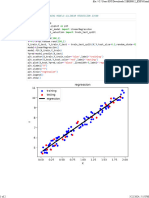
Download as pdf or txt
You might also like
- 21bei0012 Exp10Document2 pages21bei0012 Exp10srujanNo ratings yet
- Data Preprocessing TutorialDocument39 pagesData Preprocessing TutorialTháiSơnNo ratings yet
- 19bcs1522 CG 2.3Document9 pages19bcs1522 CG 2.3Naman ChahalNo ratings yet
- Assignment 3 - 20BCE7124Document5 pagesAssignment 3 - 20BCE7124Piyali karNo ratings yet
- NAME: Srithin Nair Class: Te Division: A Roll No: 65 DEPARTMENT: Computer SUBJECT: Computational Statistics YEAR: 2020-2021 PRN: 71918420HDocument9 pagesNAME: Srithin Nair Class: Te Division: A Roll No: 65 DEPARTMENT: Computer SUBJECT: Computational Statistics YEAR: 2020-2021 PRN: 71918420HSrithin NairNo ratings yet
- Priyal Keharia - CG Exp 2Document8 pagesPriyal Keharia - CG Exp 2Priyal KehariaNo ratings yet
- Computer Graphics & Multimedia: Program 5Document6 pagesComputer Graphics & Multimedia: Program 5umair riazNo ratings yet
- Ait AllDocument83 pagesAit AllramasaiNo ratings yet
- 13-Tracking L13Document11 pages13-Tracking L13hisisthesongoficeandfireNo ratings yet
- Computer Graphics Lab ReportDocument36 pagesComputer Graphics Lab Reportposhanbasnet10No ratings yet
- MLfullDocument29 pagesMLfullJanvi PatelNo ratings yet
- 01 Machine Learning BasicsDocument51 pages01 Machine Learning Basicsanirudh917No ratings yet
- Dynamic Time Warping Algorithm Review PDFDocument23 pagesDynamic Time Warping Algorithm Review PDFBenjiman RuneNo ratings yet
- DL Exp-1.3 19BCS1431Document8 pagesDL Exp-1.3 19BCS1431phaneendra mothukuruNo ratings yet
- CGM File - Sharonkaur - It2 - 104Document40 pagesCGM File - Sharonkaur - It2 - 104Sharon kaur katyalNo ratings yet
- SC 1.1 AMitDocument2 pagesSC 1.1 AMitravimalhotra01081999No ratings yet
- Computer Graphics Lab File VibhuDocument44 pagesComputer Graphics Lab File VibhuLavi KukretiNo ratings yet
- NSM - Runge Kutta - 2nd Order - Lab 4Document3 pagesNSM - Runge Kutta - 2nd Order - Lab 4Ulsema 09No ratings yet
- Prediction of Liquefaction Potential Based On CPTDocument7 pagesPrediction of Liquefaction Potential Based On CPTPhạm Thái HọcNo ratings yet
- GM Curves (Analytic)Document152 pagesGM Curves (Analytic)h20230085No ratings yet
- Fei - Grain Production Forecasting Based On PSO-based SVM - 2009Document5 pagesFei - Grain Production Forecasting Based On PSO-based SVM - 2009nisa fatharaniNo ratings yet
- UntitledDocument8 pagesUntitledRahul BroNo ratings yet
- 20bce0872 VL2022230503441 Ast01 230122 204351Document10 pages20bce0872 VL2022230503441 Ast01 230122 204351Vishesh BhargavaNo ratings yet
- 20-SE-66 ML Assign 2Document4 pages20-SE-66 ML Assign 2Muhammad Ali EjazNo ratings yet
- Towards Gaussian Process Models of Complex Rotorcraft Dynamics - FinalDocument11 pagesTowards Gaussian Process Models of Complex Rotorcraft Dynamics - Final2532909567No ratings yet
- 19100016tama SahaDocument57 pages19100016tama SahaPathul02No ratings yet
- MMDS Da3Document8 pagesMMDS Da3Good BoyNo ratings yet
- Computer Graphics Lab (CSP-305) Worksheet-2Document5 pagesComputer Graphics Lab (CSP-305) Worksheet-2Samridh GargNo ratings yet
- CS6513-COMPUTER GRAPHICS LABORATORY-664424542-computer Graphics Lab Manual 2013 RegulationDocument77 pagesCS6513-COMPUTER GRAPHICS LABORATORY-664424542-computer Graphics Lab Manual 2013 RegulationGanesh100% (1)
- Application To A Biped Walking RobotDocument6 pagesApplication To A Biped Walking RobotAPRIL_SNOWNo ratings yet
- Power Load Forecasting Based On Multi Task Gaussia - 2014 - IFAC Proceedings VolDocument6 pagesPower Load Forecasting Based On Multi Task Gaussia - 2014 - IFAC Proceedings VolKhalid AlHashemiNo ratings yet
