
EE20BTECH11035 AutoRegression
EE20BTECH11035 AutoRegression
You might also like
- Modern Big Data AlgorithmsDocument52 pagesModern Big Data Algorithmsdakuan luNo ratings yet
- Paper 11-Shape Prediction Linear Algorithm Using FuzzyDocument5 pagesPaper 11-Shape Prediction Linear Algorithm Using FuzzyEditor IJACSANo ratings yet
- Digital Image Processing Segmntation Lab With PythonDocument9 pagesDigital Image Processing Segmntation Lab With PythonVishal VermaNo ratings yet
- Achour Idoughi - Project03Document7 pagesAchour Idoughi - Project03Achour IdoughiNo ratings yet
- Color TrackingDocument5 pagesColor TrackingNicky MuscatNo ratings yet
- Image Search by Features of Sorted Gray Level Histogram Polynomial CurveDocument6 pagesImage Search by Features of Sorted Gray Level Histogram Polynomial Curvematkhau01No ratings yet
- Image Processing Part 3Document5 pagesImage Processing Part 3Felix2ZNo ratings yet
- Principle Component AnalysisDocument4 pagesPrinciple Component AnalysisRutvikNo ratings yet
- Secene Image SegmentationDocument30 pagesSecene Image SegmentationRasool ReddyNo ratings yet
- Unit 2 MMDocument11 pagesUnit 2 MMjusticesavior08No ratings yet
- Linear RegressionDocument6 pagesLinear RegressionAishwarya GawaliNo ratings yet
- Asift AsiftDocument11 pagesAsift AsiftHaris MasoodNo ratings yet
- B7 An Image Enhancement Method For Extracting Multi-License Plate Region Yun 2017Document20 pagesB7 An Image Enhancement Method For Extracting Multi-License Plate Region Yun 2017Ruben CuervoNo ratings yet
- ML Lab - Sukanya RajaDocument23 pagesML Lab - Sukanya RajaRick MitraNo ratings yet
- Problem Statement 40Document8 pagesProblem Statement 40Let see With positiveNo ratings yet
- Analysis of Various Techniques Used For Implementation of Video Surveillance SystemDocument6 pagesAnalysis of Various Techniques Used For Implementation of Video Surveillance SystemShakeel RanaNo ratings yet
- Jurnal Tugas JSTDocument5 pagesJurnal Tugas JSTAmsal MaestroNo ratings yet
- Image Encryption Using Chaos Maps: Aarya Arun, Indu Rallabhandi, Rachana Jayaram November 2019Document17 pagesImage Encryption Using Chaos Maps: Aarya Arun, Indu Rallabhandi, Rachana Jayaram November 2019Animesh PrasadNo ratings yet
- New Algothrithm of Image Segmentation Using Curve Fitting Based Higher Polynimial SmoothingDocument10 pagesNew Algothrithm of Image Segmentation Using Curve Fitting Based Higher Polynimial SmoothingKhoa LêNo ratings yet
- Image Classification Using Backpropagation Neural Network Without Using Built-In FunctionDocument8 pagesImage Classification Using Backpropagation Neural Network Without Using Built-In FunctionMaisha MashiataNo ratings yet
- InTech-High Speed Architecure Based On Fpga For A Stereo Vision AlgorithmDocument18 pagesInTech-High Speed Architecure Based On Fpga For A Stereo Vision AlgorithmdvtruongsonNo ratings yet
- 1214 - خمسه عشریDocument5 pages1214 - خمسه عشریm1.nourianNo ratings yet
- Journal of Computer Applications - WWW - Jcaksrce.org - Volume 4 Issue 2Document5 pagesJournal of Computer Applications - WWW - Jcaksrce.org - Volume 4 Issue 2Journal of Computer ApplicationsNo ratings yet
- Image Processing: Mentor: Saqib AzimDocument24 pagesImage Processing: Mentor: Saqib AzimatgNo ratings yet
- Supervidsed AlgorithmDocument19 pagesSupervidsed AlgorithmMittu RajareddyNo ratings yet
