
NI LabVIEW For CompactRIO Developer's Guide-30-58
NI LabVIEW For CompactRIO Developer's Guide-30-58
You might also like
- Construction CompaniesDocument24 pagesConstruction Companiesmanup1980100% (1)
- Review of Measuring Methods and Results in Nonviscous Gas-Liquid Mass Transfer in Stirred VesselsDocument8 pagesReview of Measuring Methods and Results in Nonviscous Gas-Liquid Mass Transfer in Stirred VesselsAntonela PortaNo ratings yet
- RTS Ptu Sample Paper Lords MBDDocument48 pagesRTS Ptu Sample Paper Lords MBDKaveesh NykNo ratings yet
- Silk PerformerDocument33 pagesSilk PerformerGeetha Sravanthi100% (1)
- Accounting and Finance For ManagersDocument322 pagesAccounting and Finance For ManagersPrasanna Aravindan100% (5)
- BY Arun Kumar D: 1MV06MCA07Document18 pagesBY Arun Kumar D: 1MV06MCA07crazyladduNo ratings yet
- Labview: Real-Time Operating System (RTOS)Document2 pagesLabview: Real-Time Operating System (RTOS)norhaposadaNo ratings yet
- ES II AssignmentDocument10 pagesES II AssignmentRahul MandaogadeNo ratings yet
- Real Time Operating SystemDocument5 pagesReal Time Operating SystemChethan JayasimhaNo ratings yet
- Chapter-7 Designed Methodologies and Tools: Design Flow: Sequence of Steps in A Design MethodologyDocument16 pagesChapter-7 Designed Methodologies and Tools: Design Flow: Sequence of Steps in A Design MethodologyElias YeshanawNo ratings yet
- Simple Multitasking With MicrocontrollersDocument4 pagesSimple Multitasking With MicrocontrollersEngr Muhammad Irfan ShahidNo ratings yet
- Teamcity Whitepaper Cloud CostDocument20 pagesTeamcity Whitepaper Cloud Costalta intrebareNo ratings yet
- Advanced Embedded System Design: Project ReportDocument7 pagesAdvanced Embedded System Design: Project ReportSyed Akhlaq100% (1)
- Functional Verification ChallengesDocument9 pagesFunctional Verification ChallengesnikolicnemanjaNo ratings yet
- Pertemuan OS - Id.enDocument11 pagesPertemuan OS - Id.enBayu FerdinandNo ratings yet
- What Is A RealDocument4 pagesWhat Is A RealRajat RishiNo ratings yet
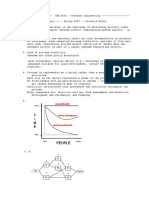
- T I M E: PeopleDocument4 pagesT I M E: PeopleMg ChanNo ratings yet
- What Is A RealDocument6 pagesWhat Is A RealnagarajNo ratings yet
- Dietrich Beck and Holger Brand, DVEE, GSI 1Document1 pageDietrich Beck and Holger Brand, DVEE, GSI 1itrialNo ratings yet
- Review PaperDocument9 pagesReview Paperhowida nafaaNo ratings yet
- PrefacioDocument7 pagesPrefacioFausto IguagoNo ratings yet
- Benchmarking Single-Point Performance On National Instruments Real-Time HardwareDocument8 pagesBenchmarking Single-Point Performance On National Instruments Real-Time HardwaremafmonteNo ratings yet
- Debugging Embedded Systems 09Document5 pagesDebugging Embedded Systems 09Sharmila DeviNo ratings yet
- Comparison of Scheduling Algorithms in Chimera and VxWorksDocument10 pagesComparison of Scheduling Algorithms in Chimera and VxWorkskhera89No ratings yet
- NI Tutorial 3062 enDocument4 pagesNI Tutorial 3062 enkmNo ratings yet
- Consistent Timing Constraints With Primetime: Steve GolsonDocument31 pagesConsistent Timing Constraints With Primetime: Steve GolsonRajesh SirinomulaNo ratings yet
