
Loughran McDonald JE 2011
Loughran McDonald JE 2011
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5823)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Arindam Bandyopadhyay - Basic Statistics For Risk Management in Banks and Financial Institutions-Oxford University Press (2022)Document321 pagesArindam Bandyopadhyay - Basic Statistics For Risk Management in Banks and Financial Institutions-Oxford University Press (2022)Deb100% (1)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Linear Equations in Two VariablesDocument8 pagesLinear Equations in Two VariablesDebNo ratings yet
- Number SystemsDocument5 pagesNumber SystemsDebNo ratings yet
- Fiscal ConsolidationDocument11 pagesFiscal ConsolidationDebNo ratings yet
- Exp (% of GDP)Document63 pagesExp (% of GDP)DebNo ratings yet
- 5.introduction To Euclid - S GeometryDocument9 pages5.introduction To Euclid - S GeometryDebNo ratings yet
- 3.coordinate GeometryDocument12 pages3.coordinate GeometryDebNo ratings yet
- PolynomialsDocument4 pagesPolynomialsDebNo ratings yet
- GST Collection Jan'23Document3 pagesGST Collection Jan'23DebNo ratings yet
- Mock CAT - 05 PDFDocument82 pagesMock CAT - 05 PDFDebNo ratings yet
- Mock CAT - 04 PDFDocument78 pagesMock CAT - 04 PDFDebNo ratings yet
- Mock CAT - 06 PDFDocument79 pagesMock CAT - 06 PDFDebNo ratings yet
- Session4 DateDocument364 pagesSession4 DateDebNo ratings yet
- 5 SolverDocument11 pages5 SolverDebNo ratings yet
- Book 1Document5 pagesBook 1DebNo ratings yet
- FinalDocument2 pagesFinalDebNo ratings yet
- 5-Reporting and Data Visualization-1Document111 pages5-Reporting and Data Visualization-1DebNo ratings yet
- PPTXDocument10 pagesPPTXDebNo ratings yet
- Sec B Gp8 Blinds To Go PDFDocument12 pagesSec B Gp8 Blinds To Go PDFDebNo ratings yet
- 2021 Bull CAT 03Document58 pages2021 Bull CAT 03DebNo ratings yet
- 3-Data ReferencingDocument135 pages3-Data ReferencingDebNo ratings yet
- Case Study Blinds To GoDocument7 pagesCase Study Blinds To GoDebNo ratings yet
- 2021 Bull CAT 05Document60 pages2021 Bull CAT 05DebNo ratings yet
- This Content Downloaded From 115.124.43.107 On Wed, 18 Jan 2023 06:19:13 UTCDocument33 pagesThis Content Downloaded From 115.124.43.107 On Wed, 18 Jan 2023 06:19:13 UTCDebNo ratings yet
- 2021 Bull CAT 04 (New Pattern)Document42 pages2021 Bull CAT 04 (New Pattern)DebNo ratings yet
- 2021 Bull CAT 02Document56 pages2021 Bull CAT 02DebNo ratings yet
- American Finance Association, Wiley The Journal of FinanceDocument41 pagesAmerican Finance Association, Wiley The Journal of FinanceDebNo ratings yet
- 2021 Bull Cat 01Document62 pages2021 Bull Cat 01DebNo ratings yet
- Bjerring 1983Document18 pagesBjerring 1983DebNo ratings yet
- FULLTEXT01Document60 pagesFULLTEXT01DebNo ratings yet
- Miet 2420 Tutorial 01 - Rolling Element BearingsDocument2 pagesMiet 2420 Tutorial 01 - Rolling Element BearingsIsaac MahlabNo ratings yet
- Coupled Tanks - Workbook (Student) INGLÉS PDFDocument34 pagesCoupled Tanks - Workbook (Student) INGLÉS PDFDanielaLópezNo ratings yet
- 095-Everett vs. Asia Banking Corp 49 Phil 512Document8 pages095-Everett vs. Asia Banking Corp 49 Phil 512Jopan SJNo ratings yet
- Introduction of EDFADocument22 pagesIntroduction of EDFAArifiana Satya NastitiNo ratings yet
- BPE18 - 72-90 - Baelz 373-E07Document19 pagesBPE18 - 72-90 - Baelz 373-E07robbertjv2104No ratings yet
