
A Mixture Model For Duration Data Analysis of Second Births in China
A Mixture Model For Duration Data Analysis of Second Births in China
You might also like
- Bolker Et Al 2009 General Mixed ModelDocument9 pagesBolker Et Al 2009 General Mixed ModelCarlos AndradeNo ratings yet
- Frank Gambale - Guitar Sweep PickingDocument4 pagesFrank Gambale - Guitar Sweep Pickingbrightthings100% (17)
- A Theoretically-Consistent Empirical Model of Non-Expected Utility: An Application To Nuclear-Waste TransportDocument21 pagesA Theoretically-Consistent Empirical Model of Non-Expected Utility: An Application To Nuclear-Waste TransportvivianaNo ratings yet
- A Sensitivity Analysis of The Social Vulnerability IndexDocument16 pagesA Sensitivity Analysis of The Social Vulnerability IndexkowsilaxNo ratings yet
- Lieberson 1991Document14 pagesLieberson 1991Isabel M. FontanotNo ratings yet
- LiebersonDocument15 pagesLiebersonMeruyert MussamadinovaNo ratings yet
- This Content Downloaded From 193.190.2.119 On Fri, 04 Dec 2020 04:58:52 UTCDocument23 pagesThis Content Downloaded From 193.190.2.119 On Fri, 04 Dec 2020 04:58:52 UTCPhilippe TadgerNo ratings yet
- Application of Negative Binomial DistributionDocument11 pagesApplication of Negative Binomial DistributionAishaizlNo ratings yet
- A Family of Flexible Parametric Duration Functions & Their ApplicDocument34 pagesA Family of Flexible Parametric Duration Functions & Their ApplicSintayehu BirhanuNo ratings yet
- Evolution of StoriesDocument13 pagesEvolution of StoriesAsrul SaniNo ratings yet
- Gender and Well-Being: Interactions Between Work, Family and Public PoliciesDocument16 pagesGender and Well-Being: Interactions Between Work, Family and Public PoliciesValero YoannNo ratings yet
- 001 Small Ns and Big ConclusionsDocument14 pages001 Small Ns and Big ConclusionsjoseNo ratings yet
- Van Calster The Harm of Class Imbalance Corrections For Risk Prediction Models Illustration and Simulation Using Logistic RegressionDocument10 pagesVan Calster The Harm of Class Imbalance Corrections For Risk Prediction Models Illustration and Simulation Using Logistic RegressionMELINA PERESSINI ALVAREZNo ratings yet
- On A Sequential Probit Model of Infant Mortality in Nigeria: K. T. Amzat, S. A. AdeosunDocument6 pagesOn A Sequential Probit Model of Infant Mortality in Nigeria: K. T. Amzat, S. A. AdeosuninventionjournalsNo ratings yet
- Master Thesis UvtDocument5 pagesMaster Thesis Uvtbnjkstgig100% (1)
- Ivan Ermakoff 2015Document63 pagesIvan Ermakoff 2015Pola Alejandra DiazNo ratings yet
- Rmrs 2001 Schreuder h001Document11 pagesRmrs 2001 Schreuder h001Andre ChundawanNo ratings yet
- The International Journal of Biostatistics: An Introduction To Causal InferenceDocument62 pagesThe International Journal of Biostatistics: An Introduction To Causal InferenceViswas ChhapolaNo ratings yet
- Application of Multivariate Logit Analysis To Contraceptive Adoption Decisions Among Undergraduates of Kwara State PolytechnicDocument6 pagesApplication of Multivariate Logit Analysis To Contraceptive Adoption Decisions Among Undergraduates of Kwara State PolytechnicInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Additional Ma ThematicDocument37 pagesAdditional Ma ThematicSiti Noor Albaiyah100% (1)
- Resilience Processes in Development - MastenDocument12 pagesResilience Processes in Development - MastenRuxandra Zaharia100% (1)
- Fuzzy Graph Theory Applications To Global Problems John N Mordeson Full ChapterDocument67 pagesFuzzy Graph Theory Applications To Global Problems John N Mordeson Full Chapterdana.nelson195100% (11)
- 2014 CamposCuilty JBEE RiskProspectTheoryDocument10 pages2014 CamposCuilty JBEE RiskProspectTheoryFrancisco Javier Diaz PincheiraNo ratings yet
