Download as docx, pdf, or txt
You might also like
- LYXORDocument5 pagesLYXORRamalu Dinesh Reddy50% (2)
- ISOM 5510 Data Analysis Group Project 14 - 3Document7 pagesISOM 5510 Data Analysis Group Project 14 - 3Ameya PanditNo ratings yet
- Arcadia - Syndicate 9Document6 pagesArcadia - Syndicate 9Uus FirdausNo ratings yet
- Psychological Bulletin: VOL. 51, No. 4Document32 pagesPsychological Bulletin: VOL. 51, No. 4Alexandru NaeNo ratings yet
- Negotiating Style 1.2Document3 pagesNegotiating Style 1.2sushumcastle6546100% (1)
- Students Performance ChecklistDocument4 pagesStudents Performance ChecklistGeraldine Caya Amahido - GarmaNo ratings yet
- MacrodurDocument41 pagesMacrodurnoel_manroeNo ratings yet
- PSI and KS StatisticDocument6 pagesPSI and KS StatisticGaneshNo ratings yet
- FIN213 - Semester Test 1 20240406 Solutions MemoDocument11 pagesFIN213 - Semester Test 1 20240406 Solutions Memogaming.og122No ratings yet
- 75 Valuation Mistakes Ssrn-Id411600Document28 pages75 Valuation Mistakes Ssrn-Id411600hemantsharma.usNo ratings yet
- Pablo Fernández 80 Common Errors in Company Valuation IESE Business SchoolDocument27 pagesPablo Fernández 80 Common Errors in Company Valuation IESE Business SchoolFFNo ratings yet
- Big Data Analysis Assig.2Document5 pagesBig Data Analysis Assig.2gerrydenis20No ratings yet
- Assignment No. 1Document5 pagesAssignment No. 1Black PearlNo ratings yet
- (Swaraj Kishan Bhuyan)Document3 pages(Swaraj Kishan Bhuyan)ASUTOSH MUDULINo ratings yet
- 6130 Test 2.2 PracticeDocument15 pages6130 Test 2.2 PracticeTash KentNo ratings yet
- Results Descriptives: Sex Pretest Iq Posttest Iq Midquiz Finalquiz Midtop FinaltopDocument5 pagesResults Descriptives: Sex Pretest Iq Posttest Iq Midquiz Finalquiz Midtop FinaltopHeinix FrØxt WalfletNo ratings yet
- Parte InferencialDocument46 pagesParte InferencialLeidy Tatiana MartinezNo ratings yet
- Taller de PortafolioDocument18 pagesTaller de PortafolioEdi CostaNo ratings yet
- Chapter 4-5.editedDocument22 pagesChapter 4-5.editedannieezeh9No ratings yet
- Jasika RM LabDocument92 pagesJasika RM LabJessica NigamNo ratings yet
- Big Data Management and Architecture AssignmentDocument9 pagesBig Data Management and Architecture Assignmentutsavkp99No ratings yet
- Apollo Case QuestionsDocument2 pagesApollo Case QuestionsNitin VermaNo ratings yet
- Financial Management - 1 Project On Portfolio Management: Section 1 - Working Group F1Document7 pagesFinancial Management - 1 Project On Portfolio Management: Section 1 - Working Group F1soumya mishraNo ratings yet
- Introduction To Statistics: Institute of Trading & Portfolio ManagementDocument12 pagesIntroduction To Statistics: Institute of Trading & Portfolio ManagementHakam DaoudNo ratings yet
- Extra Exercises - Introductory StatisticsDocument8 pagesExtra Exercises - Introductory Statisticsworks.aliaazmiNo ratings yet
- Risk (Part 2) - Variance & Covariance - Varsity by Zerodha - All Things Stock Markets SimplifiedDocument6 pagesRisk (Part 2) - Variance & Covariance - Varsity by Zerodha - All Things Stock Markets SimplifiedSenthil KumarNo ratings yet
- Case Study Beta Management Company: Raman Dhiman Indian Institute of Management (Iim), ShillongDocument8 pagesCase Study Beta Management Company: Raman Dhiman Indian Institute of Management (Iim), ShillongFabián Fuentes100% (1)
- Course Hero Reference 4Document11 pagesCourse Hero Reference 4Sancai RamirezNo ratings yet
- Assignment Section: 2 Submitted To:: Business StatisticsDocument10 pagesAssignment Section: 2 Submitted To:: Business StatisticsRochi AhmedNo ratings yet
- Problem 1Document6 pagesProblem 1Yohanna Bregiba PurbaNo ratings yet
- 0feaf24f-6a96-4279-97a1-86708e467593 (1)Document7 pages0feaf24f-6a96-4279-97a1-86708e467593 (1)simandharNo ratings yet
