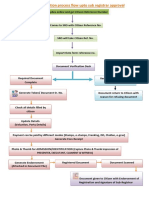
Download as pdf or txt
You might also like
- CMPG171: Study Unit 4Document44 pagesCMPG171: Study Unit 4Tshepo OscarNo ratings yet
- Program Design Pseudocode Use of Modules: Week #6Document36 pagesProgram Design Pseudocode Use of Modules: Week #6Congyao ZhengNo ratings yet
- Data MungingDocument65 pagesData Mungingba22samyukthaNo ratings yet
- Ds Module 1Document72 pagesDs Module 1Prathik SrinivasNo ratings yet
- DocumentationDocument24 pagesDocumentationDeva Hema DNo ratings yet
- Unit 4: ASIC Front-End Tools: October 2009Document15 pagesUnit 4: ASIC Front-End Tools: October 2009jesus barrionuevoNo ratings yet
- Packages in PythonDocument54 pagesPackages in Pythonshabazmohd196No ratings yet
- DS Tools Lec 01Document23 pagesDS Tools Lec 01Youmna EidNo ratings yet
- 1 OverviewDocument18 pages1 OverviewJeffrey YanNo ratings yet
- Literate Sta) S) Cal Programming With Knitr: Reproducible ResearchDocument38 pagesLiterate Sta) S) Cal Programming With Knitr: Reproducible ResearchARUSHI JAINNo ratings yet
- 6.architectural DesignDocument35 pages6.architectural Designأفنان النزيليNo ratings yet
- Lecture 4 - Self Study Part2Document26 pagesLecture 4 - Self Study Part2adiasaraf29No ratings yet
- 2 IntroPythonDocument22 pages2 IntroPythonTanvi sharmaNo ratings yet
- BES Guide Reproducible Code 2019Document44 pagesBES Guide Reproducible Code 2019Yuan WangNo ratings yet
- DataAnalytic-03 - Data Analytics ImplementationDocument37 pagesDataAnalytic-03 - Data Analytics ImplementationkadnanNo ratings yet
- Programming Logic and Design: Fourth Edition, IntroductoryDocument47 pagesProgramming Logic and Design: Fourth Edition, Introductoryl_piol2004No ratings yet
- Statistical PackagesDocument32 pagesStatistical PackagesPalaniappan SellappanNo ratings yet
- 2012 Workshop Introduction To ATLAS Ti Version 7Document31 pages2012 Workshop Introduction To ATLAS Ti Version 7marikum74No ratings yet
- Agile Frameworks - Part 1Document17 pagesAgile Frameworks - Part 1Vaibhav VermaNo ratings yet
- C/C++ Programming Techniques: ET2031 / ET2031EDocument44 pagesC/C++ Programming Techniques: ET2031 / ET2031EVăn Kiên DươngNo ratings yet
- Document Image AnalysisDocument6 pagesDocument Image AnalysisSitansu Sekhar MohantyNo ratings yet
- Lu1 - Lo 1 - 4Document47 pagesLu1 - Lo 1 - 4Queraysha JairajNo ratings yet
- 0-Ip Project NewDocument29 pages0-Ip Project Newkuwarkalra.10No ratings yet
- Programming For Data AnalysisDocument25 pagesProgramming For Data AnalysisSagar PaudelNo ratings yet
- Dr. JPSM PPT - PythonDocument50 pagesDr. JPSM PPT - Pythonmorenikhil2024No ratings yet
- 1 IntroDocument33 pages1 Introdieter.devlaminckNo ratings yet
- Enerplot: Offline Plotting and Analysis ToolDocument18 pagesEnerplot: Offline Plotting and Analysis TooldanNo ratings yet
- Murach C# Lecture 1 Slides BTM380 ProgrammingDocument36 pagesMurach C# Lecture 1 Slides BTM380 ProgrammingRosalie-Ann MasséNo ratings yet
- Programming Logic and Design: Fourth Edition, IntroductoryDocument40 pagesProgramming Logic and Design: Fourth Edition, Introductorymhil06No ratings yet
- Software Engineering PrinciplesDocument51 pagesSoftware Engineering PrinciplesShrijanand ChintapatlaNo ratings yet
- Test & Measurement Development Package: TestpointDocument4 pagesTest & Measurement Development Package: TestpointMoritery miraNo ratings yet
- CW Sequence AnalysisDocument9 pagesCW Sequence Analysisshk93359No ratings yet
- Project - Restaurant Rating Prediction: Problem StatementDocument3 pagesProject - Restaurant Rating Prediction: Problem StatementPreetam PaulNo ratings yet
- Chapetr 5Document23 pagesChapetr 5Mehari TemesgenNo ratings yet
- Software Effort EstimationDocument51 pagesSoftware Effort EstimationChetanNo ratings yet