- Summary ProposalDocument4 pagesSummary ProposalBbk SaraNo ratings yet
- An Illustration of Second Order Latent Growth ModelsDocument21 pagesAn Illustration of Second Order Latent Growth ModelssimbycrisNo ratings yet
- Equation-Free Multiscale Computational Analysis of Individual-Based Epidemic Dynamics On NetworksDocument24 pagesEquation-Free Multiscale Computational Analysis of Individual-Based Epidemic Dynamics On NetworksStar MongerNo ratings yet
- Lee 2004 QuantifyingDocument24 pagesLee 2004 QuantifyingLucía AndreozziNo ratings yet
- New Disaster ModelDocument2 pagesNew Disaster ModelchebhebmgNo ratings yet
- 2298 10466 1 PBDocument26 pages2298 10466 1 PBJulián Emiliano EscalanteNo ratings yet
- SCI 11 Module 5Document6 pagesSCI 11 Module 5Sebastian SmytheNo ratings yet
- How To Deal With Reverse Causality Using Panel Data? Recommendations For Researchers Based On A Simulation StudyDocument29 pagesHow To Deal With Reverse Causality Using Panel Data? Recommendations For Researchers Based On A Simulation StudyMa GaNo ratings yet
- The Level of Analysis Problem. SingerDocument17 pagesThe Level of Analysis Problem. Singerdianalr25No ratings yet
- A Tutorial On Frailty ModelsDocument31 pagesA Tutorial On Frailty Modelss2126002No ratings yet
- Master Thesis VubDocument7 pagesMaster Thesis Vubfc2fqg8j100% (2)
- The Sociology of Risk and Uncertainty Current StatDocument15 pagesThe Sociology of Risk and Uncertainty Current StatJAN STIVEN ASUNCIÓN FLORESNo ratings yet
- Ordinary Magic Resilience Processes in Development.Document12 pagesOrdinary Magic Resilience Processes in Development.Altikardes_Mar_5520No ratings yet
- System Sequence of Events State: United StatesDocument3 pagesSystem Sequence of Events State: United StatesHong JooNo ratings yet
- EpidemicModeling s20 SkvortsovDocument6 pagesEpidemicModeling s20 SkvortsovFadli RizkiandiNo ratings yet
- 2018 - 01 - 01 A Human Environmental Network Model For Assessing Coastal Global Environment - Small and XianDocument9 pages2018 - 01 - 01 A Human Environmental Network Model For Assessing Coastal Global Environment - Small and XianIwan AmirNo ratings yet
- (Gabriel A. Radvansky, Jeffrey M. Zacks) Event Cog (Z-Lib - Org) - 3Document25 pages(Gabriel A. Radvansky, Jeffrey M. Zacks) Event Cog (Z-Lib - Org) - 3Judy Costanza BeltránNo ratings yet
- Mining The Web To Predict Future EventsDocument10 pagesMining The Web To Predict Future EventsDevadasRajaramNo ratings yet
- Detecting Gene-Gene Interactions That Underlie Human DiseasesDocument13 pagesDetecting Gene-Gene Interactions That Underlie Human DiseasesBalaji NarayananNo ratings yet
- The Board of Regents of The University of Wisconsin SystemDocument23 pagesThe Board of Regents of The University of Wisconsin Systemsanta171No ratings yet
- Insr12271 AmDocument39 pagesInsr12271 AmUdita GoswamiNo ratings yet
- Bayesian Latent Variable Models For Mixed Discrete OutcomesDocument15 pagesBayesian Latent Variable Models For Mixed Discrete OutcomesAnonymous 4gOYyVfdfNo ratings yet
- Counter FDocument13 pagesCounter FAlejandra ParraNo ratings yet
- Disaster World: Decision-Theoretic Agents For Simulating Population Responses To HurricanesDocument34 pagesDisaster World: Decision-Theoretic Agents For Simulating Population Responses To HurricanesLuis Fernando ZhininNo ratings yet
- Probability Theory and Stochastic ProcessesDocument155 pagesProbability Theory and Stochastic ProcessesPavani0% (1)
- Dynamic Decision Making: What Do People Do?: John D. Hey Luca PanaccioneDocument39 pagesDynamic Decision Making: What Do People Do?: John D. Hey Luca PanaccioneMatteo MasottiNo ratings yet