- FYS 4220/9220 - 2012 / #3 Real Time and Embedded Data Systems and ComputingDocument25 pagesFYS 4220/9220 - 2012 / #3 Real Time and Embedded Data Systems and ComputingsansureNo ratings yet
- RTOSDocument6 pagesRTOSAkanksha SinghNo ratings yet
- Tut 3938Document4 pagesTut 3938vinod kapateNo ratings yet
- Design Patterns - Embedded Software Design - A Practical Approach To Architecture, Processes, and Coding TechniquesDocument30 pagesDesign Patterns - Embedded Software Design - A Practical Approach To Architecture, Processes, and Coding TechniquesamiteshanandNo ratings yet
- RTOSDocument6 pagesRTOS47 Bhushan BariNo ratings yet
- System Verilog TutorialDocument44 pagesSystem Verilog TutorialVishwa Shanika100% (1)
- ED01-1011-71380142 - Enterprise ComputingDocument14 pagesED01-1011-71380142 - Enterprise ComputingM. Saad IqbalNo ratings yet
- Labview Templates and Sample ProjectsDocument2 pagesLabview Templates and Sample ProjectsMichael JoNo ratings yet
- MSC Exam For Feature Use: Non-Preemptive and Preemptive Scheduling AlgorithmDocument6 pagesMSC Exam For Feature Use: Non-Preemptive and Preemptive Scheduling AlgorithmAddisu DessalegnNo ratings yet
- Mc0071 - Software Engineering SET-1 4. What About The Programming For Reliability?Document8 pagesMc0071 - Software Engineering SET-1 4. What About The Programming For Reliability?9937116687No ratings yet
- Mc0071-Software Engineering Test 4.what About The Programming For Reliability?Document4 pagesMc0071-Software Engineering Test 4.what About The Programming For Reliability?9937116687No ratings yet
- When Do I Need RT SystemDocument2 pagesWhen Do I Need RT SystemgutsjetNo ratings yet
- Tech Note 671 - Optimizing IO Performance in System PlatformDocument13 pagesTech Note 671 - Optimizing IO Performance in System PlatformsimbamikeNo ratings yet
- Kalinsky - Context SwitchDocument12 pagesKalinsky - Context SwitchRodrigo CedrimNo ratings yet
- Embedded Lab StudyDocument11 pagesEmbedded Lab Study23MZ05 - THARANI SNo ratings yet
- SystemVerilog Assertions Handbook, 4th Edition - Functional Covergae PagesDocument5 pagesSystemVerilog Assertions Handbook, 4th Edition - Functional Covergae PagesSam HoneyNo ratings yet
- Exam NotesDocument27 pagesExam NotesAbdighaniMOGoudNo ratings yet
- Cloud MaterialDocument15 pagesCloud Materialalwinhilton58No ratings yet
- Seven Deadly Sins of Slow Software Builds: Usman Muzaffar, VP Product Management - 5.2010Document12 pagesSeven Deadly Sins of Slow Software Builds: Usman Muzaffar, VP Product Management - 5.2010peterbacsiNo ratings yet
- INTERNAL ASSIGNMENT of Operating SystemDocument14 pagesINTERNAL ASSIGNMENT of Operating SystemDhananjay ChauhanNo ratings yet
- MatterDocument47 pagesMatterDevanand T SanthaNo ratings yet
- Real-Time Systems Interview Questions and Answers: Q1: What Do You Mean by A Real-Time System?Document4 pagesReal-Time Systems Interview Questions and Answers: Q1: What Do You Mean by A Real-Time System?ರಾಕೇಶ್ ಕೆ ವಿಶ್ವಕರ್ಮNo ratings yet
- Scheduling Virtual Machines For Load Balancing in Cloud Computing PlatformDocument5 pagesScheduling Virtual Machines For Load Balancing in Cloud Computing PlatformSupreeth SuhasNo ratings yet
- MSC Exam For Feature Use: Non-Preemptive and Preemptive Scheduling AlgorithmDocument6 pagesMSC Exam For Feature Use: Non-Preemptive and Preemptive Scheduling AlgorithmLens NewNo ratings yet
