
Chương 3
Chương 3
You might also like
- Cài đặt các gói và import thư việnDocument1 pageCài đặt các gói và import thư việntamphamvan33No ratings yet
- DIPFL23PRJG36Document18 pagesDIPFL23PRJG36quanga1k57hh1No ratings yet
- Final Project AIDocument12 pagesFinal Project AIHuy ĐặngNo ratings yet
- Báo-Cáo MachineLearningDocument18 pagesBáo-Cáo MachineLearningduyanhnguyen100802No ratings yet
- 231MI5206 Nhóm 8 AI ProjectDocument10 pages231MI5206 Nhóm 8 AI Projecttranhb22408No ratings yet
- Report AI Detect Flower BuiChiCuong 20146167Document25 pagesReport AI Detect Flower BuiChiCuong 2014616720146167No ratings yet
- Chương 6. Hướng Dẫn Thực Hành Nhận Diện Ảnh CNNDocument10 pagesChương 6. Hướng Dẫn Thực Hành Nhận Diện Ảnh CNNThiên Trang0% (1)
- Phân Lớp Nhị PhânDocument4 pagesPhân Lớp Nhị PhânÁnh Võ Thị HồngNo ratings yet
- AI NguyenVanQuoc-20146406Document13 pagesAI NguyenVanQuoc-20146406vvanquoc1402No ratings yet
- Nhóm 6Document15 pagesNhóm 6Bui Van Do100% (1)
- Xử lý ảnh và videoDocument12 pagesXử lý ảnh và videotuanlangla3No ratings yet
- BTL XlaDocument12 pagesBTL XlaĐặng Thị Vân AnhNo ratings yet
- Tư tưởng thuật toán nhận diện thủ ngữDocument3 pagesTư tưởng thuật toán nhận diện thủ ngữKhánh TânNo ratings yet
- Tìm hiểu thuật toán XgBoost cho phân loại mã độc AndroidDocument12 pagesTìm hiểu thuật toán XgBoost cho phân loại mã độc Androidsypgamingtv100% (1)
- TGMTDocument3 pagesTGMThoangdt.21ceNo ratings yet
- Xử lí ảnhDocument43 pagesXử lí ảnhtrongnghia03.workNo ratings yet
- Bai Thuc Hanh 2 (Updated)Document6 pagesBai Thuc Hanh 2 (Updated)Cơ Đinh VănNo ratings yet
- Bước 1: Đặt Mục Tiêu và Hiểu Rõ Vấn ĐềDocument3 pagesBước 1: Đặt Mục Tiêu và Hiểu Rõ Vấn Đềtrinhvanhaotv2007No ratings yet
- KHDL 2 OrangeDocument15 pagesKHDL 2 OrangeVương LamNo ratings yet
- Báo cáo CĐHTTT - Nhóm học phần 1 - Group 7Document18 pagesBáo cáo CĐHTTT - Nhóm học phần 1 - Group 7quanga1k57hh1No ratings yet
- M NG SDN XgboostDocument8 pagesM NG SDN Xgboostdvc.290603No ratings yet
- Machine Learning - NLP: Text Classification Sử Dụng Sklearn Python - Code Từ Đầu - Machine LearningDocument9 pagesMachine Learning - NLP: Text Classification Sử Dụng Sklearn Python - Code Từ Đầu - Machine Learningtnt007dataNo ratings yet
- (Machine Learning) Làm Thế Nào Để Đánh Giá Một Mô Hình Máy Học - AI CLUB TUTORIALSDocument15 pages(Machine Learning) Làm Thế Nào Để Đánh Giá Một Mô Hình Máy Học - AI CLUB TUTORIALSHải Đăng PhạmNo ratings yet
- Bao Cao de TaiDocument13 pagesBao Cao de TaiTrần Thị Thùy DươngNo ratings yet
- Decision TreeDocument5 pagesDecision TreeTrần Lê ThiệnNo ratings yet
- TriteunhantaoDocument25 pagesTriteunhantaoQuang HuyNo ratings yet
- Câu 22 Định nghĩa mạng neuron Định nghĩa perceptronDocument2 pagesCâu 22 Định nghĩa mạng neuron Định nghĩa perceptronHữu NhânNo ratings yet
- Phan Tich Du Doan - Machine LearningDocument65 pagesPhan Tich Du Doan - Machine Learningphuongffvip2No ratings yet
