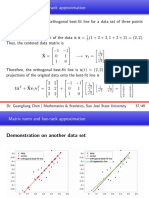
Download as pdf or txt
You might also like
- Chinese Tonic Herbs PDFDocument160 pagesChinese Tonic Herbs PDFbernteoNo ratings yet
- CH 6. Arbitration and Conciliation MCQDocument6 pagesCH 6. Arbitration and Conciliation MCQAbhishek50% (2)
- Indian Diet Plan For DiabetesDocument5 pagesIndian Diet Plan For DiabetesRanjan Sarmah0% (1)
- Principal Component Analysis (PCA) : Learning Representations. Dimensionality ReductionDocument22 pagesPrincipal Component Analysis (PCA) : Learning Representations. Dimensionality Reductionbilal qaisNo ratings yet
- KPCADocument26 pagesKPCAParmida AfsharNo ratings yet
- Part BDocument36 pagesPart BAngieNo ratings yet
- Fast Support Vector Classifier With Quantile: School of Mathematical Sciences, Inner Mongolia University, ChinaDocument7 pagesFast Support Vector Classifier With Quantile: School of Mathematical Sciences, Inner Mongolia University, ChinaJagan J Jagan JNo ratings yet
- Logistic RegressionDocument11 pagesLogistic RegressionSayan GhosalNo ratings yet
- 8-1-0-CSP EegDocument83 pages8-1-0-CSP Eegs96281No ratings yet
- Dimensionality Reduction: Jayanta Mukhopadhyay Dept. of Computer Science and EnggDocument41 pagesDimensionality Reduction: Jayanta Mukhopadhyay Dept. of Computer Science and EnggUtkarsh PatelNo ratings yet
- Model Building ThroughDocument21 pagesModel Building ThroughbotiwaNo ratings yet
- Pca IcaDocument34 pagesPca Icasachin121083No ratings yet
- Integration On QuadrilateralsDocument12 pagesIntegration On QuadrilateralsjygeorgeNo ratings yet
- Lec7matrixnorm Part4Document13 pagesLec7matrixnorm Part4Somnath DasNo ratings yet
- Ahmed Rebai PCA-ICADocument34 pagesAhmed Rebai PCA-ICAOtman ChakkorNo ratings yet
- PCA (v3)Document34 pagesPCA (v3)daredevilchoNo ratings yet
- Lecture14 PcaDocument63 pagesLecture14 PcaAbhishekNo ratings yet
- Lec 4 RQDocument32 pagesLec 4 RQRudra Shankha NandyNo ratings yet
- Nuclear Reactor AnalysisDocument30 pagesNuclear Reactor AnalysisSandamali SanchalaNo ratings yet
- Kmeans PCADocument9 pagesKmeans PCAAmitava MannaNo ratings yet
- 15 Aos1423Document37 pages15 Aos1423sherlockholmes108No ratings yet
- Pca SlidesDocument33 pagesPca Slidesforscribd1981No ratings yet
- Neural Network Learning Dynamics Analysis: Articles You May Be Interested inDocument5 pagesNeural Network Learning Dynamics Analysis: Articles You May Be Interested inerick ramosNo ratings yet
- State Estimation in A Decentralized Discrete Time LQG Control For A Multisensor SystemDocument11 pagesState Estimation in A Decentralized Discrete Time LQG Control For A Multisensor SystemIbrahim Ishaq KishimiNo ratings yet
- DS NN 03 RNNDocument259 pagesDS NN 03 RNNAllice BoneteNo ratings yet
- Principal Components Analysis (Chapter 2 MDRD) : Overview of PCADocument13 pagesPrincipal Components Analysis (Chapter 2 MDRD) : Overview of PCAMiie MirzahNo ratings yet
- Numerical Algebra, Control and Optimization Volume 1, Number 1, March 2011Document20 pagesNumerical Algebra, Control and Optimization Volume 1, Number 1, March 2011Costica PetreNo ratings yet
- Principal Component Analysis - A TutorialDocument37 pagesPrincipal Component Analysis - A TutorialchonjinhuiNo ratings yet
- Studying Some Approaches To Estimate The Smoothing Parameter For The Nonparametric Regression ModelDocument11 pagesStudying Some Approaches To Estimate The Smoothing Parameter For The Nonparametric Regression ModelÚt NhỏNo ratings yet
- Independent Components AnalysisDocument26 pagesIndependent Components AnalysisPhuc HoangNo ratings yet
- On The Eigenvalue of $P (X) $-Laplace Equation: ArticleDocument37 pagesOn The Eigenvalue of $P (X) $-Laplace Equation: ArticleVasi UtaNo ratings yet
- Neural Network Implementation in JavaDocument12 pagesNeural Network Implementation in JavaRam SarsihaNo ratings yet
