Download as pdf or txt
You might also like
- Ultimate CPU GPU BoostDocument2 pagesUltimate CPU GPU BoostOmm Go Suyajare89% (19)
- Programmable Logic Controllers LogixPro PLC Lab Manual (5th Ed.)Document180 pagesProgrammable Logic Controllers LogixPro PLC Lab Manual (5th Ed.)RAUL NNo ratings yet
- Design Document For An Object Detection Application Using OpenCVDocument14 pagesDesign Document For An Object Detection Application Using OpenCVAMEEMA ARIFNo ratings yet
- Operating System FundamentalsDocument109 pagesOperating System FundamentalsGuruKPO100% (3)
- PacFactory User Manual of INGESYSDocument170 pagesPacFactory User Manual of INGESYSAgung Chrisyancandra MobonguniNo ratings yet
- Parallel ProcessingDocument22 pagesParallel Processingsouravmittal2023No ratings yet
- 3a FlynnsDocument17 pages3a FlynnsHitarth Anand RohraNo ratings yet
- Parallel and Distributed ComputingDocument90 pagesParallel and Distributed ComputingWell WisherNo ratings yet
- Management Information System: Ghulam Yasin Hajvery University LahoreDocument42 pagesManagement Information System: Ghulam Yasin Hajvery University LahoreBilawal ShabbirNo ratings yet
- Parallel ProcessingDocument35 pagesParallel ProcessingGetu GeneneNo ratings yet
- Technical Seminar Report On: "High Performance Computing"Document14 pagesTechnical Seminar Report On: "High Performance Computing"mit_thakkar_2No ratings yet
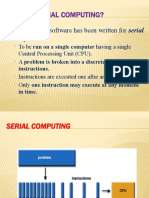
- What Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDocument22 pagesWhat Is Serial Computing?: Traditionally, Software Has Been Written For Serial ComputationDivya NigamNo ratings yet
- CC UNIT-1 MaterialDocument26 pagesCC UNIT-1 Materialarvindreddy013No ratings yet
- 24-25 - Parallel Processing PDFDocument36 pages24-25 - Parallel Processing PDFfanna786No ratings yet
- CA Unit IV Notes Part 1 PDFDocument17 pagesCA Unit IV Notes Part 1 PDFaarockiaabins AP - II - CSENo ratings yet
- Aca NotesDocument148 pagesAca NotesHanisha BavanaNo ratings yet
- Parallel Computer Models: PCA Chapter 1Document61 pagesParallel Computer Models: PCA Chapter 1AYUSH KUMARNo ratings yet
- UNIT 2 Cloud ComputingDocument18 pagesUNIT 2 Cloud ComputingRajput ShreeyaNo ratings yet
- ACA Unit. 1 Parallel ProcessingDocument10 pagesACA Unit. 1 Parallel Processingrogersalex294No ratings yet
- Parallel and Distributed ComputingDocument24 pagesParallel and Distributed ComputingOPNo ratings yet
- Cloud Computing - Lecture 3Document22 pagesCloud Computing - Lecture 3Muhammad FahadNo ratings yet
- Need For Memory Hierarchy: (Unit-1,3) (M.M. Chapter 12)Document23 pagesNeed For Memory Hierarchy: (Unit-1,3) (M.M. Chapter 12)Alvin Soriano AdduculNo ratings yet
- Unit VI Parallel Programming ConceptsDocument90 pagesUnit VI Parallel Programming ConceptsPrathameshNo ratings yet
- PDC Assignment 1Document5 pagesPDC Assignment 1Samavia RiazNo ratings yet
- CA Document 1Document8 pagesCA Document 1ToobaNo ratings yet
- Parallel ProcessingDocument31 pagesParallel ProcessingSantosh SinghNo ratings yet
- UNIT IVDocument31 pagesUNIT IVlokeshsundarmiuiNo ratings yet
- 1 of 1 PDFDocument7 pages1 of 1 PDFpatasutoshNo ratings yet
- Parallel ComputingDocument32 pagesParallel ComputingKhushal BisaniNo ratings yet
- Unit 1 NotesDocument31 pagesUnit 1 NotesRanjith SKNo ratings yet
- Parallel Computing (Unit5)Document25 pagesParallel Computing (Unit5)Shriniwas YadavNo ratings yet
- CS0051 - Module 01Document52 pagesCS0051 - Module 01Ron BayaniNo ratings yet