- Add Math 2010 Project WorkDocument38 pagesAdd Math 2010 Project WorkAhmad Firdaus86% (22)
- tmp419D TMPDocument10 pagestmp419D TMPFrontiersNo ratings yet
- 2024 - Geiß - Anticipating A Risky Future - Long Short-Term Memory LSTM Models For Spatiotemporal Extrapolation of Population Data in Areas Prone To Earthquakes and Tsunamis in Lima PeruDocument14 pages2024 - Geiß - Anticipating A Risky Future - Long Short-Term Memory LSTM Models For Spatiotemporal Extrapolation of Population Data in Areas Prone To Earthquakes and Tsunamis in Lima PerusophieNo ratings yet
- Risk Preferences Are Not Time PreferencesDocument42 pagesRisk Preferences Are Not Time PreferencesTouhid AkramNo ratings yet
- Causal Diagrams in Systems Epidemiology: Analyticperspective Open AccessDocument18 pagesCausal Diagrams in Systems Epidemiology: Analyticperspective Open AccessShopzynkNo ratings yet
- Statistical ModelingDocument18 pagesStatistical ModelingWahyu S. Ginanjar100% (1)
- Particle emission concept and probabilistic consideration of the development of infections in systems: Dynamics from logarithm and exponent in the infection process, percolation effectsFrom EverandParticle emission concept and probabilistic consideration of the development of infections in systems: Dynamics from logarithm and exponent in the infection process, percolation effectsNo ratings yet
- Linear and Generalized Linear Mixed Models and Their ApplicationsFrom EverandLinear and Generalized Linear Mixed Models and Their ApplicationsNo ratings yet
- Charting the Next Pandemic: Modeling Infectious Disease Spreading in the Data Science AgeFrom EverandCharting the Next Pandemic: Modeling Infectious Disease Spreading in the Data Science AgeNo ratings yet
- The Cybernetic Theory of Decision: New Dimensions of Political AnalysisFrom EverandThe Cybernetic Theory of Decision: New Dimensions of Political AnalysisRating: 3.5 out of 5 stars3.5/5 (4)
- Standard DeviationDocument22 pagesStandard DeviationPriya VermaNo ratings yet
- Domestic Company Notams 16 Jan 18Document41 pagesDomestic Company Notams 16 Jan 18Swastika MishraNo ratings yet
- Kaylee Analco - Calorimetry GizmosDocument7 pagesKaylee Analco - Calorimetry GizmosKaylee Analco100% (1)
- Infinity Other Solar Systems: TrinityDocument1 pageInfinity Other Solar Systems: TrinityP Eng Suraj SinghNo ratings yet
- Calculate InflationDocument2 pagesCalculate InflationNafees AhmadNo ratings yet
- 14.udemy S4hana Course MaterialDocument53 pages14.udemy S4hana Course MaterialArben LaçiNo ratings yet
- The Effect of Temperature On The PH Level of Lemon JuiceDocument12 pagesThe Effect of Temperature On The PH Level of Lemon JuicekjfanmNo ratings yet
- E-Terragridcom DIP Brochure GBDocument4 pagesE-Terragridcom DIP Brochure GBNeelakandan MasilamaniNo ratings yet
- Light: 1.1 Light Travels in Straight LinesDocument11 pagesLight: 1.1 Light Travels in Straight Linesching_jyoNo ratings yet
- Personalized Movie Hybrid Recommendation Model Based On GRUDocument4 pagesPersonalized Movie Hybrid Recommendation Model Based On GRUMritunjay JhaNo ratings yet
- Operations Management - Chapter 12Document11 pagesOperations Management - Chapter 12David Van De FliertNo ratings yet
- High Impedance Fault Detection Using Multi Domain Feature With Artificial Neural NetworkDocument15 pagesHigh Impedance Fault Detection Using Multi Domain Feature With Artificial Neural NetworkANKAN CHANDRANo ratings yet
- Cs101 Program Logic Formulation 1Document4 pagesCs101 Program Logic Formulation 1Multiple Criteria DssNo ratings yet
- 11 ProbDocument2 pages11 Probachandra100% (1)
- Netzer DS-58 SpecsheetDocument6 pagesNetzer DS-58 SpecsheetElectromateNo ratings yet