- Bridges Their Engineering and Planning PDFDocument182 pagesBridges Their Engineering and Planning PDFBlack BoxNo ratings yet
- Write-Up - GraphDocument17 pagesWrite-Up - GraphMartha AntonNo ratings yet
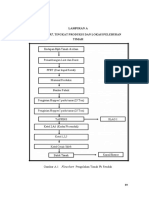
- Flowchart, Tingkat Produksi Dan Lokasi Peleburan: Lampiran ADocument11 pagesFlowchart, Tingkat Produksi Dan Lokasi Peleburan: Lampiran Aanton wibowoNo ratings yet
- Index of OP Project HIRA Activities ID No. Activities Remarks Format NoDocument7 pagesIndex of OP Project HIRA Activities ID No. Activities Remarks Format NoSameer JogasNo ratings yet
- Lesson 5 SoftwareDocument18 pagesLesson 5 SoftwareRomar BrionesNo ratings yet
- Algorithms For Data Science: CSOR W4246Document44 pagesAlgorithms For Data Science: CSOR W4246EarthaNo ratings yet
- Crop and Soil MonitoringDocument2 pagesCrop and Soil Monitoringمريم منيرNo ratings yet
- Test Bank For Human Resource Management 14Th Edition by Mondy Martocchio Isbn 9780133848809 0133848809 Full Chapter PDFDocument36 pagesTest Bank For Human Resource Management 14Th Edition by Mondy Martocchio Isbn 9780133848809 0133848809 Full Chapter PDFsimon.esche558100% (18)
- Master Thesis in Chaotic CryptographyDocument5 pagesMaster Thesis in Chaotic Cryptographyafktdftdvqtiom100% (2)
- Loadmaster Custom v. Grodel BrokerageDocument9 pagesLoadmaster Custom v. Grodel BrokerageLorelei B RecuencoNo ratings yet
- Power - System Mitra MaintenanceDocument15 pagesPower - System Mitra MaintenanceMuhammad Maulana SetiawanNo ratings yet
- Text Book Solution Lesson - 6 (Local Self Govt. in Urban Areas)Document6 pagesText Book Solution Lesson - 6 (Local Self Govt. in Urban Areas)Sahasra KiranNo ratings yet
- Resume Template 2: Rofessional XperienceDocument2 pagesResume Template 2: Rofessional XperienceVivek SinghNo ratings yet
- Dilip Datta (Auth.) - LaTeX in 24 Hours - A Practical Guide For Scientific Writing-Springer International Publishing (2017)Document309 pagesDilip Datta (Auth.) - LaTeX in 24 Hours - A Practical Guide For Scientific Writing-Springer International Publishing (2017)Leandro de Queiroz100% (3)
- Qatar - Food & Beverage Sector Overview & Forecast: Thought Leadership SeriesDocument16 pagesQatar - Food & Beverage Sector Overview & Forecast: Thought Leadership SeriesShashank Hanuman JainNo ratings yet
- Toolbox Talks: Forklift FatalitiesDocument1 pageToolbox Talks: Forklift Fatalitiesserdar yücelNo ratings yet
- Magneto Optical Current TransformerDocument23 pagesMagneto Optical Current Transformersushilkumarbhoi2897No ratings yet
- Chapter 2 Web Services Delivered From The CloudDocument8 pagesChapter 2 Web Services Delivered From The Cloudali abbasNo ratings yet
- Installation Manual M1050x Stereo Chime/Page AmplifierDocument36 pagesInstallation Manual M1050x Stereo Chime/Page AmplifierSANDOVAL RAMIREZ JORMA ANDERSONNo ratings yet
- Card Level Laptop DesktopDocument2 pagesCard Level Laptop DesktopJawad Anwar100% (1)
- Auto Confirmation of Coverage - Ahmad HleihelDocument2 pagesAuto Confirmation of Coverage - Ahmad Hleiheladamsjennifer734No ratings yet
- The Registration Process of NGOs in EthiopiaDocument20 pagesThe Registration Process of NGOs in EthiopiaTariku JebenaNo ratings yet
- 2011 Year End Capacity Report PDFDocument62 pages2011 Year End Capacity Report PDFadalcayde2514No ratings yet
- Harvard ReferencingDocument19 pagesHarvard ReferencingniroshniroshNo ratings yet
