Download as pdf or txt
You might also like
- Ethics For Engineers by Martin Peterson Full ChapterDocument41 pagesEthics For Engineers by Martin Peterson Full Chapterashley.torres627100% (26)
- ShakeDocument4 pagesShakesafak100% (3)
- Brain Tumour DetectionDocument41 pagesBrain Tumour DetectionSruthi ReddyNo ratings yet
- Assignment No 2 (Aleeza Anjum CS101)Document60 pagesAssignment No 2 (Aleeza Anjum CS101)Aleeza AnjumNo ratings yet
- DCGAN (Deep Convolution Generative Adversarial Networks)Document27 pagesDCGAN (Deep Convolution Generative Adversarial Networks)lakpa tamangNo ratings yet
- Lecture 4Document22 pagesLecture 4aly869556No ratings yet
- GAN ReportDocument24 pagesGAN ReportsenthilnathanNo ratings yet
- East West Institute of Technology: An Improved Approach For Fire Detection Using Deep Learning ModelsDocument21 pagesEast West Institute of Technology: An Improved Approach For Fire Detection Using Deep Learning ModelsDeepuNo ratings yet
- Classification Using Deep Learning NetworksDocument27 pagesClassification Using Deep Learning NetworksWaheed NangigaddaNo ratings yet
- Technical Seminar (Wildfire)Document16 pagesTechnical Seminar (Wildfire)insightsunveiledofficialNo ratings yet
- An Efficient CNN Accelerator Using Inter-Frame Data Reuse of Videos On FPGAsDocument14 pagesAn Efficient CNN Accelerator Using Inter-Frame Data Reuse of Videos On FPGAspalansamyNo ratings yet
- Zamir 2022 Mirnetv2Document15 pagesZamir 2022 Mirnetv2navya.cogni21No ratings yet
- DC GAN SummaryDocument1 pageDC GAN SummaryVaibhav YengulNo ratings yet
- ML Lab Session 06 - VGG16-CNNDocument15 pagesML Lab Session 06 - VGG16-CNNchatgptlogin2001No ratings yet
- DCNN AlgorithmsDocument4 pagesDCNN AlgorithmsMahalakshmi GNo ratings yet
- A Deep Neural Network For Image Quality AssessmentDocument5 pagesA Deep Neural Network For Image Quality Assessmentgitov13916No ratings yet
- DarkLensLuminaNet ConferenceDocument8 pagesDarkLensLuminaNet ConferenceMohd HuzaifaNo ratings yet
- Fire DetectionDocument20 pagesFire DetectionB G Sumith KumarNo ratings yet
- A - GNN - Architecture - With - Local - and - Global-Attention - Feature - For - Image - Classification 2Document13 pagesA - GNN - Architecture - With - Local - and - Global-Attention - Feature - For - Image - Classification 2Mustafa Mohammadi GharasuieNo ratings yet
- Efficient Spatially Sparse Inference For Conditional Gans and Diffusion ModelsDocument22 pagesEfficient Spatially Sparse Inference For Conditional Gans and Diffusion Models20135A0504 CHAVAKULA VIJAYA RAMA KRISHNANo ratings yet
- Scalable Neural NetworkDocument31 pagesScalable Neural Networkaryandeo2011No ratings yet
- 896 2676 1 PBDocument11 pages896 2676 1 PBDeva Nupita SariNo ratings yet
- Knowledge Transfer in CNN Networks For Image ClassificationDocument22 pagesKnowledge Transfer in CNN Networks For Image ClassificationAbenezer bediluNo ratings yet
- Typical CNN (Convolutional Neural Network) Architecture: CHARAN S (1VE20CA005) Cse-Ai, SvceDocument13 pagesTypical CNN (Convolutional Neural Network) Architecture: CHARAN S (1VE20CA005) Cse-Ai, Svcecharan.s2702No ratings yet