- Underground SurveyingDocument5 pagesUnderground SurveyingErick AlanNo ratings yet
- LLC3kW GUI ManualDocument8 pagesLLC3kW GUI Manualreferenceref31No ratings yet
- Operating Principles of Electronic Engine Management SystemsDocument6 pagesOperating Principles of Electronic Engine Management SystemsVaishali Wagh100% (2)
- Technical Information and Variances.: Spec/Feature Vst-Se VST-Mini CommentsDocument1 pageTechnical Information and Variances.: Spec/Feature Vst-Se VST-Mini CommentsAhmadNo ratings yet
- Grade (10) Chapter - 11 TrigonometryDocument21 pagesGrade (10) Chapter - 11 TrigonometryZakir Amad 32100% (1)
- Chapter - 1-QMDocument56 pagesChapter - 1-QMtebelayhabitamu12No ratings yet
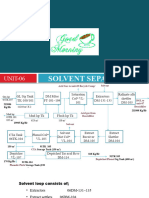
- Solvent Separation UNIT-06 - GOODDocument17 pagesSolvent Separation UNIT-06 - GOODAamir HasanNo ratings yet
- AXSS-II Access Control Configuration Guide: Enterprise Buildings IntegratorDocument128 pagesAXSS-II Access Control Configuration Guide: Enterprise Buildings IntegratorJaime AvellaNo ratings yet
- Expansion Cabinet RFDS: 6802800U74-AP Chapter 7: Radio Frequency Distribution SystemDocument201 pagesExpansion Cabinet RFDS: 6802800U74-AP Chapter 7: Radio Frequency Distribution SystemHamza AldeebNo ratings yet
- Characteristics of The Analog ComputersDocument5 pagesCharacteristics of The Analog Computersmanju_csNo ratings yet
- Linear Algebra and Random Processes (CS6015)Document5 pagesLinear Algebra and Random Processes (CS6015)CHAKRADHAR PALAVALASANo ratings yet
- Basis Certification 2003Document19 pagesBasis Certification 2003Amier Omar Al MousyNo ratings yet
- Data Sheet US - W3G910GU2201 KM89187Document7 pagesData Sheet US - W3G910GU2201 KM89187Bruno Cezar FurlinNo ratings yet
- 1.3 Analytical Chemistry 1Document17 pages1.3 Analytical Chemistry 1zedrickNo ratings yet
























































































Download as pdf or txt
You might also like
- Bolker Et Al 2009 General Mixed ModelDocument9 pagesBolker Et Al 2009 General Mixed ModelCarlos AndradeNo ratings yet
- Frank Gambale - Guitar Sweep PickingDocument4 pagesFrank Gambale - Guitar Sweep Pickingbrightthings100% (17)
- A Theoretically-Consistent Empirical Model of Non-Expected Utility: An Application To Nuclear-Waste TransportDocument21 pagesA Theoretically-Consistent Empirical Model of Non-Expected Utility: An Application To Nuclear-Waste TransportvivianaNo ratings yet
- A Sensitivity Analysis of The Social Vulnerability IndexDocument16 pagesA Sensitivity Analysis of The Social Vulnerability IndexkowsilaxNo ratings yet
- Lieberson 1991Document14 pagesLieberson 1991Isabel M. FontanotNo ratings yet
- LiebersonDocument15 pagesLiebersonMeruyert MussamadinovaNo ratings yet
- This Content Downloaded From 193.190.2.119 On Fri, 04 Dec 2020 04:58:52 UTCDocument23 pagesThis Content Downloaded From 193.190.2.119 On Fri, 04 Dec 2020 04:58:52 UTCPhilippe TadgerNo ratings yet
- Application of Negative Binomial DistributionDocument11 pagesApplication of Negative Binomial DistributionAishaizlNo ratings yet
- A Family of Flexible Parametric Duration Functions & Their ApplicDocument34 pagesA Family of Flexible Parametric Duration Functions & Their ApplicSintayehu BirhanuNo ratings yet
- Evolution of StoriesDocument13 pagesEvolution of StoriesAsrul SaniNo ratings yet
- Gender and Well-Being: Interactions Between Work, Family and Public PoliciesDocument16 pagesGender and Well-Being: Interactions Between Work, Family and Public PoliciesValero YoannNo ratings yet
- 001 Small Ns and Big ConclusionsDocument14 pages001 Small Ns and Big ConclusionsjoseNo ratings yet
