
Random Variable
Random Variable
You might also like
- Basic Statistics AssignmentDocument5 pagesBasic Statistics Assignmentsantosh raazNo ratings yet
- Math1041 Study Notes For UNSWDocument16 pagesMath1041 Study Notes For UNSWOliverNo ratings yet
- Statistics - Mathematical Statistics Functions - Python 3.10.1 DocumentationDocument14 pagesStatistics - Mathematical Statistics Functions - Python 3.10.1 Documentationluis diego correaNo ratings yet
- Quantitative Techniques in Business: Statistical PartDocument28 pagesQuantitative Techniques in Business: Statistical PartMuhammad ArslanNo ratings yet
- Mean Median ModeDocument10 pagesMean Median ModeEprinthousespNo ratings yet
- Advanced StatisticsDocument259 pagesAdvanced StatisticsVelmar Alcano LumantaoNo ratings yet
- Arithmetic Mean AverageDocument29 pagesArithmetic Mean AverageChristyl Deinla EspiloyNo ratings yet
- Session 12Document8 pagesSession 12darayir140No ratings yet
- Basic StatisticsDocument23 pagesBasic StatisticsDeepti BhoknalNo ratings yet
- Measures of Middle and SpreadDocument13 pagesMeasures of Middle and SpreadJose-Pepe SVNo ratings yet
- Nummerical SummariesDocument11 pagesNummerical Summaries60 Vibha Shree.SNo ratings yet
- Calculating Standard Error Bars For A GraphDocument6 pagesCalculating Standard Error Bars For A GraphKona MenyongaNo ratings yet
- Data Mining Lab Maual Through Python 031023Document22 pagesData Mining Lab Maual Through Python 031023Manish KumarNo ratings yet
- StatisticsDocument211 pagesStatisticsHasan Hüseyin Çakır100% (6)
- Data Visualizations: HistogramsDocument27 pagesData Visualizations: HistogramsHuu Van TranNo ratings yet
- ASSIGNMEN4Document15 pagesASSIGNMEN4Harshita Sharma100% (1)
- Notebook StatisticsDocument6 pagesNotebook Statisticsdetomal301No ratings yet
- Statistics Is A Branch of Mathematics Dealing With The Collection, Analysis, InterpretationDocument2 pagesStatistics Is A Branch of Mathematics Dealing With The Collection, Analysis, InterpretationMary ReyshelNo ratings yet
- Ics 2328 Computer Oriented Statistical Modeling Assignment March 2024 MsDocument6 pagesIcs 2328 Computer Oriented Statistical Modeling Assignment March 2024 MsaustinbodiNo ratings yet
- SDA 3E Chapter 2Document40 pagesSDA 3E Chapter 2xinearpingerNo ratings yet
- StatisticsDocument33 pagesStatisticsRado Mayson SilalahiNo ratings yet
- Interpretation of Data Topic: World Cup 2016 Subject: Business Analytics Assignment No 1Document3 pagesInterpretation of Data Topic: World Cup 2016 Subject: Business Analytics Assignment No 1daniyal shaikhNo ratings yet
- Notas EstadisticaDocument20 pagesNotas EstadisticaCristian CanazaNo ratings yet
- Measuring Central Tendency in Data MiningDocument32 pagesMeasuring Central Tendency in Data MiningDan MasangaNo ratings yet
- Data Mining-5 - Getting Know Data 1Document27 pagesData Mining-5 - Getting Know Data 1يزيد زايدNo ratings yet
- Instructions For Chapter 3 Prepared by Dr. Guru-Gharana: Terminology and ConventionsDocument11 pagesInstructions For Chapter 3 Prepared by Dr. Guru-Gharana: Terminology and ConventionsLou RawlsNo ratings yet
- RESEARCHDocument15 pagesRESEARCHJerwin SanchezNo ratings yet
- Difference Between (Median, Mean, Mode, Range, Midrange) (Descriptive Statistics)Document11 pagesDifference Between (Median, Mean, Mode, Range, Midrange) (Descriptive Statistics)mahmoudNo ratings yet
- DWDM PracticalsDocument32 pagesDWDM PracticalsSangam PandeyNo ratings yet
- Chapter1 StatisticsDocument17 pagesChapter1 Statisticsarokia samyNo ratings yet
- QUALITATIVE DATA Are Measurements For Which There Is No NaturalDocument9 pagesQUALITATIVE DATA Are Measurements For Which There Is No NaturalMarcelaMorenoNo ratings yet
