Download as docx, pdf, or txt
You might also like
- Textbook Introduction To Software Testing 2Nd Edition Paul Ammann Ebook All Chapter PDFDocument53 pagesTextbook Introduction To Software Testing 2Nd Edition Paul Ammann Ebook All Chapter PDFedith.cochran658100% (13)
- Pillars of Singing - Ebook - PopUpDocument121 pagesPillars of Singing - Ebook - PopUpmike50% (6)
- Head First Object-Oriented Analysis and DesignDocument24 pagesHead First Object-Oriented Analysis and DesignMarvin Sena OrtizNo ratings yet
- DSP Project2Document7 pagesDSP Project2Gunjan KhutNo ratings yet
- Greater Key of Solomon PentaclesDocument21 pagesGreater Key of Solomon Pentaclesprajayf94% (34)
- National University of Sciences & Technology: Submited ToDocument8 pagesNational University of Sciences & Technology: Submited ToFahad AqeelNo ratings yet
- BKF 2453 Chemical Reaction Engineering 1 Assignment 1: Lecturer: DR Sureena Binti AbdullahDocument9 pagesBKF 2453 Chemical Reaction Engineering 1 Assignment 1: Lecturer: DR Sureena Binti AbdullahThurgah VshinyNo ratings yet
- Obeticholic Acid FORM C-Crystaline Form XRDDocument3 pagesObeticholic Acid FORM C-Crystaline Form XRDmagugurgelNo ratings yet
- Exp 5 Hall EffectDocument7 pagesExp 5 Hall EffectKowsona ChakrabortyNo ratings yet
- Ada FileDocument17 pagesAda FilevishalNo ratings yet
- Experiment 1 (A) AIM-To Implement Following Algorithm Using Array As A Data Structure and Analyse Its Time Complexity. A. Bubble Sort B. Insertion Sort C. Selection SortDocument25 pagesExperiment 1 (A) AIM-To Implement Following Algorithm Using Array As A Data Structure and Analyse Its Time Complexity. A. Bubble Sort B. Insertion Sort C. Selection Sortdaman khuranaNo ratings yet
- Lab 8 Final WordDocument8 pagesLab 8 Final WordDanny NguyenNo ratings yet
- Utf-8''exemplar AgarDocument9 pagesUtf-8''exemplar AgarZia Baerfuss-liaoNo ratings yet
- Form Field CBR TestDocument1 pageForm Field CBR TestAina TianaNo ratings yet
- Sir Fawad Najam Assignment No 1 FinalDocument50 pagesSir Fawad Najam Assignment No 1 FinalRajput JanjuaNo ratings yet
- Lecture 5Document14 pagesLecture 5Waseem AbbasNo ratings yet
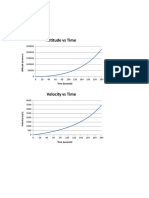
- Altitude Vs Time: Jonathan Lin 503583040 MAE 150R Problem 4bDocument4 pagesAltitude Vs Time: Jonathan Lin 503583040 MAE 150R Problem 4bJon LinNo ratings yet
- Curva Ipr Del PozoDocument2 pagesCurva Ipr Del PozoElio SuarezNo ratings yet
- 2122promana HW3 G5Document7 pages2122promana HW3 G5Dương NgNo ratings yet
- Analysis and Investigation ResultsDocument9 pagesAnalysis and Investigation ResultsStephen A. CuizonNo ratings yet
- Project Cost EstimatingDocument50 pagesProject Cost EstimatingShalik WalkerNo ratings yet
- 2024-25 Sanshtha Budget 20022024MKDocument6 pages2024-25 Sanshtha Budget 20022024MKgodaserbNo ratings yet
- Alize-Lcpc - Design Of Pavement Structures: Units: M, Mn And Mpa; Strains In Μstrain; Deflection In Mm/100Document1 pageAlize-Lcpc - Design Of Pavement Structures: Units: M, Mn And Mpa; Strains In Μstrain; Deflection In Mm/100AndresSantidasNo ratings yet
- Lab 2Document5 pagesLab 2خالد الغامديNo ratings yet
- Activity 4 Tensile Strength Analysis Using FeaDocument8 pagesActivity 4 Tensile Strength Analysis Using FeaRUSTICO PATAWARANNo ratings yet
- Department of Computer Science and EngineeringDocument8 pagesDepartment of Computer Science and EngineeringRukaiya HaqueNo ratings yet
- Wa0004.Document27 pagesWa0004.Kelvin KzhNo ratings yet
- Channel ReportDocument1 pageChannel ReportLuisHuamanQuilicheNo ratings yet