- Waked Money Laundering Organization: Panama-Based WAKED MLO AssociatesDocument2 pagesWaked Money Laundering Organization: Panama-Based WAKED MLO AssociatesErika Anruth Martinez LopezNo ratings yet




































































































Download as pdf or txt
You might also like
- The Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeFrom EverandThe Subtle Art of Not Giving a F*ck: A Counterintuitive Approach to Living a Good LifeRating: 4 out of 5 stars4/5 (5823)
- The Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreFrom EverandThe Gifts of Imperfection: Let Go of Who You Think You're Supposed to Be and Embrace Who You AreRating: 4 out of 5 stars4/5 (1093)
- Never Split the Difference: Negotiating As If Your Life Depended On ItFrom EverandNever Split the Difference: Negotiating As If Your Life Depended On ItRating: 4.5 out of 5 stars4.5/5 (852)
- Grit: The Power of Passion and PerseveranceFrom EverandGrit: The Power of Passion and PerseveranceRating: 4 out of 5 stars4/5 (590)
- Hidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceFrom EverandHidden Figures: The American Dream and the Untold Story of the Black Women Mathematicians Who Helped Win the Space RaceRating: 4 out of 5 stars4/5 (898)
- Shoe Dog: A Memoir by the Creator of NikeFrom EverandShoe Dog: A Memoir by the Creator of NikeRating: 4.5 out of 5 stars4.5/5 (540)
- The Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersFrom EverandThe Hard Thing About Hard Things: Building a Business When There Are No Easy AnswersRating: 4.5 out of 5 stars4.5/5 (349)
- Elon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureFrom EverandElon Musk: Tesla, SpaceX, and the Quest for a Fantastic FutureRating: 4.5 out of 5 stars4.5/5 (474)
- Her Body and Other Parties: StoriesFrom EverandHer Body and Other Parties: StoriesRating: 4 out of 5 stars4/5 (823)
- The Sympathizer: A Novel (Pulitzer Prize for Fiction)From EverandThe Sympathizer: A Novel (Pulitzer Prize for Fiction)Rating: 4.5 out of 5 stars4.5/5 (122)
- The Emperor of All Maladies: A Biography of CancerFrom EverandThe Emperor of All Maladies: A Biography of CancerRating: 4.5 out of 5 stars4.5/5 (271)
- The Little Book of Hygge: Danish Secrets to Happy LivingFrom EverandThe Little Book of Hygge: Danish Secrets to Happy LivingRating: 3.5 out of 5 stars3.5/5 (403)
- Devil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaFrom EverandDevil in the Grove: Thurgood Marshall, the Groveland Boys, and the Dawn of a New AmericaRating: 4.5 out of 5 stars4.5/5 (266)
- The World Is Flat 3.0: A Brief History of the Twenty-first CenturyFrom EverandThe World Is Flat 3.0: A Brief History of the Twenty-first CenturyRating: 3.5 out of 5 stars3.5/5 (2259)
- The Yellow House: A Memoir (2019 National Book Award Winner)From EverandThe Yellow House: A Memoir (2019 National Book Award Winner)Rating: 4 out of 5 stars4/5 (98)
- A Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryFrom EverandA Heartbreaking Work Of Staggering Genius: A Memoir Based on a True StoryRating: 3.5 out of 5 stars3.5/5 (231)
- Team of Rivals: The Political Genius of Abraham LincolnFrom EverandTeam of Rivals: The Political Genius of Abraham LincolnRating: 4.5 out of 5 stars4.5/5 (234)
- On Fire: The (Burning) Case for a Green New DealFrom EverandOn Fire: The (Burning) Case for a Green New DealRating: 4 out of 5 stars4/5 (74)