- Chapter 08 Statistics 2Document47 pagesChapter 08 Statistics 2aymanNo ratings yet
- MeanDocument7 pagesMeanRavi SharmaNo ratings yet
- Stats Week 1 PDFDocument6 pagesStats Week 1 PDFAnonymous n0S2m9sR1ENo ratings yet
- Statistics - Describing Data NumericalDocument56 pagesStatistics - Describing Data NumericalDr Rushen SinghNo ratings yet
- MatematikDocument26 pagesMatematikMuhd Hilmi AkhirNo ratings yet
- Frequency Table: Descriptive StatisticsDocument27 pagesFrequency Table: Descriptive StatisticsStacy JonesNo ratings yet
- Apunts BLOC 1 EstadísticaDocument15 pagesApunts BLOC 1 EstadísticaMayssae EssabbarNo ratings yet
- The Idiomatic Programmer - Statistics PrimerDocument44 pagesThe Idiomatic Programmer - Statistics PrimerssignnNo ratings yet
- BDA 09 Shridhti TiwariDocument12 pagesBDA 09 Shridhti TiwariShrishti TiwariNo ratings yet
- Statistical Machine LearningDocument12 pagesStatistical Machine LearningDeva Hema100% (1)
- Math Terms (Junior High)Document2 pagesMath Terms (Junior High)Brian BlackwellNo ratings yet
- Unit3-Data ScienceDocument37 pagesUnit3-Data ScienceDIVYANSH GAUR (RA2011027010090)No ratings yet
- Chapter 3 Numerical Descriptive Measures: 3.1 Measures of Central Tendency For Ungrouped DataDocument14 pagesChapter 3 Numerical Descriptive Measures: 3.1 Measures of Central Tendency For Ungrouped DataKhay OngNo ratings yet
- Descriptive StatisticsDocument7 pagesDescriptive StatisticsShane LiwagNo ratings yet
- Bio Statistics 3Document13 pagesBio Statistics 3Moos LightNo ratings yet
- Statistics Lecture Grouped DataDocument11 pagesStatistics Lecture Grouped DataMary Roxanne AngelesNo ratings yet
- Bda 09 Nidhi YadavDocument12 pagesBda 09 Nidhi YadavShrishti TiwariNo ratings yet
- BIOSTATISTICSDocument14 pagesBIOSTATISTICSSuhail KhanNo ratings yet
- Stats 3Document12 pagesStats 3Marianne Christie RagayNo ratings yet
- Project Management Methodology-Batch - 17082020-7AMDocument81 pagesProject Management Methodology-Batch - 17082020-7AMram DinduNo ratings yet
- Probability and Statistics For Computer Scientists Second Edition, By: Michael BaronDocument63 pagesProbability and Statistics For Computer Scientists Second Edition, By: Michael BaronVall GyiNo ratings yet
- Ecotrix With R and PythonDocument25 pagesEcotrix With R and PythonzuhanshaikNo ratings yet
- DM015SM P-IDocument15 pagesDM015SM P-IAnanya TyagiNo ratings yet
- DWDM Unit-2Document20 pagesDWDM Unit-2CS BCANo ratings yet
- MeanDocument4 pagesMeanSteward john Dela cruzNo ratings yet
- Arithmetic MeanDocument3 pagesArithmetic MeanChoi Ko DohNo ratings yet
- Evans Analytics2e PPT 04 RevisedDocument51 pagesEvans Analytics2e PPT 04 RevisedNur SabrinaNo ratings yet
- Introduction To Business Statistics Through R Software: SoftwareFrom EverandIntroduction To Business Statistics Through R Software: SoftwareNo ratings yet
- Vlsi NotesDocument9 pagesVlsi NotesVipin RajputNo ratings yet
- NumericalsDocument3 pagesNumericalsVipin RajputNo ratings yet
- Binary SearchDocument6 pagesBinary SearchVipin RajputNo ratings yet
- K-Means Clustering AlgorithmDocument17 pagesK-Means Clustering AlgorithmVipin RajputNo ratings yet
- Chapter Four: Conditional Probability and IndependenceDocument8 pagesChapter Four: Conditional Probability and IndependenceOnetwothree Tube0% (2)
- Bits F464 1339 T1M 2017 1Document1 pageBits F464 1339 T1M 2017 1ashishNo ratings yet
- Statistical Fallacies and Errors in Medical ResearchDocument41 pagesStatistical Fallacies and Errors in Medical ResearchMuhammad IrfanNo ratings yet