- Lab#10 AiDocument3 pagesLab#10 AiMomel FatimaNo ratings yet
- Virtual Mouse Inputting Device by Hand Gesture Tracking and RecognitionDocument8 pagesVirtual Mouse Inputting Device by Hand Gesture Tracking and Recognitionricx31No ratings yet
- Automatic Gradient Threshold Determination For Edge DetectionDocument4 pagesAutomatic Gradient Threshold Determination For Edge Detectionapi-3706534No ratings yet
- Image Quality Enhancement Algorithm Based On Game Theory Model-1Document29 pagesImage Quality Enhancement Algorithm Based On Game Theory Model-1Karthik BollepalliNo ratings yet
- Progress Report Loan Approval Predictor Using Machine LearningDocument15 pagesProgress Report Loan Approval Predictor Using Machine LearningRavi RajNo ratings yet
- Fingerprint Synthesis Towards Constructing An Enhanced Authentication System Using Low Resolution WebcamDocument10 pagesFingerprint Synthesis Towards Constructing An Enhanced Authentication System Using Low Resolution WebcamMd. Rajibul Islam100% (2)
- Batch 11 (Histogram)Document42 pagesBatch 11 (Histogram)Abhinav KumarNo ratings yet
- First ReportDocument14 pagesFirst Reportdnthrtm3No ratings yet
- Moving Object Detection Using Local Binary Pattern and Gaussian Background ModelDocument10 pagesMoving Object Detection Using Local Binary Pattern and Gaussian Background ModelJEEVIT HNo ratings yet
- Lukin Krylov Na So NovDocument4 pagesLukin Krylov Na So NovHoavo KhuyetNo ratings yet
- CV Utsav Kashyap 12019414Document17 pagesCV Utsav Kashyap 12019414Utsav KashyapNo ratings yet
- Character Recognition Using Neural Networks: Rókus Arnold, Póth MiklósDocument4 pagesCharacter Recognition Using Neural Networks: Rókus Arnold, Póth MiklósSharath JagannathanNo ratings yet
- Scale Invariant Feature Transfrom: A Seminar OnDocument8 pagesScale Invariant Feature Transfrom: A Seminar OnHemanthkumar TNo ratings yet
- Image Classification Using Edge Detection Withe Fuzzy Logic: Par: Chettouh Safieddine Sohbi Salem Hammoudi MabroukDocument16 pagesImage Classification Using Edge Detection Withe Fuzzy Logic: Par: Chettouh Safieddine Sohbi Salem Hammoudi MabroukDamri BachirNo ratings yet
- Удаление объектов с фотоDocument6 pagesУдаление объектов с фотоВиталий ЕвсюковNo ratings yet
- Kazemi One Millisecond Face 2014 CVPR PaperDocument8 pagesKazemi One Millisecond Face 2014 CVPR PaperRomil ShahNo ratings yet
- Assignment 3 - ReinforcementLearning - 200508263 - AdityaAnantharaman - TrikkurDocument9 pagesAssignment 3 - ReinforcementLearning - 200508263 - AdityaAnantharaman - TrikkuradyanrfutureNo ratings yet
- One Millisecond Face Alignment With An Ensemble of Regression TreesDocument8 pagesOne Millisecond Face Alignment With An Ensemble of Regression TreesJeffersonNo ratings yet
- 2 Description of T He Proposed SystemDocument10 pages2 Description of T He Proposed SystemGautham ShettyNo ratings yet
- Convolutional Neural Networks For Automatic Image ColorizationDocument15 pagesConvolutional Neural Networks For Automatic Image ColorizationChilupuri SreeyaNo ratings yet
- Unsupervised 3D Object Recognition and Reconstruction in Unordered DatasetsDocument8 pagesUnsupervised 3D Object Recognition and Reconstruction in Unordered DatasetsRicardo SutanaNo ratings yet
- A Novel Technique - FullDocument6 pagesA Novel Technique - FullTJPRC PublicationsNo ratings yet