- Final PrezDocument22 pagesFinal Prezapi-266877289No ratings yet
- CEA FPGA LabDocument4 pagesCEA FPGA LabIbrahim MehmoodNo ratings yet
- Repro ResearchDocument23 pagesRepro ResearchKelvin TingNo ratings yet
- Standard Cell and Memory Design Semester III (2010-2012) : Project Goals and DeliverablesDocument7 pagesStandard Cell and Memory Design Semester III (2010-2012) : Project Goals and DeliverablesprabhakiniNo ratings yet
- Programming For Data Analytics IntroductionDocument32 pagesProgramming For Data Analytics IntroductionAugustine Kwasi Tarkom100% (2)
- Lecture2 Introduction C LangugueDocument84 pagesLecture2 Introduction C LangugueĐức Anh CNo ratings yet
- MF 45 Handout STAMPA FinDocument84 pagesMF 45 Handout STAMPA FinCaterina MoroNo ratings yet
- It Tools For Research: Cphd4 Guided By: DR - P. ShashikalaDocument41 pagesIt Tools For Research: Cphd4 Guided By: DR - P. Shashikalaravisky1989No ratings yet
- Data Scientist Nanodegree Syllabus: Before You StartDocument5 pagesData Scientist Nanodegree Syllabus: Before You StartAditya the RetroNo ratings yet
- COMP36512 - Compilers Lecture 1: Introduction: - Module AimsDocument12 pagesCOMP36512 - Compilers Lecture 1: Introduction: - Module AimsashmhdNo ratings yet
- 2011 05 19 Design AssessmentDocument57 pages2011 05 19 Design AssessmentseansotoNo ratings yet
- Compiler Design PhaseDocument14 pagesCompiler Design PhasepoojaqNo ratings yet
- Introduction To CompilersDocument14 pagesIntroduction To CompilersshvdoNo ratings yet
- Building Design SystemsDocument70 pagesBuilding Design SystemsNurul Akbar Al-Ghifari 4No ratings yet
- SE - ImplementationDocument66 pagesSE - ImplementationAziz KhanNo ratings yet
- Bcse301l Se Module-3b SmsatapathyDocument166 pagesBcse301l Se Module-3b SmsatapathysukijaaNo ratings yet
- Programming Logic and Design: Fourth Edition, ComprehensiveDocument40 pagesProgramming Logic and Design: Fourth Edition, Comprehensivesaga54No ratings yet
- Data Analysis SystemDocument21 pagesData Analysis SystemAngga SukaryawanNo ratings yet
- Assignment 10 Fall PDFDocument1 pageAssignment 10 Fall PDFJoe DaneNo ratings yet
- Scripting ArcgisDocument27 pagesScripting ArcgisRavindhar BlackNo ratings yet
- rusers-2017-projecttemplateDocument21 pagesrusers-2017-projecttemplatelucashelalNo ratings yet
- Modelbuilder IntroductionDocument29 pagesModelbuilder IntroductionCésar Ávila AoyamaNo ratings yet
- l2 - Labview - Introduction - v22Document58 pagesl2 - Labview - Introduction - v22Pham Xuan ThuyNo ratings yet
- 1 - Ensuring Data QualityDocument26 pages1 - Ensuring Data QualityRafael MonteiroNo ratings yet
- 1 - Statistical Programming 101Document51 pages1 - Statistical Programming 101Rafael MonteiroNo ratings yet
- Book ReviewDocument5 pagesBook ReviewRafael MonteiroNo ratings yet
- Gender Conflict Climate Eastern AfricaDocument22 pagesGender Conflict Climate Eastern AfricaRafael MonteiroNo ratings yet
- Introduction To Geospatial Raster and Vector Data With R - Open and Plot Shapefiles in RDocument9 pagesIntroduction To Geospatial Raster and Vector Data With R - Open and Plot Shapefiles in RRafael MonteiroNo ratings yet
- Mapping Out-Of-School Adolescents and Youths in Low-And Middle-Income CountriesDocument10 pagesMapping Out-Of-School Adolescents and Youths in Low-And Middle-Income CountriesRafael MonteiroNo ratings yet
- Dhs Working PapersDocument43 pagesDhs Working PapersRafael MonteiroNo ratings yet
- Clustering of Census Recorded Ethnic BackgroundDocument40 pagesClustering of Census Recorded Ethnic BackgroundRafael MonteiroNo ratings yet
- Drawing Beautiful Maps Programmatically With R, SF and Ggplot2 - Part 1 - BasicsDocument28 pagesDrawing Beautiful Maps Programmatically With R, SF and Ggplot2 - Part 1 - BasicsRafael MonteiroNo ratings yet
