
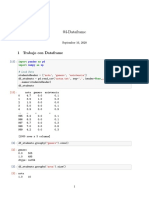
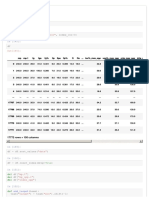
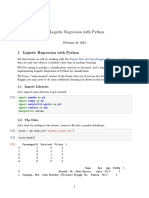
Assignment3 VidulGarg
Assignment3 VidulGarg
You might also like
- 024 Price and Everything PDFDocument12 pages024 Price and Everything PDFTman LetswaloNo ratings yet
- HNC Operations Engineering Noel Jennings Engineering Design AssignmentDocument13 pagesHNC Operations Engineering Noel Jennings Engineering Design AssignmentNoel JenningsNo ratings yet
- Setup: Chapter 2 - End-To-End Machine Learning ProjectDocument31 pagesSetup: Chapter 2 - End-To-End Machine Learning ProjectAmitNo ratings yet
- Neumoinsuflador Lut Service ManualDocument65 pagesNeumoinsuflador Lut Service Manualandres2013bio0% (1)
- Lecture Material 8Document9 pagesLecture Material 8Ali NaseerNo ratings yet
- Linear Regression: Data ExplorationDocument12 pagesLinear Regression: Data ExplorationFèdríck SämùélNo ratings yet
- Exp 4 (Movie Review)Document7 pagesExp 4 (Movie Review)pameluftNo ratings yet
- Heart DieseseDocument9 pagesHeart DieseseSuhani ShindeNo ratings yet
- Mock - Coding: Numpy NP CSV Sklearn - Linear - Model Pandas PD Matplotlib - Pyplot PLT Sklearn - MetricsDocument2 pagesMock - Coding: Numpy NP CSV Sklearn - Linear - Model Pandas PD Matplotlib - Pyplot PLT Sklearn - MetricsYTPUB001No ratings yet
- Linear and Multilinear RegressionDocument5 pagesLinear and Multilinear RegressionHarisankar R N RNo ratings yet
- Satya772244@gmail - Com Fish CategoryDocument5 pagesSatya772244@gmail - Com Fish CategorySatyendra VermaNo ratings yet
- Decision Tree Algorithm 1677030641Document9 pagesDecision Tree Algorithm 1677030641juanNo ratings yet
- Pyt Manual 1Document85 pagesPyt Manual 1Hrithik KumarNo ratings yet
- Heart: Our "Goal" Predict The Presence of Heart Disease in The PatientDocument73 pagesHeart: Our "Goal" Predict The Presence of Heart Disease in The Patientaditya b100% (1)
- Practical-5 - Jupyter NotebookDocument8 pagesPractical-5 - Jupyter NotebookHarsha Gohil100% (1)
- Python Sklearn Linear RegressionDocument45 pagesPython Sklearn Linear RegressionSurya Pranav AnnadanamNo ratings yet
- Practica 11Document7 pagesPractica 112marlenehh2003No ratings yet
- Sklearn Tutorial: DNN On Boston DataDocument9 pagesSklearn Tutorial: DNN On Boston DatahopkeinstNo ratings yet
- Maxbox Starter100 Data Science StoryDocument10 pagesMaxbox Starter100 Data Science StoryMax KleinerNo ratings yet
- Assign10.Ipynb - ColabDocument8 pagesAssign10.Ipynb - Colabatharvapudale0608No ratings yet
- 3 Confussion Matrix Hasil Modelling OKDocument8 pages3 Confussion Matrix Hasil Modelling OKArman Maulana Muhtar100% (1)
- Marvel Vs DCDocument1 pageMarvel Vs DCManoj MNo ratings yet
- IRIS BPNN - Ipynb - ColaboratoryDocument4 pagesIRIS BPNN - Ipynb - Colaboratoryrwn data100% (1)
- Mall CustomerDocument1 pageMall Customeraboodyshehab30No ratings yet
- Faseeh Chap 2 ReportDocument30 pagesFaseeh Chap 2 ReportSameer YounasNo ratings yet
- 1 Linear Regression: 1.1 Data ExplorationDocument12 pages1 Linear Regression: 1.1 Data ExplorationXyzNo ratings yet
- Medical Cost PredictionDocument27 pagesMedical Cost PredictionAbhinav RajNo ratings yet
- ML Project - End-To-End-Heart-Disease-ClassificationDocument30 pagesML Project - End-To-End-Heart-Disease-ClassificationAnurag KumarNo ratings yet
- Logistic Pima Indians - Ipynb - ColaboratoryDocument4 pagesLogistic Pima Indians - Ipynb - ColaboratorySHEKHAR SWAMINo ratings yet
