
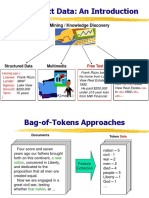
CSE442 Text
CSE442 Text
You might also like
- Attardo Raskin 1991 Script Theory Revis (It) EdDocument56 pagesAttardo Raskin 1991 Script Theory Revis (It) EddooleymurphyNo ratings yet
- TextDocument102 pagesTextSAYANI MANNANo ratings yet
- Cs8080 Ir Unit2 I Modeling and Retrieval EvaluationDocument42 pagesCs8080 Ir Unit2 I Modeling and Retrieval EvaluationGnanasekaranNo ratings yet
- NLP-Neuro Linguistic Programming: What Is A Corpus?Document3 pagesNLP-Neuro Linguistic Programming: What Is A Corpus?yousef shabanNo ratings yet
- NLP Asgn2Document7 pagesNLP Asgn2[TE A-1] Chandan SinghNo ratings yet
- Text Mining: Fast Phrase-Based Text Indexing and Matching: Khaled Hammouda, Ph.D. StudentDocument12 pagesText Mining: Fast Phrase-Based Text Indexing and Matching: Khaled Hammouda, Ph.D. StudentPradeep KumarNo ratings yet
- Digital Libraries: Language TechnologiesDocument51 pagesDigital Libraries: Language TechnologiesAmit SwamiNo ratings yet
- Data Mining:: Concepts and TechniquesDocument37 pagesData Mining:: Concepts and TechniquessuriyachackNo ratings yet
- Course 7 Terminological Activity I Term RecordDocument38 pagesCourse 7 Terminological Activity I Term RecordAlexandra Ene0% (1)
- NLP Mod-V Q - A (Uploaded by Snaptricks - In)Document7 pagesNLP Mod-V Q - A (Uploaded by Snaptricks - In)sharan rajNo ratings yet
- Tf-Idf: David Kauchak cs160 Fall 2009Document51 pagesTf-Idf: David Kauchak cs160 Fall 2009Vishal YadavNo ratings yet
- Widc TfidfDocument20 pagesWidc Tfidfnyoman sNo ratings yet
- Conceptual Clustering of Text ClustersDocument9 pagesConceptual Clustering of Text ClustersheboboNo ratings yet
- Term Frequency and Inverse Document FrequencyDocument26 pagesTerm Frequency and Inverse Document Frequencylalitha sriNo ratings yet
- Text ClassificationDocument32 pagesText ClassificationSamNeil70No ratings yet
- IR Unit 2Document54 pagesIR Unit 2jaganbecsNo ratings yet
- Chapter Two: Text OperationsDocument41 pagesChapter Two: Text Operationsendris yimerNo ratings yet
- Unit 1Document4 pagesUnit 1Shiv MNo ratings yet
- A New Approach To Represent Textual Documents Using CVSMDocument6 pagesA New Approach To Represent Textual Documents Using CVSMParimalla SubhashNo ratings yet
- A Method For Visualising Possible ContextsDocument8 pagesA Method For Visualising Possible ContextsshigekiNo ratings yet
- Multimedia Information Retrieval (CSC 545) : The Problem of IRDocument29 pagesMultimedia Information Retrieval (CSC 545) : The Problem of IRAre ZelanNo ratings yet
- Anti-Serendipity: Finding Useless Documents and Similar DocumentsDocument9 pagesAnti-Serendipity: Finding Useless Documents and Similar DocumentsfeysalnurNo ratings yet
- Improve Text Classification Accuracy Based On Classifier Fusion MethodsDocument6 pagesImprove Text Classification Accuracy Based On Classifier Fusion Methodsdanesh110No ratings yet
- Perfectionof Classification Accuracy in Text CategorizationDocument5 pagesPerfectionof Classification Accuracy in Text CategorizationIJAR JOURNALNo ratings yet