- Iv. Single Layer Structures: 4.1. PerceptronsDocument26 pagesIv. Single Layer Structures: 4.1. PerceptronsYunus KoçNo ratings yet
- Gemp Et Al. - 2020 - EigenGame PCA As A Nash EquilibriumDocument11 pagesGemp Et Al. - 2020 - EigenGame PCA As A Nash EquilibriumclearlyInvisibleNo ratings yet
- Appendix: 12.1 Inventory of DistributionsDocument6 pagesAppendix: 12.1 Inventory of DistributionsAhmed Kadem ArabNo ratings yet
- Simple PerceptronsDocument28 pagesSimple PerceptronsRishabhNo ratings yet
- Face Recognition From Video Using Robust Kernel Resistor-Average DistanceDocument24 pagesFace Recognition From Video Using Robust Kernel Resistor-Average DistanceSidharth PandaNo ratings yet
- A New Branch and Bound Algorithm For Integer Quadratic Programming-2016Document12 pagesA New Branch and Bound Algorithm For Integer Quadratic Programming-2016Shah AzNo ratings yet
- Deep Neural Network GaussianDocument29 pagesDeep Neural Network GaussianxofpwualcygbvrucsNo ratings yet
- Tharrault - DPS - 2007 Fault Detection and Isolation With Robust Principal PCADocument9 pagesTharrault - DPS - 2007 Fault Detection and Isolation With Robust Principal PCAriadh toumiNo ratings yet
- 08 - Chapter - 05Document33 pages08 - Chapter - 05Mustafa khanNo ratings yet
- 1 s2.0 S0950705124000613 MainDocument16 pages1 s2.0 S0950705124000613 MainZhang WeiNo ratings yet
- MachinelearninghghghgDocument17 pagesMachinelearninghghghgMaRsHallNo ratings yet
- C1-Vectors and Fields-St - 1.2Document12 pagesC1-Vectors and Fields-St - 1.2Lâm VănNo ratings yet
- Non-Parametric Power Spectrum Estimation MethodsDocument25 pagesNon-Parametric Power Spectrum Estimation MethodsstartechNo ratings yet
- Duality Estimation Control GoodwinDocument10 pagesDuality Estimation Control GoodwinArthur CostaNo ratings yet
- Deep Neural Networks IIDDocument36 pagesDeep Neural Networks IIDxofpwualcygbvrucsNo ratings yet
- Gkab255 Supplemental FileDocument29 pagesGkab255 Supplemental FileSharanappa ANo ratings yet
- Curve Fitting Update1Document48 pagesCurve Fitting Update1khadarswggyNo ratings yet
- Deep Learning Meets Sparse Regularization: A Signal Processing PerspectiveDocument23 pagesDeep Learning Meets Sparse Regularization: A Signal Processing PerspectiveJuan ZarateNo ratings yet
- NeurIPS 2020 Belief Propagation Neural Networks PaperDocument12 pagesNeurIPS 2020 Belief Propagation Neural Networks PaperNatasa PerovicNo ratings yet
- Pca PDFDocument33 pagesPca PDFAparajito SenguptaNo ratings yet
- Echo State Network - ScholarpediaDocument4 pagesEcho State Network - Scholarpediainkheart2349No ratings yet
- The Fast Convergence of Incremental PCADocument17 pagesThe Fast Convergence of Incremental PCAQuarktopNo ratings yet
- Perceptons Neural NetworksDocument33 pagesPerceptons Neural Networksvasu_koneti5124No ratings yet
- An Analytical Study On The Synchronization of The Varient of MLC CircuitDocument15 pagesAn Analytical Study On The Synchronization of The Varient of MLC CircuitImran MohamedNo ratings yet
- Hafiz Arslan Khalid: Roll No. Department: Subject: Assignment # 3: Submitted To: Date SubmissionDocument8 pagesHafiz Arslan Khalid: Roll No. Department: Subject: Assignment # 3: Submitted To: Date SubmissionArslan RajaNo ratings yet
- MANE 4240 & CIVL 4240 Introduction To Finite Elements: Shape Functions in 1DDocument29 pagesMANE 4240 & CIVL 4240 Introduction To Finite Elements: Shape Functions in 1DPrayag ParekhNo ratings yet
- Instruction Manual: PH412: General Physics Laboratory IDocument27 pagesInstruction Manual: PH412: General Physics Laboratory IDhananjay KapseNo ratings yet
- Almost Everywhere Strong Summability of Fejer MeanDocument20 pagesAlmost Everywhere Strong Summability of Fejer Meangovindaraju annamalaiNo ratings yet