- Power Load Forecasting Based On Multi-Task Gaussian ProcessDocument6 pagesPower Load Forecasting Based On Multi-Task Gaussian ProcessKhalid AlHashemiNo ratings yet
- ANA Projects ListDocument44 pagesANA Projects ListRaul GarciaNo ratings yet
- Chapter1: Introduction: Notes On MLAPPDocument25 pagesChapter1: Introduction: Notes On MLAPPwuziqiNo ratings yet
- Python-Advances in Probabilistic Graphical ModelsDocument102 pagesPython-Advances in Probabilistic Graphical Modelsnaveen441No ratings yet
- Learning Algorithms For The Classification Restricted Boltzmann MachineDocument27 pagesLearning Algorithms For The Classification Restricted Boltzmann MachineCaballero Alférez Roy TorresNo ratings yet
- Task3 Docx3Document7 pagesTask3 Docx3Md. Mukatter Fuad MizuNo ratings yet
- BCSL-058 (2022-23) Solved AssignmentDocument9 pagesBCSL-058 (2022-23) Solved Assignmentlenovo miNo ratings yet
- Metrology Ad Measuremet Systems: Index 330930, ISS 0860-8229 WWW - Metrology.pg - Gda.plDocument12 pagesMetrology Ad Measuremet Systems: Index 330930, ISS 0860-8229 WWW - Metrology.pg - Gda.plSiddharthNo ratings yet
- Linear Regression: Matplotlib Import As Import AsDocument4 pagesLinear Regression: Matplotlib Import As Import AsRyan GohNo ratings yet
- NSM Runge Kutta 4th Order Lab 3 StudentaDocument4 pagesNSM Runge Kutta 4th Order Lab 3 StudentaMeetkumar khairnarNo ratings yet
- Drilling Tool Failure Diagnosis Based On GA-SVMDocument4 pagesDrilling Tool Failure Diagnosis Based On GA-SVMDrSaurabh TewariNo ratings yet
- Gradient Descent and SGDDocument8 pagesGradient Descent and SGDROHIT ARORANo ratings yet
- DDA3020 Lecture 06 Logistic RegressionDocument47 pagesDDA3020 Lecture 06 Logistic RegressionJ DengNo ratings yet
- Program 1: Write A Program in C++ To Implement DDA Line Drawing AlgorithmDocument83 pagesProgram 1: Write A Program in C++ To Implement DDA Line Drawing AlgorithmChinmay BhakeNo ratings yet
- Computer Graphics Lab ManualDocument107 pagesComputer Graphics Lab ManualFemilaGoldy79% (14)
- Lecture - Line Scan ConversionDocument46 pagesLecture - Line Scan Conversionsumayya shaikNo ratings yet
- Assignment 1+2 IME MA 244L 1Document12 pagesAssignment 1+2 IME MA 244L 1Muhammad Asim Muhammad ArshadNo ratings yet
- Unit 3Document14 pagesUnit 3b7qxnnm8mzNo ratings yet
- Programs For Computer GraphicsDocument31 pagesPrograms For Computer GraphicssajjanNo ratings yet
- Intelligent Control, Its Evolution, Recent Technology On RoboticsDocument23 pagesIntelligent Control, Its Evolution, Recent Technology On RoboticsBinsi KedaramNo ratings yet
- Fisseha Berhane,: Analytical and Numerical Solutions, With R, To Linear Regression ProblemsDocument22 pagesFisseha Berhane,: Analytical and Numerical Solutions, With R, To Linear Regression ProblemsGeorge HamiltonNo ratings yet
- DAA JournalDocument71 pagesDAA JournalSHRUTI CHAVANNo ratings yet
- School of Computer Science and Engineering Winter Session 2020-21Document45 pagesSchool of Computer Science and Engineering Winter Session 2020-21Priyanshu MishraNo ratings yet
- Machine Learning Assignment 1 Basic Concepts: Due: 27 March 2015, 15:00pmDocument3 pagesMachine Learning Assignment 1 Basic Concepts: Due: 27 March 2015, 15:00pmpasomagaNo ratings yet
- Ikrimatul KhotimahDocument7 pagesIkrimatul KhotimahArinyNewbieNo ratings yet
- Computer Graphics Lab ManualDocument114 pagesComputer Graphics Lab ManualKhushbu MauryaNo ratings yet
- Gaussian Process For Nonstationary Time Series Prediction: So$ane Brahim-Belhouari, Amine BermakDocument8 pagesGaussian Process For Nonstationary Time Series Prediction: So$ane Brahim-Belhouari, Amine BermakThomas TseNo ratings yet