- Van Calster The Harm of Class Imbalance Corrections For Risk Prediction Models Illustration and Simulation Using Logistic RegressionDocument10 pagesVan Calster The Harm of Class Imbalance Corrections For Risk Prediction Models Illustration and Simulation Using Logistic RegressionMELINA PERESSINI ALVAREZNo ratings yet
- On A Sequential Probit Model of Infant Mortality in Nigeria: K. T. Amzat, S. A. AdeosunDocument6 pagesOn A Sequential Probit Model of Infant Mortality in Nigeria: K. T. Amzat, S. A. AdeosuninventionjournalsNo ratings yet
- Master Thesis UvtDocument5 pagesMaster Thesis Uvtbnjkstgig100% (1)
- Ivan Ermakoff 2015Document63 pagesIvan Ermakoff 2015Pola Alejandra DiazNo ratings yet
- Rmrs 2001 Schreuder h001Document11 pagesRmrs 2001 Schreuder h001Andre ChundawanNo ratings yet
- The International Journal of Biostatistics: An Introduction To Causal InferenceDocument62 pagesThe International Journal of Biostatistics: An Introduction To Causal InferenceViswas ChhapolaNo ratings yet
- Application of Multivariate Logit Analysis To Contraceptive Adoption Decisions Among Undergraduates of Kwara State PolytechnicDocument6 pagesApplication of Multivariate Logit Analysis To Contraceptive Adoption Decisions Among Undergraduates of Kwara State PolytechnicInternational Journal of Application or Innovation in Engineering & ManagementNo ratings yet
- Additional Ma ThematicDocument37 pagesAdditional Ma ThematicSiti Noor Albaiyah100% (1)
- Resilience Processes in Development - MastenDocument12 pagesResilience Processes in Development - MastenRuxandra Zaharia100% (1)
- Fuzzy Graph Theory Applications To Global Problems John N Mordeson Full ChapterDocument67 pagesFuzzy Graph Theory Applications To Global Problems John N Mordeson Full Chapterdana.nelson195100% (11)
- 2014 CamposCuilty JBEE RiskProspectTheoryDocument10 pages2014 CamposCuilty JBEE RiskProspectTheoryFrancisco Javier Diaz PincheiraNo ratings yet
- Summary ProposalDocument4 pagesSummary ProposalBbk SaraNo ratings yet
- An Illustration of Second Order Latent Growth ModelsDocument21 pagesAn Illustration of Second Order Latent Growth ModelssimbycrisNo ratings yet
- Equation-Free Multiscale Computational Analysis of Individual-Based Epidemic Dynamics On NetworksDocument24 pagesEquation-Free Multiscale Computational Analysis of Individual-Based Epidemic Dynamics On NetworksStar MongerNo ratings yet
- Lee 2004 QuantifyingDocument24 pagesLee 2004 QuantifyingLucía AndreozziNo ratings yet
- New Disaster ModelDocument2 pagesNew Disaster ModelchebhebmgNo ratings yet
- 2298 10466 1 PBDocument26 pages2298 10466 1 PBJulián Emiliano EscalanteNo ratings yet
- SCI 11 Module 5Document6 pagesSCI 11 Module 5Sebastian SmytheNo ratings yet
- How To Deal With Reverse Causality Using Panel Data? Recommendations For Researchers Based On A Simulation StudyDocument29 pagesHow To Deal With Reverse Causality Using Panel Data? Recommendations For Researchers Based On A Simulation StudyMa GaNo ratings yet
- The Level of Analysis Problem. SingerDocument17 pagesThe Level of Analysis Problem. Singerdianalr25No ratings yet
- A Tutorial On Frailty ModelsDocument31 pagesA Tutorial On Frailty Modelss2126002No ratings yet
- Master Thesis VubDocument7 pagesMaster Thesis Vubfc2fqg8j100% (2)
- The Sociology of Risk and Uncertainty Current StatDocument15 pagesThe Sociology of Risk and Uncertainty Current StatJAN STIVEN ASUNCIÓN FLORESNo ratings yet
- Ordinary Magic Resilience Processes in Development.Document12 pagesOrdinary Magic Resilience Processes in Development.Altikardes_Mar_5520No ratings yet
- System Sequence of Events State: United StatesDocument3 pagesSystem Sequence of Events State: United StatesHong JooNo ratings yet
