Download as pdf or txt
You might also like
- Andrew Granville Number Theory Revealed - An Introduction American Mathematical Society 2020 PDFDocument290 pagesAndrew Granville Number Theory Revealed - An Introduction American Mathematical Society 2020 PDFBrigitte ReyesNo ratings yet
- Solution HW5Document9 pagesSolution HW5fawademadNo ratings yet
- 05 PDFDocument70 pages05 PDFRahul RahulNo ratings yet
- Week 10 - Differential EntropyDocument22 pagesWeek 10 - Differential EntropyLOmesh SaHuNo ratings yet
- Lecture 2Document19 pagesLecture 2kungmuNo ratings yet
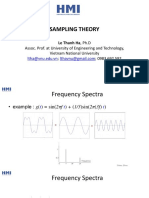
- Digital Image Processing - Sampling TheoryDocument56 pagesDigital Image Processing - Sampling TheoryLong Đặng HoàngNo ratings yet
- Lecture 5 Mask/Filter TransformationDocument24 pagesLecture 5 Mask/Filter Transformationtadiwos workeyeNo ratings yet
- A New Proof of A Classical FormulaDocument5 pagesA New Proof of A Classical FormulaKonstantinos MichailidisNo ratings yet
- PRST 05 DiscreteProbabilityDistributionsDocument25 pagesPRST 05 DiscreteProbabilityDistributionsjth9111No ratings yet
- II CSE Even Sem 2 16 MarksDocument175 pagesII CSE Even Sem 2 16 MarksSoundaryamutha LakshmiNo ratings yet
- Numerical Analysis Lecture NotesDocument72 pagesNumerical Analysis Lecture NotesZhenhuan SongNo ratings yet
- Chapter 4 One Random Variable: Cumulative Distribution FunctionDocument31 pagesChapter 4 One Random Variable: Cumulative Distribution FunctionTayyab AhmedNo ratings yet
- Ma2261 Probability And Random Processes: ω: X (ω) ≤ x x ∈ RDocument17 pagesMa2261 Probability And Random Processes: ω: X (ω) ≤ x x ∈ RSivabalanNo ratings yet
- Statistical Models: Modeling and SimulationDocument51 pagesStatistical Models: Modeling and Simulationsourabh sagdeoNo ratings yet
- STAT2372 Topic4 2020Document39 pagesSTAT2372 Topic4 2020Simthande SokeNo ratings yet
- Chapter 2B - Continuous: Random VariablesDocument20 pagesChapter 2B - Continuous: Random VariablesAhmad AiNo ratings yet
- Lecture3 PDFDocument43 pagesLecture3 PDFSerkan SezinNo ratings yet
- The Source Coding Theorem: M Ario S. Alvim (Msalvim@dcc - Ufmg.br)Document62 pagesThe Source Coding Theorem: M Ario S. Alvim (Msalvim@dcc - Ufmg.br)rose marineNo ratings yet
- Slide 04Document16 pagesSlide 04nguyennd_56No ratings yet
- MGF, Discrete Statistical Distributions - 551Document49 pagesMGF, Discrete Statistical Distributions - 551SatheeskumarNo ratings yet
- Statistics For Business and Economics: Discrete Random Variables and Probability DistributionsDocument82 pagesStatistics For Business and Economics: Discrete Random Variables and Probability DistributionsPui Po FongNo ratings yet
- AciidsDocument16 pagesAciidsTuấn Lưu MinhNo ratings yet
- S1B 16 All LecturesDocument221 pagesS1B 16 All LecturesSaumya GuptaNo ratings yet
- Expected Value:) P (X X X EDocument28 pagesExpected Value:) P (X X X EQuyên Nguyễn HảiNo ratings yet
- Maths FireDocument1 pageMaths Firesaravanan.9344308178No ratings yet
- StatDocument41 pagesStatJason D ChenNo ratings yet
- 1.4 Predicates and Quantifiers: Predicate LogicDocument4 pages1.4 Predicates and Quantifiers: Predicate LogicNgoc DucNo ratings yet
- 472notes PDFDocument98 pages472notes PDFAnonymous vNyn0ch3nNo ratings yet
- An Orthogonality Property of Legendre Polynomials: ResearchDocument13 pagesAn Orthogonality Property of Legendre Polynomials: ResearchRivaldo Cifuentes MonroyNo ratings yet
- 07 Random Variate GenerationDocument44 pages07 Random Variate Generationsaruji_sanNo ratings yet
- Continuity PDFDocument96 pagesContinuity PDFaFNo ratings yet
- Lecture 11Document6 pagesLecture 11Tiffany PersadNo ratings yet