- East Pipe Dn1200Document1 pageEast Pipe Dn1200olsi barkoNo ratings yet
- DSSDSDSDDocument4 pagesDSSDSDSDLenin Arnold Reyes SalvatierraNo ratings yet
- Ejercicio en ClaseDocument4 pagesEjercicio en ClaseAndres CevallosNo ratings yet
- Assignment No 2Document2 pagesAssignment No 2Sidra IqbalNo ratings yet
- DataSheet TA23-P ENDocument12 pagesDataSheet TA23-P ENAlexandre SepulvedaNo ratings yet
- Assignment 2 Final Version1Document27 pagesAssignment 2 Final Version1Christopher Bayo DaramolaNo ratings yet
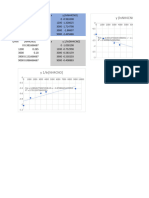
- Simulated Data For A High Performance Mustang: Time MPH Accel - Gs Miles C - RPM Engrpm Log (Dist) /MPHDocument4 pagesSimulated Data For A High Performance Mustang: Time MPH Accel - Gs Miles C - RPM Engrpm Log (Dist) /MPHRiza Gabaya AliaNo ratings yet
- Group 2: Dakshayani Biscuits (: Cost Sheet)Document6 pagesGroup 2: Dakshayani Biscuits (: Cost Sheet)Vinu DNo ratings yet
- Torque at Turbine Shaft Vs SpeedDocument1 pageTorque at Turbine Shaft Vs SpeedDivyansh BansalNo ratings yet
- 17-P-30A/B/C: 1.0 Machine Load DataDocument6 pages17-P-30A/B/C: 1.0 Machine Load Datatitir bagchiNo ratings yet
- Tugas Kelompok 3 - Mekanika MaterialDocument3 pagesTugas Kelompok 3 - Mekanika Materialfikri wahyu pratamaNo ratings yet
- Pavement Information NoteDocument1 pagePavement Information NoteAch MustNo ratings yet
- Writing Scientific NotationDocument4 pagesWriting Scientific NotationRomeo Bordallo Jr.No ratings yet
- Field California Bearing Ratio Test: Pekerjaan Road and Drainage (Entrance Cibitung Projeck)Document2 pagesField California Bearing Ratio Test: Pekerjaan Road and Drainage (Entrance Cibitung Projeck)salim mulhadiNo ratings yet
- Topic: Measurement Activity 1.1 Average and Standard Deviation (Show Your Solutions)Document3 pagesTopic: Measurement Activity 1.1 Average and Standard Deviation (Show Your Solutions)John JohnnyNo ratings yet
- As Built Factory DetailingDocument4 pagesAs Built Factory DetailingMd Ashad NasimNo ratings yet
- Experiment 5 PHYS 105Document2 pagesExperiment 5 PHYS 105غالب الزبيريNo ratings yet
- Nanotechnology Understanding Small Systems 3rd Rogers Solution Manual download pdf full chapterDocument36 pagesNanotechnology Understanding Small Systems 3rd Rogers Solution Manual download pdf full chapteranigeraldu100% (5)
- CE168P-2 S-Curve SampleDocument4 pagesCE168P-2 S-Curve SampleCat BugNo ratings yet
- Mypearth Ch3answersDocument4 pagesMypearth Ch3answersVARGAS GUTIERREZ OMAR DANILO DOCENTE DE FISICANo ratings yet
- R - 522 HDT - Triaxial (Uu)Document9 pagesR - 522 HDT - Triaxial (Uu)Rider BravoNo ratings yet
- ClusteringDocument45 pagesClusteringapi-3717234No ratings yet
- (Firda) Soal Atkins Nomor 22.1 Hal 826Document3 pages(Firda) Soal Atkins Nomor 22.1 Hal 826nadiakamila690No ratings yet
- Homework On Dynamics of StrucutresDocument2 pagesHomework On Dynamics of StrucutresShahidul Islam ShahariarNo ratings yet
- Laboratory CBR Test (SNI 03 - 1744 - 1989) : Tested byDocument2 pagesLaboratory CBR Test (SNI 03 - 1744 - 1989) : Tested byMrdNo ratings yet
- Abc CostingDocument27 pagesAbc CostingSumeet KanojiaNo ratings yet
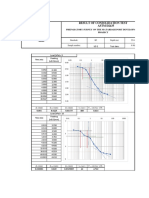
- Result of Consolidation Test ASTM D2435: Preparatory Survey On The Matarbari Port Developm ProjectDocument7 pagesResult of Consolidation Test ASTM D2435: Preparatory Survey On The Matarbari Port Developm ProjectSultan Al ShafianNo ratings yet
- AB Eport: InstructionsDocument5 pagesAB Eport: InstructionsNursultan AibekulyNo ratings yet