- CS8491 Ca Unit 4Document32 pagesCS8491 Ca Unit 4Vasuki rameshNo ratings yet
- Building Low Latency Applications For Financial MarketsDocument9 pagesBuilding Low Latency Applications For Financial MarketsTraderCat SolarisNo ratings yet
- DVCon Europe 2015 TA1 5 PaperDocument7 pagesDVCon Europe 2015 TA1 5 PaperJon DCNo ratings yet
- 5.3. Feasibility StudyDocument24 pages5.3. Feasibility StudyVipul GautamNo ratings yet
- Cycle 2Document61 pagesCycle 2asiya_ahNo ratings yet
- RTOSpaperDocument6 pagesRTOSpaperndkhoa82No ratings yet
- Unit IiDocument90 pagesUnit Iisk9271054No ratings yet
- When To Migrate Software Testing To The Cloud?: Tauhida Parveen Scott TilleyDocument4 pagesWhen To Migrate Software Testing To The Cloud?: Tauhida Parveen Scott TilleyMurali SankarNo ratings yet
- MICROCONTROLLERS AND MICROPROCESSORS SYSTEMS DESIGN - ChapterDocument12 pagesMICROCONTROLLERS AND MICROPROCESSORS SYSTEMS DESIGN - Chapteralice katenjeleNo ratings yet
- 7 Steps To Writing A Simple Cooperative Scheduler PDFDocument5 pages7 Steps To Writing A Simple Cooperative Scheduler PDFReid LindsayNo ratings yet
- RTS M-4 NotesDocument21 pagesRTS M-4 Notesmvs sowmyaNo ratings yet
- Programming The Application: First With Siemens: Organizing The Program in S7Document41 pagesProgramming The Application: First With Siemens: Organizing The Program in S7George GNo ratings yet
- Procesos Clase3 PDFDocument33 pagesProcesos Clase3 PDFMANFREED CARVAJAL PILLIMUENo ratings yet
- Procesos Clase2 PDFDocument54 pagesProcesos Clase2 PDFMANFREED CARVAJAL PILLIMUENo ratings yet
- Fract. FrágilDocument52 pagesFract. FrágilMANFREED CARVAJAL PILLIMUENo ratings yet
- Fractura Por FatigaDocument63 pagesFractura Por FatigaMANFREED CARVAJAL PILLIMUENo ratings yet
- Fract. DúctilDocument69 pagesFract. DúctilMANFREED CARVAJAL PILLIMUENo ratings yet
- Introducción - Desastres de IngenieríaDocument42 pagesIntroducción - Desastres de IngenieríaMANFREED CARVAJAL PILLIMUENo ratings yet
- Performance Analysis and Optimization of Centrifugal Fan"Document11 pagesPerformance Analysis and Optimization of Centrifugal Fan"MANFREED CARVAJAL PILLIMUENo ratings yet
- Debug Tacacs CiscoDocument5 pagesDebug Tacacs CiscodeztrocxeNo ratings yet
- Nail Care Lesson 2Document5 pagesNail Care Lesson 2Tin TinNo ratings yet
- Product Environmental Profile: Canalis KNA 40A To 160ADocument7 pagesProduct Environmental Profile: Canalis KNA 40A To 160AJavier LazoNo ratings yet
- Cloud Data Security: University College of Engineering, RTU, Kota (Rajasthan)Document26 pagesCloud Data Security: University College of Engineering, RTU, Kota (Rajasthan)arpita patidarNo ratings yet
- Properties of MaterialsDocument7 pagesProperties of MaterialsPunchGirl ChannelNo ratings yet
- TC-42X1 Part 1Document50 pagesTC-42X1 Part 1Pedro SandovalNo ratings yet
- Credit Note MH2202104 AA28787Document1 pageCredit Note MH2202104 AA28787Martin NadarNo ratings yet
- Game Sense ApproachDocument7 pagesGame Sense Approachapi-408626896No ratings yet
- Unlocking Efficient Ocean Freight With Cargomate LogisticsDocument13 pagesUnlocking Efficient Ocean Freight With Cargomate Logisticsbusinessowner2030No ratings yet