- Khai phá dữ liệuDocument20 pagesKhai phá dữ liệuNguyen LinhNo ratings yet
- Deep Learning Cho Bài Toán Nhận Diện Chữ ViếtDocument8 pagesDeep Learning Cho Bài Toán Nhận Diện Chữ Viếtlearnit learnitNo ratings yet
- LtudDocument6 pagesLtudNgoan NguyễnNo ratings yet
- IntSysDev - 03 - 17 - bt8 - Lê H, Oàng DũngDocument11 pagesIntSysDev - 03 - 17 - bt8 - Lê H, Oàng DũngLương Nhật TuấnNo ratings yet
- Phat Hien Ma Doc Bang Machine LearningDocument63 pagesPhat Hien Ma Doc Bang Machine LearningHana YukiNo ratings yet
- PowpointDocument29 pagesPowpointEDM NCSNo ratings yet
- DeepLearning NguyenXuanCongDocument8 pagesDeepLearning NguyenXuanCongcong100% (1)
- Simple Code Demo FunctionDocument67 pagesSimple Code Demo Functionquanghieu.inamedNo ratings yet
- Deep DreamDocument12 pagesDeep DreamĐăng KhoaNo ratings yet
- AutomotiveLAB ProjectProposal Nghiên cứu quy trình gắn nhãn dữ liệu và huấn luyện xe tự hành2021 2022Document8 pagesAutomotiveLAB ProjectProposal Nghiên cứu quy trình gắn nhãn dữ liệu và huấn luyện xe tự hành2021 2022Phạm Gia LongNo ratings yet
- Trí tuệ nhân tạoDocument29 pagesTrí tuệ nhân tạoQuang HuyNo ratings yet
- Bao CaoDocument8 pagesBao Cao0296Nguyễn Nhật Song HàoNo ratings yet
- 2.9: Logistic regression la gì? Chạy các ví dụ và giải thíchDocument9 pages2.9: Logistic regression la gì? Chạy các ví dụ và giải thíchAnh QuânNo ratings yet
- Slide Bao CaoDocument51 pagesSlide Bao CaoLê NguyễnNo ratings yet
- 6 Chuong 4 Hoc May Va Hoc SauDocument30 pages6 Chuong 4 Hoc May Va Hoc SauNguyễn KhánhNo ratings yet
- Bai Thuc Hanh 4Document6 pagesBai Thuc Hanh 4Tong HuynhNo ratings yet
- (LV - C6) Future (Ed - Indivi)Document4 pages(LV - C6) Future (Ed - Indivi)BẢO ĐẶNG THÁINo ratings yet
- tiểu luận 3Document8 pagestiểu luận 3tienn4143No ratings yet
- Presentation MLDocument24 pagesPresentation MLĐức Võ Phạm DuyNo ratings yet
- Chương 4Document8 pagesChương 414.Khổng xuân hoàngNo ratings yet
- 5. Huong dan su dung mo hinh với WekaDocument13 pages5. Huong dan su dung mo hinh với Wekajarvisle11No ratings yet
- 3. Sử Dụng Kỹ Thuật Máy Học Trong Các Hệ Thống Phát Hiện Xâm Nhập MạngDocument12 pages3. Sử Dụng Kỹ Thuật Máy Học Trong Các Hệ Thống Phát Hiện Xâm Nhập MạngTuyên Đặng LêNo ratings yet
- Thuc Hanh Buoi 2 NLMH DT Feb2019Document5 pagesThuc Hanh Buoi 2 NLMH DT Feb2019nhiNo ratings yet
- btl hệ cơ sở dữ liệu đa phương tiệnDocument51 pagesbtl hệ cơ sở dữ liệu đa phương tiệnBảo Anh DươngNo ratings yet
- Deep LearningDocument7 pagesDeep LearningTuấn Nguyễn AnhNo ratings yet
- 1Document6 pages1Huy ĐoànNo ratings yet
- 211is42a13 Nhom 02 BaocaoDocument11 pages211is42a13 Nhom 02 BaocaoLê Quỳnh NhưNo ratings yet
- Bao Cao Cuoi Ki FiDocument20 pagesBao Cao Cuoi Ki FiAditya SundawaNo ratings yet
- Tài liệu không có tiêu đềDocument3 pagesTài liệu không có tiêu đềdung.lequang10548No ratings yet
- NguyenDacThanh TomTatLuanVanDocument30 pagesNguyenDacThanh TomTatLuanVanPINK BLACKNo ratings yet











