Download as pdf or txt
You might also like
- For The 3 Harmless Questions That Will Awaken His Love and Devotion, Follow This LinkDocument40 pagesFor The 3 Harmless Questions That Will Awaken His Love and Devotion, Follow This LinkJolin Wong100% (1)
- Transcript-Ex23-As1-2018-Bc-Bw 1564166663001 1Document4 pagesTranscript-Ex23-As1-2018-Bc-Bw 1564166663001 1api-4901105670% (1)
- Experiment 8 RefractometerDocument7 pagesExperiment 8 RefractometerJoshua80% (5)
- Literacy Narrative Self-ReflectionDocument2 pagesLiteracy Narrative Self-ReflectionMahadeo SinghNo ratings yet
- Cell WorksheetDocument12 pagesCell WorksheetNahed Safi100% (1)
- Experiment 8 RefractometerDocument6 pagesExperiment 8 RefractometerChristine Mae CablingNo ratings yet
- Cluster Analysis Using SPSSDocument12 pagesCluster Analysis Using SPSSroi_marketingNo ratings yet
- Lesson Plan Life of PiDocument3 pagesLesson Plan Life of Piapi-260707119No ratings yet
- Worked Examples of Non-Parametric TestsDocument22 pagesWorked Examples of Non-Parametric TestsCollins MuseraNo ratings yet
- Subject: Biology SL Internal Assessment Name: Malo Sofía ID: 000000Document12 pagesSubject: Biology SL Internal Assessment Name: Malo Sofía ID: 000000Sofia MaloNo ratings yet
- Correlation and Regression Analysis PDFDocument11 pagesCorrelation and Regression Analysis PDFKhalid EmonNo ratings yet
- Quantitative Techniques:: OPJS University, Rajgarh - Churu Quantitative MethodDocument20 pagesQuantitative Techniques:: OPJS University, Rajgarh - Churu Quantitative MethodJoly SinhaNo ratings yet
- Correlation and RegressionDocument34 pagesCorrelation and Regressionashutosh raiNo ratings yet
- Numerical Analysis 2 (Mid Term)Document2 pagesNumerical Analysis 2 (Mid Term)sasafafsNo ratings yet
- Elina Kanybekova - EXAM - 19 - 12 - 2022Document1,942 pagesElina Kanybekova - EXAM - 19 - 12 - 2022elina 14No ratings yet
- MethodologyDocument7 pagesMethodologyQuratulain BilalNo ratings yet
- Eia2013 Individual AssignmentDocument8 pagesEia2013 Individual AssignmentjoysellamohdalkaffNo ratings yet
- Anne Hankel - Practice IADocument17 pagesAnne Hankel - Practice IAAnne HankelNo ratings yet
- Two Variable StatisticsDocument12 pagesTwo Variable StatisticsdarlingtonmabayaNo ratings yet
- The Gender Pay Gap22Document24 pagesThe Gender Pay Gap22Erik KimNo ratings yet
- RegressionDocument21 pagesRegressionJoyce ChoyNo ratings yet
- Exp. 1 FLRDocument5 pagesExp. 1 FLRDCRUZNo ratings yet
- Zachary Sahari IA For AI SLDocument10 pagesZachary Sahari IA For AI SLZachary ConcessioNo ratings yet
- Business Analytics Practical ProblemsDocument26 pagesBusiness Analytics Practical ProblemsPriyaNo ratings yet
- Odelling and Predicting Using Linear Regression: Penny RobinsonDocument45 pagesOdelling and Predicting Using Linear Regression: Penny RobinsonhgfmefNo ratings yet
- Statistical Analysis TechniquesDocument11 pagesStatistical Analysis TechniquesSashiNo ratings yet
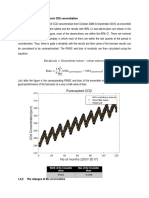
- 1.4.1 Forecast The Atmospheric CO2 Concentration: RMSE of The Ensemble Mean Bias of The Ensemble MeanDocument6 pages1.4.1 Forecast The Atmospheric CO2 Concentration: RMSE of The Ensemble Mean Bias of The Ensemble MeanEmmanuel LazoNo ratings yet
- MIC481 Lab ReportDocument6 pagesMIC481 Lab ReportAbg Khairul Hannan Bin Abg AbdillahNo ratings yet
- Chapter 4-5.editedDocument22 pagesChapter 4-5.editedannieezeh9No ratings yet
- Test of RelationshipDocument8 pagesTest of RelationshipErin Shira BactadanNo ratings yet
- Chap 1 IntroductionDocument15 pagesChap 1 Introductionrifqimh20000No ratings yet
