Download as pdf or txt
You might also like
- Data Structures & Algorithms Interview Questions You'll Most Likely Be AskedFrom EverandData Structures & Algorithms Interview Questions You'll Most Likely Be AskedRating: 1 out of 5 stars1/5 (1)
- Data Structure ClassificationDocument16 pagesData Structure Classificationrajneeshsingh018No ratings yet
- Data Structure and Algorithms: Similar Types of Data Stored at Contiguous Memory LocationsDocument5 pagesData Structure and Algorithms: Similar Types of Data Stored at Contiguous Memory LocationsMayur RaulNo ratings yet
- DS UNIT-3 NotesDocument34 pagesDS UNIT-3 Notesedla srijaNo ratings yet
- DS Unit IDocument27 pagesDS Unit IBharghavtejaNo ratings yet
- Data Structure Note - 2Document8 pagesData Structure Note - 2ejioforjo01No ratings yet
- Ralated Terms of DBMSDocument19 pagesRalated Terms of DBMSDr. Hitesh MohapatraNo ratings yet
- DSL Pract (Oral) QuestionDocument14 pagesDSL Pract (Oral) QuestionSanchit KharadeNo ratings yet
- Dsa Viva QuestionsDocument13 pagesDsa Viva QuestionsAashu ThakurNo ratings yet
- Imp - Data-Structures QuestionsDocument16 pagesImp - Data-Structures QuestionsBLACK xDEMONNo ratings yet
- DsMahiwaya PDFDocument21 pagesDsMahiwaya PDFMahiwaymaNo ratings yet
- Book Computer Setting CH 1Document14 pagesBook Computer Setting CH 1Gautham SajuNo ratings yet
- Mobile Computimg and Information Super Highway 2023 Y3 s2 Nswadi William George COURSEWORKDocument8 pagesMobile Computimg and Information Super Highway 2023 Y3 s2 Nswadi William George COURSEWORKNSWADI WILLIAMNo ratings yet
- Unit - IDocument41 pagesUnit - IchinnikngNo ratings yet
- Data Structure AssignmentDocument7 pagesData Structure AssignmentNedved RichNo ratings yet
- Introducution To Data Structure and AlgorithmDocument24 pagesIntroducution To Data Structure and AlgorithmFaithman EkponneNo ratings yet
- Data Structure CSE2050 Assignment-2: Submitted To-Mr. Munish Kumar MittalDocument7 pagesData Structure CSE2050 Assignment-2: Submitted To-Mr. Munish Kumar MittalGaurav SharmaNo ratings yet
- Data Structures With Java Unit - 1Document22 pagesData Structures With Java Unit - 1kishore kumarNo ratings yet
- Linked List - NoteDocument10 pagesLinked List - Notesayanpal854No ratings yet
- DS NotesDocument21 pagesDS Notesvijayalaxmib93No ratings yet
- Data Structure 1 UnitDocument17 pagesData Structure 1 Unitvijayalaxmib93No ratings yet
- DS Sem 2 Case Study PDFDocument10 pagesDS Sem 2 Case Study PDFchaituNo ratings yet
- What Is Data StructureDocument6 pagesWhat Is Data StructurePrishita KapoorNo ratings yet
- Linked ListDocument13 pagesLinked ListChirag JainNo ratings yet
- Link List-2Document6 pagesLink List-2Kashif RiazNo ratings yet
- Data StructureDocument31 pagesData StructureRaseena HaneefNo ratings yet
- Data Structures - Lecture - 2Document94 pagesData Structures - Lecture - 2tantos557No ratings yet
- What Is Data StructureDocument49 pagesWhat Is Data Structureh4nj68z8xxNo ratings yet
- ADSADocument14 pagesADSAkanteti.srisandhyaNo ratings yet
- DS Unit-IDocument53 pagesDS Unit-InikhithakomanapalliNo ratings yet
- CSC Assignment 123Document7 pagesCSC Assignment 123Bashjr01No ratings yet