- Arindam Bandyopadhyay - Basic Statistics For Risk Management in Banks and Financial Institutions-Oxford University Press (2022)Document321 pagesArindam Bandyopadhyay - Basic Statistics For Risk Management in Banks and Financial Institutions-Oxford University Press (2022)Deb100% (1)
- The Unwinding: An Inner History of the New AmericaFrom EverandThe Unwinding: An Inner History of the New AmericaRating: 4 out of 5 stars4/5 (45)
- Linear Equations in Two VariablesDocument8 pagesLinear Equations in Two VariablesDebNo ratings yet
- Number SystemsDocument5 pagesNumber SystemsDebNo ratings yet
- Fiscal ConsolidationDocument11 pagesFiscal ConsolidationDebNo ratings yet
- Exp (% of GDP)Document63 pagesExp (% of GDP)DebNo ratings yet
- 5.introduction To Euclid - S GeometryDocument9 pages5.introduction To Euclid - S GeometryDebNo ratings yet
- 3.coordinate GeometryDocument12 pages3.coordinate GeometryDebNo ratings yet
- PolynomialsDocument4 pagesPolynomialsDebNo ratings yet
- GST Collection Jan'23Document3 pagesGST Collection Jan'23DebNo ratings yet
- Mock CAT - 05 PDFDocument82 pagesMock CAT - 05 PDFDebNo ratings yet
- Mock CAT - 04 PDFDocument78 pagesMock CAT - 04 PDFDebNo ratings yet
- Mock CAT - 06 PDFDocument79 pagesMock CAT - 06 PDFDebNo ratings yet
- Session4 DateDocument364 pagesSession4 DateDebNo ratings yet
- 5 SolverDocument11 pages5 SolverDebNo ratings yet
- Book 1Document5 pagesBook 1DebNo ratings yet
- FinalDocument2 pagesFinalDebNo ratings yet
- 5-Reporting and Data Visualization-1Document111 pages5-Reporting and Data Visualization-1DebNo ratings yet
- PPTXDocument10 pagesPPTXDebNo ratings yet
- Sec B Gp8 Blinds To Go PDFDocument12 pagesSec B Gp8 Blinds To Go PDFDebNo ratings yet
- 2021 Bull CAT 03Document58 pages2021 Bull CAT 03DebNo ratings yet
- 3-Data ReferencingDocument135 pages3-Data ReferencingDebNo ratings yet
- Case Study Blinds To GoDocument7 pagesCase Study Blinds To GoDebNo ratings yet
- 2021 Bull CAT 05Document60 pages2021 Bull CAT 05DebNo ratings yet
- This Content Downloaded From 115.124.43.107 On Wed, 18 Jan 2023 06:19:13 UTCDocument33 pagesThis Content Downloaded From 115.124.43.107 On Wed, 18 Jan 2023 06:19:13 UTCDebNo ratings yet
- 2021 Bull CAT 04 (New Pattern)Document42 pages2021 Bull CAT 04 (New Pattern)DebNo ratings yet
- 2021 Bull CAT 02Document56 pages2021 Bull CAT 02DebNo ratings yet
- American Finance Association, Wiley The Journal of FinanceDocument41 pagesAmerican Finance Association, Wiley The Journal of FinanceDebNo ratings yet
- 2021 Bull Cat 01Document62 pages2021 Bull Cat 01DebNo ratings yet
- Bjerring 1983Document18 pagesBjerring 1983DebNo ratings yet
- FULLTEXT01Document60 pagesFULLTEXT01DebNo ratings yet
- Miet 2420 Tutorial 01 - Rolling Element BearingsDocument2 pagesMiet 2420 Tutorial 01 - Rolling Element BearingsIsaac MahlabNo ratings yet
- Coupled Tanks - Workbook (Student) INGLÉS PDFDocument34 pagesCoupled Tanks - Workbook (Student) INGLÉS PDFDanielaLópezNo ratings yet
- 095-Everett vs. Asia Banking Corp 49 Phil 512Document8 pages095-Everett vs. Asia Banking Corp 49 Phil 512Jopan SJNo ratings yet
- Introduction of EDFADocument22 pagesIntroduction of EDFAArifiana Satya NastitiNo ratings yet
- BPE18 - 72-90 - Baelz 373-E07Document19 pagesBPE18 - 72-90 - Baelz 373-E07robbertjv2104No ratings yet
- Bridges Their Engineering and Planning PDFDocument182 pagesBridges Their Engineering and Planning PDFBlack BoxNo ratings yet