- Chapter 2: Probability: Course Name: Probability & StatisticsDocument95 pagesChapter 2: Probability: Course Name: Probability & StatisticsThiên IceNo ratings yet
- PPT05-Quantifying UncertaintyDocument39 pagesPPT05-Quantifying UncertaintyVeri VeriNo ratings yet
- PDF Best Explanations New Essays On Inference To The Best Explanation Kevin Mccain and Ted Poston Eds Ebook Full ChapterDocument53 pagesPDF Best Explanations New Essays On Inference To The Best Explanation Kevin Mccain and Ted Poston Eds Ebook Full Chapterjessica.briggs792100% (2)
- Jupyter Notebook ViewerDocument32 pagesJupyter Notebook ViewerThomas Amleth BottiniNo ratings yet
- Basic Business Statistics: 12 EditionDocument41 pagesBasic Business Statistics: 12 EditionMuhammad AfzalNo ratings yet
- Ai PrinciplesDocument29 pagesAi PrinciplesKalpana MrcetNo ratings yet
- Statistical Reasoning: Dr. Anjali DiwanDocument64 pagesStatistical Reasoning: Dr. Anjali DiwanPaulos KNo ratings yet
- Expert Systems TutorialDocument8 pagesExpert Systems TutorialKuganeswara Sarma AatithanNo ratings yet
- Soil Dynamics and Earthquake Engineering: Shima Taheri, Reza Karami MohammadiDocument20 pagesSoil Dynamics and Earthquake Engineering: Shima Taheri, Reza Karami MohammadiSumit SahaNo ratings yet
- Practice For Homework 2: QuestionsDocument8 pagesPractice For Homework 2: QuestionsGurjar DevyaniNo ratings yet
- Fundamentals of Business Statistics: 6E John LoucksDocument63 pagesFundamentals of Business Statistics: 6E John LoucksHafsah Ahmad najibNo ratings yet
- Chapter 1 The Basics of Bayesian Statistics - An Introduction To Bayesian ThinkingDocument17 pagesChapter 1 The Basics of Bayesian Statistics - An Introduction To Bayesian Thinkingmrs dosadoNo ratings yet
- Chapter 5 - Uncertain Knowledge and ReasoningDocument29 pagesChapter 5 - Uncertain Knowledge and ReasoningsomsonengdaNo ratings yet
- Bpa12303 Week2 28probability 291Document36 pagesBpa12303 Week2 28probability 291Nur MaishaNo ratings yet
- DM-Model Question Paper SolutionsDocument27 pagesDM-Model Question Paper Solutionscsumant94No ratings yet
- Unit IV Uncertain Knowledge and Decision TheoryDocument54 pagesUnit IV Uncertain Knowledge and Decision TheoryPallavi BhartiNo ratings yet
- Chapter Two: 2. Conditional Probability and IndependenceDocument6 pagesChapter Two: 2. Conditional Probability and IndependenceTewodros Alemu LoveNo ratings yet
- Bayesian Statistics and ModellingDocument28 pagesBayesian Statistics and Modellingmainking2003No ratings yet
- Probability QTHDocument115 pagesProbability QTHNidhi MatlaniNo ratings yet
- Lecture No.4Document13 pagesLecture No.4m.sheraz malikNo ratings yet
- Bayesian Theory: By: Khaliq BeroDocument15 pagesBayesian Theory: By: Khaliq BeroMr KhaliqNo ratings yet
- AL3391 AI UNIT 5 NOTES EduEnggDocument26 pagesAL3391 AI UNIT 5 NOTES EduEnggKarthik king K100% (1)
- Quantitative Methods For Business 13th Edition Anderson Sweeney Williams Camm Cochran Fry Ohlmann Solution ManualDocument16 pagesQuantitative Methods For Business 13th Edition Anderson Sweeney Williams Camm Cochran Fry Ohlmann Solution Manualrichard100% (27)
- Gandhinagar Institute of Technology: B.E. Sem 8 Computer Engineering DepartmentDocument10 pagesGandhinagar Institute of Technology: B.E. Sem 8 Computer Engineering Departmentbhavya parikhNo ratings yet
- Bayesian Theory and Methods With ApplicationsDocument327 pagesBayesian Theory and Methods With ApplicationsDavid Arteaga100% (2)
- Managerial Decisions Under UncertaintyDocument29 pagesManagerial Decisions Under UncertaintykiNo ratings yet
- Unit Iii ClassificationDocument57 pagesUnit Iii ClassificationarshuyasNo ratings yet




























