- EpidemicModeling s20 SkvortsovDocument6 pagesEpidemicModeling s20 SkvortsovFadli RizkiandiNo ratings yet
- 2018 - 01 - 01 A Human Environmental Network Model For Assessing Coastal Global Environment - Small and XianDocument9 pages2018 - 01 - 01 A Human Environmental Network Model For Assessing Coastal Global Environment - Small and XianIwan AmirNo ratings yet
- (Gabriel A. Radvansky, Jeffrey M. Zacks) Event Cog (Z-Lib - Org) - 3Document25 pages(Gabriel A. Radvansky, Jeffrey M. Zacks) Event Cog (Z-Lib - Org) - 3Judy Costanza BeltránNo ratings yet
- Mining The Web To Predict Future EventsDocument10 pagesMining The Web To Predict Future EventsDevadasRajaramNo ratings yet
- Detecting Gene-Gene Interactions That Underlie Human DiseasesDocument13 pagesDetecting Gene-Gene Interactions That Underlie Human DiseasesBalaji NarayananNo ratings yet
- The Board of Regents of The University of Wisconsin SystemDocument23 pagesThe Board of Regents of The University of Wisconsin Systemsanta171No ratings yet
- Insr12271 AmDocument39 pagesInsr12271 AmUdita GoswamiNo ratings yet
- Bayesian Latent Variable Models For Mixed Discrete OutcomesDocument15 pagesBayesian Latent Variable Models For Mixed Discrete OutcomesAnonymous 4gOYyVfdfNo ratings yet
- Counter FDocument13 pagesCounter FAlejandra ParraNo ratings yet
- Disaster World: Decision-Theoretic Agents For Simulating Population Responses To HurricanesDocument34 pagesDisaster World: Decision-Theoretic Agents For Simulating Population Responses To HurricanesLuis Fernando ZhininNo ratings yet
- Probability Theory and Stochastic ProcessesDocument155 pagesProbability Theory and Stochastic ProcessesPavani0% (1)
- Dynamic Decision Making: What Do People Do?: John D. Hey Luca PanaccioneDocument39 pagesDynamic Decision Making: What Do People Do?: John D. Hey Luca PanaccioneMatteo MasottiNo ratings yet
- Add Math 2010 Project WorkDocument38 pagesAdd Math 2010 Project WorkAhmad Firdaus86% (22)
- tmp419D TMPDocument10 pagestmp419D TMPFrontiersNo ratings yet
- 2024 - Geiß - Anticipating A Risky Future - Long Short-Term Memory LSTM Models For Spatiotemporal Extrapolation of Population Data in Areas Prone To Earthquakes and Tsunamis in Lima PeruDocument14 pages2024 - Geiß - Anticipating A Risky Future - Long Short-Term Memory LSTM Models For Spatiotemporal Extrapolation of Population Data in Areas Prone To Earthquakes and Tsunamis in Lima PerusophieNo ratings yet
- Risk Preferences Are Not Time PreferencesDocument42 pagesRisk Preferences Are Not Time PreferencesTouhid AkramNo ratings yet
- Causal Diagrams in Systems Epidemiology: Analyticperspective Open AccessDocument18 pagesCausal Diagrams in Systems Epidemiology: Analyticperspective Open AccessShopzynkNo ratings yet
- Statistical ModelingDocument18 pagesStatistical ModelingWahyu S. Ginanjar100% (1)
- Particle emission concept and probabilistic consideration of the development of infections in systems: Dynamics from logarithm and exponent in the infection process, percolation effectsFrom EverandParticle emission concept and probabilistic consideration of the development of infections in systems: Dynamics from logarithm and exponent in the infection process, percolation effectsNo ratings yet
- Linear and Generalized Linear Mixed Models and Their ApplicationsFrom EverandLinear and Generalized Linear Mixed Models and Their ApplicationsNo ratings yet
- Charting the Next Pandemic: Modeling Infectious Disease Spreading in the Data Science AgeFrom EverandCharting the Next Pandemic: Modeling Infectious Disease Spreading in the Data Science AgeNo ratings yet