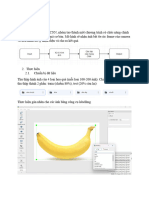
















































Download as docx, pdf, or txt
You might also like
- Cài đặt các gói và import thư việnDocument1 pageCài đặt các gói và import thư việntamphamvan33No ratings yet
- DIPFL23PRJG36Document18 pagesDIPFL23PRJG36quanga1k57hh1No ratings yet
- Final Project AIDocument12 pagesFinal Project AIHuy ĐặngNo ratings yet
- Báo-Cáo MachineLearningDocument18 pagesBáo-Cáo MachineLearningduyanhnguyen100802No ratings yet
- 231MI5206 Nhóm 8 AI ProjectDocument10 pages231MI5206 Nhóm 8 AI Projecttranhb22408No ratings yet
- Report AI Detect Flower BuiChiCuong 20146167Document25 pagesReport AI Detect Flower BuiChiCuong 2014616720146167No ratings yet
- Chương 6. Hướng Dẫn Thực Hành Nhận Diện Ảnh CNNDocument10 pagesChương 6. Hướng Dẫn Thực Hành Nhận Diện Ảnh CNNThiên Trang0% (1)
- Phân Lớp Nhị PhânDocument4 pagesPhân Lớp Nhị PhânÁnh Võ Thị HồngNo ratings yet
- AI NguyenVanQuoc-20146406Document13 pagesAI NguyenVanQuoc-20146406vvanquoc1402No ratings yet
- Nhóm 6Document15 pagesNhóm 6Bui Van Do100% (1)
- Xử lý ảnh và videoDocument12 pagesXử lý ảnh và videotuanlangla3No ratings yet
- BTL XlaDocument12 pagesBTL XlaĐặng Thị Vân AnhNo ratings yet
- Tư tưởng thuật toán nhận diện thủ ngữDocument3 pagesTư tưởng thuật toán nhận diện thủ ngữKhánh TânNo ratings yet
- Tìm hiểu thuật toán XgBoost cho phân loại mã độc AndroidDocument12 pagesTìm hiểu thuật toán XgBoost cho phân loại mã độc Androidsypgamingtv100% (1)
- TGMTDocument3 pagesTGMThoangdt.21ceNo ratings yet
- Xử lí ảnhDocument43 pagesXử lí ảnhtrongnghia03.workNo ratings yet
- Bai Thuc Hanh 2 (Updated)Document6 pagesBai Thuc Hanh 2 (Updated)Cơ Đinh VănNo ratings yet
- Bước 1: Đặt Mục Tiêu và Hiểu Rõ Vấn ĐềDocument3 pagesBước 1: Đặt Mục Tiêu và Hiểu Rõ Vấn Đềtrinhvanhaotv2007No ratings yet
- KHDL 2 OrangeDocument15 pagesKHDL 2 OrangeVương LamNo ratings yet
- Báo cáo CĐHTTT - Nhóm học phần 1 - Group 7Document18 pagesBáo cáo CĐHTTT - Nhóm học phần 1 - Group 7quanga1k57hh1No ratings yet
- M NG SDN XgboostDocument8 pagesM NG SDN Xgboostdvc.290603No ratings yet
- Machine Learning - NLP: Text Classification Sử Dụng Sklearn Python - Code Từ Đầu - Machine LearningDocument9 pagesMachine Learning - NLP: Text Classification Sử Dụng Sklearn Python - Code Từ Đầu - Machine Learningtnt007dataNo ratings yet
- (Machine Learning) Làm Thế Nào Để Đánh Giá Một Mô Hình Máy Học - AI CLUB TUTORIALSDocument15 pages(Machine Learning) Làm Thế Nào Để Đánh Giá Một Mô Hình Máy Học - AI CLUB TUTORIALSHải Đăng PhạmNo ratings yet
- Bao Cao de TaiDocument13 pagesBao Cao de TaiTrần Thị Thùy DươngNo ratings yet
- Decision TreeDocument5 pagesDecision TreeTrần Lê ThiệnNo ratings yet
- TriteunhantaoDocument25 pagesTriteunhantaoQuang HuyNo ratings yet
- Câu 22 Định nghĩa mạng neuron Định nghĩa perceptronDocument2 pagesCâu 22 Định nghĩa mạng neuron Định nghĩa perceptronHữu NhânNo ratings yet
- Phan Tich Du Doan - Machine LearningDocument65 pagesPhan Tich Du Doan - Machine Learningphuongffvip2No ratings yet