- Wordnet Improves Text Document Clustering: Andreas Hotho Steffen Staab Gerd StummeDocument8 pagesWordnet Improves Text Document Clustering: Andreas Hotho Steffen Staab Gerd StummeriverguardianNo ratings yet
- 2 Text OperationsDocument32 pages2 Text Operationshalal.army07No ratings yet
- Keyword 2Document5 pagesKeyword 2202002025.jayeshsvmNo ratings yet
- Minor Project Ii Report Text Mining: Reuters-21578: Submitted byDocument51 pagesMinor Project Ii Report Text Mining: Reuters-21578: Submitted bysabihuddin100% (1)
- Dicle 2018Document8 pagesDicle 2018Love EnvironmentNo ratings yet
- Course Name: Advanced Information RetrievalDocument6 pagesCourse Name: Advanced Information RetrievaljewarNo ratings yet
- Text AnalyticsDocument32 pagesText AnalyticsMahesh RamalingamNo ratings yet
- WINSEM2022-23 - CSI3005 - ETH - VL2022230503219 - ReferenceMaterialI - FriFeb1700 00 00IST2023 - TextandDocumentVisualizationDocument20 pagesWINSEM2022-23 - CSI3005 - ETH - VL2022230503219 - ReferenceMaterialI - FriFeb1700 00 00IST2023 - TextandDocumentVisualizationM Ramani DeviNo ratings yet
- Data Science Interview Preparation Questions (#Day06)Document10 pagesData Science Interview Preparation Questions (#Day06)ThànhĐạt NgôNo ratings yet
- Masters Thesis Examples HistoryDocument6 pagesMasters Thesis Examples Historyamandaburkettbridgeport100% (2)
- Chapter 4: Query Languages: Baeza-Yates, 1999 Modern Information RetrievalDocument29 pagesChapter 4: Query Languages: Baeza-Yates, 1999 Modern Information RetrievalTamizharasi ANo ratings yet
- Chapter 4: Query Languages: Baeza-Yates, 1999 Modern Information RetrievalDocument29 pagesChapter 4: Query Languages: Baeza-Yates, 1999 Modern Information RetrievalFarid AzhariNo ratings yet
- Irt-23 Unit 2Document10 pagesIrt-23 Unit 2karthin.roy115No ratings yet
- NLP An Intuitive Understanding of Word Embeddings From Count Vectors To Word2VecDocument18 pagesNLP An Intuitive Understanding of Word Embeddings From Count Vectors To Word2VecpayNo ratings yet
- Baader Et Al, 2005, DLs As Ontology Languages For The Semantic WebDocument21 pagesBaader Et Al, 2005, DLs As Ontology Languages For The Semantic Web43535097No ratings yet
- Turk Bootstrap Word Sense Inventory 2.0: A Large-Scale Resource For Lexical SubstitutionDocument5 pagesTurk Bootstrap Word Sense Inventory 2.0: A Large-Scale Resource For Lexical SubstitutionacouillaultNo ratings yet
- NLP IrDocument24 pagesNLP IrpawebiarxdxdNo ratings yet
- Text Pre Processing With NLTKDocument42 pagesText Pre Processing With NLTKMohsin Ali KhattakNo ratings yet
- A Comparative Study of TF IDF LSIDocument8 pagesA Comparative Study of TF IDF LSIRichard ValdiviaNo ratings yet
- Latent Semantic AnalysisDocument36 pagesLatent Semantic AnalysisRea ReaNo ratings yet
- WordcloudDocument10 pagesWordcloudASGNo ratings yet
- Made By:-Bhawana Agarwal Cs IiiyrDocument29 pagesMade By:-Bhawana Agarwal Cs IiiyrBhawana AgarwalNo ratings yet
- Chapter #4: Query LanguagesDocument16 pagesChapter #4: Query LanguagesMaxamed Cabdi garawNo ratings yet
- NLP m3Document111 pagesNLP m3priyankap1624153No ratings yet