- Dsbda 10Document3 pagesDsbda 10monaliauti2No ratings yet
- Import As Import As: "Iris - CSV"Document4 pagesImport As Import As: "Iris - CSV"avinashNo ratings yet
- California 1673295505Document18 pagesCalifornia 1673295505doudoudzNo ratings yet
- Linear - Regression - Ipynb - ColaboratoryDocument4 pagesLinear - Regression - Ipynb - Colaboratoryavnimote121No ratings yet
- Python Assignment 1.ipynb - ColaboratoryDocument3 pagesPython Assignment 1.ipynb - ColaboratoryAmritaRupiniNo ratings yet
- Project 8 Predictive Analytics - Ipynb - ColaboratoryDocument8 pagesProject 8 Predictive Analytics - Ipynb - ColaboratoryaadityadeolalikarNo ratings yet
- Logistic RegressionDocument12 pagesLogistic RegressionKagade AjinkyaNo ratings yet
- Saurabh Verma 9919102005Document11 pagesSaurabh Verma 9919102005Yogendra pratap Singh100% (1)
- Prac 10Document6 pagesPrac 1003rajput.kiNo ratings yet
- ModelDocument164 pagesModelSanjayNo ratings yet
- RegressionDocument3 pagesRegressionJerald RoyNo ratings yet
- Observation: As We Can See We Have Threwe Types of Datatypes I.E. (Int, Float, Object) That Means We Have Both Categorical and Numerical DataDocument2 pagesObservation: As We Can See We Have Threwe Types of Datatypes I.E. (Int, Float, Object) That Means We Have Both Categorical and Numerical DataPRATIK RATHODNo ratings yet
- Ash RegressionDocument11 pagesAsh Regressionsarpateashish5No ratings yet
- Fmsa315 - s11 - A.ipynb - Fernández - ConstanzaDocument6 pagesFmsa315 - s11 - A.ipynb - Fernández - ConstanzaScribdTranslationsNo ratings yet
- FDS Solved SlipsDocument63 pagesFDS Solved Slipsyashm4071100% (1)
- C2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsDocument38 pagesC2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsSarah Mendes100% (1)
- Pandas: Import As Import AsDocument40 pagesPandas: Import As Import Asacaro222No ratings yet
- Decision TreeDocument12 pagesDecision TreeKagade AjinkyaNo ratings yet
- Loadalgarve MLPDocument7 pagesLoadalgarve MLPRony RockNo ratings yet
- 2.2.1 DataframeDocument5 pages2.2.1 DataframeJavier ChandíaNo ratings yet
- B - 59 - SMA - Exp 4Document9 pagesB - 59 - SMA - Exp 4Ritz FernandesNo ratings yet
- Logistic Regression 205Document8 pagesLogistic Regression 205Ranadeep DeyNo ratings yet
- PANDAS - Series DataframesDocument118 pagesPANDAS - Series DataframesVaibhav SharmaNo ratings yet
- NBA Games Prediction 1683875972Document11 pagesNBA Games Prediction 1683875972luis pozaspalomoNo ratings yet
- 01-Logistic Regression With PythonDocument12 pages01-Logistic Regression With PythonHellem BiersackNo ratings yet
- Assignment No - 10Document3 pagesAssignment No - 10Sid ChabukswarNo ratings yet
- QUIZ Week 2 CART Practice PDFDocument10 pagesQUIZ Week 2 CART Practice PDFNagarajan ThandayuthamNo ratings yet
- DSBDA2Document6 pagesDSBDA2403 Chaudhari Sanika SagarNo ratings yet
- MBA SectionD MBA20235 PranayGupta Assignment RDocument16 pagesMBA SectionD MBA20235 PranayGupta Assignment RSomesh RoyNo ratings yet
- EDA QUIZ SolutionDocument2 pagesEDA QUIZ SolutionSoba CNo ratings yet
- 022 Price and Location PDFDocument16 pages022 Price and Location PDFTman LetswaloNo ratings yet
- Assignement 4Document6 pagesAssignement 4SHREYANSHU KODILKARNo ratings yet
- Email ProtectedDocument14 pagesEmail Protectedvidulgarg1524No ratings yet
- Task Allocation DocumentDocument1 pageTask Allocation Documentvidulgarg1524No ratings yet