- Data Structures 2Document82 pagesData Structures 2Kamran RaziNo ratings yet
- Linked ListDocument11 pagesLinked ListGosh KreativityNo ratings yet
- Application of NonDocument17 pagesApplication of Non1106 Sumit SharmaNo ratings yet
- Data Structure Algorithums AssignmentDocument14 pagesData Structure Algorithums AssignmentwhatstubesNo ratings yet
- DWHDocument5 pagesDWHchaitanya paruvadaNo ratings yet
- What Is Data Structure?Document10 pagesWhat Is Data Structure?AřJűn DashNo ratings yet
- Units Topics Introduction To Data Structures and AlgorithmsDocument82 pagesUnits Topics Introduction To Data Structures and AlgorithmsDipen TamangNo ratings yet
- Unit 1 (Dsa)Document51 pagesUnit 1 (Dsa)aditi duttaNo ratings yet
- DSL Practical Oral QueAnsDocument10 pagesDSL Practical Oral QueAnsAnkit BhujbalNo ratings yet
- Q1. Data Structures and Types of With Is Chart?Document87 pagesQ1. Data Structures and Types of With Is Chart?Abhay SharmaNo ratings yet
- Data Structure QuestionsDocument23 pagesData Structure Questionssamswag2898No ratings yet
- BCA 403 (File & Data Structure)Document94 pagesBCA 403 (File & Data Structure)neerukumari1100% (1)
- DS Q BankDocument43 pagesDS Q BankMoxit ParmarNo ratings yet
- Data Structure and Its TypesDocument9 pagesData Structure and Its TypesVanAravinthanNo ratings yet
- Ds Viva QDocument13 pagesDs Viva Qhackers earthNo ratings yet
- Data Structure1Document8 pagesData Structure1SelvaKrishnanNo ratings yet
- Prelims 5Document7 pagesPrelims 5Akshata ChopadeNo ratings yet
- Data Structure and Algorithm Lec 1Document19 pagesData Structure and Algorithm Lec 1Kunza HammadNo ratings yet
- TCS QuestionsDocument5 pagesTCS QuestionsFann KannNo ratings yet
- Data Structure Assignment AAMIR MUHAMMAD JUNAIDDocument6 pagesData Structure Assignment AAMIR MUHAMMAD JUNAIDaamirmjunaidNo ratings yet
- ADBMS QuestionnaireDocument30 pagesADBMS QuestionnaireguestmodeplmNo ratings yet
- Data TypeDocument14 pagesData TypeRohan RahalkarNo ratings yet
- FDS Unit 1Document14 pagesFDS Unit 1Priyanka DhanwateNo ratings yet
- Data Strucuture NotesDocument14 pagesData Strucuture NotesMohammed Rizwan MalikNo ratings yet
- Lec 15 NotesDocument3 pagesLec 15 NotesRitikNo ratings yet
- Unit 1: Introduction To Data Structures & RecursionDocument36 pagesUnit 1: Introduction To Data Structures & RecursionEsha MukherjeeNo ratings yet
- C-3 (Dsa)Document11 pagesC-3 (Dsa)carryminati238No ratings yet
- Data Structures - SCSA1203: Unit - IDocument27 pagesData Structures - SCSA1203: Unit - IDinesh SheelamNo ratings yet
- Introduction To Data StructureDocument205 pagesIntroduction To Data Structurehim1234567890No ratings yet
- Serv LetDocument107 pagesServ Letadv Rajat SharmaNo ratings yet
- CH 15Document1 pageCH 15adv Rajat SharmaNo ratings yet
- TREEDocument27 pagesTREEadv Rajat SharmaNo ratings yet
- B.techDSA PaperDocument2 pagesB.techDSA Paperadv Rajat SharmaNo ratings yet
- Jbase-Internationalization PDFDocument55 pagesJbase-Internationalization PDFCrayolo HernandezNo ratings yet
- Grade 11 ICT (S) AnswerDocument2 pagesGrade 11 ICT (S) AnswerHasantha ChamuNo ratings yet
- SQL Interview QuestionsDocument2 pagesSQL Interview QuestionscourpediaNo ratings yet