- Lacerte Jennifer ResumeDocument1 pageLacerte Jennifer Resumejennifer_lacerteNo ratings yet
- Thin Film Composite Reverse Osmosis MembranesDocument42 pagesThin Film Composite Reverse Osmosis MembranesGunay Tekkale100% (1)
- Experiment No. 2: Aim: A) D Flip-Flop: Synchronous VHDL CodeDocument6 pagesExperiment No. 2: Aim: A) D Flip-Flop: Synchronous VHDL CodeRahul MishraNo ratings yet
- Express Lifts Planning GuideDocument24 pagesExpress Lifts Planning GuideFERNSNo ratings yet
- Buddy SystemDocument7 pagesBuddy SystemJahangir SiddikiNo ratings yet
- CMA Pre Exam Test PDFDocument28 pagesCMA Pre Exam Test PDFVinay YerubandiNo ratings yet
- 12life Saving RulesDocument33 pages12life Saving RulesLakshmi Kanth P100% (1)
- MFI 2 - Unit 3 - SB - L+SDocument10 pagesMFI 2 - Unit 3 - SB - L+SHoan HoàngNo ratings yet
- Final Trust ListDocument19 pagesFinal Trust Listnamdev bkNo ratings yet
- Envisci Revised FloodingDocument5 pagesEnvisci Revised Floodingrjosephine529No ratings yet
- Basics of News WritingDocument31 pagesBasics of News WritingAngela Mae VillalunaNo ratings yet
- Ra 8294Document2 pagesRa 8294Rio TolentinoNo ratings yet
- HKB Industrial Boiler PlantsDocument12 pagesHKB Industrial Boiler PlantsIvan KorlevicNo ratings yet
- Police RRDocument17 pagesPolice RRindrajitdhadhal400No ratings yet
- C-18 Dme-I-SemDocument94 pagesC-18 Dme-I-SemBollu SatyanarayanaNo ratings yet
- SAP HANA StudioDocument33 pagesSAP HANA StudioPrateekVermaNo ratings yet
- A Court Case On Letters of Credit & UCP600Document2 pagesA Court Case On Letters of Credit & UCP600gmat1287No ratings yet
- Lab 1Document15 pagesLab 1Vic SeungNo ratings yet































































































Download as pdf or txt
You might also like
- Construction CompaniesDocument24 pagesConstruction Companiesmanup1980100% (1)
- Review of Measuring Methods and Results in Nonviscous Gas-Liquid Mass Transfer in Stirred VesselsDocument8 pagesReview of Measuring Methods and Results in Nonviscous Gas-Liquid Mass Transfer in Stirred VesselsAntonela PortaNo ratings yet
- RTS Ptu Sample Paper Lords MBDDocument48 pagesRTS Ptu Sample Paper Lords MBDKaveesh NykNo ratings yet
- Silk PerformerDocument33 pagesSilk PerformerGeetha Sravanthi100% (1)
- Accounting and Finance For ManagersDocument322 pagesAccounting and Finance For ManagersPrasanna Aravindan100% (5)
- BY Arun Kumar D: 1MV06MCA07Document18 pagesBY Arun Kumar D: 1MV06MCA07crazyladduNo ratings yet
- Labview: Real-Time Operating System (RTOS)Document2 pagesLabview: Real-Time Operating System (RTOS)norhaposadaNo ratings yet
- ES II AssignmentDocument10 pagesES II AssignmentRahul MandaogadeNo ratings yet
- Real Time Operating SystemDocument5 pagesReal Time Operating SystemChethan JayasimhaNo ratings yet
- Chapter-7 Designed Methodologies and Tools: Design Flow: Sequence of Steps in A Design MethodologyDocument16 pagesChapter-7 Designed Methodologies and Tools: Design Flow: Sequence of Steps in A Design MethodologyElias YeshanawNo ratings yet
- Simple Multitasking With MicrocontrollersDocument4 pagesSimple Multitasking With MicrocontrollersEngr Muhammad Irfan ShahidNo ratings yet
- Teamcity Whitepaper Cloud CostDocument20 pagesTeamcity Whitepaper Cloud Costalta intrebareNo ratings yet