- Correlation Pearson WPS OfficeDocument24 pagesCorrelation Pearson WPS OfficeHamida patinoNo ratings yet
- SHDS3195 - Midterm AssignmentDocument5 pagesSHDS3195 - Midterm AssignmentAsma AliNo ratings yet
- Tutorial 2 Sem11011Document2 pagesTutorial 2 Sem11011Nurul Izzatti Syahida KhaadNo ratings yet
- A Study On Brand Switching in Telecom Industry in IndiaDocument15 pagesA Study On Brand Switching in Telecom Industry in IndiaGurinder DhindsaNo ratings yet
- Ugandan Women's Perception of Contracting AIDS by Marital StatusDocument6 pagesUgandan Women's Perception of Contracting AIDS by Marital Statusapi-66754388No ratings yet
- Principal Component Analysis For Noise Reduction and Fraudulent Activity Detection in Scientific DataDocument10 pagesPrincipal Component Analysis For Noise Reduction and Fraudulent Activity Detection in Scientific DataDisant UpadhyayNo ratings yet
- A221 Sqqs1013 g4 Group Project 2Document6 pagesA221 Sqqs1013 g4 Group Project 2tasya zakariaNo ratings yet
- DM&DW Individual Assignment (50%)Document4 pagesDM&DW Individual Assignment (50%)abrhamNo ratings yet
- Mulia EditDocument11 pagesMulia Editmuliasena.ndNo ratings yet
- Business AnalyticsDocument10 pagesBusiness AnalyticsMaurren SalidoNo ratings yet
- Factor AnalysisDocument34 pagesFactor Analysisrashed azadNo ratings yet
- Physics Lab Manual 2022-23Document60 pagesPhysics Lab Manual 2022-23NikhilNo ratings yet
- Weibull Ortega GurumendiDocument8 pagesWeibull Ortega GurumendiYaritza maribel ortega anzulesNo ratings yet
- STE Mod Research-II-Correlation Q3 Wk-1 Final-1Document10 pagesSTE Mod Research-II-Correlation Q3 Wk-1 Final-1Jean Sachin JacaNo ratings yet
- Exp7 Result ReportDocument7 pagesExp7 Result Report성제박No ratings yet
- Processing and EDA and CorrelationDocument7 pagesProcessing and EDA and Correlationanus2021No ratings yet
- Maderazo Rodriguez Sangalang CE 2103 EDADocument5 pagesMaderazo Rodriguez Sangalang CE 2103 EDAjocelNo ratings yet
- Mulia EditDocument13 pagesMulia Editmuliasena.ndNo ratings yet
- Sta Mann WhitneyU Test of SignificanceDocument6 pagesSta Mann WhitneyU Test of SignificancePuji HartonoNo ratings yet
- Implementation Multiple Linear Regresion in NeuralDocument8 pagesImplementation Multiple Linear Regresion in NeuralPhạm TrưởngNo ratings yet
- The Application of Inferential Statistics in Testing Research Hypotheses in Library and Information ScienceDocument9 pagesThe Application of Inferential Statistics in Testing Research Hypotheses in Library and Information ScienceInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- Chapter 4Document9 pagesChapter 4Rizwan RaziNo ratings yet
- Statistic Group 4Document12 pagesStatistic Group 4Arlyn Edem EspirituNo ratings yet
- X RAY DefractionDocument7 pagesX RAY Defractiondulararashmika00No ratings yet
- Decision Science - Assingment June 2021 1AB0uFHVj3Document5 pagesDecision Science - Assingment June 2021 1AB0uFHVj3karunakar vNo ratings yet
- Application of Chi - Square Test of Independence: A Seminar Presented ONDocument9 pagesApplication of Chi - Square Test of Independence: A Seminar Presented ONjimoh olamidayo MichealNo ratings yet
- Full ReportDocument25 pagesFull ReportMuhammad Asyraf Bin RusliNo ratings yet
- BusStat 2023 HW13 Chapter 13Document3 pagesBusStat 2023 HW13 Chapter 13Friscilia OrlandoNo ratings yet
- Title: X - Ray Analysis of Ceramic Materials. Aim:: N N D IDocument4 pagesTitle: X - Ray Analysis of Ceramic Materials. Aim:: N N D IDimantha SwarnapalaNo ratings yet
- Chapter Nineteen: Factor AnalysisDocument37 pagesChapter Nineteen: Factor AnalysisSAIKRISHNA VAIDYANo ratings yet