- CS 725: Foundations of Machine Learning: Lecture 2. Overview of Probability Theory For MLDocument23 pagesCS 725: Foundations of Machine Learning: Lecture 2. Overview of Probability Theory For MLAnonymous d0rFT76BNo ratings yet
- Predicate LogicDocument3 pagesPredicate Logicflo sisonNo ratings yet
- Predicates P (X) : - A Predicate P (X) Is A Function That Gives A Unique Output (Truth Values) Against Every InputDocument15 pagesPredicates P (X) : - A Predicate P (X) Is A Function That Gives A Unique Output (Truth Values) Against Every InputaqeelNo ratings yet
- 2021 - Week - 3 - Ch.2 Random ProcessDocument11 pages2021 - Week - 3 - Ch.2 Random ProcessAdibNo ratings yet
- Differential Entropy: Peng-Hua WangDocument24 pagesDifferential Entropy: Peng-Hua Wangriondi27No ratings yet
- Lect - 22 KhalilDocument17 pagesLect - 22 KhalilDaniel AmbrizNo ratings yet
- Lec 1Document12 pagesLec 1khodangNo ratings yet
- Mean Value TheoremDocument2 pagesMean Value Theorem220112034No ratings yet
- Seq SlidesDocument43 pagesSeq Slidesmyturtle game01No ratings yet
- Taylor PDFDocument4 pagesTaylor PDFrajdeep paulNo ratings yet
- Question DPP 1 Continuity and Differentiability Mathongo Jee Main 2022 Crash CourseDocument6 pagesQuestion DPP 1 Continuity and Differentiability Mathongo Jee Main 2022 Crash CoursePc xoixaNo ratings yet
- The Binary Entropy Function: ECE 7680 Lecture 2 - Definitions and Basic FactsDocument8 pagesThe Binary Entropy Function: ECE 7680 Lecture 2 - Definitions and Basic Factsvahap_samanli4102No ratings yet
- Chapter 3: Random Variables: Yunghsiang S. HanDocument75 pagesChapter 3: Random Variables: Yunghsiang S. HanRaj ThakurNo ratings yet
- Problem Set For Tutorial 1 - TDDD08: 1 Syntax of First-Order LogicDocument2 pagesProblem Set For Tutorial 1 - TDDD08: 1 Syntax of First-Order Logictay keithNo ratings yet
- m8 FolDocument27 pagesm8 FolAnonymous hkWIKjoXFVNo ratings yet
- Cls Jeead-17-18 Xii Mat Target-6 Set-2 Chapter-5Document84 pagesCls Jeead-17-18 Xii Mat Target-6 Set-2 Chapter-5Sagar MalhotraNo ratings yet
- An Introduction To Rough PathsDocument59 pagesAn Introduction To Rough PathsAriel MorgensternNo ratings yet
- Discrete Probability Distribution Chapter3Document47 pagesDiscrete Probability Distribution Chapter3TARA NATH POUDELNo ratings yet
- Cooperating Intelligent Systems: Learning From Observations Chapter 18, AIMADocument51 pagesCooperating Intelligent Systems: Learning From Observations Chapter 18, AIMAapi-19643506No ratings yet
- Discrete Probability DistributionsDocument6 pagesDiscrete Probability Distributionssam256256No ratings yet
- Information-Theoretic IdentitiesDocument29 pagesInformation-Theoretic IdentitiesprapunNo ratings yet
- Lecture 10Document22 pagesLecture 10ruff ianNo ratings yet
- Ai Lecture22Document32 pagesAi Lecture22Noun NounaNo ratings yet
- CSCE 970 Lecture 2: Bayesian-Based Classifiers: Most ProbableDocument5 pagesCSCE 970 Lecture 2: Bayesian-Based Classifiers: Most ProbableRachnaNo ratings yet
- DistributionsDocument30 pagesDistributionsb11902142No ratings yet
- f791ff66 108工程機率ch2作業Document3 pagesf791ff66 108工程機率ch2作業孔令洋No ratings yet
- 01 Single Neurons and Small CircuitsDocument104 pages01 Single Neurons and Small CircuitsdagushNo ratings yet
- Bayes Sample QuestionsDocument2 pagesBayes Sample QuestionsRekha RaniNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- HW 1 SolnDocument3 pagesHW 1 Solngooseneck06No ratings yet
- 06 9MA0 01 9MA0 02 A Level Pure Mathematics Practice Set 6 Mark SchemeDocument22 pages06 9MA0 01 9MA0 02 A Level Pure Mathematics Practice Set 6 Mark Schemealexander.tarakanovNo ratings yet
