Download as pdf or txt
You might also like
- Etextbook PDF For Introductory Statistics Exploring The World Through Data 2ndDocument61 pagesEtextbook PDF For Introductory Statistics Exploring The World Through Data 2ndbeverly.bustos487100% (50)
- Analysis: User Profiles Personae ScenariosDocument32 pagesAnalysis: User Profiles Personae ScenariosSalmanNo ratings yet
- Final Project Report Pizza HutDocument11 pagesFinal Project Report Pizza HutayazsandeeloNo ratings yet
- A Literature Survery On Infromation Reterival in Web Based DataDocument8 pagesA Literature Survery On Infromation Reterival in Web Based DataInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Relevance Feedback in Information Retrieval Systems: October 2017Document4 pagesRelevance Feedback in Information Retrieval Systems: October 2017Eggg RrrrNo ratings yet
- Rocchio RelevanceDocument10 pagesRocchio RelevanceOmar El MidaouiNo ratings yet
- Automatic Query Expansion Using Word Embedding Based On Fuzzy Graph Connectivity MeasuresDocument14 pagesAutomatic Query Expansion Using Word Embedding Based On Fuzzy Graph Connectivity MeasuresEditor IJTSRDNo ratings yet
- Achieving High Recall and Precision With HTLM Documents: An Innovation Approach in Information RetrievalDocument6 pagesAchieving High Recall and Precision With HTLM Documents: An Innovation Approach in Information RetrievalBhuvana SakthiNo ratings yet
- A Survey On Interactive Video Retrieval Using Active Learning ApproachDocument3 pagesA Survey On Interactive Video Retrieval Using Active Learning ApproachseventhsensegroupNo ratings yet
- 2512ijdkp04 With Cover Page v2Document10 pages2512ijdkp04 With Cover Page v2QUAN HWNo ratings yet
- Information Retrieval From Scientific Abstract and Citation Database Query by Documents Approach Based On Monte Carlo SamplingDocument9 pagesInformation Retrieval From Scientific Abstract and Citation Database Query by Documents Approach Based On Monte Carlo SamplingVorVloNo ratings yet
- Predicting Sample Size Required For Classification PerformanceDocument10 pagesPredicting Sample Size Required For Classification PerformanceNelsonNwaucheNo ratings yet
- Chapter 3Document14 pagesChapter 3ManziniLeeNo ratings yet
- Part 4Document4 pagesPart 4api-235858110No ratings yet
- Chapter 03Document10 pagesChapter 03engr.shahzaibashfaqNo ratings yet
- International Journal of Engineering and Science Invention (IJESI)Document6 pagesInternational Journal of Engineering and Science Invention (IJESI)inventionjournalsNo ratings yet
- Vocabulary Mismatch Avoidance Techniques: AbstractDocument10 pagesVocabulary Mismatch Avoidance Techniques: AbstractsivakumarNo ratings yet
- Deep Learning Rs ChallengesDocument37 pagesDeep Learning Rs ChallengesDinah AnyangoNo ratings yet
- Big Data Mining Literature ReviewDocument7 pagesBig Data Mining Literature Reviewea884b2k100% (1)
- Chapter Three Cloud Computing Adoption For CorrectionDocument19 pagesChapter Three Cloud Computing Adoption For CorrectionMbereobongNo ratings yet
- Rijul Research PaperDocument9 pagesRijul Research PaperRijul ChauhanNo ratings yet
- Ranking MetricsDocument15 pagesRanking MetricsrobertsharklasersNo ratings yet
- Research Design Chapter 3 ThesisDocument7 pagesResearch Design Chapter 3 Thesisaflpaftaofqtoa100% (1)
- Strathprints Institutional Repository: Strathprints - Strath.ac - UkDocument10 pagesStrathprints Institutional Repository: Strathprints - Strath.ac - UkVINCENT REFORMANo ratings yet
