Download as pdf or txt
You might also like
- GRE - Reading ComprehensionDocument207 pagesGRE - Reading ComprehensionAnantjit Singh Sahni100% (10)
- 597 - Correction TD Fonction CirculaireDocument4 pages597 - Correction TD Fonction CirculaireToxic DEVNo ratings yet
- Calculus - A Brief Revision of DifferentiationDocument12 pagesCalculus - A Brief Revision of DifferentiationkhavthompsonNo ratings yet
- Pptintegraldualipat 170512082355Document26 pagesPptintegraldualipat 170512082355Aisyah KhairaniNo ratings yet
- Tarea 1 RICATTIDocument4 pagesTarea 1 RICATTIFernando Estrada CalvilloNo ratings yet
- Mata 33Document37 pagesMata 33Aissatou FallNo ratings yet
- 7.definite Integrals: 1. Fundamental Theorem of Integral CalculusDocument4 pages7.definite Integrals: 1. Fundamental Theorem of Integral Calculuskartikey papnoiNo ratings yet
- UntitledDocument6 pagesUntitledrobertoNo ratings yet
- 04-Regression-III Machine LearningDocument26 pages04-Regression-III Machine LearningAli DonNo ratings yet
- Examples of DerivativesDocument6 pagesExamples of DerivativesHamza HanaBhaiNo ratings yet
- Formulario de Lanzamito Parabolico Eje X Eje Y MRU Mruv: CinemáticaDocument3 pagesFormulario de Lanzamito Parabolico Eje X Eje Y MRU Mruv: CinemáticaLuis IlbayNo ratings yet
- Module 1Document11 pagesModule 1Murali Karthik VNo ratings yet
- ( ) : ( ) ( - ) ( - ) Máxima SimilitudDocument1 page( ) : ( ) ( - ) ( - ) Máxima SimilitudErick XavierNo ratings yet
- DerivadasDocument9 pagesDerivadasl23102000820232No ratings yet
- LectureDocument8 pagesLecturemarNo ratings yet
- Chapter 5 &6 Differentiation &its Applications: Quotient RuleDocument2 pagesChapter 5 &6 Differentiation &its Applications: Quotient RuleRahul SinghNo ratings yet
- Notes - Fourier Series in (-π,π)Document35 pagesNotes - Fourier Series in (-π,π)vu1f2122093No ratings yet
- 焦润一已发表论文1Document5 pages焦润一已发表论文1Runyi JiaoNo ratings yet
- Distribucion de Poisson e Introduccion A Las Distribuciones ContinuasDocument8 pagesDistribucion de Poisson e Introduccion A Las Distribuciones ContinuasAlejandro Hernandez PinedaNo ratings yet
- Differential Equations: Lecture - 8Document13 pagesDifferential Equations: Lecture - 8Talha JavedNo ratings yet
- FE_MM III_List of Formulae-1Document4 pagesFE_MM III_List of Formulae-1bce23020004No ratings yet
- Methods ConnectEd TI-NspireDocument38 pagesMethods ConnectEd TI-Nspiremvz61484No ratings yet
- Integration I Lecture08Document22 pagesIntegration I Lecture08paulkhor74No ratings yet
- Derivadas: Teoremas Básicos para Derivadas 1. ( ), ( ) 0Document2 pagesDerivadas: Teoremas Básicos para Derivadas 1. ( ), ( ) 0Daniela OrtizNo ratings yet
- Lecture 8 BackpropagationDocument28 pagesLecture 8 BackpropagationHodatama Karanna OneNo ratings yet
- G11 Q3 W8 Basic-Calculus 100428Document10 pagesG11 Q3 W8 Basic-Calculus 100428John Paul Luzgano AganapNo ratings yet
- CPE262 - Tutorial 2 - L3 - L4-L5 - 1445-IDocument9 pagesCPE262 - Tutorial 2 - L3 - L4-L5 - 1445-IAhmed SaidNo ratings yet
- Gr11 Physics Formula SheetDocument2 pagesGr11 Physics Formula SheetAndrew NguyenNo ratings yet
- Marín 2024Document195 pagesMarín 2024emiliomarino356No ratings yet
- Lecture Notes On Function Mapping and Limits by Dr. AjijolaDocument11 pagesLecture Notes On Function Mapping and Limits by Dr. AjijolasmartruthieNo ratings yet