- Calculator NotesDocument101 pagesCalculator NotesMary Dunham100% (1)
- Chapter 9 Test Study Guide: Find The Vertex and Use It To Help Sketch The Graph of Each Function. Identify The SolutionsDocument3 pagesChapter 9 Test Study Guide: Find The Vertex and Use It To Help Sketch The Graph of Each Function. Identify The SolutionsMarissa WalczakNo ratings yet
- Remainder Theorem Sheet 01Document4 pagesRemainder Theorem Sheet 01Rajan shahNo ratings yet
- Axioms of HilbertDocument2 pagesAxioms of HilbertArdis Dimp100% (1)
- Congruence of Triangles - SSS, SAS, ASA, & RHS Examples & FAQsDocument1 pageCongruence of Triangles - SSS, SAS, ASA, & RHS Examples & FAQsOlivia TeakleNo ratings yet
- 2016 Financial Mathematics AssignmentDocument1 page2016 Financial Mathematics AssignmentDfcNo ratings yet
- Engineering Mathematics I Question Bank With Answer KeyDocument10 pagesEngineering Mathematics I Question Bank With Answer KeyKuru KshetranNo ratings yet
- Rte-M1 Algebra & TrigonometryDocument5 pagesRte-M1 Algebra & TrigonometryPaco Pascua0% (2)
- Havârneanu, Geanina, Strategies and Teaching Methods For Stimulate Creativity by Teaching Mathematics PDFDocument20 pagesHavârneanu, Geanina, Strategies and Teaching Methods For Stimulate Creativity by Teaching Mathematics PDFGu Gu100% (1)
- Libro Kamala - Formal Languages and ComputationDocument517 pagesLibro Kamala - Formal Languages and Computationroberto lazoNo ratings yet
- Mat106 Discrete-Mathematical-Structures TH 1.20 Ac26Document2 pagesMat106 Discrete-Mathematical-Structures TH 1.20 Ac26Ayyappa KolliNo ratings yet
- Math Curriculum AY 2023-2024 Lower Secondary Year 8Document6 pagesMath Curriculum AY 2023-2024 Lower Secondary Year 8Saanvi100% (1)
- Paper June 2009Document16 pagesPaper June 2009elpingaritoNo ratings yet
- Information Theory & Coding (ECE) by Nitin MittalDocument15 pagesInformation Theory & Coding (ECE) by Nitin MittalAmanjeet Panghal0% (1)
- AA222 Old 1 IntroDocument28 pagesAA222 Old 1 IntroJan PeetersNo ratings yet
- Math 5 Q2 FDocument41 pagesMath 5 Q2 FLorefe Delos SantosNo ratings yet
- Pre Assessment SummativeDocument26 pagesPre Assessment SummativeRomeo Jr Pacheco OpenaNo ratings yet
- Penelitian Dari Naufal Dan Magnadi (2017) PDFDocument9 pagesPenelitian Dari Naufal Dan Magnadi (2017) PDFPrecious OracionNo ratings yet
- Eigen Symmetric 3 X 3Document21 pagesEigen Symmetric 3 X 3Igor GjorgjievNo ratings yet
- Dr. Pradeep Kumar Saroj: Introduction To Differential Equations (With Applications)Document23 pagesDr. Pradeep Kumar Saroj: Introduction To Differential Equations (With Applications)Sujal ChandakNo ratings yet
- Unit-1: Dynamics K1 Level Questions Multiple Choice QuestionsDocument21 pagesUnit-1: Dynamics K1 Level Questions Multiple Choice QuestionsBabitha Dhana100% (1)
- Chapter 7 - Poisson's and Laplace EquationsDocument19 pagesChapter 7 - Poisson's and Laplace EquationsCarlosAlbanNo ratings yet
- Pure Maths Revision Tracker: Resource Status (Tick If Completed) & DateDocument3 pagesPure Maths Revision Tracker: Resource Status (Tick If Completed) & DateQuan nguyen minhNo ratings yet
- Laplace Transformation - WordDocument9 pagesLaplace Transformation - WordlovebeannNo ratings yet
- Projection of Straight Line: - A Straight Line Can Be Kept in SIXDocument9 pagesProjection of Straight Line: - A Straight Line Can Be Kept in SIXAravamudhanNo ratings yet
- 3.2 Logarithmic Functions & Their GraphsDocument16 pages3.2 Logarithmic Functions & Their GraphsGaming With the BoysNo ratings yet
- Sat Math Practice Test 12 AnswersDocument6 pagesSat Math Practice Test 12 AnswerswwwmacyNo ratings yet