- 2 - Text OperationDocument43 pages2 - Text OperationHailemariam SetegnNo ratings yet
- Thesis Sahib - Order Now OnDocument11 pagesThesis Sahib - Order Now Onrredknlpd100% (1)
- T5-Digital ThesauriDocument4 pagesT5-Digital Thesauri100524484No ratings yet
- Ontology AagamDocument3 pagesOntology Aagamusefordownload999No ratings yet
- Modern Information Retrieval Chapter 7: Text Operations: Ricardo Baeza-Yates Berthier Ribeiro-NetoDocument40 pagesModern Information Retrieval Chapter 7: Text Operations: Ricardo Baeza-Yates Berthier Ribeiro-Netoapi-20013624No ratings yet
- Text MiningDocument12 pagesText Miningساره عبد المجيد المراكبى عبد المجيد احمد UnknownNo ratings yet
- 2 CapabilityDocument20 pages2 CapabilitysudhaNo ratings yet
- Vector Space ModelDocument11 pagesVector Space ModeljeysamNo ratings yet
- Anti-Serendipity: Finding Useless Documents and Similar DocumentsDocument9 pagesAnti-Serendipity: Finding Useless Documents and Similar DocumentsPreeti BansalNo ratings yet
- Lecture 2 - Word EmeddingDocument45 pagesLecture 2 - Word EmeddingAndrew ChungNo ratings yet
- Text MiningDocument27 pagesText MiningAchyuth PentakotaNo ratings yet
- Tei HeaderDocument14 pagesTei HeaderaymynetNo ratings yet
- Troublesome Verb Pairs 8Document3 pagesTroublesome Verb Pairs 8OscarTadlockNo ratings yet
- Unit 4 Progress Test A: GrammarDocument5 pagesUnit 4 Progress Test A: GrammarAvenueNo ratings yet
- Nishitha RESUMEDocument3 pagesNishitha RESUMEStigan IndiaNo ratings yet
- Accelerate 2E Unit 7 INT - Consumerism - Teacher - S Notes - Edited 17.02.20Document10 pagesAccelerate 2E Unit 7 INT - Consumerism - Teacher - S Notes - Edited 17.02.20Trevor AndersonNo ratings yet
- Letter WritingDocument46 pagesLetter WritingAditya Pratap SinghNo ratings yet
- 02MakeTheGrade2 Unit1 TestLevel2Document2 pages02MakeTheGrade2 Unit1 TestLevel2Carlos Gomez GarciaNo ratings yet
- Graduation ProjectDocument8 pagesGraduation ProjectMunther asadNo ratings yet
- Ravana Kaviyam PDFDocument402 pagesRavana Kaviyam PDFAdmirable Anto100% (1)
- Geteway B2+ - Unit 1 and 2 - Vocabulary Test Preparation - Ready For The Road Flashcards - QuizletDocument8 pagesGeteway B2+ - Unit 1 and 2 - Vocabulary Test Preparation - Ready For The Road Flashcards - QuizletSara ŠantićNo ratings yet
- Week 13Document2 pagesWeek 13Sri AzuraNo ratings yet
- Good Morning/afternoon Class, How Are You Today?: University of Rizal System College of EducationDocument2 pagesGood Morning/afternoon Class, How Are You Today?: University of Rizal System College of EducationVan DuranNo ratings yet
- Quiz Comparatives and SuperlativesDocument1 pageQuiz Comparatives and SuperlativesMaryferNo ratings yet
- Respect For EldersDocument15 pagesRespect For EldersCastillo Gene Andrew M.No ratings yet
- Material Used in Class - Writing 1Document5 pagesMaterial Used in Class - Writing 1janegrsNo ratings yet
- III A. Preliminaries (This Part Will Contain The Springboard, Motivation or Other Activities That May Introduce / Begin The Lesson)Document6 pagesIII A. Preliminaries (This Part Will Contain The Springboard, Motivation or Other Activities That May Introduce / Begin The Lesson)Yanyan EducNo ratings yet