- Portfolio ModelsDocument19 pagesPortfolio ModelsP.sai.prathyushaNo ratings yet
- 10.1 Product ConsistencyDocument9 pages10.1 Product ConsistencyBiniyam haileNo ratings yet
- Measures of The Location of The DataDocument13 pagesMeasures of The Location of The DataDanzen Dema-alaNo ratings yet
- Study Material Hypothesis Testing PDFDocument19 pagesStudy Material Hypothesis Testing PDFMajji ToshithaNo ratings yet
- 20151113141143introduction To Statistics-7Document29 pages20151113141143introduction To Statistics-7thinagaranNo ratings yet
- 2035 CH2 NotesDocument42 pages2035 CH2 Noteskejacob629No ratings yet
- Lecture Notes - Logistic RegressionDocument11 pagesLecture Notes - Logistic RegressionPrathap BalachandraNo ratings yet
- Horizon Group Eco 204 Term PaperDocument10 pagesHorizon Group Eco 204 Term Paperআহনাফ গালিবNo ratings yet
- C 4 - Discrete Probability CalculatorsDocument23 pagesC 4 - Discrete Probability CalculatorsGautam DugarNo ratings yet
- Statistics and Data Analysis For Nursing Research 2Nd Edition 2Nd Edition Full Chapter PDFDocument53 pagesStatistics and Data Analysis For Nursing Research 2Nd Edition 2Nd Edition Full Chapter PDFespinlkumaza100% (4)
- Mean and Standard Deviation SolutionDocument4 pagesMean and Standard Deviation SolutionC.E.O AnnieNo ratings yet
- 20% 0.25 To 1 0.25 To 1 20% 50% 1 To 1 1 To 1 50% 75% 3 To 1 3 To 1 75% 90% 9 To 1 9 To 1 90%Document6 pages20% 0.25 To 1 0.25 To 1 20% 50% 1 To 1 1 To 1 50% 75% 3 To 1 3 To 1 75% 90% 9 To 1 9 To 1 90%krish lopezNo ratings yet
- Sta Chương15Document4 pagesSta Chương15Nguyễn Thu HươngNo ratings yet
- Exercise 2.1: Historical Simulation MethodDocument8 pagesExercise 2.1: Historical Simulation MethodHang PhamNo ratings yet
- Safe As Houses Better Way To Measure Investment EfficacyDocument8 pagesSafe As Houses Better Way To Measure Investment EfficacyCarlos TresemeNo ratings yet
- Formativetest Bus - Math Q1 W1-W4Document4 pagesFormativetest Bus - Math Q1 W1-W4ARON PAUL SAN MIGUELNo ratings yet
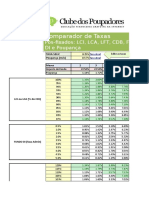
- CP Comparador de Taxas LCI LCA LFT CDB Poupanca FundosDIDocument5 pagesCP Comparador de Taxas LCI LCA LFT CDB Poupanca FundosDIeduardolavratiNo ratings yet
- Long Lasting ResourcesDocument41 pagesLong Lasting ResourcesOsmar ZayasNo ratings yet
- MCHA022 (Analytical Chemistry 2)Document62 pagesMCHA022 (Analytical Chemistry 2)Mbali MazongweNo ratings yet
- L03 ECO220 PrintDocument15 pagesL03 ECO220 PrintAli SioNo ratings yet
- SD Corr Cov SolutionDocument5 pagesSD Corr Cov SolutionRidwan IslamNo ratings yet
- Global Div Inv Grade Income Trust II-IndyMac 2005-AR14!3!31-10Document17 pagesGlobal Div Inv Grade Income Trust II-IndyMac 2005-AR14!3!31-10Barbara J. FordeNo ratings yet
- Annual Letter 2016Document25 pagesAnnual Letter 2016Incandescent CapitalNo ratings yet
- CRSP Deciles Size Study Per2019 12 31Document3 pagesCRSP Deciles Size Study Per2019 12 31AnDReW DisHNo ratings yet
- True Regression Model: C - Logincome = Β + Β · B - Years Of Schooling + Β · D - Age + Β · E - Female + Β ·H - Smoker + Β · D - Age ·E - Female + Β · D - Age · H - Smoker + ΕDocument7 pagesTrue Regression Model: C - Logincome = Β + Β · B - Years Of Schooling + Β · D - Age + Β · E - Female + Β ·H - Smoker + Β · D - Age ·E - Female + Β · D - Age · H - Smoker + ΕAnonymous 5eT9JfDMNo ratings yet
- CovarDocument9 pagesCovarLoubill Dayne AceronNo ratings yet
- Currency Options Pricing Under Mean Reverting VolatilityDocument20 pagesCurrency Options Pricing Under Mean Reverting Volatilitymichael odiemboNo ratings yet
- Price and Return Data For Walmart (WMT) and Target (TGT)Document8 pagesPrice and Return Data For Walmart (WMT) and Target (TGT)Raja17No ratings yet
- LM09 Parametric and Non-Parametric Tests of Independence IFT NotesDocument7 pagesLM09 Parametric and Non-Parametric Tests of Independence IFT NotesYuri BNo ratings yet