- COVID-19: Embracing Digital Government During The Pandemic and BeyondDocument4 pagesCOVID-19: Embracing Digital Government During The Pandemic and BeyondRafael MonteiroNo ratings yet
- bp2004 4 PDFDocument24 pagesbp2004 4 PDFRafael MonteiroNo ratings yet
- Good Governance For Sustainable Development: Munich Personal Repec ArchiveDocument10 pagesGood Governance For Sustainable Development: Munich Personal Repec ArchiveRafael MonteiroNo ratings yet
- Optiswitch 900 Series - : Service DemarcationDocument4 pagesOptiswitch 900 Series - : Service DemarcationAmiNo ratings yet
- DriverDocument1 pageDriverKhanh Le Dinh100% (1)
- Deepthi NairDocument17 pagesDeepthi Nairrmsh301No ratings yet
- Department of Computer Science & Engineering: Bbdnitm LucknowDocument6 pagesDepartment of Computer Science & Engineering: Bbdnitm Lucknowneha ShuklaNo ratings yet
- Model Based Design of Pid Controller For BLDC Motor With Implementation ofDocument8 pagesModel Based Design of Pid Controller For BLDC Motor With Implementation ofBrasoveanu GheorghitaNo ratings yet
- Telnet Technical ModemDocument2 pagesTelnet Technical ModemHà MậpNo ratings yet
- User Manual: Smart Alarm System & AppDocument41 pagesUser Manual: Smart Alarm System & AppEduardo Jose Fernandez PedrozaNo ratings yet
- Numerical Structural Analysis - O'Hara, Steven (SRG) PDFDocument302 pagesNumerical Structural Analysis - O'Hara, Steven (SRG) PDFggsarne100% (7)
- Parameters v5.00 Fdu VFX - enDocument468 pagesParameters v5.00 Fdu VFX - enpablo caceresNo ratings yet
- Xbee Based Remote Monitoring of 3 Parameters On Transformer Generator HealthDocument11 pagesXbee Based Remote Monitoring of 3 Parameters On Transformer Generator HealthCrispNo ratings yet
- Baseband Training 2018-7-22Document39 pagesBaseband Training 2018-7-22hassanNo ratings yet
- Chap08 Moving Average Control Charts 2Document23 pagesChap08 Moving Average Control Charts 2john brownNo ratings yet
- Capture Photo & Thumb Impression of Presenter, Executant, Claiment & WitnessDocument11 pagesCapture Photo & Thumb Impression of Presenter, Executant, Claiment & Witnesskeshav bajajNo ratings yet
- Basics of LabViewDocument30 pagesBasics of LabViewnomimanNo ratings yet
- Kalloo 2011Document18 pagesKalloo 2011Nhóm 10 tin họcNo ratings yet
- PracDescription PDFDocument6 pagesPracDescription PDFVincent Liu100% (1)
- AKX00022 WebDocument3 pagesAKX00022 WebShaik Arif BashaNo ratings yet
- dcm580 12 Fin Eng PDFDocument2 pagesdcm580 12 Fin Eng PDFboxyyy2No ratings yet
- ICT-CSS12 Q1 Mod1 PerformingComputerOperations Version1Document53 pagesICT-CSS12 Q1 Mod1 PerformingComputerOperations Version1Rainier DoctoleroNo ratings yet
- Edited Gfi Seminar ReportDocument18 pagesEdited Gfi Seminar Reportkerya ibrahimNo ratings yet
- Cough Assist Service Guide PDFDocument114 pagesCough Assist Service Guide PDFsec.ivbNo ratings yet
- Parametric LPDocument13 pagesParametric LPSou TibonNo ratings yet
- 2 en 1309Document70 pages2 en 1309Miguel Angel PérezNo ratings yet
- EDU CAT EN ASM FF V5-6R2015 ToprintDocument301 pagesEDU CAT EN ASM FF V5-6R2015 ToprintBosse BoseNo ratings yet
- Automated Teller MachineDocument21 pagesAutomated Teller MachineAhmed SharifNo ratings yet
- RHEL6Document203 pagesRHEL6Naman ArusiaNo ratings yet
- Chapter 4-Bipolar Junction Transistor (BJT)Document31 pagesChapter 4-Bipolar Junction Transistor (BJT)Peter YekNo ratings yet
- Fireeye Email Security Server Edition: Data SheetDocument7 pagesFireeye Email Security Server Edition: Data SheetNADERNo ratings yet
- TAMBAHAN SPJ COVID NovDocument33 pagesTAMBAHAN SPJ COVID NovCinthya RahayuNo ratings yet
- The Tropos Software Development Methodology: Processes, Models and DiagramsDocument11 pagesThe Tropos Software Development Methodology: Processes, Models and Diagramsyossef. kassayNo ratings yet