- Python Data Types Unit IDocument8 pagesPython Data Types Unit IVASANTHI.V Dept Of MCANo ratings yet
- Handling Messages Greater Than 4 MB LongDocument11 pagesHandling Messages Greater Than 4 MB LongmuraliarepuNo ratings yet
- Assembling Computer: Presented By: Group 4 Reporters: Carlos Jade L. Pelina Mycel Patingo Nicholas Andrei SangcoDocument48 pagesAssembling Computer: Presented By: Group 4 Reporters: Carlos Jade L. Pelina Mycel Patingo Nicholas Andrei SangcoCeejaay PelinaNo ratings yet
- Data Extract SVGDocument3 pagesData Extract SVGAxl AxlNo ratings yet
- Faking Bluetooth LE PDFDocument20 pagesFaking Bluetooth LE PDFslysoft.20009951No ratings yet
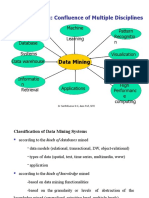
- 4-Confluence of Multiple Disciplines, Classifictaion, Integration-08-Feb-2021Material I 08-Feb-2021 Mod1 Confluence ClassifictaionDocument4 pages4-Confluence of Multiple Disciplines, Classifictaion, Integration-08-Feb-2021Material I 08-Feb-2021 Mod1 Confluence ClassifictaionLikith MallipeddiNo ratings yet
- Compiler Design and ConstructionDocument14 pagesCompiler Design and ConstructionmadhurocksktmNo ratings yet
- Data Sheet 6Es7414-2Xg03-0Ab0: Cir - Configuration in RunDocument9 pagesData Sheet 6Es7414-2Xg03-0Ab0: Cir - Configuration in RunDiego Alejandro Gallardo IbarraNo ratings yet
- Multitenant Best Practices - AiougDocument44 pagesMultitenant Best Practices - AiougMd Sikandar AlamNo ratings yet
- Fundamental Programming Structures in JavaDocument23 pagesFundamental Programming Structures in JavaVinayKumarSinghNo ratings yet
- Install UpdatesDocument10 pagesInstall UpdatesPreethi GopalanNo ratings yet
- PCA 6143man PDFDocument102 pagesPCA 6143man PDFLuis Alberto Díaz OlmedoNo ratings yet
- Expert - VMAX All Flash and VMAX3 Solutions 2.0: Certification DescriptionDocument4 pagesExpert - VMAX All Flash and VMAX3 Solutions 2.0: Certification DescriptionuthramNo ratings yet
- Teradata BasicsDocument141 pagesTeradata BasicsMohan AdariNo ratings yet
- Amazon S3 Essentials - Sample ChapterDocument13 pagesAmazon S3 Essentials - Sample ChapterPackt PublishingNo ratings yet
- Eastron Modbus RegistersDocument22 pagesEastron Modbus RegistersdiegoacunarNo ratings yet
- Manual Informix 10Document193 pagesManual Informix 10marcelorferrariNo ratings yet
- MySQl VulnerabilitiesDocument13 pagesMySQl VulnerabilitiesLias JassiNo ratings yet
- David PlotkinDocument41 pagesDavid PlotkinArk GroupNo ratings yet
- XMLDocument67 pagesXMLAnirudh PandeyNo ratings yet
- Java Network ProgrammingDocument21 pagesJava Network Programminghj43usNo ratings yet
- PCM PDH and SDHDocument58 pagesPCM PDH and SDHAkram Ba-odhanNo ratings yet
- Nmap + Nessus Cheat Sheet: Different Usage OptionsDocument1 pageNmap + Nessus Cheat Sheet: Different Usage OptionspanmihNo ratings yet
- Hitachi Storage Operation GuideDocument61 pagesHitachi Storage Operation GuidechologinNo ratings yet
- Cucm B Upgrade-Guide-1251su2 Chapter 01100-TasksDocument18 pagesCucm B Upgrade-Guide-1251su2 Chapter 01100-TasksFlavio AlonsoNo ratings yet
- QC PM485 Modbus Registers - Rev2Document1 pageQC PM485 Modbus Registers - Rev2Paolo BaldracchiNo ratings yet
- Part 2Document19 pagesPart 2Bharat RathodNo ratings yet