Download as pdf or txt
You might also like
- Katherine Byrne, Tuberculosis and The Victorian: Literary ImaginationDocument5 pagesKatherine Byrne, Tuberculosis and The Victorian: Literary ImaginationMaria Eliza GiuboruncaNo ratings yet
- Johnston (1999) Why We Feel. The Science of Human EmotionsDocument221 pagesJohnston (1999) Why We Feel. The Science of Human EmotionsNavi Setnom ArieugonNo ratings yet
- CS2B - Sept23 - EXAM - Clean ProofDocument5 pagesCS2B - Sept23 - EXAM - Clean ProofVaibhav SharmaNo ratings yet
- CS1B September22 EXAM Clean ProofDocument5 pagesCS1B September22 EXAM Clean ProofPranshu JagtapNo ratings yet
- CS1B April 2019 ExamPaperDocument5 pagesCS1B April 2019 ExamPaperBRUME JAGBORONo ratings yet
- Final Assignment: 1 InstructionsDocument5 pagesFinal Assignment: 1 InstructionsLanjun ShaoNo ratings yet
- Activity 7Document5 pagesActivity 7Sam Sat PatNo ratings yet
- Section A (45 Marks) : Answer All Questions in This SectionDocument4 pagesSection A (45 Marks) : Answer All Questions in This SectionSTPMmathsNo ratings yet
- 2019 - Introduction To Data Analytics Using RDocument5 pages2019 - Introduction To Data Analytics Using RYeickson Mendoza MartinezNo ratings yet
- A2 QMTDocument2 pagesA2 QMTZeeshan Ali0% (1)
- Assignment 1Document2 pagesAssignment 1Afaan AliNo ratings yet
- MCS 053Document4 pagesMCS 053Rajat KoundalNo ratings yet
- MCA111CDocument2 pagesMCA111CSiddharth shuklaNo ratings yet
- Ip Practice Questions Class 12Document5 pagesIp Practice Questions Class 1215099No ratings yet
- Yy 1 XyDocument4 pagesYy 1 Xydinsopheakpanha24No ratings yet
- Paper Open ElectiveDocument3 pagesPaper Open ElectiveCHANDERHASSNo ratings yet
- CT3 QP 0512 PDFDocument6 pagesCT3 QP 0512 PDFNathan RkNo ratings yet
- 2020-09-22SupplementaryCS467CS467-E - Ktu QbankDocument3 pages2020-09-22SupplementaryCS467CS467-E - Ktu Qbanksabitha sNo ratings yet
- Answer All Questions, Each Carries 4 MarksDocument3 pagesAnswer All Questions, Each Carries 4 MarksKarthikaNo ratings yet
- CS2B_121_EXAMDocument5 pagesCS2B_121_EXAMtanishajainNo ratings yet
- Allama Iqbal Open University, Islamabad Warning: (Department of Statistics)Document3 pagesAllama Iqbal Open University, Islamabad Warning: (Department of Statistics)gulzar ahmadNo ratings yet
- Practice QuestionsDocument2 pagesPractice QuestionsVarnika RaiNo ratings yet
- CS3362 Set2Document3 pagesCS3362 Set2karthika muruganNo ratings yet
- CS2B - April23 - EXAM - Clean Proof - v2Document8 pagesCS2B - April23 - EXAM - Clean Proof - v2boomaNo ratings yet
- 2101CS301 48 Question PaperDocument2 pages2101CS301 48 Question Paperkarmabhatt02No ratings yet
- 2019 CSS Winter Question PaperDocument4 pages2019 CSS Winter Question PaperSampada Parate (Samp)No ratings yet
- BCSL-044 S3Document3 pagesBCSL-044 S3nikita rawatNo ratings yet
- Department of Computer Science & Engineering End Semester Examination-May, 2019Document2 pagesDepartment of Computer Science & Engineering End Semester Examination-May, 2019Yash GagnejaNo ratings yet
- Term-I Practical Question Paper 2022-2023Document8 pagesTerm-I Practical Question Paper 2022-2023Divij JainNo ratings yet
- CS1B April22 EXAM Clean ProofDocument5 pagesCS1B April22 EXAM Clean ProofSeshankrishnaNo ratings yet
- Anna University: Chennai - 600 025Document7 pagesAnna University: Chennai - 600 025Anonymous Xr7bf3un0No ratings yet