- The Cybernetic Theory of Decision: New Dimensions of Political AnalysisFrom EverandThe Cybernetic Theory of Decision: New Dimensions of Political AnalysisRating: 3.5 out of 5 stars3.5/5 (4)
- Standard DeviationDocument22 pagesStandard DeviationPriya VermaNo ratings yet
- Domestic Company Notams 16 Jan 18Document41 pagesDomestic Company Notams 16 Jan 18Swastika MishraNo ratings yet
- Kaylee Analco - Calorimetry GizmosDocument7 pagesKaylee Analco - Calorimetry GizmosKaylee Analco100% (1)
- Infinity Other Solar Systems: TrinityDocument1 pageInfinity Other Solar Systems: TrinityP Eng Suraj SinghNo ratings yet
- Calculate InflationDocument2 pagesCalculate InflationNafees AhmadNo ratings yet
- 14.udemy S4hana Course MaterialDocument53 pages14.udemy S4hana Course MaterialArben LaçiNo ratings yet
- The Effect of Temperature On The PH Level of Lemon JuiceDocument12 pagesThe Effect of Temperature On The PH Level of Lemon JuicekjfanmNo ratings yet
- E-Terragridcom DIP Brochure GBDocument4 pagesE-Terragridcom DIP Brochure GBNeelakandan MasilamaniNo ratings yet
- Light: 1.1 Light Travels in Straight LinesDocument11 pagesLight: 1.1 Light Travels in Straight Linesching_jyoNo ratings yet
- Personalized Movie Hybrid Recommendation Model Based On GRUDocument4 pagesPersonalized Movie Hybrid Recommendation Model Based On GRUMritunjay JhaNo ratings yet
- Operations Management - Chapter 12Document11 pagesOperations Management - Chapter 12David Van De FliertNo ratings yet
- High Impedance Fault Detection Using Multi Domain Feature With Artificial Neural NetworkDocument15 pagesHigh Impedance Fault Detection Using Multi Domain Feature With Artificial Neural NetworkANKAN CHANDRANo ratings yet
- Cs101 Program Logic Formulation 1Document4 pagesCs101 Program Logic Formulation 1Multiple Criteria DssNo ratings yet
- 11 ProbDocument2 pages11 Probachandra100% (1)
- Netzer DS-58 SpecsheetDocument6 pagesNetzer DS-58 SpecsheetElectromateNo ratings yet
- Underground SurveyingDocument5 pagesUnderground SurveyingErick AlanNo ratings yet
- LLC3kW GUI ManualDocument8 pagesLLC3kW GUI Manualreferenceref31No ratings yet
- Operating Principles of Electronic Engine Management SystemsDocument6 pagesOperating Principles of Electronic Engine Management SystemsVaishali Wagh100% (2)
- Technical Information and Variances.: Spec/Feature Vst-Se VST-Mini CommentsDocument1 pageTechnical Information and Variances.: Spec/Feature Vst-Se VST-Mini CommentsAhmadNo ratings yet
- Grade (10) Chapter - 11 TrigonometryDocument21 pagesGrade (10) Chapter - 11 TrigonometryZakir Amad 32100% (1)
- Chapter - 1-QMDocument56 pagesChapter - 1-QMtebelayhabitamu12No ratings yet
- Solvent Separation UNIT-06 - GOODDocument17 pagesSolvent Separation UNIT-06 - GOODAamir HasanNo ratings yet
- AXSS-II Access Control Configuration Guide: Enterprise Buildings IntegratorDocument128 pagesAXSS-II Access Control Configuration Guide: Enterprise Buildings IntegratorJaime AvellaNo ratings yet
- Expansion Cabinet RFDS: 6802800U74-AP Chapter 7: Radio Frequency Distribution SystemDocument201 pagesExpansion Cabinet RFDS: 6802800U74-AP Chapter 7: Radio Frequency Distribution SystemHamza AldeebNo ratings yet
- Characteristics of The Analog ComputersDocument5 pagesCharacteristics of The Analog Computersmanju_csNo ratings yet
- Linear Algebra and Random Processes (CS6015)Document5 pagesLinear Algebra and Random Processes (CS6015)CHAKRADHAR PALAVALASANo ratings yet
- Basis Certification 2003Document19 pagesBasis Certification 2003Amier Omar Al MousyNo ratings yet
- Data Sheet US - W3G910GU2201 KM89187Document7 pagesData Sheet US - W3G910GU2201 KM89187Bruno Cezar FurlinNo ratings yet
- 1.3 Analytical Chemistry 1Document17 pages1.3 Analytical Chemistry 1zedrickNo ratings yet