- Generative - Adversarial - Networks - For - Extreme - Learned - Image - CompressionDocument11 pagesGenerative - Adversarial - Networks - For - Extreme - Learned - Image - CompressionThe ProphecyNo ratings yet
- Cvpr23 - Scaling Up GANs For Text-To-Image SynthesisDocument35 pagesCvpr23 - Scaling Up GANs For Text-To-Image SynthesisitomixyzkiNo ratings yet
- JournalPaper ASC UpdatedDocument16 pagesJournalPaper ASC UpdatedAdeeba AliNo ratings yet
- G H F I S P N M U: Enerating IGH Idelity Mages With Ubscale Ixel Etworks AND Ultidimensional PscalingDocument14 pagesG H F I S P N M U: Enerating IGH Idelity Mages With Ubscale Ixel Etworks AND Ultidimensional PscalingyyscribdNo ratings yet
- A Rotation-Invariant Convolutional Neural Network For ImageDocument5 pagesA Rotation-Invariant Convolutional Neural Network For ImageMohammad WaleedNo ratings yet
- Image Classification: CNN ModelDocument2 pagesImage Classification: CNN ModelEdyoucate Tuition CentreNo ratings yet
- DNN ArchitecturesDocument12 pagesDNN Architecturesshreyagoudar06No ratings yet
- GN-CNN: A Point Cloud Analysis Method For Metaverse ApplicationsDocument16 pagesGN-CNN: A Point Cloud Analysis Method For Metaverse ApplicationszhujianzhaiNo ratings yet
- Semantic Segmentation Via Highly Fused Convolutional Network With Multiple Soft Cost FunctionsDocument16 pagesSemantic Segmentation Via Highly Fused Convolutional Network With Multiple Soft Cost FunctionsV.R.S.MANINo ratings yet
- GANpptDocument34 pagesGANpptSreejith PBNo ratings yet
- Lec 11Document20 pagesLec 11BasantNo ratings yet
- Image Compression and Decompression Using AnnDocument25 pagesImage Compression and Decompression Using Annpallavi_subbaiah0% (1)
- Aidl 2023s DL 08 CNN ArchitecturesDocument51 pagesAidl 2023s DL 08 CNN ArchitecturesOuriNo ratings yet
- TP3 Mi204 Santos ScardellatoDocument20 pagesTP3 Mi204 Santos ScardellatoDoente PedroNo ratings yet
- Boosting Monocular Depth Estimation Models To High-Resolution Via Content-Adaptive Multi-Resolution CVPR 2021 PaperDocument10 pagesBoosting Monocular Depth Estimation Models To High-Resolution Via Content-Adaptive Multi-Resolution CVPR 2021 Paper徐啸宇No ratings yet
- InceptionDocument56 pagesInceptionPriti SharmaNo ratings yet
- Research Paper (SummaryDocument6 pagesResearch Paper (SummarySUBHASH ENG21CS0418No ratings yet
- Fixing The Train-Test Resolution DiscrepancyDocument14 pagesFixing The Train-Test Resolution DiscrepancyHECTOR FABRIZIO CALDERON HERRERANo ratings yet
- GNNChap 6Document27 pagesGNNChap 6Shahin4220No ratings yet
- Convolutional Neural Networks For No-Reference Image Quality AssessmentDocument8 pagesConvolutional Neural Networks For No-Reference Image Quality Assessmentgitov13916No ratings yet
- Deep Monocular Depth Estimation Via Integration of Global and Local PredictionsDocument2 pagesDeep Monocular Depth Estimation Via Integration of Global and Local Predictionsbvkarthik2711No ratings yet
- Denoising Pretraining For Semantic SegmentationDocument12 pagesDenoising Pretraining For Semantic SegmentationYe DuNo ratings yet
- Generative Adversarial Networks For Data Generation and Damage Detection Using Resnet in Structural Health MonitoringDocument25 pagesGenerative Adversarial Networks For Data Generation and Damage Detection Using Resnet in Structural Health MonitoringBhavana BollarapuNo ratings yet