- Shape Classification Using Histogram of Oriented GradientsDocument6 pagesShape Classification Using Histogram of Oriented Gradientspi194043No ratings yet
- Lab NN KNN SVMDocument13 pagesLab NN KNN SVMmaaian.iancuNo ratings yet
- Experience Implementing An Elliptical Head Tracker in MatlabDocument7 pagesExperience Implementing An Elliptical Head Tracker in MatlabdewddudeNo ratings yet
- Gradient OperatorDocument5 pagesGradient Operatorchaithra580No ratings yet
- Similarity-Based Image RetrievalDocument11 pagesSimilarity-Based Image RetrievalHugo UegoNo ratings yet
- Stock Price Prediction Using Machine Learning in PythonDocument49 pagesStock Price Prediction Using Machine Learning in PythonKATHIKA SAI KRISHNA URK17CS063100% (1)
- Color Feature Based Object Localization in Real Time ImplementationDocument7 pagesColor Feature Based Object Localization in Real Time ImplementationPoitu ErmawantiaNo ratings yet
- OverviewofthresholdingDocument5 pagesOverviewofthresholdingSanjay ShahNo ratings yet
- An Efficient System For Automatic Sorting of The Ceramic TilesDocument3 pagesAn Efficient System For Automatic Sorting of The Ceramic TilesMekaTronNo ratings yet
- Satgan PaperDocument17 pagesSatgan PaperraleighNo ratings yet
- Matlab ExercisesDocument5 pagesMatlab Exercisesj_salazar20No ratings yet
- Digital Image Processing and Recognition Using PytDocument4 pagesDigital Image Processing and Recognition Using Pyt9920102030No ratings yet
- Cad SlidesviDocument69 pagesCad SlidesvimaxsilverNo ratings yet
- Call 3220Document456 pagesCall 3220Nano GomeshNo ratings yet
- DDA Algorithm 1Document16 pagesDDA Algorithm 1Sakshi PatilNo ratings yet
- Data-Structures-Lecture 1Document12 pagesData-Structures-Lecture 1Zakir HossenNo ratings yet
- A Multitier Deep Learning Model For Arrhythmia DetectionDocument9 pagesA Multitier Deep Learning Model For Arrhythmia DetectionSahil TiwariNo ratings yet
- Week 07bDocument11 pagesWeek 07bngokfong yuNo ratings yet
- DNN Cluster S2 22 MidSem MakeupDocument7 pagesDNN Cluster S2 22 MidSem MakeuprahulsgaykeNo ratings yet
- Unit I: Discrete Time Signals and Systems: Dr. Raghu Indrakanti, Ph.D. Assistant Professor E.C.E DepartmentDocument47 pagesUnit I: Discrete Time Signals and Systems: Dr. Raghu Indrakanti, Ph.D. Assistant Professor E.C.E Departmentanil kumarNo ratings yet
- Final ReportDocument11 pagesFinal ReportSi BasNo ratings yet
- Department of Computer Science & Engineering Practical File Subject: Artificial Intelligence Lab (BTCS 605-18) B. Tech - 6 Semester (Batch 2020-24)Document28 pagesDepartment of Computer Science & Engineering Practical File Subject: Artificial Intelligence Lab (BTCS 605-18) B. Tech - 6 Semester (Batch 2020-24)Pankaj KumarNo ratings yet
- Lecture 9 Binary Search TreesDocument28 pagesLecture 9 Binary Search TreesMuhammad Owais khanNo ratings yet
- Lect 7Document10 pagesLect 7Salem SobhyNo ratings yet
- Compulsory To All Branch 14Phdrm: Research MethodologyDocument6 pagesCompulsory To All Branch 14Phdrm: Research MethodologyAmbica AnnavarapuNo ratings yet
- Comparative Evaluation of Filters For Liver Ultrasound Image EnhancementDocument5 pagesComparative Evaluation of Filters For Liver Ultrasound Image EnhancementInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- EC6512 Communication System Lab ManualDocument52 pagesEC6512 Communication System Lab ManualSalai Kishwar JahanNo ratings yet