- Chapter 6 SolutionsDocument13 pagesChapter 6 Solutionshappy062733No ratings yet
- Please Answer All The Question GivenDocument6 pagesPlease Answer All The Question GivenJessica YeeNo ratings yet
- Calculus (Uni)Document22 pagesCalculus (Uni)PEDRO ARTEAGANo ratings yet
- Mat-130 Day-1Document7 pagesMat-130 Day-1Tahsina TasneemNo ratings yet
- 5 6266826484271284719Document3 pages5 6266826484271284719Bhagvat prasadNo ratings yet
- Notes - Fourier Series in (0,2l)Document20 pagesNotes - Fourier Series in (0,2l)vu1f2122093No ratings yet
- Class 12 Formula in A3Document20 pagesClass 12 Formula in A3Tshering TashiNo ratings yet
- Numerical Analysis: Lecture - 14Document8 pagesNumerical Analysis: Lecture - 14Muhammad AliNo ratings yet
- Worksheet Solution 1Document9 pagesWorksheet Solution 1abdelrahmanhelal13No ratings yet
- Problemario Unidad 2 VectorialDocument2 pagesProblemario Unidad 2 VectorialRobles Ramírez Angel EliasNo ratings yet
- Multivariate Random VariableDocument16 pagesMultivariate Random Variablescribd140778No ratings yet
- Penj El Asan Integral Lipat Dua & Penerapan Pada Momen InersiaDocument26 pagesPenj El Asan Integral Lipat Dua & Penerapan Pada Momen InersiaDevi apNo ratings yet
- BMATE201 - Module 3Document44 pagesBMATE201 - Module 3ashuranpvt79No ratings yet
- Lecture On Derivative of Inverse Trigonometric FunctionsDocument9 pagesLecture On Derivative of Inverse Trigonometric FunctionsG02 - BALACANAO JHERICE A.No ratings yet
- Epreuve Surveillée 2 Maths 2BAC PR Hassan ArssaniDocument1 pageEpreuve Surveillée 2 Maths 2BAC PR Hassan Arssanikaramouharou25No ratings yet
- L2 Integrals PDFDocument2 pagesL2 Integrals PDFRalph Michael CondinoNo ratings yet
- DerivadasDocument7 pagesDerivadasFausto Alejandro Mogrovejo TeneNo ratings yet
- Derivative FormulasDocument3 pagesDerivative FormulasGul sher BalochNo ratings yet
- Solutions - Assignment - No - 4 - EditedDocument13 pagesSolutions - Assignment - No - 4 - EditedJahid HasanNo ratings yet
- Basic Stats Cheat SheetDocument26 pagesBasic Stats Cheat SheetMbusoThabetheNo ratings yet
- Calculo 2.tarea 1Document9 pagesCalculo 2.tarea 1DIANA LEYVA HERNANDEZNo ratings yet
- MATHEMATICS (2) - LecDocument18 pagesMATHEMATICS (2) - LecToka RaafatNo ratings yet
- Grupo 5 - Ev14: Algebra LinealDocument5 pagesGrupo 5 - Ev14: Algebra Linealmario alonso vienaNo ratings yet
- Theory of Approximation and Splines-I Lecture-1 Basic Concepts of InterpolationDocument4 pagesTheory of Approximation and Splines-I Lecture-1 Basic Concepts of InterpolationMusavarah SarwarNo ratings yet
- Super HojaDocument3 pagesSuper HojaWilfriSegundoIzquierdoNo ratings yet
- MATH 223 Advanced Engineering Mathematics W9 To W13 PDFDocument54 pagesMATH 223 Advanced Engineering Mathematics W9 To W13 PDFGreen zolarNo ratings yet
- Newton-Leibnitz Rule & Standard IntegralsDocument4 pagesNewton-Leibnitz Rule & Standard Integralssubhadip1workNo ratings yet
- Inverse Trigonometric Functions (Trigonometry) Mathematics Question BankFrom EverandInverse Trigonometric Functions (Trigonometry) Mathematics Question BankNo ratings yet
- A-level Maths Revision: Cheeky Revision ShortcutsFrom EverandA-level Maths Revision: Cheeky Revision ShortcutsRating: 3.5 out of 5 stars3.5/5 (8)