- Gender Classification Using Convolutional Neural Networks: J Component - Project ReportDocument36 pagesGender Classification Using Convolutional Neural Networks: J Component - Project ReportSanjay NithinNo ratings yet
- Advanced Single Image Resolution Upsurging Using A Generative Adversarial NetworkDocument10 pagesAdvanced Single Image Resolution Upsurging Using A Generative Adversarial NetworksipijNo ratings yet
- Data Aug TransDocument4 pagesData Aug Transmavoho1719No ratings yet
- Computer Vision NN ArchitectureDocument19 pagesComputer Vision NN ArchitecturePrasu MuthyalapatiNo ratings yet
- EfficientNet TutorialDocument20 pagesEfficientNet TutorialTsigabuNo ratings yet
- GANs and Types of GAN'sDocument2 pagesGANs and Types of GAN'sSanjaya Kumar KhadangaNo ratings yet
- Application of PCA-CNN (Principal Component Analysis - Convolutional Neural Networks) Method On Sentinel-2 Image Classification For Land Cover MappingDocument5 pagesApplication of PCA-CNN (Principal Component Analysis - Convolutional Neural Networks) Method On Sentinel-2 Image Classification For Land Cover MappingIJAERS JOURNALNo ratings yet
- Effect of Data-Augmentation On Fine-Tuned CNN Model PerformanceDocument9 pagesEffect of Data-Augmentation On Fine-Tuned CNN Model PerformanceIAES IJAINo ratings yet
- Align: A Highly Accurate Adaptive Layerwise Log - 2 - Lead Quantization of Pre-Trained Neural NetworksDocument13 pagesAlign: A Highly Accurate Adaptive Layerwise Log - 2 - Lead Quantization of Pre-Trained Neural NetworksHarsh Mittal-36No ratings yet
- DL Anonymous Question BankDocument22 pagesDL Anonymous Question BankAnuradha PiseNo ratings yet
- Le y Yang - Tiny ImageNet Visual Recognition ChallengeDocument6 pagesLe y Yang - Tiny ImageNet Visual Recognition Challengemusicalización pacíficoNo ratings yet
- ML II - Unit IVDocument20 pagesML II - Unit IVPARTHNo ratings yet
- How To Train Your Pre Trained GAN Models: Sung Wook Park Jun Yeong Kim Jun Park Se Hoon Jung Chun Bo SimDocument26 pagesHow To Train Your Pre Trained GAN Models: Sung Wook Park Jun Yeong Kim Jun Park Se Hoon Jung Chun Bo Simahmed.mohammedNo ratings yet
- A Deep Learning Based No-Reference Image Quality Assessment Model For Single-Image Super-ResolutionDocument5 pagesA Deep Learning Based No-Reference Image Quality Assessment Model For Single-Image Super-Resolutiongitov13916No ratings yet
- MPDFDocument3 pagesMPDFmandaashok1615No ratings yet
- Fin Irjmets1671702694Document4 pagesFin Irjmets1671702694mandaashok1615No ratings yet
- Btech 11 Midpostpone 3-11-23Document1 pageBtech 11 Midpostpone 3-11-23mandaashok1615No ratings yet
- Covering Letter For Asst Prof NaikDocument4 pagesCovering Letter For Asst Prof Naikmandaashok1615No ratings yet
- Head Bolts & Nuts Size 12 X 45 MM 11.06.24Document4 pagesHead Bolts & Nuts Size 12 X 45 MM 11.06.24luv.wadhwa001No ratings yet
- 6th Grade Worksheet With Reading ComprehensionDocument3 pages6th Grade Worksheet With Reading ComprehensionEce GungorenNo ratings yet
- Why The Hero PlatformDocument6 pagesWhy The Hero PlatformRolazski123No ratings yet