- Advanced Embedded System Design: Project ReportDocument7 pagesAdvanced Embedded System Design: Project ReportSyed Akhlaq100% (1)
- Functional Verification ChallengesDocument9 pagesFunctional Verification ChallengesnikolicnemanjaNo ratings yet
- Pertemuan OS - Id.enDocument11 pagesPertemuan OS - Id.enBayu FerdinandNo ratings yet
- What Is A RealDocument4 pagesWhat Is A RealRajat RishiNo ratings yet
- T I M E: PeopleDocument4 pagesT I M E: PeopleMg ChanNo ratings yet
- What Is A RealDocument6 pagesWhat Is A RealnagarajNo ratings yet
- Dietrich Beck and Holger Brand, DVEE, GSI 1Document1 pageDietrich Beck and Holger Brand, DVEE, GSI 1itrialNo ratings yet
- Review PaperDocument9 pagesReview Paperhowida nafaaNo ratings yet
- PrefacioDocument7 pagesPrefacioFausto IguagoNo ratings yet
- Benchmarking Single-Point Performance On National Instruments Real-Time HardwareDocument8 pagesBenchmarking Single-Point Performance On National Instruments Real-Time HardwaremafmonteNo ratings yet
- Debugging Embedded Systems 09Document5 pagesDebugging Embedded Systems 09Sharmila DeviNo ratings yet
- Comparison of Scheduling Algorithms in Chimera and VxWorksDocument10 pagesComparison of Scheduling Algorithms in Chimera and VxWorkskhera89No ratings yet
- NI Tutorial 3062 enDocument4 pagesNI Tutorial 3062 enkmNo ratings yet
- Consistent Timing Constraints With Primetime: Steve GolsonDocument31 pagesConsistent Timing Constraints With Primetime: Steve GolsonRajesh SirinomulaNo ratings yet
- FYS 4220/9220 - 2012 / #3 Real Time and Embedded Data Systems and ComputingDocument25 pagesFYS 4220/9220 - 2012 / #3 Real Time and Embedded Data Systems and ComputingsansureNo ratings yet
- RTOSDocument6 pagesRTOSAkanksha SinghNo ratings yet
- Tut 3938Document4 pagesTut 3938vinod kapateNo ratings yet
- Design Patterns - Embedded Software Design - A Practical Approach To Architecture, Processes, and Coding TechniquesDocument30 pagesDesign Patterns - Embedded Software Design - A Practical Approach To Architecture, Processes, and Coding TechniquesamiteshanandNo ratings yet
- RTOSDocument6 pagesRTOS47 Bhushan BariNo ratings yet
- System Verilog TutorialDocument44 pagesSystem Verilog TutorialVishwa Shanika100% (1)
- ED01-1011-71380142 - Enterprise ComputingDocument14 pagesED01-1011-71380142 - Enterprise ComputingM. Saad IqbalNo ratings yet
- Labview Templates and Sample ProjectsDocument2 pagesLabview Templates and Sample ProjectsMichael JoNo ratings yet
- MSC Exam For Feature Use: Non-Preemptive and Preemptive Scheduling AlgorithmDocument6 pagesMSC Exam For Feature Use: Non-Preemptive and Preemptive Scheduling AlgorithmAddisu DessalegnNo ratings yet
- Mc0071 - Software Engineering SET-1 4. What About The Programming For Reliability?Document8 pagesMc0071 - Software Engineering SET-1 4. What About The Programming For Reliability?9937116687No ratings yet
- Mc0071-Software Engineering Test 4.what About The Programming For Reliability?Document4 pagesMc0071-Software Engineering Test 4.what About The Programming For Reliability?9937116687No ratings yet
- When Do I Need RT SystemDocument2 pagesWhen Do I Need RT SystemgutsjetNo ratings yet