- Elt 3 Lesson 1Document8 pagesElt 3 Lesson 1Joysaveth Rama VillaverNo ratings yet
- English 6 - AdjectivesDocument47 pagesEnglish 6 - AdjectivesKit LigueNo ratings yet
- Active Vs Passive Textbook ReadersDocument1 pageActive Vs Passive Textbook ReadersHannah LINo ratings yet
- Inglés Temario 2024Document4 pagesInglés Temario 2024Yoselin GuerreroNo ratings yet
- MÃ ĐỀ 037Document3 pagesMÃ ĐỀ 037Đặng Thu TrangNo ratings yet
- Elt Curriculum: Oral Approach, Audio LingualDocument26 pagesElt Curriculum: Oral Approach, Audio LingualAdies NuariNo ratings yet
- Legal Profession by AquinoDocument4 pagesLegal Profession by AquinoTeddyboy AgnisebNo ratings yet
- Tiếng Anh 6Document8 pagesTiếng Anh 6tkhanhmy.eduNo ratings yet
- PneumonoultramicroscopicsilicovolcanoconiosisDocument1 pagePneumonoultramicroscopicsilicovolcanoconiosisdaria popescuNo ratings yet
- الدراما والمسرح التربوي كمدخل علاجي لصعوبات التعلمDocument18 pagesالدراما والمسرح التربوي كمدخل علاجي لصعوبات التعلمDILA ART'SNo ratings yet
- Review in The Celebration of Buwan NG WikaDocument2 pagesReview in The Celebration of Buwan NG WikaRachelRamosNo ratings yet
- Racine 2018 Lexi Cal MethodDocument9 pagesRacine 2018 Lexi Cal MethodGustavo RegesNo ratings yet
- Unit 8 - Lesson 6 - Skills - 2Document5 pagesUnit 8 - Lesson 6 - Skills - 2Anh VuNo ratings yet
- 1 Complete The Sentences With ShouldDocument6 pages1 Complete The Sentences With Shouldjulia merlo vegaNo ratings yet
























































































Download as pdf or txt
You might also like
- Attardo Raskin 1991 Script Theory Revis (It) EdDocument56 pagesAttardo Raskin 1991 Script Theory Revis (It) EddooleymurphyNo ratings yet
- TextDocument102 pagesTextSAYANI MANNANo ratings yet
- Cs8080 Ir Unit2 I Modeling and Retrieval EvaluationDocument42 pagesCs8080 Ir Unit2 I Modeling and Retrieval EvaluationGnanasekaranNo ratings yet
- NLP-Neuro Linguistic Programming: What Is A Corpus?Document3 pagesNLP-Neuro Linguistic Programming: What Is A Corpus?yousef shabanNo ratings yet
- NLP Asgn2Document7 pagesNLP Asgn2[TE A-1] Chandan SinghNo ratings yet
- Text Mining: Fast Phrase-Based Text Indexing and Matching: Khaled Hammouda, Ph.D. StudentDocument12 pagesText Mining: Fast Phrase-Based Text Indexing and Matching: Khaled Hammouda, Ph.D. StudentPradeep KumarNo ratings yet
- Digital Libraries: Language TechnologiesDocument51 pagesDigital Libraries: Language TechnologiesAmit SwamiNo ratings yet
- Data Mining:: Concepts and TechniquesDocument37 pagesData Mining:: Concepts and TechniquessuriyachackNo ratings yet
- Course 7 Terminological Activity I Term RecordDocument38 pagesCourse 7 Terminological Activity I Term RecordAlexandra Ene0% (1)
- NLP Mod-V Q - A (Uploaded by Snaptricks - In)Document7 pagesNLP Mod-V Q - A (Uploaded by Snaptricks - In)sharan rajNo ratings yet
- Tf-Idf: David Kauchak cs160 Fall 2009Document51 pagesTf-Idf: David Kauchak cs160 Fall 2009Vishal YadavNo ratings yet