- Victoria M Esses Lisa Bitacola Reference Letter 2Document1 pageVictoria M Esses Lisa Bitacola Reference Letter 2api-243019491No ratings yet
- EL - 124 Electronic Devices & Circuits: Experiment # 04Document6 pagesEL - 124 Electronic Devices & Circuits: Experiment # 04Jawwad IqbalNo ratings yet
- LLaVA MEDDocument17 pagesLLaVA MED권오민 / 학생 / 전기·정보공학부No ratings yet
- CNS - Module 2.1-AESDocument17 pagesCNS - Module 2.1-AESNIKSHITH SHETTYNo ratings yet
- Installation, Operation and Maintenance Instructions: Model 3600 API 610 10th Edition (ISO 13709)Document92 pagesInstallation, Operation and Maintenance Instructions: Model 3600 API 610 10th Edition (ISO 13709)José Fernando TerronesNo ratings yet
- Medium Voltage Products and Equipment - Australian Catalogue 2015Document112 pagesMedium Voltage Products and Equipment - Australian Catalogue 2015Dariush JavanNo ratings yet
- Chapter 5. Regression Models: 1 A Simple ModelDocument49 pagesChapter 5. Regression Models: 1 A Simple ModelPiNo ratings yet
- K3HB-H: Model Number StructureDocument15 pagesK3HB-H: Model Number StructureGustaf Aurellio PanelNo ratings yet
- VM651, Pi-2555Document8 pagesVM651, Pi-2555Carlos Rubén Oliveras RodríguezNo ratings yet
- RESPIRATION IN PLANTS DPP by Seep PahujaDocument4 pagesRESPIRATION IN PLANTS DPP by Seep Pahujamaheshgutam8756No ratings yet
- Structure AnswersDocument7 pagesStructure Answersbunshin AAANo ratings yet
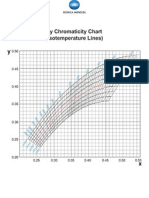
- Correlated Color Temperature With Iso Temperature Curves - A1 SizeDocument1 pageCorrelated Color Temperature With Iso Temperature Curves - A1 SizeKonica Minolta Sensing Singapore Pte LtdNo ratings yet
- Patent Agent Exam Preparation Training CourseDocument3 pagesPatent Agent Exam Preparation Training CourseGlobal Institute of Intellectual PropertyNo ratings yet
- Full Download Retailing Management Levy 9th Edition Solutions Manual PDF Full ChapterDocument36 pagesFull Download Retailing Management Levy 9th Edition Solutions Manual PDF Full Chapterbeastlyfulberj6gkg100% (20)
- Space: What Is This Topic About?Document34 pagesSpace: What Is This Topic About?CyberbullyNo ratings yet
- Strategic AuditDocument10 pagesStrategic AuditDapoer OmaOpaNo ratings yet
- Q3 Assessment Wk3&4Document3 pagesQ3 Assessment Wk3&4Jaybie TejadaNo ratings yet
- Acsl 16-17 Contest 4 Notes - Graph Theory de AssemblyDocument31 pagesAcsl 16-17 Contest 4 Notes - Graph Theory de Assemblyapi-328824013No ratings yet
- Internship Offer Letter - Software Development - AdarshDocument4 pagesInternship Offer Letter - Software Development - Adarshadd100% (1)
- Bangabazar and ChowkbazarDocument13 pagesBangabazar and Chowkbazarprantosaha602No ratings yet
- Computer Requirements: La NWM InstallationDocument8 pagesComputer Requirements: La NWM InstallationJorge EstradaNo ratings yet
- Lab 3 (Polygon Law of ForcesDocument4 pagesLab 3 (Polygon Law of ForcesMuhammad HuzaifaNo ratings yet
- Proceeding Icgrc 2014Document102 pagesProceeding Icgrc 2014AlexanderKurniawanSariyantoPuteraNo ratings yet
- Tech Spec 8mvaDocument40 pagesTech Spec 8mvachekurivishnu7No ratings yet
- All About Glass BeadsDocument15 pagesAll About Glass BeadsLuciacighir100% (1)