutionsMarcel JonathanNo ratings yet
- Tests of HypothesisDocument16 pagesTests of HypothesisDilip YadavNo ratings yet
- Zeon Auto Research Name: Akshay Sharma. Seat No: 24, Section GDocument5 pagesZeon Auto Research Name: Akshay Sharma. Seat No: 24, Section GAkshay SharmaNo ratings yet
- Problem Set VDocument7 pagesProblem Set VR Gandhimathi RajamaniNo ratings yet
- Lecture - 8-Statistical Inference - Single PopulationDocument25 pagesLecture - 8-Statistical Inference - Single PopulationTushar SohaleNo ratings yet
- PDF Econometrics 1St Edition K Nirmal Ravi Kumar Ebook Full ChapterDocument53 pagesPDF Econometrics 1St Edition K Nirmal Ravi Kumar Ebook Full Chapterandrea.carpenter531100% (3)
- Learning Activity Sheets: Mean and Variance of Discrete Random VariableDocument9 pagesLearning Activity Sheets: Mean and Variance of Discrete Random VariableCire HerreraNo ratings yet
- Tutorial: Rao-Blackwell Particle Filtering: The ModelDocument2 pagesTutorial: Rao-Blackwell Particle Filtering: The Modeljai_haas06No ratings yet
- MATH 1280-01 Assignment Unit 4Document6 pagesMATH 1280-01 Assignment Unit 4Julius OwuondaNo ratings yet
- Generalized Method of Moments Estimation: Econometrics C Lecture Note 8 Heino Bohn Nielsen November 20, 2013Document31 pagesGeneralized Method of Moments Estimation: Econometrics C Lecture Note 8 Heino Bohn Nielsen November 20, 2013lars32madsenNo ratings yet
- Math 102 Midterms Reviewer (With Mock Tests)Document3 pagesMath 102 Midterms Reviewer (With Mock Tests)Jirish RiveraNo ratings yet
- Chapter 2 Probability Concepts and ApplicationsDocument112 pagesChapter 2 Probability Concepts and Applicationsvita sarasiNo ratings yet
- 11-Measures of SkewnessDocument11 pages11-Measures of SkewnessPoojaNo ratings yet
- Hypothesis Testing: Ervin C. ReyesDocument15 pagesHypothesis Testing: Ervin C. ReyesReyes C. ErvinNo ratings yet
- Paired T-Test: A Project Report OnDocument19 pagesPaired T-Test: A Project Report OnTarun kumarNo ratings yet
- Homework1 AnswersDocument9 pagesHomework1 AnswersYagya Raj JoshiNo ratings yet
- StatisticsDocument7 pagesStatisticsNo NameNo ratings yet
- Min MaxDocument2 pagesMin MaxKashif KhalidNo ratings yet
- Exercises 4: Autocorrelated Processes ARIMA ModelsDocument45 pagesExercises 4: Autocorrelated Processes ARIMA ModelsGaurav VenkateshNo ratings yet
- ReliabilityHw1 R26104047Document4 pagesReliabilityHw1 R26104047Yen-Jen ChangNo ratings yet
- 4 Key Aspects To VariographyDocument14 pages4 Key Aspects To Variographysupri100% (2)
- Binomial and PoissonDocument45 pagesBinomial and PoissonjonatanNo ratings yet
- Statistics ReviewerDocument3 pagesStatistics ReviewerRenatoCosmeGalvanJunior100% (1)
- Part - 4 - Estimation - 1.ppt (Compatibility Mode)Document89 pagesPart - 4 - Estimation - 1.ppt (Compatibility Mode)đm đmNo ratings yet
- Lim PR Ob - 0: Convergence in ProbabilityDocument4 pagesLim PR Ob - 0: Convergence in ProbabilityRajendra GuptaNo ratings yet
- Coefficient Std. Error T-Ratio P-Value: Running OLS On DataDocument15 pagesCoefficient Std. Error T-Ratio P-Value: Running OLS On DataAadil ZamanNo ratings yet
- Multiple Regression - D. BoduszekDocument27 pagesMultiple Regression - D. Boduszekrebela29No ratings yet