- Fem Coding OverviewDocument10 pagesFem Coding OverviewGopinath ChakrabortyNo ratings yet
- CE2407B Lecture 2 PDFDocument26 pagesCE2407B Lecture 2 PDFJeremus the MedicNo ratings yet
- Minimax Math FunctionsDocument7 pagesMinimax Math FunctionsNenad PetrovicNo ratings yet
- Numerical AnalysisDocument9 pagesNumerical Analysisamir nabilNo ratings yet
- Finite Element MethodDocument24 pagesFinite Element Methodshivam choudhary0% (1)
- Image Compression Using Resilient-Propagation Neural NetworkDocument5 pagesImage Compression Using Resilient-Propagation Neural NetworkInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Dcs Assignment No 2Document6 pagesDcs Assignment No 2ramjee26No ratings yet
- Transitive ClosureDocument9 pagesTransitive ClosureSK108108No ratings yet
- TSE X30 ManualDocument3 pagesTSE X30 ManualAndrès LandaetaNo ratings yet
- Lesson 2 Mat183Document9 pagesLesson 2 Mat183itsmeliyaarmyNo ratings yet
- Modified Parametric Approach For Linear Plus Linear Fractional Programming ProblemDocument5 pagesModified Parametric Approach For Linear Plus Linear Fractional Programming ProblemcompmathsjournalwsNo ratings yet
- Computer Graphics and Multimedia Systems SCS1302: Unit 1Document51 pagesComputer Graphics and Multimedia Systems SCS1302: Unit 1ss sriNo ratings yet
- Kernel Isomap: Heeyoul Choi and Seungjin ChoiDocument6 pagesKernel Isomap: Heeyoul Choi and Seungjin ChoiMaria LomeliNo ratings yet
- SUMSEM2022-23 CSI3020 TH VL2022230700600 2023-06-08 Reference-Material-IDocument115 pagesSUMSEM2022-23 CSI3020 TH VL2022230700600 2023-06-08 Reference-Material-IVishnu MukundanNo ratings yet











































































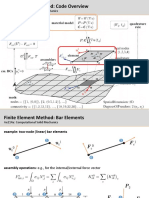

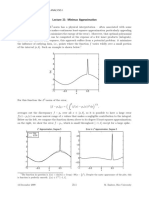











Download as pdf or txt
You might also like
- Modern Big Data AlgorithmsDocument52 pagesModern Big Data Algorithmsdakuan luNo ratings yet
- Paper 11-Shape Prediction Linear Algorithm Using FuzzyDocument5 pagesPaper 11-Shape Prediction Linear Algorithm Using FuzzyEditor IJACSANo ratings yet
- Digital Image Processing Segmntation Lab With PythonDocument9 pagesDigital Image Processing Segmntation Lab With PythonVishal VermaNo ratings yet
- Achour Idoughi - Project03Document7 pagesAchour Idoughi - Project03Achour IdoughiNo ratings yet
- Color TrackingDocument5 pagesColor TrackingNicky MuscatNo ratings yet
- Image Search by Features of Sorted Gray Level Histogram Polynomial CurveDocument6 pagesImage Search by Features of Sorted Gray Level Histogram Polynomial Curvematkhau01No ratings yet
- Image Processing Part 3Document5 pagesImage Processing Part 3Felix2ZNo ratings yet
- Principle Component AnalysisDocument4 pagesPrinciple Component AnalysisRutvikNo ratings yet
- Secene Image SegmentationDocument30 pagesSecene Image SegmentationRasool ReddyNo ratings yet
- Unit 2 MMDocument11 pagesUnit 2 MMjusticesavior08No ratings yet
- Linear RegressionDocument6 pagesLinear RegressionAishwarya GawaliNo ratings yet
- Asift AsiftDocument11 pagesAsift AsiftHaris MasoodNo ratings yet
- B7 An Image Enhancement Method For Extracting Multi-License Plate Region Yun 2017Document20 pagesB7 An Image Enhancement Method For Extracting Multi-License Plate Region Yun 2017Ruben CuervoNo ratings yet
- ML Lab - Sukanya RajaDocument23 pagesML Lab - Sukanya RajaRick MitraNo ratings yet