- Write-Up - GraphDocument17 pagesWrite-Up - GraphMartha AntonNo ratings yet
- Flowchart, Tingkat Produksi Dan Lokasi Peleburan: Lampiran ADocument11 pagesFlowchart, Tingkat Produksi Dan Lokasi Peleburan: Lampiran Aanton wibowoNo ratings yet
- Index of OP Project HIRA Activities ID No. Activities Remarks Format NoDocument7 pagesIndex of OP Project HIRA Activities ID No. Activities Remarks Format NoSameer JogasNo ratings yet
- Lesson 5 SoftwareDocument18 pagesLesson 5 SoftwareRomar BrionesNo ratings yet
- Algorithms For Data Science: CSOR W4246Document44 pagesAlgorithms For Data Science: CSOR W4246EarthaNo ratings yet
- Crop and Soil MonitoringDocument2 pagesCrop and Soil Monitoringمريم منيرNo ratings yet
- Test Bank For Human Resource Management 14Th Edition by Mondy Martocchio Isbn 9780133848809 0133848809 Full Chapter PDFDocument36 pagesTest Bank For Human Resource Management 14Th Edition by Mondy Martocchio Isbn 9780133848809 0133848809 Full Chapter PDFsimon.esche558100% (18)
- Master Thesis in Chaotic CryptographyDocument5 pagesMaster Thesis in Chaotic Cryptographyafktdftdvqtiom100% (2)
- Loadmaster Custom v. Grodel BrokerageDocument9 pagesLoadmaster Custom v. Grodel BrokerageLorelei B RecuencoNo ratings yet
- Power - System Mitra MaintenanceDocument15 pagesPower - System Mitra MaintenanceMuhammad Maulana SetiawanNo ratings yet
- Text Book Solution Lesson - 6 (Local Self Govt. in Urban Areas)Document6 pagesText Book Solution Lesson - 6 (Local Self Govt. in Urban Areas)Sahasra KiranNo ratings yet
- Resume Template 2: Rofessional XperienceDocument2 pagesResume Template 2: Rofessional XperienceVivek SinghNo ratings yet
- Dilip Datta (Auth.) - LaTeX in 24 Hours - A Practical Guide For Scientific Writing-Springer International Publishing (2017)Document309 pagesDilip Datta (Auth.) - LaTeX in 24 Hours - A Practical Guide For Scientific Writing-Springer International Publishing (2017)Leandro de Queiroz100% (3)
- Qatar - Food & Beverage Sector Overview & Forecast: Thought Leadership SeriesDocument16 pagesQatar - Food & Beverage Sector Overview & Forecast: Thought Leadership SeriesShashank Hanuman JainNo ratings yet
- Toolbox Talks: Forklift FatalitiesDocument1 pageToolbox Talks: Forklift Fatalitiesserdar yücelNo ratings yet
- Magneto Optical Current TransformerDocument23 pagesMagneto Optical Current Transformersushilkumarbhoi2897No ratings yet
- Chapter 2 Web Services Delivered From The CloudDocument8 pagesChapter 2 Web Services Delivered From The Cloudali abbasNo ratings yet
- Installation Manual M1050x Stereo Chime/Page AmplifierDocument36 pagesInstallation Manual M1050x Stereo Chime/Page AmplifierSANDOVAL RAMIREZ JORMA ANDERSONNo ratings yet
- Card Level Laptop DesktopDocument2 pagesCard Level Laptop DesktopJawad Anwar100% (1)
- Auto Confirmation of Coverage - Ahmad HleihelDocument2 pagesAuto Confirmation of Coverage - Ahmad Hleiheladamsjennifer734No ratings yet
- The Registration Process of NGOs in EthiopiaDocument20 pagesThe Registration Process of NGOs in EthiopiaTariku JebenaNo ratings yet
- 2011 Year End Capacity Report PDFDocument62 pages2011 Year End Capacity Report PDFadalcayde2514No ratings yet
- Harvard ReferencingDocument19 pagesHarvard ReferencingniroshniroshNo ratings yet
- Waked Money Laundering Organization: Panama-Based WAKED MLO AssociatesDocument2 pagesWaked Money Laundering Organization: Panama-Based WAKED MLO AssociatesErika Anruth Martinez LopezNo ratings yet