- GP 1 (Joint 1) 1Document613 pagesGP 1 (Joint 1) 1imanatul khairaNo ratings yet
- APA - Lab.2 - ReportDocument7 pagesAPA - Lab.2 - ReportMihai LunguNo ratings yet
- Lab 1Document5 pagesLab 1muhammad.amir14333No ratings yet
- TK Final DataDocument5 pagesTK Final Dataapi-447485924No ratings yet
- MPC Session 3: S&OP ProblemsDocument15 pagesMPC Session 3: S&OP ProblemsHarshwardhan PhatakNo ratings yet
- Oscilloscope: College of Arts and Sciences Mathematics, Statistics and Physics Department Physics ProgramDocument6 pagesOscilloscope: College of Arts and Sciences Mathematics, Statistics and Physics Department Physics ProgramAbdulNo ratings yet
- Earth QuakeDocument2 pagesEarth Quakeالمنذر سليمNo ratings yet
- O level Physics Questions And Answer Practice Papers 3From EverandO level Physics Questions And Answer Practice Papers 3Rating: 3 out of 5 stars3/5 (1)
- FSI Updated Colloquial - Sinhala - Part - 1Document233 pagesFSI Updated Colloquial - Sinhala - Part - 1Frank McGrathNo ratings yet
- Principles of Speech WritingDocument24 pagesPrinciples of Speech WritingKate Iannel VicenteNo ratings yet
- AIN I AkbariDocument198 pagesAIN I AkbariParveen KumarNo ratings yet
- Handout Games To Develop Speech and Language SkillsDocument4 pagesHandout Games To Develop Speech and Language SkillsLuisa Fernanda DueñasNo ratings yet
- SP791 Data SheetsDocument19 pagesSP791 Data SheetstarpinoNo ratings yet
- Proposal Ellipsis Dewa Gede Eta Ardiansa (1) - DikonversiDocument9 pagesProposal Ellipsis Dewa Gede Eta Ardiansa (1) - Dikonversisleepy pancakeNo ratings yet
- Soal TOEFL Dan Pembahasan JawabanDocument3 pagesSoal TOEFL Dan Pembahasan JawabanJannatun MakwaNo ratings yet
- Ajit ResumeDocument3 pagesAjit ResumeSreeluNo ratings yet
- Topic 3Document7 pagesTopic 3Ainhoa Sempere Ilazarri100% (1)
- Bei Ya Vitabu Dukani 2023Document16 pagesBei Ya Vitabu Dukani 2023sele aloysNo ratings yet
- Eprints DocsDocument132 pagesEprints DocssummerjamNo ratings yet
- Types of Speech in Context g11Document26 pagesTypes of Speech in Context g11Camille FaustinoNo ratings yet
- Mit18 900s23 Lec1Document5 pagesMit18 900s23 Lec1Htike HtikeNo ratings yet
- ConditionalsDocument5 pagesConditionalsfranosullivanNo ratings yet
- P211 OrderForm - v6 - 022022Document6 pagesP211 OrderForm - v6 - 022022Bijay KumarNo ratings yet
- The Story of Prophet HudDocument3 pagesThe Story of Prophet HudHafiz MajdiNo ratings yet
- AP Proceedings Word TemplateDocument4 pagesAP Proceedings Word TemplateLuqmanulHakimNo ratings yet
- Alpaca + Llama-3 8b Full Example - Ipynb - ColabDocument10 pagesAlpaca + Llama-3 8b Full Example - Ipynb - ColabitisqhNo ratings yet
- WRITING Emails PETDocument3 pagesWRITING Emails PETLiliana BorbollaNo ratings yet
- Exam Prep For AWS Certified Solutions Architect - Associate: Domain 1 - Organizational ComplexityDocument3 pagesExam Prep For AWS Certified Solutions Architect - Associate: Domain 1 - Organizational ComplexityJohann LeeNo ratings yet
- U2 I Still Havent Found What Im Looking For2Document2 pagesU2 I Still Havent Found What Im Looking For2Priscilla F. RoccoNo ratings yet
- 9stantard Eng - Sub - VerificatDocument4 pages9stantard Eng - Sub - VerificatMaraa LovelyNo ratings yet
- Hadmama FinalDocument20 pagesHadmama FinalBen ShekalimNo ratings yet
- Million Dreams Lyrical IdentificationDocument5 pagesMillion Dreams Lyrical Identification24XII MIPA 3 RIFAN RAMADANINo ratings yet
- Question Paper Nov 22Document2 pagesQuestion Paper Nov 22shankar patilNo ratings yet
- Oops Lab ManualDocument41 pagesOops Lab Manualsilicongmaster7060No ratings yet