- Litcoder Brief For VIT StudentsDocument14 pagesLitcoder Brief For VIT Studentsvidulgarg1524No ratings yet
- Assignment1 VidulGargDocument2 pagesAssignment1 VidulGargvidulgarg1524No ratings yet
- Solution ArchitectureDocument4 pagesSolution Architecturevidulgarg1524No ratings yet
- VIT Assignment 3Document2 pagesVIT Assignment 3vidulgarg1524No ratings yet
- Comparative and Superlative AdjectivesDocument5 pagesComparative and Superlative AdjectivesYoussef BrsNo ratings yet
- Am at Photogr 21 February 2015Document92 pagesAm at Photogr 21 February 2015TraficantdePufarineNo ratings yet
- Computed Radiography (CR) : Dosen: Anak Agung Aris Diartama, S.ST, M.TR - IDDocument28 pagesComputed Radiography (CR) : Dosen: Anak Agung Aris Diartama, S.ST, M.TR - IDKevin TagahNo ratings yet
- Visible ThinkingDocument4 pagesVisible ThinkinginterianobersabeNo ratings yet
- Assignment - 6 SolutionsDocument7 pagesAssignment - 6 SolutionsGopal Iswarpur Ghosh100% (1)
- Chapter 24 Notes (Student)Document11 pagesChapter 24 Notes (Student)Regina LinNo ratings yet
- Chapter 2 - Equivalence Above Word LevelDocument23 pagesChapter 2 - Equivalence Above Word LevelNoo NooNo ratings yet
- 1 s2.0 S0920586123000196 MainDocument13 pages1 s2.0 S0920586123000196 Mainsofch2011No ratings yet
- Colah Github Io Posts 2015 08 Understanding LSTMsDocument16 pagesColah Github Io Posts 2015 08 Understanding LSTMsMithun PantNo ratings yet
- February 2023Document4 pagesFebruary 2023Cresilda BiloyNo ratings yet
- Bovaird Loeffler 2016Document13 pagesBovaird Loeffler 2016coolchannel26No ratings yet
- 19Document227 pages19Miguel José DuarteNo ratings yet
- Current Issues in AIS655Document5 pagesCurrent Issues in AIS655AmmarNo ratings yet
- ABB Unit Trip EMAX PR112-PD PDFDocument27 pagesABB Unit Trip EMAX PR112-PD PDFPedro MartinsNo ratings yet
- Pre - Board - 2 STD XII MathematicsDocument7 pagesPre - Board - 2 STD XII MathematicsPradip MohiteNo ratings yet
- Safety Rules and Laboratory Equipment: Experiment 1Document5 pagesSafety Rules and Laboratory Equipment: Experiment 1ricardojosecortinaNo ratings yet
- Fleet-Catalogue GasketDocument34 pagesFleet-Catalogue GasketJMS OverseasNo ratings yet
- Tata Motors's AchivementsDocument105 pagesTata Motors's AchivementsSunny SinghNo ratings yet
- Canada Oilfield EquipmentDocument8 pagesCanada Oilfield Equipmenteduardo.torresNo ratings yet
- ADT Service ManualDocument152 pagesADT Service ManualZakhele MpofuNo ratings yet
- Year 9 Naplan Non CalcDocument12 pagesYear 9 Naplan Non CalcSophieNoorSalibiNo ratings yet
- Proposed 15 Numerical Problems For PresentationDocument8 pagesProposed 15 Numerical Problems For PresentationalexNo ratings yet
- HZ 01Cpr: Material Safety Data SheetDocument6 pagesHZ 01Cpr: Material Safety Data SheetFakhreddine BousninaNo ratings yet
- Translator 文华在线教育 - Collaboration Agreement Bilingual TemplateDocument5 pagesTranslator 文华在线教育 - Collaboration Agreement Bilingual TemplateАлтер КацизнеNo ratings yet
- Noc19 Me17 Assignment5Document3 pagesNoc19 Me17 Assignment5mechanicalNo ratings yet
- Macbeth Lesson PlanDocument2 pagesMacbeth Lesson Planrymahoney10No ratings yet
- Declaration of Conformity For Restriction of Hazardous Substances (Rohs)Document1 pageDeclaration of Conformity For Restriction of Hazardous Substances (Rohs)Yogesh KatyarmalNo ratings yet