- Problem Statement 40Document8 pagesProblem Statement 40Let see With positiveNo ratings yet
- Analysis of Various Techniques Used For Implementation of Video Surveillance SystemDocument6 pagesAnalysis of Various Techniques Used For Implementation of Video Surveillance SystemShakeel RanaNo ratings yet
- Jurnal Tugas JSTDocument5 pagesJurnal Tugas JSTAmsal MaestroNo ratings yet
- Image Encryption Using Chaos Maps: Aarya Arun, Indu Rallabhandi, Rachana Jayaram November 2019Document17 pagesImage Encryption Using Chaos Maps: Aarya Arun, Indu Rallabhandi, Rachana Jayaram November 2019Animesh PrasadNo ratings yet
- New Algothrithm of Image Segmentation Using Curve Fitting Based Higher Polynimial SmoothingDocument10 pagesNew Algothrithm of Image Segmentation Using Curve Fitting Based Higher Polynimial SmoothingKhoa LêNo ratings yet
- Image Classification Using Backpropagation Neural Network Without Using Built-In FunctionDocument8 pagesImage Classification Using Backpropagation Neural Network Without Using Built-In FunctionMaisha MashiataNo ratings yet
- InTech-High Speed Architecure Based On Fpga For A Stereo Vision AlgorithmDocument18 pagesInTech-High Speed Architecure Based On Fpga For A Stereo Vision AlgorithmdvtruongsonNo ratings yet
- 1214 - خمسه عشریDocument5 pages1214 - خمسه عشریm1.nourianNo ratings yet
- Journal of Computer Applications - WWW - Jcaksrce.org - Volume 4 Issue 2Document5 pagesJournal of Computer Applications - WWW - Jcaksrce.org - Volume 4 Issue 2Journal of Computer ApplicationsNo ratings yet
- Image Processing: Mentor: Saqib AzimDocument24 pagesImage Processing: Mentor: Saqib AzimatgNo ratings yet
- Supervidsed AlgorithmDocument19 pagesSupervidsed AlgorithmMittu RajareddyNo ratings yet
- Lab#10 AiDocument3 pagesLab#10 AiMomel FatimaNo ratings yet
- Virtual Mouse Inputting Device by Hand Gesture Tracking and RecognitionDocument8 pagesVirtual Mouse Inputting Device by Hand Gesture Tracking and Recognitionricx31No ratings yet
- Automatic Gradient Threshold Determination For Edge DetectionDocument4 pagesAutomatic Gradient Threshold Determination For Edge Detectionapi-3706534No ratings yet
- Image Quality Enhancement Algorithm Based On Game Theory Model-1Document29 pagesImage Quality Enhancement Algorithm Based On Game Theory Model-1Karthik BollepalliNo ratings yet
- Progress Report Loan Approval Predictor Using Machine LearningDocument15 pagesProgress Report Loan Approval Predictor Using Machine LearningRavi RajNo ratings yet
- Fingerprint Synthesis Towards Constructing An Enhanced Authentication System Using Low Resolution WebcamDocument10 pagesFingerprint Synthesis Towards Constructing An Enhanced Authentication System Using Low Resolution WebcamMd. Rajibul Islam100% (2)
- Batch 11 (Histogram)Document42 pagesBatch 11 (Histogram)Abhinav KumarNo ratings yet
- First ReportDocument14 pagesFirst Reportdnthrtm3No ratings yet
- Moving Object Detection Using Local Binary Pattern and Gaussian Background ModelDocument10 pagesMoving Object Detection Using Local Binary Pattern and Gaussian Background ModelJEEVIT HNo ratings yet
- Lukin Krylov Na So NovDocument4 pagesLukin Krylov Na So NovHoavo KhuyetNo ratings yet
- CV Utsav Kashyap 12019414Document17 pagesCV Utsav Kashyap 12019414Utsav KashyapNo ratings yet