- Text Completion SampleDocument8 pagesText Completion SampleNadeem ArainNo ratings yet
- 100 GK Crunch: Title: General Knowledge Quiz Questions With AnswersDocument4 pages100 GK Crunch: Title: General Knowledge Quiz Questions With AnswersNadeem ArainNo ratings yet
- KOC Fall-Semester-2021-22 - Nadeem-NadeemDocument24 pagesKOC Fall-Semester-2021-22 - Nadeem-NadeemNadeem ArainNo ratings yet
- Analytical & Logical Reasoning For GATDocument53 pagesAnalytical & Logical Reasoning For GATNadeem ArainNo ratings yet
- FractionsDocument6 pagesFractionsNadeem ArainNo ratings yet
- 6 GK Crunch by Sir MudassirDocument2 pages6 GK Crunch by Sir MudassirNadeem ArainNo ratings yet
- 150 GK Crunch: Title: General Knowledge Quiz Questions - Part 2Document3 pages150 GK Crunch: Title: General Knowledge Quiz Questions - Part 2Nadeem ArainNo ratings yet
- FractionsDocument6 pagesFractionsNadeem ArainNo ratings yet
- Short Question and Answers: The Kingdom FungiDocument9 pagesShort Question and Answers: The Kingdom FungiNadeem ArainNo ratings yet
- Kingdom Plantae: Short Questions and AnswersDocument17 pagesKingdom Plantae: Short Questions and AnswersNadeem ArainNo ratings yet
- The Kingdom Protoctista: Short Question and AnswersDocument5 pagesThe Kingdom Protoctista: Short Question and AnswersNadeem ArainNo ratings yet
- Variety of Life: Short Question AnswersDocument7 pagesVariety of Life: Short Question AnswersNadeem ArainNo ratings yet
- Kingdom Prokaryotae (Monera) : Short Questions AnswersDocument6 pagesKingdom Prokaryotae (Monera) : Short Questions AnswersNadeem ArainNo ratings yet
- Chapter - 3 ShortDocument4 pagesChapter - 3 ShortNadeem ArainNo ratings yet
- Chapter - 3 ShortDocument4 pagesChapter - 3 ShortNadeem ArainNo ratings yet
- Chapter - 2 ShortDocument16 pagesChapter - 2 ShortNadeem ArainNo ratings yet
- Chapter - 4 ShortDocument15 pagesChapter - 4 ShortNadeem ArainNo ratings yet
- Gaseous Exchange: Short Question AnswersDocument5 pagesGaseous Exchange: Short Question AnswersNadeem ArainNo ratings yet
- Introduction To Biology Short Question and Answers: Q. Define Biology. Explain Its Branches. BiologyDocument7 pagesIntroduction To Biology Short Question and Answers: Q. Define Biology. Explain Its Branches. BiologyNadeem ArainNo ratings yet
- Introduction To Biology Short Question and AnswersDocument218 pagesIntroduction To Biology Short Question and AnswersNadeem ArainNo ratings yet
- English-1 Grammar & VocabDocument107 pagesEnglish-1 Grammar & VocabNadeem Arain100% (1)
- Permutation & CombinationDocument1 pagePermutation & CombinationNadeem ArainNo ratings yet
- Writing AbilityDocument10 pagesWriting AbilityNadeem ArainNo ratings yet
- 11 NADEEM ARAIN Algebra Practice Test AllDocument20 pages11 NADEEM ARAIN Algebra Practice Test AllNadeem ArainNo ratings yet
- Oluwarotimi Ademola OmotolaDocument5 pagesOluwarotimi Ademola OmotolaOluwarotimi Ademola OMOTOLANo ratings yet
- Basic Grammar Unit6 Without AnswersDocument1 pageBasic Grammar Unit6 Without AnswerstitnNo ratings yet
- ABB Analog Signal Converter and Serial Data ConverterDocument42 pagesABB Analog Signal Converter and Serial Data ConverterKmj KmjNo ratings yet