- Gosat Gs 7055 Hdi FirmwareDocument3 pagesGosat Gs 7055 Hdi FirmwareAntoinetteNo ratings yet




























































































Download as pdf or txt
You might also like
- 024 Price and Everything PDFDocument12 pages024 Price and Everything PDFTman LetswaloNo ratings yet
- HNC Operations Engineering Noel Jennings Engineering Design AssignmentDocument13 pagesHNC Operations Engineering Noel Jennings Engineering Design AssignmentNoel JenningsNo ratings yet
- Setup: Chapter 2 - End-To-End Machine Learning ProjectDocument31 pagesSetup: Chapter 2 - End-To-End Machine Learning ProjectAmitNo ratings yet
- Neumoinsuflador Lut Service ManualDocument65 pagesNeumoinsuflador Lut Service Manualandres2013bio0% (1)
- Lecture Material 8Document9 pagesLecture Material 8Ali NaseerNo ratings yet
- Linear Regression: Data ExplorationDocument12 pagesLinear Regression: Data ExplorationFèdríck SämùélNo ratings yet
- Exp 4 (Movie Review)Document7 pagesExp 4 (Movie Review)pameluftNo ratings yet
- Heart DieseseDocument9 pagesHeart DieseseSuhani ShindeNo ratings yet
- Mock - Coding: Numpy NP CSV Sklearn - Linear - Model Pandas PD Matplotlib - Pyplot PLT Sklearn - MetricsDocument2 pagesMock - Coding: Numpy NP CSV Sklearn - Linear - Model Pandas PD Matplotlib - Pyplot PLT Sklearn - MetricsYTPUB001No ratings yet
- Linear and Multilinear RegressionDocument5 pagesLinear and Multilinear RegressionHarisankar R N RNo ratings yet
- Satya772244@gmail - Com Fish CategoryDocument5 pagesSatya772244@gmail - Com Fish CategorySatyendra VermaNo ratings yet
- Decision Tree Algorithm 1677030641Document9 pagesDecision Tree Algorithm 1677030641juanNo ratings yet
- Pyt Manual 1Document85 pagesPyt Manual 1Hrithik KumarNo ratings yet
- Heart: Our "Goal" Predict The Presence of Heart Disease in The PatientDocument73 pagesHeart: Our "Goal" Predict The Presence of Heart Disease in The Patientaditya b100% (1)
- Practical-5 - Jupyter NotebookDocument8 pagesPractical-5 - Jupyter NotebookHarsha Gohil100% (1)
- Python Sklearn Linear RegressionDocument45 pagesPython Sklearn Linear RegressionSurya Pranav AnnadanamNo ratings yet
- Practica 11Document7 pagesPractica 112marlenehh2003No ratings yet
- Sklearn Tutorial: DNN On Boston DataDocument9 pagesSklearn Tutorial: DNN On Boston DatahopkeinstNo ratings yet
- Maxbox Starter100 Data Science StoryDocument10 pagesMaxbox Starter100 Data Science StoryMax KleinerNo ratings yet
- Assign10.Ipynb - ColabDocument8 pagesAssign10.Ipynb - Colabatharvapudale0608No ratings yet
- 3 Confussion Matrix Hasil Modelling OKDocument8 pages3 Confussion Matrix Hasil Modelling OKArman Maulana Muhtar100% (1)
- Marvel Vs DCDocument1 pageMarvel Vs DCManoj MNo ratings yet
- IRIS BPNN - Ipynb - ColaboratoryDocument4 pagesIRIS BPNN - Ipynb - Colaboratoryrwn data100% (1)
- Mall CustomerDocument1 pageMall Customeraboodyshehab30No ratings yet
- Faseeh Chap 2 ReportDocument30 pagesFaseeh Chap 2 ReportSameer YounasNo ratings yet
- 1 Linear Regression: 1.1 Data ExplorationDocument12 pages1 Linear Regression: 1.1 Data ExplorationXyzNo ratings yet
- Medical Cost PredictionDocument27 pagesMedical Cost PredictionAbhinav RajNo ratings yet
- ML Project - End-To-End-Heart-Disease-ClassificationDocument30 pagesML Project - End-To-End-Heart-Disease-ClassificationAnurag KumarNo ratings yet
- Logistic Pima Indians - Ipynb - ColaboratoryDocument4 pagesLogistic Pima Indians - Ipynb - ColaboratorySHEKHAR SWAMINo ratings yet