- Tech Note 671 - Optimizing IO Performance in System PlatformDocument13 pagesTech Note 671 - Optimizing IO Performance in System PlatformsimbamikeNo ratings yet
- Kalinsky - Context SwitchDocument12 pagesKalinsky - Context SwitchRodrigo CedrimNo ratings yet
- Embedded Lab StudyDocument11 pagesEmbedded Lab Study23MZ05 - THARANI SNo ratings yet
- SystemVerilog Assertions Handbook, 4th Edition - Functional Covergae PagesDocument5 pagesSystemVerilog Assertions Handbook, 4th Edition - Functional Covergae PagesSam HoneyNo ratings yet
- Exam NotesDocument27 pagesExam NotesAbdighaniMOGoudNo ratings yet
- Cloud MaterialDocument15 pagesCloud Materialalwinhilton58No ratings yet
- Seven Deadly Sins of Slow Software Builds: Usman Muzaffar, VP Product Management - 5.2010Document12 pagesSeven Deadly Sins of Slow Software Builds: Usman Muzaffar, VP Product Management - 5.2010peterbacsiNo ratings yet
- INTERNAL ASSIGNMENT of Operating SystemDocument14 pagesINTERNAL ASSIGNMENT of Operating SystemDhananjay ChauhanNo ratings yet
- MatterDocument47 pagesMatterDevanand T SanthaNo ratings yet
- Real-Time Systems Interview Questions and Answers: Q1: What Do You Mean by A Real-Time System?Document4 pagesReal-Time Systems Interview Questions and Answers: Q1: What Do You Mean by A Real-Time System?ರಾಕೇಶ್ ಕೆ ವಿಶ್ವಕರ್ಮNo ratings yet
- Scheduling Virtual Machines For Load Balancing in Cloud Computing PlatformDocument5 pagesScheduling Virtual Machines For Load Balancing in Cloud Computing PlatformSupreeth SuhasNo ratings yet
- MSC Exam For Feature Use: Non-Preemptive and Preemptive Scheduling AlgorithmDocument6 pagesMSC Exam For Feature Use: Non-Preemptive and Preemptive Scheduling AlgorithmLens NewNo ratings yet
- CS8491 Ca Unit 4Document32 pagesCS8491 Ca Unit 4Vasuki rameshNo ratings yet
- Building Low Latency Applications For Financial MarketsDocument9 pagesBuilding Low Latency Applications For Financial MarketsTraderCat SolarisNo ratings yet
- DVCon Europe 2015 TA1 5 PaperDocument7 pagesDVCon Europe 2015 TA1 5 PaperJon DCNo ratings yet
- 5.3. Feasibility StudyDocument24 pages5.3. Feasibility StudyVipul GautamNo ratings yet
- Cycle 2Document61 pagesCycle 2asiya_ahNo ratings yet
- RTOSpaperDocument6 pagesRTOSpaperndkhoa82No ratings yet
- Unit IiDocument90 pagesUnit Iisk9271054No ratings yet
- When To Migrate Software Testing To The Cloud?: Tauhida Parveen Scott TilleyDocument4 pagesWhen To Migrate Software Testing To The Cloud?: Tauhida Parveen Scott TilleyMurali SankarNo ratings yet
- MICROCONTROLLERS AND MICROPROCESSORS SYSTEMS DESIGN - ChapterDocument12 pagesMICROCONTROLLERS AND MICROPROCESSORS SYSTEMS DESIGN - Chapteralice katenjeleNo ratings yet
- 7 Steps To Writing A Simple Cooperative Scheduler PDFDocument5 pages7 Steps To Writing A Simple Cooperative Scheduler PDFReid LindsayNo ratings yet
- RTS M-4 NotesDocument21 pagesRTS M-4 Notesmvs sowmyaNo ratings yet
- Programming The Application: First With Siemens: Organizing The Program in S7Document41 pagesProgramming The Application: First With Siemens: Organizing The Program in S7George GNo ratings yet
- Procesos Clase3 PDFDocument33 pagesProcesos Clase3 PDFMANFREED CARVAJAL PILLIMUENo ratings yet
- Procesos Clase2 PDFDocument54 pagesProcesos Clase2 PDFMANFREED CARVAJAL PILLIMUENo ratings yet