- Widc TfidfDocument20 pagesWidc Tfidfnyoman sNo ratings yet
- Conceptual Clustering of Text ClustersDocument9 pagesConceptual Clustering of Text ClustersheboboNo ratings yet
- Term Frequency and Inverse Document FrequencyDocument26 pagesTerm Frequency and Inverse Document Frequencylalitha sriNo ratings yet
- Text ClassificationDocument32 pagesText ClassificationSamNeil70No ratings yet
- IR Unit 2Document54 pagesIR Unit 2jaganbecsNo ratings yet
- Chapter Two: Text OperationsDocument41 pagesChapter Two: Text Operationsendris yimerNo ratings yet
- Unit 1Document4 pagesUnit 1Shiv MNo ratings yet
- A New Approach To Represent Textual Documents Using CVSMDocument6 pagesA New Approach To Represent Textual Documents Using CVSMParimalla SubhashNo ratings yet
- A Method For Visualising Possible ContextsDocument8 pagesA Method For Visualising Possible ContextsshigekiNo ratings yet
- Multimedia Information Retrieval (CSC 545) : The Problem of IRDocument29 pagesMultimedia Information Retrieval (CSC 545) : The Problem of IRAre ZelanNo ratings yet
- Anti-Serendipity: Finding Useless Documents and Similar DocumentsDocument9 pagesAnti-Serendipity: Finding Useless Documents and Similar DocumentsfeysalnurNo ratings yet
- Improve Text Classification Accuracy Based On Classifier Fusion MethodsDocument6 pagesImprove Text Classification Accuracy Based On Classifier Fusion Methodsdanesh110No ratings yet
- Perfectionof Classification Accuracy in Text CategorizationDocument5 pagesPerfectionof Classification Accuracy in Text CategorizationIJAR JOURNALNo ratings yet
- Wordnet Improves Text Document Clustering: Andreas Hotho Steffen Staab Gerd StummeDocument8 pagesWordnet Improves Text Document Clustering: Andreas Hotho Steffen Staab Gerd StummeriverguardianNo ratings yet
- 2 Text OperationsDocument32 pages2 Text Operationshalal.army07No ratings yet
- Keyword 2Document5 pagesKeyword 2202002025.jayeshsvmNo ratings yet
- Minor Project Ii Report Text Mining: Reuters-21578: Submitted byDocument51 pagesMinor Project Ii Report Text Mining: Reuters-21578: Submitted bysabihuddin100% (1)
- Dicle 2018Document8 pagesDicle 2018Love EnvironmentNo ratings yet
- Course Name: Advanced Information RetrievalDocument6 pagesCourse Name: Advanced Information RetrievaljewarNo ratings yet
- Text AnalyticsDocument32 pagesText AnalyticsMahesh RamalingamNo ratings yet
- WINSEM2022-23 - CSI3005 - ETH - VL2022230503219 - ReferenceMaterialI - FriFeb1700 00 00IST2023 - TextandDocumentVisualizationDocument20 pagesWINSEM2022-23 - CSI3005 - ETH - VL2022230503219 - ReferenceMaterialI - FriFeb1700 00 00IST2023 - TextandDocumentVisualizationM Ramani DeviNo ratings yet
- Data Science Interview Preparation Questions (#Day06)Document10 pagesData Science Interview Preparation Questions (#Day06)ThànhĐạt NgôNo ratings yet
- Masters Thesis Examples HistoryDocument6 pagesMasters Thesis Examples Historyamandaburkettbridgeport100% (2)
- Chapter 4: Query Languages: Baeza-Yates, 1999 Modern Information RetrievalDocument29 pagesChapter 4: Query Languages: Baeza-Yates, 1999 Modern Information RetrievalTamizharasi ANo ratings yet