- Application of Derivatives Tangents and Normals (Calculus) Mathematics E-Book For Public ExamsFrom EverandApplication of Derivatives Tangents and Normals (Calculus) Mathematics E-Book For Public ExamsRating: 5 out of 5 stars5/5 (1)
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Strategic Management (Case Study) PDFDocument5 pagesStrategic Management (Case Study) PDFDineshNo ratings yet
- Republic Vs LedesmaDocument2 pagesRepublic Vs LedesmaestvanguardiaNo ratings yet
- Leadership SkillsDocument8 pagesLeadership SkillsJeyarajasekar TtrNo ratings yet
- Numbers 10 To 100 ESL Vocabulary Interactive Board GameDocument6 pagesNumbers 10 To 100 ESL Vocabulary Interactive Board GameStefanía Molano Ch.No ratings yet
- Basic Electrical Circuits DR Nagendra Krishnapura Department of Electrical Engineering Indian Institute of Technology Madras Lecture - 01Document2 pagesBasic Electrical Circuits DR Nagendra Krishnapura Department of Electrical Engineering Indian Institute of Technology Madras Lecture - 01Ranjeet Singh BishtNo ratings yet
- Berroco CassiaDocument4 pagesBerroco CassiaDiana Font ThomasNo ratings yet
- Factfulness Book Review #2: Taehoon KimDocument3 pagesFactfulness Book Review #2: Taehoon KimTaehoon KimNo ratings yet
- Article The Bible On Marriage and FamilyDocument6 pagesArticle The Bible On Marriage and FamilyKarl D EscobarNo ratings yet
- 7 Meaning - Sri StutiDocument24 pages7 Meaning - Sri StutiLeela KNo ratings yet
- WLA Weeks 7-8 Term 3 2012Document2 pagesWLA Weeks 7-8 Term 3 2012butcher_katherine_jNo ratings yet
- Deploying Oracle Database On Oracle Compute Cloud Service InstanceDocument30 pagesDeploying Oracle Database On Oracle Compute Cloud Service Instanceambipac@yahoo.comNo ratings yet
- So You Want To Play Mahjong 1.5Document26 pagesSo You Want To Play Mahjong 1.5tate2927No ratings yet
- Gastrointestinal BleedingDocument17 pagesGastrointestinal BleedingMaría José GalvisNo ratings yet
- Christmas VacationDocument8 pagesChristmas VacationNatália SzabóNo ratings yet
- Finer - 2015 - Russian ModernismDocument18 pagesFiner - 2015 - Russian ModernismJosué Durán HNo ratings yet
- Great Compline Service BookDocument20 pagesGreat Compline Service BookMarguerite Paizis100% (2)
- P3. Farmakoterapi Penyakit Gangguan EndokrinDocument84 pagesP3. Farmakoterapi Penyakit Gangguan EndokrinRidzal Ade PutraNo ratings yet
- Veto Bargaining Presidents and The PolitDocument26 pagesVeto Bargaining Presidents and The PolitWaqas BukhariNo ratings yet
- Solution Science-X T 2 POW reducesupportMaterialSolution To Science-IX T2 POW Solutions PDFDocument138 pagesSolution Science-X T 2 POW reducesupportMaterialSolution To Science-IX T2 POW Solutions PDFSumeet AroraNo ratings yet
- Seismic Design - 2000Document62 pagesSeismic Design - 2000Riza SuwondoNo ratings yet
- Topic 5 - Teaching For Understanding - The Role of ICT and E-Learning (By Martha Stone Wiske)Document2 pagesTopic 5 - Teaching For Understanding - The Role of ICT and E-Learning (By Martha Stone Wiske)Hark Herald Cruz SarmientoNo ratings yet
- The ABCs of DR Desmond Ford S Theology W H JohnsDocument16 pagesThe ABCs of DR Desmond Ford S Theology W H JohnsBogdan PlaticaNo ratings yet
- A Critical Analysis of The Writings of Amos RapoportDocument11 pagesA Critical Analysis of The Writings of Amos RapoportmaxwalkerdreamNo ratings yet
- Sri Nisargadatta Maharaj: Created By: Pradeep ApteDocument30 pagesSri Nisargadatta Maharaj: Created By: Pradeep AptePradeep Apte100% (6)
- Coop Learning ActivitiesDocument198 pagesCoop Learning ActivitiesJanine Mosca GonzalesNo ratings yet
- Project Title: Koç University College of Engineering INDR 491 Engineering Design Project ProposalDocument5 pagesProject Title: Koç University College of Engineering INDR 491 Engineering Design Project ProposalPınar ErcanNo ratings yet
- Whirligig Design ChallengeDocument4 pagesWhirligig Design Challengeapi-450232271No ratings yet