- Khai phá dữ liệuDocument20 pagesKhai phá dữ liệuNguyen LinhNo ratings yet
- Deep Learning Cho Bài Toán Nhận Diện Chữ ViếtDocument8 pagesDeep Learning Cho Bài Toán Nhận Diện Chữ Viếtlearnit learnitNo ratings yet
- LtudDocument6 pagesLtudNgoan NguyễnNo ratings yet
- IntSysDev - 03 - 17 - bt8 - Lê H, Oàng DũngDocument11 pagesIntSysDev - 03 - 17 - bt8 - Lê H, Oàng DũngLương Nhật TuấnNo ratings yet
- Phat Hien Ma Doc Bang Machine LearningDocument63 pagesPhat Hien Ma Doc Bang Machine LearningHana YukiNo ratings yet
- PowpointDocument29 pagesPowpointEDM NCSNo ratings yet
- DeepLearning NguyenXuanCongDocument8 pagesDeepLearning NguyenXuanCongcong100% (1)
- Simple Code Demo FunctionDocument67 pagesSimple Code Demo Functionquanghieu.inamedNo ratings yet
- Deep DreamDocument12 pagesDeep DreamĐăng KhoaNo ratings yet
- AutomotiveLAB ProjectProposal Nghiên cứu quy trình gắn nhãn dữ liệu và huấn luyện xe tự hành2021 2022Document8 pagesAutomotiveLAB ProjectProposal Nghiên cứu quy trình gắn nhãn dữ liệu và huấn luyện xe tự hành2021 2022Phạm Gia LongNo ratings yet
- Trí tuệ nhân tạoDocument29 pagesTrí tuệ nhân tạoQuang HuyNo ratings yet
- Bao CaoDocument8 pagesBao Cao0296Nguyễn Nhật Song HàoNo ratings yet
- 2.9: Logistic regression la gì? Chạy các ví dụ và giải thíchDocument9 pages2.9: Logistic regression la gì? Chạy các ví dụ và giải thíchAnh QuânNo ratings yet
- Slide Bao CaoDocument51 pagesSlide Bao CaoLê NguyễnNo ratings yet
- 6 Chuong 4 Hoc May Va Hoc SauDocument30 pages6 Chuong 4 Hoc May Va Hoc SauNguyễn KhánhNo ratings yet
- Bai Thuc Hanh 4Document6 pagesBai Thuc Hanh 4Tong HuynhNo ratings yet
- (LV - C6) Future (Ed - Indivi)Document4 pages(LV - C6) Future (Ed - Indivi)BẢO ĐẶNG THÁINo ratings yet
- tiểu luận 3Document8 pagestiểu luận 3tienn4143No ratings yet
- Presentation MLDocument24 pagesPresentation MLĐức Võ Phạm DuyNo ratings yet
- Chương 4Document8 pagesChương 414.Khổng xuân hoàngNo ratings yet
- 5. Huong dan su dung mo hinh với WekaDocument13 pages5. Huong dan su dung mo hinh với Wekajarvisle11No ratings yet
- 3. Sử Dụng Kỹ Thuật Máy Học Trong Các Hệ Thống Phát Hiện Xâm Nhập MạngDocument12 pages3. Sử Dụng Kỹ Thuật Máy Học Trong Các Hệ Thống Phát Hiện Xâm Nhập MạngTuyên Đặng LêNo ratings yet
- Thuc Hanh Buoi 2 NLMH DT Feb2019Document5 pagesThuc Hanh Buoi 2 NLMH DT Feb2019nhiNo ratings yet
- btl hệ cơ sở dữ liệu đa phương tiệnDocument51 pagesbtl hệ cơ sở dữ liệu đa phương tiệnBảo Anh DươngNo ratings yet
- Deep LearningDocument7 pagesDeep LearningTuấn Nguyễn AnhNo ratings yet
- 1Document6 pages1Huy ĐoànNo ratings yet
- 211is42a13 Nhom 02 BaocaoDocument11 pages211is42a13 Nhom 02 BaocaoLê Quỳnh NhưNo ratings yet
- Bao Cao Cuoi Ki FiDocument20 pagesBao Cao Cuoi Ki FiAditya SundawaNo ratings yet
- Tài liệu không có tiêu đềDocument3 pagesTài liệu không có tiêu đềdung.lequang10548No ratings yet
- NguyenDacThanh TomTatLuanVanDocument30 pagesNguyenDacThanh TomTatLuanVanPINK BLACKNo ratings yet