- Chapter 4: Query Languages: Baeza-Yates, 1999 Modern Information RetrievalDocument29 pagesChapter 4: Query Languages: Baeza-Yates, 1999 Modern Information RetrievalFarid AzhariNo ratings yet
- Irt-23 Unit 2Document10 pagesIrt-23 Unit 2karthin.roy115No ratings yet
- NLP An Intuitive Understanding of Word Embeddings From Count Vectors To Word2VecDocument18 pagesNLP An Intuitive Understanding of Word Embeddings From Count Vectors To Word2VecpayNo ratings yet
- Baader Et Al, 2005, DLs As Ontology Languages For The Semantic WebDocument21 pagesBaader Et Al, 2005, DLs As Ontology Languages For The Semantic Web43535097No ratings yet
- Turk Bootstrap Word Sense Inventory 2.0: A Large-Scale Resource For Lexical SubstitutionDocument5 pagesTurk Bootstrap Word Sense Inventory 2.0: A Large-Scale Resource For Lexical SubstitutionacouillaultNo ratings yet
- NLP IrDocument24 pagesNLP IrpawebiarxdxdNo ratings yet
- Text Pre Processing With NLTKDocument42 pagesText Pre Processing With NLTKMohsin Ali KhattakNo ratings yet
- A Comparative Study of TF IDF LSIDocument8 pagesA Comparative Study of TF IDF LSIRichard ValdiviaNo ratings yet
- Latent Semantic AnalysisDocument36 pagesLatent Semantic AnalysisRea ReaNo ratings yet
- WordcloudDocument10 pagesWordcloudASGNo ratings yet
- Made By:-Bhawana Agarwal Cs IiiyrDocument29 pagesMade By:-Bhawana Agarwal Cs IiiyrBhawana AgarwalNo ratings yet
- Chapter #4: Query LanguagesDocument16 pagesChapter #4: Query LanguagesMaxamed Cabdi garawNo ratings yet
- NLP m3Document111 pagesNLP m3priyankap1624153No ratings yet
- 2 - Text OperationDocument43 pages2 - Text OperationHailemariam SetegnNo ratings yet
- Thesis Sahib - Order Now OnDocument11 pagesThesis Sahib - Order Now Onrredknlpd100% (1)
- T5-Digital ThesauriDocument4 pagesT5-Digital Thesauri100524484No ratings yet
- Ontology AagamDocument3 pagesOntology Aagamusefordownload999No ratings yet
- Modern Information Retrieval Chapter 7: Text Operations: Ricardo Baeza-Yates Berthier Ribeiro-NetoDocument40 pagesModern Information Retrieval Chapter 7: Text Operations: Ricardo Baeza-Yates Berthier Ribeiro-Netoapi-20013624No ratings yet
- Text MiningDocument12 pagesText Miningساره عبد المجيد المراكبى عبد المجيد احمد UnknownNo ratings yet
- 2 CapabilityDocument20 pages2 CapabilitysudhaNo ratings yet
- Vector Space ModelDocument11 pagesVector Space ModeljeysamNo ratings yet
- Anti-Serendipity: Finding Useless Documents and Similar DocumentsDocument9 pagesAnti-Serendipity: Finding Useless Documents and Similar DocumentsPreeti BansalNo ratings yet
- Lecture 2 - Word EmeddingDocument45 pagesLecture 2 - Word EmeddingAndrew ChungNo ratings yet
- Text MiningDocument27 pagesText MiningAchyuth PentakotaNo ratings yet
- Tei HeaderDocument14 pagesTei HeaderaymynetNo ratings yet
- Troublesome Verb Pairs 8Document3 pagesTroublesome Verb Pairs 8OscarTadlockNo ratings yet
- Unit 4 Progress Test A: GrammarDocument5 pagesUnit 4 Progress Test A: GrammarAvenueNo ratings yet
- Nishitha RESUMEDocument3 pagesNishitha RESUMEStigan IndiaNo ratings yet