- Fract. FrágilDocument52 pagesFract. FrágilMANFREED CARVAJAL PILLIMUENo ratings yet
- Fractura Por FatigaDocument63 pagesFractura Por FatigaMANFREED CARVAJAL PILLIMUENo ratings yet
- Fract. DúctilDocument69 pagesFract. DúctilMANFREED CARVAJAL PILLIMUENo ratings yet
- Introducción - Desastres de IngenieríaDocument42 pagesIntroducción - Desastres de IngenieríaMANFREED CARVAJAL PILLIMUENo ratings yet
- Performance Analysis and Optimization of Centrifugal Fan"Document11 pagesPerformance Analysis and Optimization of Centrifugal Fan"MANFREED CARVAJAL PILLIMUENo ratings yet
- Debug Tacacs CiscoDocument5 pagesDebug Tacacs CiscodeztrocxeNo ratings yet
- Nail Care Lesson 2Document5 pagesNail Care Lesson 2Tin TinNo ratings yet
- Product Environmental Profile: Canalis KNA 40A To 160ADocument7 pagesProduct Environmental Profile: Canalis KNA 40A To 160AJavier LazoNo ratings yet
- Cloud Data Security: University College of Engineering, RTU, Kota (Rajasthan)Document26 pagesCloud Data Security: University College of Engineering, RTU, Kota (Rajasthan)arpita patidarNo ratings yet
- Properties of MaterialsDocument7 pagesProperties of MaterialsPunchGirl ChannelNo ratings yet
- TC-42X1 Part 1Document50 pagesTC-42X1 Part 1Pedro SandovalNo ratings yet
- Credit Note MH2202104 AA28787Document1 pageCredit Note MH2202104 AA28787Martin NadarNo ratings yet
- Game Sense ApproachDocument7 pagesGame Sense Approachapi-408626896No ratings yet
- Unlocking Efficient Ocean Freight With Cargomate LogisticsDocument13 pagesUnlocking Efficient Ocean Freight With Cargomate Logisticsbusinessowner2030No ratings yet
- Lacerte Jennifer ResumeDocument1 pageLacerte Jennifer Resumejennifer_lacerteNo ratings yet
- Thin Film Composite Reverse Osmosis MembranesDocument42 pagesThin Film Composite Reverse Osmosis MembranesGunay Tekkale100% (1)
- Experiment No. 2: Aim: A) D Flip-Flop: Synchronous VHDL CodeDocument6 pagesExperiment No. 2: Aim: A) D Flip-Flop: Synchronous VHDL CodeRahul MishraNo ratings yet
- Express Lifts Planning GuideDocument24 pagesExpress Lifts Planning GuideFERNSNo ratings yet
- Buddy SystemDocument7 pagesBuddy SystemJahangir SiddikiNo ratings yet
- CMA Pre Exam Test PDFDocument28 pagesCMA Pre Exam Test PDFVinay YerubandiNo ratings yet
- 12life Saving RulesDocument33 pages12life Saving RulesLakshmi Kanth P100% (1)
- MFI 2 - Unit 3 - SB - L+SDocument10 pagesMFI 2 - Unit 3 - SB - L+SHoan HoàngNo ratings yet
- Final Trust ListDocument19 pagesFinal Trust Listnamdev bkNo ratings yet
- Envisci Revised FloodingDocument5 pagesEnvisci Revised Floodingrjosephine529No ratings yet
- Basics of News WritingDocument31 pagesBasics of News WritingAngela Mae VillalunaNo ratings yet
- Ra 8294Document2 pagesRa 8294Rio TolentinoNo ratings yet
- HKB Industrial Boiler PlantsDocument12 pagesHKB Industrial Boiler PlantsIvan KorlevicNo ratings yet
- Police RRDocument17 pagesPolice RRindrajitdhadhal400No ratings yet
- C-18 Dme-I-SemDocument94 pagesC-18 Dme-I-SemBollu SatyanarayanaNo ratings yet
- SAP HANA StudioDocument33 pagesSAP HANA StudioPrateekVermaNo ratings yet
- A Court Case On Letters of Credit & UCP600Document2 pagesA Court Case On Letters of Credit & UCP600gmat1287No ratings yet
- Lab 1Document15 pagesLab 1Vic SeungNo ratings yet