- LEAP Brochure 2013Document15 pagesLEAP Brochure 2013Reparto100% (1)
- Cummins C25 C30 C35 C40 Spec SheetDocument5 pagesCummins C25 C30 C35 C40 Spec Sheetkillers201493No ratings yet
- Lateral ThinkingDocument3 pagesLateral Thinkingapi-258279026No ratings yet
- KSP Solutibilty Practice ProblemsDocument22 pagesKSP Solutibilty Practice ProblemsRohan BhatiaNo ratings yet
- Actors On Stage Sketching Characters On The StreetDocument11 pagesActors On Stage Sketching Characters On The StreetOscar GalliNo ratings yet
- Consumption of Functional Food and Our Health ConcernsDocument8 pagesConsumption of Functional Food and Our Health ConcernsPhysiology by Dr RaghuveerNo ratings yet
- Estimated Service Life of Wood PolesDocument6 pagesEstimated Service Life of Wood Poleshalel111No ratings yet
- ATT EL52203 UserManualDocument102 pagesATT EL52203 UserManualdalton95198285No ratings yet
- Muscular Tissues: Skeletal MusclesDocument3 pagesMuscular Tissues: Skeletal Musclesalimsaadun alimsaadunNo ratings yet
- Location Recce - Horror SceneDocument2 pagesLocation Recce - Horror Sceneapi-634642526No ratings yet
- Warning: No Smoking! No Open Flame! While Installing Your Jet KitDocument2 pagesWarning: No Smoking! No Open Flame! While Installing Your Jet KitBrad MonkNo ratings yet
- EU Igus Dry-Tech BEA1 2023 Catalogue 02-05 Iglidur Food ContactDocument38 pagesEU Igus Dry-Tech BEA1 2023 Catalogue 02-05 Iglidur Food ContactDaniel Andrés ReigNo ratings yet
- Bokk, Fiber, Naam 1985, BasedDocument210 pagesBokk, Fiber, Naam 1985, BasedDoddy UskonoNo ratings yet
- Lease Agreement SampleDocument11 pagesLease Agreement SampleStephen QuiambaoNo ratings yet
- VaughanDocument16 pagesVaughanMalik RizwanNo ratings yet
- Router Digi Manual Hg8121hDocument14 pagesRouter Digi Manual Hg8121haritmeticsNo ratings yet
- Rev0 (Technical and User's Manual)Document72 pagesRev0 (Technical and User's Manual)mohamedNo ratings yet
- Gothra PattikaDocument172 pagesGothra PattikaParimi VeeraVenkata Krishna SarveswarraoNo ratings yet
- GEV Organic ProductsDocument4 pagesGEV Organic ProductssubhashNo ratings yet
- Cooley, Charles - Social Organization. A Study of The Larger Mind (1909) (1910) PDFDocument458 pagesCooley, Charles - Social Organization. A Study of The Larger Mind (1909) (1910) PDFGermán Giupponi100% (1)
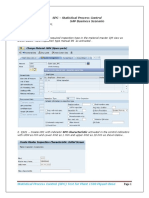
- Control Charts in SAP QM: Step by StepDocument10 pagesControl Charts in SAP QM: Step by StepPiyush BoseNo ratings yet
- 9th Science EM WWW - Tntextbooks.inDocument328 pages9th Science EM WWW - Tntextbooks.inMohamed aslamNo ratings yet
- Health Products and Food Branch Inspectorate: Good Manufacturing Practices (GMP) Guidelines - 2009 EditionDocument102 pagesHealth Products and Food Branch Inspectorate: Good Manufacturing Practices (GMP) Guidelines - 2009 Editionmario_corrales1059No ratings yet
- P 75-92 QTR 2 TG Module 2 Plant and Animal CellsDocument18 pagesP 75-92 QTR 2 TG Module 2 Plant and Animal CellsJane Limsan PaglinawanNo ratings yet
- Note 2Document11 pagesNote 2Taqiben YeamenNo ratings yet
- Accenture Aptitude Questions and AnswersDocument10 pagesAccenture Aptitude Questions and AnswersMehboobNo ratings yet
- Eye Bolt StandardsDocument5 pagesEye Bolt Standardsnilesh tadhaNo ratings yet