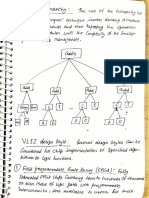

































Download as pdf or txt
You might also like
- Basic Statistics AssignmentDocument5 pagesBasic Statistics Assignmentsantosh raazNo ratings yet
- Math1041 Study Notes For UNSWDocument16 pagesMath1041 Study Notes For UNSWOliverNo ratings yet
- Statistics - Mathematical Statistics Functions - Python 3.10.1 DocumentationDocument14 pagesStatistics - Mathematical Statistics Functions - Python 3.10.1 Documentationluis diego correaNo ratings yet
- Quantitative Techniques in Business: Statistical PartDocument28 pagesQuantitative Techniques in Business: Statistical PartMuhammad ArslanNo ratings yet
- Mean Median ModeDocument10 pagesMean Median ModeEprinthousespNo ratings yet
- Advanced StatisticsDocument259 pagesAdvanced StatisticsVelmar Alcano LumantaoNo ratings yet
- Arithmetic Mean AverageDocument29 pagesArithmetic Mean AverageChristyl Deinla EspiloyNo ratings yet
- Session 12Document8 pagesSession 12darayir140No ratings yet
- Basic StatisticsDocument23 pagesBasic StatisticsDeepti BhoknalNo ratings yet
- Measures of Middle and SpreadDocument13 pagesMeasures of Middle and SpreadJose-Pepe SVNo ratings yet
- Nummerical SummariesDocument11 pagesNummerical Summaries60 Vibha Shree.SNo ratings yet
- Calculating Standard Error Bars For A GraphDocument6 pagesCalculating Standard Error Bars For A GraphKona MenyongaNo ratings yet
- Data Mining Lab Maual Through Python 031023Document22 pagesData Mining Lab Maual Through Python 031023Manish KumarNo ratings yet
- StatisticsDocument211 pagesStatisticsHasan Hüseyin Çakır100% (6)
- Data Visualizations: HistogramsDocument27 pagesData Visualizations: HistogramsHuu Van TranNo ratings yet
- ASSIGNMEN4Document15 pagesASSIGNMEN4Harshita Sharma100% (1)
- Notebook StatisticsDocument6 pagesNotebook Statisticsdetomal301No ratings yet
- Statistics Is A Branch of Mathematics Dealing With The Collection, Analysis, InterpretationDocument2 pagesStatistics Is A Branch of Mathematics Dealing With The Collection, Analysis, InterpretationMary ReyshelNo ratings yet
- Ics 2328 Computer Oriented Statistical Modeling Assignment March 2024 MsDocument6 pagesIcs 2328 Computer Oriented Statistical Modeling Assignment March 2024 MsaustinbodiNo ratings yet
- SDA 3E Chapter 2Document40 pagesSDA 3E Chapter 2xinearpingerNo ratings yet
- StatisticsDocument33 pagesStatisticsRado Mayson SilalahiNo ratings yet
- Interpretation of Data Topic: World Cup 2016 Subject: Business Analytics Assignment No 1Document3 pagesInterpretation of Data Topic: World Cup 2016 Subject: Business Analytics Assignment No 1daniyal shaikhNo ratings yet
- Notas EstadisticaDocument20 pagesNotas EstadisticaCristian CanazaNo ratings yet
- Measuring Central Tendency in Data MiningDocument32 pagesMeasuring Central Tendency in Data MiningDan MasangaNo ratings yet
- Data Mining-5 - Getting Know Data 1Document27 pagesData Mining-5 - Getting Know Data 1يزيد زايدNo ratings yet
- Instructions For Chapter 3 Prepared by Dr. Guru-Gharana: Terminology and ConventionsDocument11 pagesInstructions For Chapter 3 Prepared by Dr. Guru-Gharana: Terminology and ConventionsLou RawlsNo ratings yet
- RESEARCHDocument15 pagesRESEARCHJerwin SanchezNo ratings yet
- Difference Between (Median, Mean, Mode, Range, Midrange) (Descriptive Statistics)Document11 pagesDifference Between (Median, Mean, Mode, Range, Midrange) (Descriptive Statistics)mahmoudNo ratings yet
- DWDM PracticalsDocument32 pagesDWDM PracticalsSangam PandeyNo ratings yet
- Chapter1 StatisticsDocument17 pagesChapter1 Statisticsarokia samyNo ratings yet