- Large Computer Systems and Pipelining: HomeworkDocument11 pagesLarge Computer Systems and Pipelining: HomeworkRyan ReyesNo ratings yet
- Parallel Computing: Er. Anupama Singh Department of Computer Science & EnggDocument22 pagesParallel Computing: Er. Anupama Singh Department of Computer Science & EnggVinay GuptaNo ratings yet
- Parallel Algorithm - Intro and Computational ModelsDocument5 pagesParallel Algorithm - Intro and Computational ModelszololuxyNo ratings yet
- ACA Assignment 4Document16 pagesACA Assignment 4shresth choudharyNo ratings yet
- Lecture 1 - Parallel and Distributed ComputingDocument25 pagesLecture 1 - Parallel and Distributed ComputingSibgha IsrarNo ratings yet
- CS0051 - M1-Parallel Computing HardwareDocument36 pagesCS0051 - M1-Parallel Computing HardwareNATHANIEL LAMPREANo ratings yet
- SIMD ArchitectureDocument16 pagesSIMD Architecturebinzidd007100% (1)
- 01 Intro Parallel ComputingDocument40 pages01 Intro Parallel ComputingHilmy MuhammadNo ratings yet
- Types of Parallel ComputingDocument11 pagesTypes of Parallel Computingprakashvivek990No ratings yet
- Coa Unit-3,4 NotesDocument17 pagesCoa Unit-3,4 NotesDeepanshu krNo ratings yet
- Cloud ComputingDocument27 pagesCloud ComputingmanojNo ratings yet
- 5 Marks Q. Describe Array Processor ArchitectureDocument11 pages5 Marks Q. Describe Array Processor ArchitectureGaurav BiswasNo ratings yet
- Ca Unit 4 PrabuDocument24 pagesCa Unit 4 Prabu6109 Sathish Kumar JNo ratings yet
- IntroductionDocument34 pagesIntroductionjosephboyong542No ratings yet
- Lec 5Document14 pagesLec 5Sayantani DuttaNo ratings yet
- Computer Achitecture II - Parallel - ComputingDocument46 pagesComputer Achitecture II - Parallel - ComputingAbdullahi Zubairu SokombaNo ratings yet
- Mod 7Document56 pagesMod 7sania.anwar100No ratings yet
- Performance of Computers: Factors Affecting Computer PerformanceDocument4 pagesPerformance of Computers: Factors Affecting Computer Performanceom mustafa yousifNo ratings yet
- CS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesDocument47 pagesCS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesNehaNo ratings yet
- Artificial IntelligenceDocument12 pagesArtificial IntelligenceHimanshu MishraNo ratings yet
- Introduction To: Parallel DistributedDocument32 pagesIntroduction To: Parallel Distributedaliha ghaffarNo ratings yet
- Week1 - Parallel and Distributed ComputingDocument46 pagesWeek1 - Parallel and Distributed ComputingA NNo ratings yet
- Hardware MultithreadingDocument10 pagesHardware MultithreadingFarin KhanNo ratings yet
- CS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesDocument33 pagesCS326 Parallel and Distributed Computing: SPRING 2021 National University of Computer and Emerging SciencesNehaNo ratings yet
- CP4253 Map Unit IDocument31 pagesCP4253 Map Unit INivi VNo ratings yet
- Synopsis On "Massive Parallel Processing (MPP) "Document4 pagesSynopsis On "Massive Parallel Processing (MPP) "Jyoti PunhaniNo ratings yet
- Bit-Level ParallelismDocument3 pagesBit-Level ParallelismSHAMEEK PATHAKNo ratings yet
- Untitled DocumentDocument24 pagesUntitled Documentdihosid99No ratings yet
- Introduction To Parallel and Distributed ComputingDocument29 pagesIntroduction To Parallel and Distributed ComputingBerto ZerimarNo ratings yet
- Multiprocessor Is A Computer Used For Processing and Executes IsolatedDocument6 pagesMultiprocessor Is A Computer Used For Processing and Executes IsolatedAnubhav KumarNo ratings yet
- Chapter - 5 Multiprocessors and Thread-Level Parallelism: A Taxonomy of Parallel ArchitecturesDocument41 pagesChapter - 5 Multiprocessors and Thread-Level Parallelism: A Taxonomy of Parallel ArchitecturesraghvendrmNo ratings yet