- Accuracies and Training Times of Data Mining Classification Algorithms: An Empirical Comparative StudyDocument8 pagesAccuracies and Training Times of Data Mining Classification Algorithms: An Empirical Comparative StudyQaisar HussainNo ratings yet
- Patterns of Query Reformulation DuringWeb SearchingDocument14 pagesPatterns of Query Reformulation DuringWeb Searchingmic_iamNo ratings yet
- Object Oriented Implementation of Concept-Based User Profiles From Search Engine LogsDocument5 pagesObject Oriented Implementation of Concept-Based User Profiles From Search Engine LogsG Appa RaoNo ratings yet
- Thesis Chapter 3 Methods and ProcedureDocument7 pagesThesis Chapter 3 Methods and ProcedureCustomCollegePaperCanada100% (2)
- Document 24Document8 pagesDocument 24Maryam MohamedNo ratings yet
- Contextual Information Search Based On Domain Using Query ExpansionDocument4 pagesContextual Information Search Based On Domain Using Query ExpansionInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Anomaly Detection Via Eliminating Data Redundancy and Rectifying Data Error in Uncertain Data StreamsDocument18 pagesAnomaly Detection Via Eliminating Data Redundancy and Rectifying Data Error in Uncertain Data StreamsAnonymous OT4vepNo ratings yet
- Soa WebirDocument29 pagesSoa WebirDersoNo ratings yet
- 522 EditedcoverartifactDocument2 pages522 Editedcoverartifactapi-285466724No ratings yet
- Performance and Feedback AnalyzerDocument6 pagesPerformance and Feedback AnalyzerIJRASETPublicationsNo ratings yet
- Effective Semi-Supervised Document Clustering Via Active Learning With Instance-Level ConstraintsDocument19 pagesEffective Semi-Supervised Document Clustering Via Active Learning With Instance-Level ConstraintsShih MargaritaNo ratings yet
- Materialized View Generation Using Apriori AlgorithmDocument11 pagesMaterialized View Generation Using Apriori AlgorithmMaurice LeeNo ratings yet
- Role of 360-Degree Feedback From An Employee Perspective at British Petroleum, Cranford.Document38 pagesRole of 360-Degree Feedback From An Employee Perspective at British Petroleum, Cranford.Anthony GeorgeNo ratings yet
- Chapter 3 Thesis PhilippinesDocument5 pagesChapter 3 Thesis PhilippinesWriteMyStatisticsPaperUK100% (3)
- Thesis Chapter 3 Sample PhilippinesDocument8 pagesThesis Chapter 3 Sample Philippinesaparnaharrisonstamford100% (1)
- Student Performance Prediction and Analysis: IjarcceDocument4 pagesStudent Performance Prediction and Analysis: Ijarcceshital shermaleNo ratings yet
- Components Analysis Examination For Identifying Stronger Variables Related To Users' Satisfaction in Research Data Management Systems of Subject-Related Libraries in Colombo District, Sri LankaDocument15 pagesComponents Analysis Examination For Identifying Stronger Variables Related To Users' Satisfaction in Research Data Management Systems of Subject-Related Libraries in Colombo District, Sri LankaCentral Asian StudiesNo ratings yet
- MethodologyDocument4 pagesMethodologyRAHEEL AKHTARNo ratings yet
- 02 - Klyuev - A Query Expansion Technique Using The EWC SeDocument6 pages02 - Klyuev - A Query Expansion Technique Using The EWC SeparagdaveNo ratings yet
- Decision Trees For Handling Uncertain Data To Identify Bank FraudsDocument4 pagesDecision Trees For Handling Uncertain Data To Identify Bank FraudsWARSE JournalsNo ratings yet
- Qualitative Research in Software EngineeringDocument8 pagesQualitative Research in Software EngineeringGuillermo MotaNo ratings yet