- Chapter Nineteen: Factor AnalysisDocument37 pagesChapter Nineteen: Factor AnalysisSAIKRISHNA VAIDYANo ratings yet
- 43 Paper Smart Signal Noise 508Document18 pages43 Paper Smart Signal Noise 508amarmotNo ratings yet
- Mapping the Spatial Distribution of Poverty Using Satellite Imagery in ThailandFrom EverandMapping the Spatial Distribution of Poverty Using Satellite Imagery in ThailandNo ratings yet
- CernuschiFederico2015 PDFDocument283 pagesCernuschiFederico2015 PDFsergio3h33largo3cocuNo ratings yet
- PICQS Qatar Scholarship ProgramDocument2 pagesPICQS Qatar Scholarship Programsui1981No ratings yet
- Department of Ship Technology ModifiedDocument21 pagesDepartment of Ship Technology ModifiedAbhishek GauravNo ratings yet
- Invitation LettersDocument9 pagesInvitation LettersMarivic de la CruzNo ratings yet
- Repairing Relationships With A Time-InDocument1 pageRepairing Relationships With A Time-InRobin PotterNo ratings yet
- Bilingualism EffectDocument6 pagesBilingualism EffectHammad AliNo ratings yet
- Mapudungun: Illustrations of The IpaDocument10 pagesMapudungun: Illustrations of The IpaAlita_77No ratings yet
- 5310 Syllabus 2017 SpringDocument3 pages5310 Syllabus 2017 SpringAbhishek VermaNo ratings yet
- Meeting Nutritional Needs ElderlyDocument25 pagesMeeting Nutritional Needs ElderlyJustine PlazaNo ratings yet
- What Are The Main Features That Differentiate Qualitative Research From Quantitative ResearchDocument3 pagesWhat Are The Main Features That Differentiate Qualitative Research From Quantitative ResearchAhmed AlesaNo ratings yet
- The Fault in Our StarsDocument5 pagesThe Fault in Our StarsAnaliza Kitongan LantayanNo ratings yet
- CPU OverloadDocument3 pagesCPU OverloadadriansyahputraNo ratings yet
- HR Anexi BrochureDocument2 pagesHR Anexi BrochurehranexiNo ratings yet
- Comprehensive Assessment of Professional CompetenceDocument11 pagesComprehensive Assessment of Professional CompetenceRizka PutrantiNo ratings yet
- Non Linear Control of Four Wheel Omnidirectional Mobile Robot Modeling Simulation Real Time ImplementationDocument23 pagesNon Linear Control of Four Wheel Omnidirectional Mobile Robot Modeling Simulation Real Time Implementationchahinez abdellaouiNo ratings yet
- Electrical Preventive MaintenanceDocument2 pagesElectrical Preventive MaintenanceSayed NagyNo ratings yet
- Dr. Yanga'S Colleges, Inc.: Center For Curriculum Development and Instructional Technology Course SyllabusDocument3 pagesDr. Yanga'S Colleges, Inc.: Center For Curriculum Development and Instructional Technology Course SyllabusJohn Luis Masangkay BantolinoNo ratings yet
- Đề kiểm tra 45 phút Tiếng Anh 12 học kì 1 Số 1Document11 pagesĐề kiểm tra 45 phút Tiếng Anh 12 học kì 1 Số 1Diễm Quỳnh NguyễnNo ratings yet
- Lesson Plan Integral CalculusDocument47 pagesLesson Plan Integral CalculusAdriane TingzonNo ratings yet
- Working With Sexual Issues in Systemic Therapy by Desa Markovic PDFDocument13 pagesWorking With Sexual Issues in Systemic Therapy by Desa Markovic PDFsusannegriffinNo ratings yet
- ELP2 Minutes of The MeetingDocument2 pagesELP2 Minutes of The MeetingMark TayagNo ratings yet
- A Practical Guide To Coping With Hearing Voices by Paul BakerDocument32 pagesA Practical Guide To Coping With Hearing Voices by Paul BakerNaresh Vepuri50% (2)
- Jee & Anggoro 2012 - Comic CognitionDocument15 pagesJee & Anggoro 2012 - Comic CognitionAyu IndraswaryNo ratings yet
- Gordon's Functional Health PatternsDocument4 pagesGordon's Functional Health PatternsJamaica Leslie Noveno0% (1)
- An Malipayon Nga Pamilya (A3)Document23 pagesAn Malipayon Nga Pamilya (A3)Richell OmandamNo ratings yet