- Worksheet 1.2Document10 pagesWorksheet 1.2Rohit RohillaNo ratings yet
- Mathematical Formulas for Economics and Business: A Simple IntroductionFrom EverandMathematical Formulas for Economics and Business: A Simple IntroductionRating: 4 out of 5 stars4/5 (4)
- Chapter 5 ODE AshuDocument4 pagesChapter 5 ODE AshuAbel TayeNo ratings yet
- How To Solve The Maximum Flow Problem in A Network Using Ford MethodDocument5 pagesHow To Solve The Maximum Flow Problem in A Network Using Ford MethodAngga AnggaraNo ratings yet
- Asymptotic Analysis and Conclusion PDFDocument51 pagesAsymptotic Analysis and Conclusion PDFLeila HamidNo ratings yet
- Coding of Direct Stiffness MethodDocument2 pagesCoding of Direct Stiffness MethodgrabspNo ratings yet
- Bfs Find Shortest Path On Unweighted GraphDocument3 pagesBfs Find Shortest Path On Unweighted GraphNgo Quang MinhNo ratings yet
- First Quarterly Exam in Math 8 - Junior High School Table of SpecificationDocument1 pageFirst Quarterly Exam in Math 8 - Junior High School Table of SpecificationAnderson Marantan100% (1)
- Unit I Lesson 1 Interpolation & Extrapolation: ContextDocument9 pagesUnit I Lesson 1 Interpolation & Extrapolation: ContextVandana SharmaNo ratings yet
- Lab 6 LU DecompositionDocument6 pagesLab 6 LU DecompositionFaraz Ali ShahNo ratings yet
- Tutorial 02Document1 pageTutorial 02Tussank GuptaNo ratings yet
- LAB Manual Part A: Experiment No.02Document12 pagesLAB Manual Part A: Experiment No.02BiatchNo ratings yet
- Overview-Numerical MethodsDocument25 pagesOverview-Numerical MethodsB.srinivasaraoNo ratings yet
- Unit - 1b ORDocument32 pagesUnit - 1b ORMedandrao. Kavya SreeNo ratings yet
- QABD Group AssignmentDocument4 pagesQABD Group Assignmenttinsaefaji900No ratings yet
- SC607 Assignment2Document2 pagesSC607 Assignment2Tirthankar AdhikariNo ratings yet
- Back Propagation Neural Network 1: Lili Ayu Wulandhari PH.DDocument8 pagesBack Propagation Neural Network 1: Lili Ayu Wulandhari PH.DDewa Bagus KrisnaNo ratings yet
- IE141 - IX.a. Transportation ModelDocument77 pagesIE141 - IX.a. Transportation ModelIvan LajaraNo ratings yet
- L26 Travelling Salesman Problem Using B and BDocument28 pagesL26 Travelling Salesman Problem Using B and BShivansh RagNo ratings yet
- DAA First-Internal Question Paper (2018) 3.4Document2 pagesDAA First-Internal Question Paper (2018) 3.4deccancollegeNo ratings yet
- I Big M - MethodDocument15 pagesI Big M - Methodاحمد محمد ساهيNo ratings yet
- Problem SolvingDocument16 pagesProblem Solvingshehzad AliNo ratings yet
- Mathematical Optimization Techniques: S. RussenschuckDocument13 pagesMathematical Optimization Techniques: S. RussenschuckKartikeya DhanwariaNo ratings yet
- UCK 337 Introduction To Optimization Spring 2019-2020 Problem Set IDocument3 pagesUCK 337 Introduction To Optimization Spring 2019-2020 Problem Set IMim Alperen YarenNo ratings yet
- Worksheet - Maxima and MinimaDocument2 pagesWorksheet - Maxima and Minimaniyathi panickerNo ratings yet
- Unit IIIDocument28 pagesUnit IIINirav AgarwalNo ratings yet
- Course Outline MTH-375Document5 pagesCourse Outline MTH-375Tal HaNo ratings yet
- Title: Implement Depth-First Search: Department of Computer Science and EngineeringDocument5 pagesTitle: Implement Depth-First Search: Department of Computer Science and EngineeringSazeda SultanaNo ratings yet
- Math Iv Chapter 3Document60 pagesMath Iv Chapter 3Benjamin AkingeneyeNo ratings yet
- Practice MidtermDocument8 pagesPractice MidtermOlabiyi RidwanNo ratings yet
- Lib Burst GeneratedDocument30 pagesLib Burst GeneratedfDfasNo ratings yet
- Algebra 1 Chapter 7Document62 pagesAlgebra 1 Chapter 7v9hz5pkpb6No ratings yet