- Pso Entrnamiento Redes BayesianasDocument6 pagesPso Entrnamiento Redes BayesianasPia EscarateNo ratings yet
- Wang 2007Document6 pagesWang 2007amine332No ratings yet
- Performance Evaluation of Query Processing Techniques in Information RetrievalDocument6 pagesPerformance Evaluation of Query Processing Techniques in Information RetrievalidescitationNo ratings yet
- Recommendation System With Automated Web Usage Data Mining by Using K-Nearest Neighbour (KNN) Classification and Artificial Neural Network (ANN) AlgorithmDocument9 pagesRecommendation System With Automated Web Usage Data Mining by Using K-Nearest Neighbour (KNN) Classification and Artificial Neural Network (ANN) AlgorithmIJRASETPublicationsNo ratings yet
- Binary Ebola Optimization Search Algorithm For Feature Selection and Classification ProblemsDocument46 pagesBinary Ebola Optimization Search Algorithm For Feature Selection and Classification ProblemsMustafa BAYSALNo ratings yet
- Disengagement Detection in Online Learning Using Quasi FrameworkDocument6 pagesDisengagement Detection in Online Learning Using Quasi FrameworkIOSRJEN : hard copy, certificates, Call for Papers 2013, publishing of journalNo ratings yet
- Using ID3 Decision Tree Algorithm To The Student Grade Analysis and PredictionDocument4 pagesUsing ID3 Decision Tree Algorithm To The Student Grade Analysis and PredictionEditor IJTSRDNo ratings yet
- Literature Review On Data Mining PDFDocument5 pagesLiterature Review On Data Mining PDFfvgr8hna100% (1)
- Exploring Representativeness and Informativeness For Active LearnDocument14 pagesExploring Representativeness and Informativeness For Active LearnelmannaiNo ratings yet
- Full Download PDF of (Ebook PDF) Introductory Statistics Exploring The World Through Data 2nd All ChapterDocument43 pagesFull Download PDF of (Ebook PDF) Introductory Statistics Exploring The World Through Data 2nd All Chapterloardikerro100% (7)
- Java Datamining IEEE Projects 2012 at Seabirds (Chennai, Trichy, Pudukkottai, Thanjavur, Perambalur, Karur)Document9 pagesJava Datamining IEEE Projects 2012 at Seabirds (Chennai, Trichy, Pudukkottai, Thanjavur, Perambalur, Karur)sathish20059No ratings yet
- State of The Art Document Clustering Algorithms Based On Semantic SimilarityDocument18 pagesState of The Art Document Clustering Algorithms Based On Semantic SimilarityAna ArianiNo ratings yet
- Modern Research Design: The Best Approach To Qualitative And Quantitative DataFrom EverandModern Research Design: The Best Approach To Qualitative And Quantitative DataNo ratings yet
- Towards best practice in the Archetype Development ProcessFrom EverandTowards best practice in the Archetype Development ProcessNo ratings yet
- An Investigation into the Use of a Neural Tree Classifier for Knowledge Discovery in OLAP DatabasesFrom EverandAn Investigation into the Use of a Neural Tree Classifier for Knowledge Discovery in OLAP DatabasesNo ratings yet
- Implementing the Stakeholder Based Goal-Question-Metric (Gqm) Measurement Model for Software ProjectsFrom EverandImplementing the Stakeholder Based Goal-Question-Metric (Gqm) Measurement Model for Software ProjectsNo ratings yet
- Introducing The Balanced Scorecard - Creating Metrics To Measure PDocument16 pagesIntroducing The Balanced Scorecard - Creating Metrics To Measure PEyobNo ratings yet
- Tijbm, BM2001-019Document7 pagesTijbm, BM2001-019EyobNo ratings yet
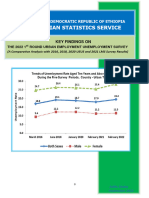