- Programming in C N20 R15 2131Document3 pagesProgramming in C N20 R15 2131Sreekanth KuNo ratings yet
- Data Science - Part II (Cra 4061)Document2 pagesData Science - Part II (Cra 4061)Sarvagya RanjanNo ratings yet
- Chinhoyi University of TechnologyDocument2 pagesChinhoyi University of TechnologyRutendo JajiNo ratings yet
- Statistic Practice QuestionDocument28 pagesStatistic Practice QuestionSaqib AliNo ratings yet
- Allama Iqbal Open University, Islamabad (Department of Statistics) WarningDocument4 pagesAllama Iqbal Open University, Islamabad (Department of Statistics) Warningsamranaseem367No ratings yet
- CUMT105 Tutorial Worksheet 2 Data Presentation Data SummarisationDocument2 pagesCUMT105 Tutorial Worksheet 2 Data Presentation Data SummarisationVincent ChataikahNo ratings yet
- Be Winter 2021Document2 pagesBe Winter 2021Raj SutharNo ratings yet
- Simulation ES MERGEDDocument24 pagesSimulation ES MERGEDadityaNo ratings yet
- B.Tech. Degree Examination Civil, CSE, IT & Mechanical: (Nov-16) (EMA-203)Document3 pagesB.Tech. Degree Examination Civil, CSE, IT & Mechanical: (Nov-16) (EMA-203)raghuNo ratings yet
- Machine Learning PYQ 2023Document8 pagesMachine Learning PYQ 2023nitob90303No ratings yet
- Heq Mar15 Dip OopDocument4 pagesHeq Mar15 Dip OopAngelica SaanaayaNo ratings yet
- Fundamentals of Applied StatisticsDocument8 pagesFundamentals of Applied StatisticsAam IRNo ratings yet
- OopsDocument3 pagesOopsDrMayank SinghNo ratings yet
- 2018 H2 Prelim Compilation (Correlation Regression)Document21 pages2018 H2 Prelim Compilation (Correlation Regression)toh tim lamNo ratings yet
- Assignment Paper 001Document5 pagesAssignment Paper 001jksvsglaNo ratings yet
- Bachelor of Computer Application (Bca-Revised) : Term-End Examination December, 2013 Bcs-040: Statistical TechniquesDocument3 pagesBachelor of Computer Application (Bca-Revised) : Term-End Examination December, 2013 Bcs-040: Statistical TechniquesRahul SharmaNo ratings yet
- Práctica General EstadísticaaDocument6 pagesPráctica General EstadísticaaAlison Alvarado OtárolaNo ratings yet
- Quantitative Methods Ca Icap Past Papers Spring 2014 PDFDocument3 pagesQuantitative Methods Ca Icap Past Papers Spring 2014 PDFsecret student100% (1)
- 5 6314393805420232845 PDFDocument11 pages5 6314393805420232845 PDFTaruna BajajNo ratings yet
- Gujarat Technological UniversityDocument2 pagesGujarat Technological UniversityOm Patel PatelNo ratings yet
- Comp Question Paper HFEDocument5 pagesComp Question Paper HFEfreakinfox95No ratings yet
- Grade11 DSC Hy - Sample-PaDocument6 pagesGrade11 DSC Hy - Sample-Pagreenpouch509No ratings yet
- FHMM1034 Tutorial 6-Correlation Regression 201910Document8 pagesFHMM1034 Tutorial 6-Correlation Regression 201910JUN JET LOHNo ratings yet
- Ast 001Document21 pagesAst 001kpwazafxzavheotowwNo ratings yet
- Machine Learning (Csen 3233)Document4 pagesMachine Learning (Csen 3233)cmmaity2017No ratings yet
- Dsa Question PaperDocument2 pagesDsa Question Papershubhamofficial23klNo ratings yet
- Pre 10Document9 pagesPre 10hargunnkaur31802No ratings yet
- Actuarial cs2Document4 pagesActuarial cs2Aman NarangNo ratings yet
- AP Computer Science Principles: Student-Crafted Practice Tests For ExcellenceFrom EverandAP Computer Science Principles: Student-Crafted Practice Tests For ExcellenceNo ratings yet
- Let's Practise: Maths Workbook Coursebook 6From EverandLet's Practise: Maths Workbook Coursebook 6No ratings yet