- Operating Systems Interview Questions You'll Most Likely Be AskedFrom EverandOperating Systems Interview Questions You'll Most Likely Be AskedNo ratings yet
- Computer Science: Learn about Algorithms, Cybersecurity, Databases, Operating Systems, and Web DesignFrom EverandComputer Science: Learn about Algorithms, Cybersecurity, Databases, Operating Systems, and Web DesignNo ratings yet
- The Urban Sketching Handbook Drawing With A Tablet Easy Techniques For Mastering Digital Drawing On Location (Uma Kelkar) (Z-Library)Document164 pagesThe Urban Sketching Handbook Drawing With A Tablet Easy Techniques For Mastering Digital Drawing On Location (Uma Kelkar) (Z-Library)miguel100% (1)
- Introduction To Programming CS 114Document2 pagesIntroduction To Programming CS 114fykkNo ratings yet
- SCOTTISH MOTORHOME CAMPERVAN ADVENTURES Group MapDocument9 pagesSCOTTISH MOTORHOME CAMPERVAN ADVENTURES Group MapstevenburnsNo ratings yet
- SAP Fiori: Zhenna Na Cloud Success ServicesDocument47 pagesSAP Fiori: Zhenna Na Cloud Success ServicesDurwanNo ratings yet
- Quickspecs: HP 240 G7 Notebook PCDocument39 pagesQuickspecs: HP 240 G7 Notebook PCHardikNo ratings yet
- CS6008 - Hci MCQDocument23 pagesCS6008 - Hci MCQPavithra JanarthananNo ratings yet
- Maya Lab 2Document1 pageMaya Lab 2MonoNo ratings yet
- Taylors Gmo Inbound Exchange Module Guide 2022 v060921Document84 pagesTaylors Gmo Inbound Exchange Module Guide 2022 v060921Fahad FarhanNo ratings yet
- ETQ Reliance Application Overview - Document ControlDocument3 pagesETQ Reliance Application Overview - Document ControlJulie julNo ratings yet
- Introduction and Installation: Composer ™Document60 pagesIntroduction and Installation: Composer ™Karim MagdyNo ratings yet
- Crash 2023 08 26 - 14.14.05 ClientDocument7 pagesCrash 2023 08 26 - 14.14.05 ClientGustavo CogoNo ratings yet
- GeometryGym-Quick Start Guide-Parametric Structural Analysis - V1Document63 pagesGeometryGym-Quick Start Guide-Parametric Structural Analysis - V1CarsonBaker100% (1)
- Implementing Client Virtualization and Cloud ComputingDocument33 pagesImplementing Client Virtualization and Cloud ComputingEthan BooisNo ratings yet
- CS2002Document2 pagesCS2002Satya DasNo ratings yet
- Uniformance ToolsDocument244 pagesUniformance ToolsMohammad Ivan HariyantoNo ratings yet
- c3 ANSYS TutorialsDocument107 pagesc3 ANSYS TutorialsMark Dominic KipkorirNo ratings yet
- Sifive Interrupt CookbookDocument34 pagesSifive Interrupt Cookbookrose jackNo ratings yet
- Pcon - Planner FunctionsDocument5 pagesPcon - Planner FunctionsQuiteño AlessandroNo ratings yet
- Chapter 1 Introduction 1 1 IntroductionDocument34 pagesChapter 1 Introduction 1 1 IntroductionBeet LalNo ratings yet
- SyllabusDocument9 pagesSyllabusNerdNo ratings yet
- Palm 3245ww - Wireless - Keyboard - With - Bluetooth - Technology 1Document18 pagesPalm 3245ww - Wireless - Keyboard - With - Bluetooth - Technology 1LUIZ FACIOLINo ratings yet
- Light Brown Beige Modern Scrapbook Travel Brand Guidelines PresentationDocument13 pagesLight Brown Beige Modern Scrapbook Travel Brand Guidelines Presentationnadahot492No ratings yet
- Task 3 EssayDocument4 pagesTask 3 Essayapi-548978026No ratings yet
- M2M GEKKO Specifications Sheet - 8 - 5x11 01Document4 pagesM2M GEKKO Specifications Sheet - 8 - 5x11 01刘晖No ratings yet
- Free Bitco - in Wining ScriptDocument21 pagesFree Bitco - in Wining Scripttech the world parwatNo ratings yet