- 2022 - 1st Round UEUS Key FindingsDocument17 pages2022 - 1st Round UEUS Key FindingsEyobNo ratings yet
- SCW4 Curriculum Level IV V2Document48 pagesSCW4 Curriculum Level IV V2EyobNo ratings yet
- TTLM 02. Arranging Building Applications and ApprovalsDocument44 pagesTTLM 02. Arranging Building Applications and ApprovalsEyobNo ratings yet
- Article Review AssignmentDocument16 pagesArticle Review AssignmentEyobNo ratings yet
- Cloud Computing and Its ApplicationsDocument6 pagesCloud Computing and Its ApplicationsKavinhariharasudhan SankaralingamNo ratings yet
- E Book Drones in Mining and AggregatesDocument23 pagesE Book Drones in Mining and Aggregatesrizqi auliaNo ratings yet
- Common StatisticsDocument23 pagesCommon StatisticsJeffNo ratings yet
- Digital Pressure Gauges Additel 681: Pressure Ranges To 60,000 Psi (4,200 Bar)Document4 pagesDigital Pressure Gauges Additel 681: Pressure Ranges To 60,000 Psi (4,200 Bar)BrigitteNo ratings yet
- Take Home ExamDocument9 pagesTake Home ExamAris SantosNo ratings yet
- Amrita School of Engineering, Bengaluru Campus: End Semester Exam-August 2021Document1 pageAmrita School of Engineering, Bengaluru Campus: End Semester Exam-August 2021TejaNo ratings yet
- FM Read - TextDocument3 pagesFM Read - Textedmondo77No ratings yet
- TK228 User Manual V2.0 - 201602Document21 pagesTK228 User Manual V2.0 - 201602BTM Mosti100% (1)
- Biocomputers: Biochemical ComputersDocument3 pagesBiocomputers: Biochemical ComputersAjinkyaJadNo ratings yet
- 4 ESO Academics - Unit 01 - Exercises 1.2.Document10 pages4 ESO Academics - Unit 01 - Exercises 1.2.GoheimNo ratings yet
- Electrical Price ListDocument19 pagesElectrical Price ListCheftaimoor KhanNo ratings yet
- IB OverviewDocument11 pagesIB OverviewGopalakrishna DevulapalliNo ratings yet
- GSM Based Water Management in Irrigation System Using ARM7: N.D. Pergad, Y.P. PatilDocument3 pagesGSM Based Water Management in Irrigation System Using ARM7: N.D. Pergad, Y.P. PatilmeenachiNo ratings yet
- Touchscreen Technology PPT by Pavan Kumar M.T.Document24 pagesTouchscreen Technology PPT by Pavan Kumar M.T.pavankumarmt91% (11)
- Jclplus BrochureDocument4 pagesJclplus BrochureAbdul SubhanNo ratings yet
- Reengineering and Case ToolsDocument24 pagesReengineering and Case ToolsShruthi SrinivasanNo ratings yet
- Letter To PMO On Passport PortalDocument4 pagesLetter To PMO On Passport PortalMld OnnetNo ratings yet
- Surjeet Singh: ProfessionalDocument3 pagesSurjeet Singh: ProfessionalGracefulldudeNo ratings yet
- GURO21 Course 1 Module 1Document231 pagesGURO21 Course 1 Module 1Cyril Coscos83% (6)
- SQL Server Interview QuestionsDocument14 pagesSQL Server Interview QuestionschandrasekarNo ratings yet
- Session 2 Sensors - TransducerDocument106 pagesSession 2 Sensors - TransducerJenny JadhavNo ratings yet
- Distributed Operating Systems: Unit - 2Document48 pagesDistributed Operating Systems: Unit - 2eyasuNo ratings yet
- Pipe Flange and Gaskets BasicsDocument3 pagesPipe Flange and Gaskets BasicsEhab AbowardaNo ratings yet
- Markov ChainDocument7 pagesMarkov Chainshanigondal126No ratings yet
- Control SystemsDocument161 pagesControl SystemsDr. Gollapalli NareshNo ratings yet
- Consent FormDocument1 pageConsent FormDaniel NeillNo ratings yet
- Interscan Web Security Virtual Appliance 5.1Document168 pagesInterscan Web Security Virtual Appliance 5.1Sumit RoyNo ratings yet
- Tachometer and Speedometer Wiring DiagramDocument6 pagesTachometer and Speedometer Wiring Diagrammohamed A.abdeltwabNo ratings yet