- Dsbda 10Document3 pagesDsbda 10monaliauti2No ratings yet
- Import As Import As: "Iris - CSV"Document4 pagesImport As Import As: "Iris - CSV"avinashNo ratings yet
- California 1673295505Document18 pagesCalifornia 1673295505doudoudzNo ratings yet
- Linear - Regression - Ipynb - ColaboratoryDocument4 pagesLinear - Regression - Ipynb - Colaboratoryavnimote121No ratings yet
- Python Assignment 1.ipynb - ColaboratoryDocument3 pagesPython Assignment 1.ipynb - ColaboratoryAmritaRupiniNo ratings yet
- Project 8 Predictive Analytics - Ipynb - ColaboratoryDocument8 pagesProject 8 Predictive Analytics - Ipynb - ColaboratoryaadityadeolalikarNo ratings yet
- Logistic RegressionDocument12 pagesLogistic RegressionKagade AjinkyaNo ratings yet
- Saurabh Verma 9919102005Document11 pagesSaurabh Verma 9919102005Yogendra pratap Singh100% (1)
- Prac 10Document6 pagesPrac 1003rajput.kiNo ratings yet
- ModelDocument164 pagesModelSanjayNo ratings yet
- RegressionDocument3 pagesRegressionJerald RoyNo ratings yet
- Observation: As We Can See We Have Threwe Types of Datatypes I.E. (Int, Float, Object) That Means We Have Both Categorical and Numerical DataDocument2 pagesObservation: As We Can See We Have Threwe Types of Datatypes I.E. (Int, Float, Object) That Means We Have Both Categorical and Numerical DataPRATIK RATHODNo ratings yet
- Ash RegressionDocument11 pagesAsh Regressionsarpateashish5No ratings yet
- Fmsa315 - s11 - A.ipynb - Fernández - ConstanzaDocument6 pagesFmsa315 - s11 - A.ipynb - Fernández - ConstanzaScribdTranslationsNo ratings yet
- FDS Solved SlipsDocument63 pagesFDS Solved Slipsyashm4071100% (1)
- C2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsDocument38 pagesC2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsSarah Mendes100% (1)
- Pandas: Import As Import AsDocument40 pagesPandas: Import As Import Asacaro222No ratings yet
- Decision TreeDocument12 pagesDecision TreeKagade AjinkyaNo ratings yet
- Loadalgarve MLPDocument7 pagesLoadalgarve MLPRony RockNo ratings yet
- 2.2.1 DataframeDocument5 pages2.2.1 DataframeJavier ChandíaNo ratings yet
- B - 59 - SMA - Exp 4Document9 pagesB - 59 - SMA - Exp 4Ritz FernandesNo ratings yet
- Logistic Regression 205Document8 pagesLogistic Regression 205Ranadeep DeyNo ratings yet
- PANDAS - Series DataframesDocument118 pagesPANDAS - Series DataframesVaibhav SharmaNo ratings yet
- NBA Games Prediction 1683875972Document11 pagesNBA Games Prediction 1683875972luis pozaspalomoNo ratings yet
- 01-Logistic Regression With PythonDocument12 pages01-Logistic Regression With PythonHellem BiersackNo ratings yet
- Assignment No - 10Document3 pagesAssignment No - 10Sid ChabukswarNo ratings yet
- QUIZ Week 2 CART Practice PDFDocument10 pagesQUIZ Week 2 CART Practice PDFNagarajan ThandayuthamNo ratings yet
- DSBDA2Document6 pagesDSBDA2403 Chaudhari Sanika SagarNo ratings yet
- MBA SectionD MBA20235 PranayGupta Assignment RDocument16 pagesMBA SectionD MBA20235 PranayGupta Assignment RSomesh RoyNo ratings yet
- EDA QUIZ SolutionDocument2 pagesEDA QUIZ SolutionSoba CNo ratings yet
- 022 Price and Location PDFDocument16 pages022 Price and Location PDFTman LetswaloNo ratings yet
- Assignement 4Document6 pagesAssignement 4SHREYANSHU KODILKARNo ratings yet
- Email ProtectedDocument14 pagesEmail Protectedvidulgarg1524No ratings yet
- Task Allocation DocumentDocument1 pageTask Allocation Documentvidulgarg1524No ratings yet