- Character Recognition Using Neural Networks: Rókus Arnold, Póth MiklósDocument4 pagesCharacter Recognition Using Neural Networks: Rókus Arnold, Póth MiklósSharath JagannathanNo ratings yet
- Scale Invariant Feature Transfrom: A Seminar OnDocument8 pagesScale Invariant Feature Transfrom: A Seminar OnHemanthkumar TNo ratings yet
- Image Classification Using Edge Detection Withe Fuzzy Logic: Par: Chettouh Safieddine Sohbi Salem Hammoudi MabroukDocument16 pagesImage Classification Using Edge Detection Withe Fuzzy Logic: Par: Chettouh Safieddine Sohbi Salem Hammoudi MabroukDamri BachirNo ratings yet
- Удаление объектов с фотоDocument6 pagesУдаление объектов с фотоВиталий ЕвсюковNo ratings yet
- Kazemi One Millisecond Face 2014 CVPR PaperDocument8 pagesKazemi One Millisecond Face 2014 CVPR PaperRomil ShahNo ratings yet
- Assignment 3 - ReinforcementLearning - 200508263 - AdityaAnantharaman - TrikkurDocument9 pagesAssignment 3 - ReinforcementLearning - 200508263 - AdityaAnantharaman - TrikkuradyanrfutureNo ratings yet
- One Millisecond Face Alignment With An Ensemble of Regression TreesDocument8 pagesOne Millisecond Face Alignment With An Ensemble of Regression TreesJeffersonNo ratings yet
- 2 Description of T He Proposed SystemDocument10 pages2 Description of T He Proposed SystemGautham ShettyNo ratings yet
- Convolutional Neural Networks For Automatic Image ColorizationDocument15 pagesConvolutional Neural Networks For Automatic Image ColorizationChilupuri SreeyaNo ratings yet
- Unsupervised 3D Object Recognition and Reconstruction in Unordered DatasetsDocument8 pagesUnsupervised 3D Object Recognition and Reconstruction in Unordered DatasetsRicardo SutanaNo ratings yet
- A Novel Technique - FullDocument6 pagesA Novel Technique - FullTJPRC PublicationsNo ratings yet
- Shape Classification Using Histogram of Oriented GradientsDocument6 pagesShape Classification Using Histogram of Oriented Gradientspi194043No ratings yet
- Lab NN KNN SVMDocument13 pagesLab NN KNN SVMmaaian.iancuNo ratings yet
- Experience Implementing An Elliptical Head Tracker in MatlabDocument7 pagesExperience Implementing An Elliptical Head Tracker in MatlabdewddudeNo ratings yet
- Gradient OperatorDocument5 pagesGradient Operatorchaithra580No ratings yet
- Similarity-Based Image RetrievalDocument11 pagesSimilarity-Based Image RetrievalHugo UegoNo ratings yet
- Stock Price Prediction Using Machine Learning in PythonDocument49 pagesStock Price Prediction Using Machine Learning in PythonKATHIKA SAI KRISHNA URK17CS063100% (1)
- Color Feature Based Object Localization in Real Time ImplementationDocument7 pagesColor Feature Based Object Localization in Real Time ImplementationPoitu ErmawantiaNo ratings yet
- OverviewofthresholdingDocument5 pagesOverviewofthresholdingSanjay ShahNo ratings yet
- An Efficient System For Automatic Sorting of The Ceramic TilesDocument3 pagesAn Efficient System For Automatic Sorting of The Ceramic TilesMekaTronNo ratings yet
- Satgan PaperDocument17 pagesSatgan PaperraleighNo ratings yet
- Matlab ExercisesDocument5 pagesMatlab Exercisesj_salazar20No ratings yet
- Digital Image Processing and Recognition Using PytDocument4 pagesDigital Image Processing and Recognition Using Pyt9920102030No ratings yet
- Cad SlidesviDocument69 pagesCad SlidesvimaxsilverNo ratings yet
- Call 3220Document456 pagesCall 3220Nano GomeshNo ratings yet
- DDA Algorithm 1Document16 pagesDDA Algorithm 1Sakshi PatilNo ratings yet