- Accelerate 2E Unit 7 INT - Consumerism - Teacher - S Notes - Edited 17.02.20Document10 pagesAccelerate 2E Unit 7 INT - Consumerism - Teacher - S Notes - Edited 17.02.20Trevor AndersonNo ratings yet
- Letter WritingDocument46 pagesLetter WritingAditya Pratap SinghNo ratings yet
- 02MakeTheGrade2 Unit1 TestLevel2Document2 pages02MakeTheGrade2 Unit1 TestLevel2Carlos Gomez GarciaNo ratings yet
- Graduation ProjectDocument8 pagesGraduation ProjectMunther asadNo ratings yet
- Ravana Kaviyam PDFDocument402 pagesRavana Kaviyam PDFAdmirable Anto100% (1)
- Geteway B2+ - Unit 1 and 2 - Vocabulary Test Preparation - Ready For The Road Flashcards - QuizletDocument8 pagesGeteway B2+ - Unit 1 and 2 - Vocabulary Test Preparation - Ready For The Road Flashcards - QuizletSara ŠantićNo ratings yet
- Week 13Document2 pagesWeek 13Sri AzuraNo ratings yet
- Good Morning/afternoon Class, How Are You Today?: University of Rizal System College of EducationDocument2 pagesGood Morning/afternoon Class, How Are You Today?: University of Rizal System College of EducationVan DuranNo ratings yet
- Quiz Comparatives and SuperlativesDocument1 pageQuiz Comparatives and SuperlativesMaryferNo ratings yet
- Respect For EldersDocument15 pagesRespect For EldersCastillo Gene Andrew M.No ratings yet
- Material Used in Class - Writing 1Document5 pagesMaterial Used in Class - Writing 1janegrsNo ratings yet
- III A. Preliminaries (This Part Will Contain The Springboard, Motivation or Other Activities That May Introduce / Begin The Lesson)Document6 pagesIII A. Preliminaries (This Part Will Contain The Springboard, Motivation or Other Activities That May Introduce / Begin The Lesson)Yanyan EducNo ratings yet
- Elt 3 Lesson 1Document8 pagesElt 3 Lesson 1Joysaveth Rama VillaverNo ratings yet
- English 6 - AdjectivesDocument47 pagesEnglish 6 - AdjectivesKit LigueNo ratings yet
- Active Vs Passive Textbook ReadersDocument1 pageActive Vs Passive Textbook ReadersHannah LINo ratings yet
- Inglés Temario 2024Document4 pagesInglés Temario 2024Yoselin GuerreroNo ratings yet
- MÃ ĐỀ 037Document3 pagesMÃ ĐỀ 037Đặng Thu TrangNo ratings yet
- Elt Curriculum: Oral Approach, Audio LingualDocument26 pagesElt Curriculum: Oral Approach, Audio LingualAdies NuariNo ratings yet
- Legal Profession by AquinoDocument4 pagesLegal Profession by AquinoTeddyboy AgnisebNo ratings yet
- Tiếng Anh 6Document8 pagesTiếng Anh 6tkhanhmy.eduNo ratings yet
- PneumonoultramicroscopicsilicovolcanoconiosisDocument1 pagePneumonoultramicroscopicsilicovolcanoconiosisdaria popescuNo ratings yet
- الدراما والمسرح التربوي كمدخل علاجي لصعوبات التعلمDocument18 pagesالدراما والمسرح التربوي كمدخل علاجي لصعوبات التعلمDILA ART'SNo ratings yet
- Review in The Celebration of Buwan NG WikaDocument2 pagesReview in The Celebration of Buwan NG WikaRachelRamosNo ratings yet
- Racine 2018 Lexi Cal MethodDocument9 pagesRacine 2018 Lexi Cal MethodGustavo RegesNo ratings yet
- Unit 8 - Lesson 6 - Skills - 2Document5 pagesUnit 8 - Lesson 6 - Skills - 2Anh VuNo ratings yet
- 1 Complete The Sentences With ShouldDocument6 pages1 Complete The Sentences With Shouldjulia merlo vegaNo ratings yet