- Litcoder Brief For VIT StudentsDocument14 pagesLitcoder Brief For VIT Studentsvidulgarg1524No ratings yet
- Assignment1 VidulGargDocument2 pagesAssignment1 VidulGargvidulgarg1524No ratings yet
- Solution ArchitectureDocument4 pagesSolution Architecturevidulgarg1524No ratings yet
- VIT Assignment 3Document2 pagesVIT Assignment 3vidulgarg1524No ratings yet
- Comparative and Superlative AdjectivesDocument5 pagesComparative and Superlative AdjectivesYoussef BrsNo ratings yet
- Am at Photogr 21 February 2015Document92 pagesAm at Photogr 21 February 2015TraficantdePufarineNo ratings yet
- Computed Radiography (CR) : Dosen: Anak Agung Aris Diartama, S.ST, M.TR - IDDocument28 pagesComputed Radiography (CR) : Dosen: Anak Agung Aris Diartama, S.ST, M.TR - IDKevin TagahNo ratings yet
- Visible ThinkingDocument4 pagesVisible ThinkinginterianobersabeNo ratings yet
- Assignment - 6 SolutionsDocument7 pagesAssignment - 6 SolutionsGopal Iswarpur Ghosh100% (1)
- Chapter 24 Notes (Student)Document11 pagesChapter 24 Notes (Student)Regina LinNo ratings yet
- Chapter 2 - Equivalence Above Word LevelDocument23 pagesChapter 2 - Equivalence Above Word LevelNoo NooNo ratings yet
- 1 s2.0 S0920586123000196 MainDocument13 pages1 s2.0 S0920586123000196 Mainsofch2011No ratings yet
- Colah Github Io Posts 2015 08 Understanding LSTMsDocument16 pagesColah Github Io Posts 2015 08 Understanding LSTMsMithun PantNo ratings yet
- February 2023Document4 pagesFebruary 2023Cresilda BiloyNo ratings yet
- Bovaird Loeffler 2016Document13 pagesBovaird Loeffler 2016coolchannel26No ratings yet
- 19Document227 pages19Miguel José DuarteNo ratings yet
- Current Issues in AIS655Document5 pagesCurrent Issues in AIS655AmmarNo ratings yet
- ABB Unit Trip EMAX PR112-PD PDFDocument27 pagesABB Unit Trip EMAX PR112-PD PDFPedro MartinsNo ratings yet
- Pre - Board - 2 STD XII MathematicsDocument7 pagesPre - Board - 2 STD XII MathematicsPradip MohiteNo ratings yet
- Safety Rules and Laboratory Equipment: Experiment 1Document5 pagesSafety Rules and Laboratory Equipment: Experiment 1ricardojosecortinaNo ratings yet
- Fleet-Catalogue GasketDocument34 pagesFleet-Catalogue GasketJMS OverseasNo ratings yet
- Tata Motors's AchivementsDocument105 pagesTata Motors's AchivementsSunny SinghNo ratings yet
- Canada Oilfield EquipmentDocument8 pagesCanada Oilfield Equipmenteduardo.torresNo ratings yet
- ADT Service ManualDocument152 pagesADT Service ManualZakhele MpofuNo ratings yet
- Year 9 Naplan Non CalcDocument12 pagesYear 9 Naplan Non CalcSophieNoorSalibiNo ratings yet
- Proposed 15 Numerical Problems For PresentationDocument8 pagesProposed 15 Numerical Problems For PresentationalexNo ratings yet
- HZ 01Cpr: Material Safety Data SheetDocument6 pagesHZ 01Cpr: Material Safety Data SheetFakhreddine BousninaNo ratings yet
- Translator 文华在线教育 - Collaboration Agreement Bilingual TemplateDocument5 pagesTranslator 文华在线教育 - Collaboration Agreement Bilingual TemplateАлтер КацизнеNo ratings yet
- Noc19 Me17 Assignment5Document3 pagesNoc19 Me17 Assignment5mechanicalNo ratings yet
- Macbeth Lesson PlanDocument2 pagesMacbeth Lesson Planrymahoney10No ratings yet
- Declaration of Conformity For Restriction of Hazardous Substances (Rohs)Document1 pageDeclaration of Conformity For Restriction of Hazardous Substances (Rohs)Yogesh KatyarmalNo ratings yet
- Gosat Gs 7055 Hdi FirmwareDocument3 pagesGosat Gs 7055 Hdi FirmwareAntoinetteNo ratings yet