- Data-Structures-Lecture 1Document12 pagesData-Structures-Lecture 1Zakir HossenNo ratings yet
- A Multitier Deep Learning Model For Arrhythmia DetectionDocument9 pagesA Multitier Deep Learning Model For Arrhythmia DetectionSahil TiwariNo ratings yet
- Week 07bDocument11 pagesWeek 07bngokfong yuNo ratings yet
- DNN Cluster S2 22 MidSem MakeupDocument7 pagesDNN Cluster S2 22 MidSem MakeuprahulsgaykeNo ratings yet
- Unit I: Discrete Time Signals and Systems: Dr. Raghu Indrakanti, Ph.D. Assistant Professor E.C.E DepartmentDocument47 pagesUnit I: Discrete Time Signals and Systems: Dr. Raghu Indrakanti, Ph.D. Assistant Professor E.C.E Departmentanil kumarNo ratings yet
- Final ReportDocument11 pagesFinal ReportSi BasNo ratings yet
- Department of Computer Science & Engineering Practical File Subject: Artificial Intelligence Lab (BTCS 605-18) B. Tech - 6 Semester (Batch 2020-24)Document28 pagesDepartment of Computer Science & Engineering Practical File Subject: Artificial Intelligence Lab (BTCS 605-18) B. Tech - 6 Semester (Batch 2020-24)Pankaj KumarNo ratings yet
- Lecture 9 Binary Search TreesDocument28 pagesLecture 9 Binary Search TreesMuhammad Owais khanNo ratings yet
- Lect 7Document10 pagesLect 7Salem SobhyNo ratings yet
- Compulsory To All Branch 14Phdrm: Research MethodologyDocument6 pagesCompulsory To All Branch 14Phdrm: Research MethodologyAmbica AnnavarapuNo ratings yet
- Comparative Evaluation of Filters For Liver Ultrasound Image EnhancementDocument5 pagesComparative Evaluation of Filters For Liver Ultrasound Image EnhancementInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- EC6512 Communication System Lab ManualDocument52 pagesEC6512 Communication System Lab ManualSalai Kishwar JahanNo ratings yet
- Fem Coding OverviewDocument10 pagesFem Coding OverviewGopinath ChakrabortyNo ratings yet
- CE2407B Lecture 2 PDFDocument26 pagesCE2407B Lecture 2 PDFJeremus the MedicNo ratings yet
- Minimax Math FunctionsDocument7 pagesMinimax Math FunctionsNenad PetrovicNo ratings yet
- Numerical AnalysisDocument9 pagesNumerical Analysisamir nabilNo ratings yet
- Finite Element MethodDocument24 pagesFinite Element Methodshivam choudhary0% (1)
- Image Compression Using Resilient-Propagation Neural NetworkDocument5 pagesImage Compression Using Resilient-Propagation Neural NetworkInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Dcs Assignment No 2Document6 pagesDcs Assignment No 2ramjee26No ratings yet
- Transitive ClosureDocument9 pagesTransitive ClosureSK108108No ratings yet
- TSE X30 ManualDocument3 pagesTSE X30 ManualAndrès LandaetaNo ratings yet
- Lesson 2 Mat183Document9 pagesLesson 2 Mat183itsmeliyaarmyNo ratings yet
- Modified Parametric Approach For Linear Plus Linear Fractional Programming ProblemDocument5 pagesModified Parametric Approach For Linear Plus Linear Fractional Programming ProblemcompmathsjournalwsNo ratings yet
- Computer Graphics and Multimedia Systems SCS1302: Unit 1Document51 pagesComputer Graphics and Multimedia Systems SCS1302: Unit 1ss sriNo ratings yet
- Kernel Isomap: Heeyoul Choi and Seungjin ChoiDocument6 pagesKernel Isomap: Heeyoul Choi and Seungjin ChoiMaria LomeliNo ratings yet
- SUMSEM2022-23 CSI3020 TH VL2022230700600 2023-06-08 Reference-Material-IDocument115 pagesSUMSEM2022-23 CSI3020 TH VL2022230700600 2023-06-08 Reference-Material-IVishnu MukundanNo ratings yet