- QUALITATIVE DATA Are Measurements For Which There Is No NaturalDocument9 pagesQUALITATIVE DATA Are Measurements For Which There Is No NaturalMarcelaMorenoNo ratings yet
- Chapter 08 Statistics 2Document47 pagesChapter 08 Statistics 2aymanNo ratings yet
- MeanDocument7 pagesMeanRavi SharmaNo ratings yet
- Stats Week 1 PDFDocument6 pagesStats Week 1 PDFAnonymous n0S2m9sR1ENo ratings yet
- Statistics - Describing Data NumericalDocument56 pagesStatistics - Describing Data NumericalDr Rushen SinghNo ratings yet
- MatematikDocument26 pagesMatematikMuhd Hilmi AkhirNo ratings yet
- Frequency Table: Descriptive StatisticsDocument27 pagesFrequency Table: Descriptive StatisticsStacy JonesNo ratings yet
- Apunts BLOC 1 EstadísticaDocument15 pagesApunts BLOC 1 EstadísticaMayssae EssabbarNo ratings yet
- The Idiomatic Programmer - Statistics PrimerDocument44 pagesThe Idiomatic Programmer - Statistics PrimerssignnNo ratings yet
- BDA 09 Shridhti TiwariDocument12 pagesBDA 09 Shridhti TiwariShrishti TiwariNo ratings yet
- Statistical Machine LearningDocument12 pagesStatistical Machine LearningDeva Hema100% (1)
- Math Terms (Junior High)Document2 pagesMath Terms (Junior High)Brian BlackwellNo ratings yet
- Unit3-Data ScienceDocument37 pagesUnit3-Data ScienceDIVYANSH GAUR (RA2011027010090)No ratings yet
- Chapter 3 Numerical Descriptive Measures: 3.1 Measures of Central Tendency For Ungrouped DataDocument14 pagesChapter 3 Numerical Descriptive Measures: 3.1 Measures of Central Tendency For Ungrouped DataKhay OngNo ratings yet
- Descriptive StatisticsDocument7 pagesDescriptive StatisticsShane LiwagNo ratings yet
- Bio Statistics 3Document13 pagesBio Statistics 3Moos LightNo ratings yet
- Statistics Lecture Grouped DataDocument11 pagesStatistics Lecture Grouped DataMary Roxanne AngelesNo ratings yet
- Bda 09 Nidhi YadavDocument12 pagesBda 09 Nidhi YadavShrishti TiwariNo ratings yet
- BIOSTATISTICSDocument14 pagesBIOSTATISTICSSuhail KhanNo ratings yet
- Stats 3Document12 pagesStats 3Marianne Christie RagayNo ratings yet
- Project Management Methodology-Batch - 17082020-7AMDocument81 pagesProject Management Methodology-Batch - 17082020-7AMram DinduNo ratings yet
- Probability and Statistics For Computer Scientists Second Edition, By: Michael BaronDocument63 pagesProbability and Statistics For Computer Scientists Second Edition, By: Michael BaronVall GyiNo ratings yet
- Ecotrix With R and PythonDocument25 pagesEcotrix With R and PythonzuhanshaikNo ratings yet
- DM015SM P-IDocument15 pagesDM015SM P-IAnanya TyagiNo ratings yet
- DWDM Unit-2Document20 pagesDWDM Unit-2CS BCANo ratings yet
- MeanDocument4 pagesMeanSteward john Dela cruzNo ratings yet
- Arithmetic MeanDocument3 pagesArithmetic MeanChoi Ko DohNo ratings yet
- Evans Analytics2e PPT 04 RevisedDocument51 pagesEvans Analytics2e PPT 04 RevisedNur SabrinaNo ratings yet
- Introduction To Business Statistics Through R Software: SoftwareFrom EverandIntroduction To Business Statistics Through R Software: SoftwareNo ratings yet
- Vlsi NotesDocument9 pagesVlsi NotesVipin RajputNo ratings yet
- NumericalsDocument3 pagesNumericalsVipin RajputNo ratings yet
- Binary SearchDocument6 pagesBinary SearchVipin RajputNo ratings yet
- K-Means Clustering AlgorithmDocument17 pagesK-Means Clustering AlgorithmVipin RajputNo ratings yet
- Chapter Four: Conditional Probability and IndependenceDocument8 pagesChapter Four: Conditional Probability and IndependenceOnetwothree Tube0% (2)
- Bits F464 1339 T1M 2017 1Document1 pageBits F464 1339 T1M 2017 1ashishNo ratings yet
- Statistical Fallacies and Errors in Medical ResearchDocument41 pagesStatistical Fallacies and Errors in Medical ResearchMuhammad IrfanNo ratings yet