- Importing Google Earth Data Into A GISDocument15 pagesImporting Google Earth Data Into A GISJONAMNo ratings yet
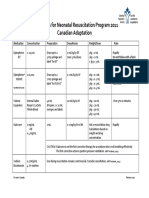
- Medications For Neonatal Resuscitation Program 2011 Canadian AdaptationDocument1 pageMedications For Neonatal Resuscitation Program 2011 Canadian AdaptationrubymayNo ratings yet
- Bradley Eye Wash Manual S19224Document44 pagesBradley Eye Wash Manual S19224jackNo ratings yet
- Interior Design Using Augmented RealityDocument24 pagesInterior Design Using Augmented RealityHarfizzie FatehNo ratings yet
- I Slams War On TerrorDocument0 pagesI Slams War On TerrorkhalidpandithNo ratings yet
- TB 001 Gas Industry Unsafe Situation Procedure Giusp Edition 71 1 PDFDocument38 pagesTB 001 Gas Industry Unsafe Situation Procedure Giusp Edition 71 1 PDFPeter Monk100% (1)
- CCNA1 Mod 6Document28 pagesCCNA1 Mod 6KlokanNo ratings yet
- Kenya Institute of Business and Counselling StudiesDocument16 pagesKenya Institute of Business and Counselling StudiesEdwine Jeremiah ONo ratings yet
- Bridge Alert Management PDFDocument18 pagesBridge Alert Management PDFbhabhasunilNo ratings yet
- LAS Module 5 Applied Economics MARKET STRUCTURESDocument7 pagesLAS Module 5 Applied Economics MARKET STRUCTURESellamaecalamucha8No ratings yet
- TLE DRILL 150 Items With Answer KeyDocument16 pagesTLE DRILL 150 Items With Answer KeyEd Doloriel MoralesNo ratings yet
- Ascensional and Descensional VentilationDocument5 pagesAscensional and Descensional VentilationP Taviti Naidu100% (1)
- Img 0004Document7 pagesImg 0004velavan100% (1)
- Dreams LuDocument325 pagesDreams Luscrib3030100% (1)
- Deped Order No.31 S. 2020 Interim Guidelines For Assessment and Grading in Light of The Basic Education Learning Continuity PlanDocument24 pagesDeped Order No.31 S. 2020 Interim Guidelines For Assessment and Grading in Light of The Basic Education Learning Continuity PlanAlyssa AlbertoNo ratings yet
- Seven Paths To Perfection Kirpal SinghDocument52 pagesSeven Paths To Perfection Kirpal SinghjaideepkdNo ratings yet
- Increasing and Decreasing Functions, Concavity and Inflection PointsDocument17 pagesIncreasing and Decreasing Functions, Concavity and Inflection PointsAnonymous Gd16J3n7No ratings yet
- Excel Project AssignmentDocument5 pagesExcel Project AssignmentJayden RinquestNo ratings yet
- Structuralism SummaryDocument3 pagesStructuralism SummaryumamaNo ratings yet
- Principle of ManagementDocument6 pagesPrinciple of ManagementArthiNo ratings yet
- Tong Hop Bai Tap So Sanh Hon Va So Sanh Nhat Co Dap AnDocument14 pagesTong Hop Bai Tap So Sanh Hon Va So Sanh Nhat Co Dap AnGia HuyNo ratings yet
- Bluetooth Car Using ArduinoDocument13 pagesBluetooth Car Using ArduinoRainy Thakur100% (1)
- Questions (1-30)Document39 pagesQuestions (1-30)Khánh ToànNo ratings yet
- Khidmat - The ServiceDocument6 pagesKhidmat - The ServiceAjay Prakash VermaNo ratings yet
- PFI ES-5-1993 Cleaning of Fabricated PipingDocument4 pagesPFI ES-5-1993 Cleaning of Fabricated PipingRodrigo Chambilla VernazaNo ratings yet
- Contin Educ Anaesth Crit Care Pain-2008-Gauntlett-121-4Document4 pagesContin Educ Anaesth Crit Care Pain-2008-Gauntlett-121-4Wahyu HidayatiNo ratings yet
- Hx-Chart Humid Air: Humidity Ratio, G/KG (Dry Air)Document1 pageHx-Chart Humid Air: Humidity Ratio, G/KG (Dry Air)KundzoNo ratings yet
- Environmental ScienceDocument2 pagesEnvironmental Sciencegillianbernice.alaNo ratings yet