- RegressionDocument21 pagesRegressionJoyce ChoyNo ratings yet
- ML Stragegic Balance INDEX - FACT SHEETDocument3 pagesML Stragegic Balance INDEX - FACT SHEETRaj JarNo ratings yet
- Math Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesFrom EverandMath Practice Simplified: Decimals & Percents (Book H): Practicing the Concepts of Decimals and PercentagesRating: 5 out of 5 stars5/5 (3)
- Students Perceptions About Games in ClassroomDocument12 pagesStudents Perceptions About Games in ClassroomAlex DamacenoNo ratings yet
- How To Write A German CVDocument17 pagesHow To Write A German CVRužica MatićNo ratings yet
- Statistical Report On The 2013 National Labour Force SurveyDocument480 pagesStatistical Report On The 2013 National Labour Force Surveymusie100% (1)
- Dr. Poonam Madan: The Consumer ResearchDocument158 pagesDr. Poonam Madan: The Consumer Researchmuskan taliwalNo ratings yet
- Organisational Study Report of OushadhiDocument15 pagesOrganisational Study Report of OushadhiReema JohnyNo ratings yet
- Shell CaseDocument12 pagesShell CasewchaitanNo ratings yet
- Communication Scale (Ages 12-18)Document4 pagesCommunication Scale (Ages 12-18)Sharma Harshita 0568100% (1)
- Eop 32 01Document20 pagesEop 32 01kamranNo ratings yet
- Assessing The Impact of Cost Inflation On Building Construction Material A Study in Wolaita Zone Southern EthiopiaDocument7 pagesAssessing The Impact of Cost Inflation On Building Construction Material A Study in Wolaita Zone Southern EthiopiaSusan AlienaNo ratings yet
- Solution AssignmentDocument34 pagesSolution AssignmentBizuayehu AyeleNo ratings yet
- Raven 1989Document16 pagesRaven 1989Varga Katalin EszterNo ratings yet
- Impact of Strategic Management On CompetDocument15 pagesImpact of Strategic Management On CompetHabtamu AysheshimNo ratings yet
- AI For HRMDocument2 pagesAI For HRMRupjilika TimungpiNo ratings yet
- Group1 Research ProposalDocument10 pagesGroup1 Research ProposalAB124P - Vaflor, John CrisNo ratings yet
- @ 2 Effects of Electronic Medical Records On Patient Safety Culture: The Perspective of NursesDocument7 pages@ 2 Effects of Electronic Medical Records On Patient Safety Culture: The Perspective of NursesElizabeth Coten100% (1)
- Treatise On The Theory of Determinants by Thomas MuirDocument256 pagesTreatise On The Theory of Determinants by Thomas MuirUday Kumar100% (1)
- 1 - Business StatisticsDocument82 pages1 - Business StatisticsGagan Deep SinghNo ratings yet
- كتاب الاحصاء الحيويةDocument67 pagesكتاب الاحصاء الحيويةziad aymanNo ratings yet
- Salesman ReportDocument10 pagesSalesman ReportJaninne BianesNo ratings yet
- What Is Validity in ResearchDocument3 pagesWhat Is Validity in ResearchMelody BautistaNo ratings yet
- DCTP ReportDocument10 pagesDCTP ReportAtubrah PrinceNo ratings yet
- Tools For A Multiaxial Fatigue Analysis of Structures Submitted To Random VibrationsDocument6 pagesTools For A Multiaxial Fatigue Analysis of Structures Submitted To Random Vibrationsjvo917No ratings yet
- MBK7005M Building and Leading High Performing Teams Module HandbookDocument5 pagesMBK7005M Building and Leading High Performing Teams Module HandbookHelder AlvesNo ratings yet
- Psychometric Development and Validation of GaslightingDocument15 pagesPsychometric Development and Validation of GaslightingYang ZhangNo ratings yet
- DMC Report - FinalDocument129 pagesDMC Report - FinalAlyssa RobertsNo ratings yet
- Prevalence and Correlates of Poor Sleep Quality Among Medical Students at A Nigerian UniversityDocument7 pagesPrevalence and Correlates of Poor Sleep Quality Among Medical Students at A Nigerian UniversityCandra FaridNo ratings yet
- Atroloji-Iq IlişkisiDocument3 pagesAtroloji-Iq Ilişkisisefa şahinNo ratings yet