- Chapter 2: Probability: Course Name: Probability & StatisticsDocument95 pagesChapter 2: Probability: Course Name: Probability & StatisticsThiên IceNo ratings yet
- PPT05-Quantifying UncertaintyDocument39 pagesPPT05-Quantifying UncertaintyVeri VeriNo ratings yet
- PDF Best Explanations New Essays On Inference To The Best Explanation Kevin Mccain and Ted Poston Eds Ebook Full ChapterDocument53 pagesPDF Best Explanations New Essays On Inference To The Best Explanation Kevin Mccain and Ted Poston Eds Ebook Full Chapterjessica.briggs792100% (2)
- Jupyter Notebook ViewerDocument32 pagesJupyter Notebook ViewerThomas Amleth BottiniNo ratings yet
- Basic Business Statistics: 12 EditionDocument41 pagesBasic Business Statistics: 12 EditionMuhammad AfzalNo ratings yet
- Ai PrinciplesDocument29 pagesAi PrinciplesKalpana MrcetNo ratings yet
- Statistical Reasoning: Dr. Anjali DiwanDocument64 pagesStatistical Reasoning: Dr. Anjali DiwanPaulos KNo ratings yet
- Expert Systems TutorialDocument8 pagesExpert Systems TutorialKuganeswara Sarma AatithanNo ratings yet
- Soil Dynamics and Earthquake Engineering: Shima Taheri, Reza Karami MohammadiDocument20 pagesSoil Dynamics and Earthquake Engineering: Shima Taheri, Reza Karami MohammadiSumit SahaNo ratings yet
- Practice For Homework 2: QuestionsDocument8 pagesPractice For Homework 2: QuestionsGurjar DevyaniNo ratings yet
- Fundamentals of Business Statistics: 6E John LoucksDocument63 pagesFundamentals of Business Statistics: 6E John LoucksHafsah Ahmad najibNo ratings yet
- Chapter 1 The Basics of Bayesian Statistics - An Introduction To Bayesian ThinkingDocument17 pagesChapter 1 The Basics of Bayesian Statistics - An Introduction To Bayesian Thinkingmrs dosadoNo ratings yet
- Chapter 5 - Uncertain Knowledge and ReasoningDocument29 pagesChapter 5 - Uncertain Knowledge and ReasoningsomsonengdaNo ratings yet
- Bpa12303 Week2 28probability 291Document36 pagesBpa12303 Week2 28probability 291Nur MaishaNo ratings yet
- DM-Model Question Paper SolutionsDocument27 pagesDM-Model Question Paper Solutionscsumant94No ratings yet
- Unit IV Uncertain Knowledge and Decision TheoryDocument54 pagesUnit IV Uncertain Knowledge and Decision TheoryPallavi BhartiNo ratings yet
- Chapter Two: 2. Conditional Probability and IndependenceDocument6 pagesChapter Two: 2. Conditional Probability and IndependenceTewodros Alemu LoveNo ratings yet
- Bayesian Statistics and ModellingDocument28 pagesBayesian Statistics and Modellingmainking2003No ratings yet
- Probability QTHDocument115 pagesProbability QTHNidhi MatlaniNo ratings yet
- Lecture No.4Document13 pagesLecture No.4m.sheraz malikNo ratings yet
- Bayesian Theory: By: Khaliq BeroDocument15 pagesBayesian Theory: By: Khaliq BeroMr KhaliqNo ratings yet
- AL3391 AI UNIT 5 NOTES EduEnggDocument26 pagesAL3391 AI UNIT 5 NOTES EduEnggKarthik king K100% (1)
- Quantitative Methods For Business 13th Edition Anderson Sweeney Williams Camm Cochran Fry Ohlmann Solution ManualDocument16 pagesQuantitative Methods For Business 13th Edition Anderson Sweeney Williams Camm Cochran Fry Ohlmann Solution Manualrichard100% (27)
- Gandhinagar Institute of Technology: B.E. Sem 8 Computer Engineering DepartmentDocument10 pagesGandhinagar Institute of Technology: B.E. Sem 8 Computer Engineering Departmentbhavya parikhNo ratings yet
- Bayesian Theory and Methods With ApplicationsDocument327 pagesBayesian Theory and Methods With ApplicationsDavid Arteaga100% (2)
- Managerial Decisions Under UncertaintyDocument29 pagesManagerial Decisions Under UncertaintykiNo ratings yet
- Unit Iii ClassificationDocument57 pagesUnit Iii ClassificationarshuyasNo ratings yet