
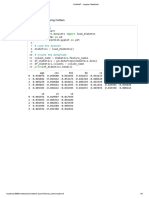
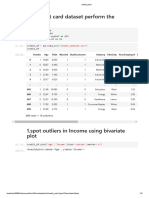
Bank Customer Churn Analysis - Jupyter Notebook
Bank Customer Churn Analysis - Jupyter Notebook
You might also like
- Machine Learning Project Problem 1 Jupyter Notebook PDFDocument85 pagesMachine Learning Project Problem 1 Jupyter Notebook PDFsonali Pradhan100% (5)
- Uber - Analysis - Jupyter - NotebookDocument10 pagesUber - Analysis - Jupyter - NotebookAnurag Singh100% (1)
- CAF 1 - Accounting For PartnershipDocument48 pagesCAF 1 - Accounting For PartnershipAhsan Kamran100% (1)
- Germany Credit AnalysisDocument41 pagesGermany Credit AnalysisAndrew EngNo ratings yet
- Churn For Bank CustomersDocument28 pagesChurn For Bank CustomersKrutika SapkalNo ratings yet
- Churn Prediction ModelDocument36 pagesChurn Prediction ModelkarthikeyanNo ratings yet
- # Importing: Import From Import Import As Import AsDocument6 pages# Importing: Import From Import Import As Import AsCH VISHNUPRIYA 22111514No ratings yet
- Week 4 LABDocument26 pagesWeek 4 LABtarunbinjadagi18No ratings yet
- Data Visualization On Pandas - Jupyter NotebookDocument7 pagesData Visualization On Pandas - Jupyter Notebookclassfunction9No ratings yet
- 07bRegresionLinealBostonVerdConEstandarizacion - Jupyter NotebookDocument17 pages07bRegresionLinealBostonVerdConEstandarizacion - Jupyter NotebookJIMMY CRISTHIAN CJURO APAZANo ratings yet
- Pembersihan Data ScriptDocument2 pagesPembersihan Data Scriptbagus arimanuNo ratings yet
- 07aRegresionLinealBostonVerdSinEstandarizacion - Jupyter NotebookDocument15 pages07aRegresionLinealBostonVerdSinEstandarizacion - Jupyter NotebookJIMMY CRISTHIAN CJURO APAZANo ratings yet
- Ensemble Techniques ProjectDocument28 pagesEnsemble Techniques ProjectVishweshRaviShrimali100% (2)
- Customer Retention in BankDocument27 pagesCustomer Retention in BankHarun ul Rasheed ShaikNo ratings yet
- Pyt Manual 1Document85 pagesPyt Manual 1Hrithik KumarNo ratings yet
- 27 Jupyter NotebookDocument42 pages27 Jupyter NotebookJonathan VillanuevaNo ratings yet
- DS - Assig-03-Part-I - Jupyter NotebookDocument8 pagesDS - Assig-03-Part-I - Jupyter NotebookYash ShindeNo ratings yet
- SMDM Project Gopala Satish Kumar Jupyter Notebook G8 DSBADocument14 pagesSMDM Project Gopala Satish Kumar Jupyter Notebook G8 DSBASatish Kumar100% (1)
- Loading The Dataset: Import As Import As Import As Import As From Import From Import From Import From Import From ImportDocument3 pagesLoading The Dataset: Import As Import As Import As Import As From Import From Import From Import From Import From ImportDivyani ChavanNo ratings yet
- Reset: Runfile (, Wdir)Document8 pagesReset: Runfile (, Wdir)indreshnaithani40No ratings yet
- Loading The Dataset: 'Churn - Modelling - CSV'Document6 pagesLoading The Dataset: 'Churn - Modelling - CSV'Divyani ChavanNo ratings yet
- Week 6 LABDocument13 pagesWeek 6 LABtarunbinjadagi18No ratings yet
- Heart Disease Classification ML Assignment - Jupyter NotebookDocument7 pagesHeart Disease Classification ML Assignment - Jupyter Notebookfurole sammyceNo ratings yet
- Import Numpy As NP Import Pandas As PDDocument7 pagesImport Numpy As NP Import Pandas As PDShripad HNo ratings yet
- Amazon Product Review - Ipynb - ColaboratoryDocument7 pagesAmazon Product Review - Ipynb - ColaboratoryThomas ShelbyNo ratings yet
- ML File FinalDocument11 pagesML File FinalGautam SharmaNo ratings yet
- Sakthi Vinayakar Hindu Vidyalaya: Academic Year 2021-22Document21 pagesSakthi Vinayakar Hindu Vidyalaya: Academic Year 2021-22Nithesh MNo ratings yet
- Assignment 2 - Jupyter NotebookDocument8 pagesAssignment 2 - Jupyter NotebookMahakNo ratings yet
- Ip Project On Credit Card AnalysisDocument48 pagesIp Project On Credit Card Analysisshikhaashish1587No ratings yet
- PandasDocument82 pagesPandasaacharyadhruv1310No ratings yet
- C2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsDocument38 pagesC2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsSarah Mendes100% (1)
- Bits Pilani, Dubai CampusDocument11 pagesBits Pilani, Dubai CampussatyaNo ratings yet
- Unit10 QB VHADocument36 pagesUnit10 QB VHAdaku5246No ratings yet
- 1.diagnosis Using MLDocument69 pages1.diagnosis Using MLChoral WealthNo ratings yet
- Bank Term Deposit 877b04Document61 pagesBank Term Deposit 877b0420BEC098 PANKAJNo ratings yet
- Modulo 4 - EDA - Ipynb - ColaboratoryDocument21 pagesModulo 4 - EDA - Ipynb - ColaboratoryJardeilson NascimentoNo ratings yet
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Document11 pagesML0101EN Clas K Nearest Neighbors CustCat Py v1banicx100% (1)
- Statistical Learning Project: Ques 1 - Import The Necessary LibrariesDocument16 pagesStatistical Learning Project: Ques 1 - Import The Necessary LibrariesHarsh SinghNo ratings yet
- Customer Segmentation With K-Means and RMFDocument13 pagesCustomer Segmentation With K-Means and RMFmoinNo ratings yet
- DL (Pra 01)Document9 pagesDL (Pra 01)Dhanashri SalunkheNo ratings yet
- Coding TitanicmainDocument58 pagesCoding Titanicmainnaderaqistina23No ratings yet
- 4c Sklearn-Classification-Regression-Bkhw-Spring 2019Document20 pages4c Sklearn-Classification-Regression-Bkhw-Spring 2019Radhika KhandelwalNo ratings yet
- Bangluru IpDocument6 pagesBangluru IpNamita SahuNo ratings yet
- Decision TreeDocument12 pagesDecision TreeKagade AjinkyaNo ratings yet
- Ip Worksheet 2 XiiDocument4 pagesIp Worksheet 2 XiiIndu GoyalNo ratings yet
- Computer Science ProjectDocument104 pagesComputer Science ProjectShashank KumarNo ratings yet
- Record DSCP508 - DV-1-1Document89 pagesRecord DSCP508 - DV-1-1cse2021criteria3No ratings yet
- Ip Project (Ekagra & Naman)Document23 pagesIp Project (Ekagra & Naman)satpal singhNo ratings yet
- Logistic Regression - Session 6 & 7Document15 pagesLogistic Regression - Session 6 & 7Vinayak KharbandaNo ratings yet
- Exploratory Data AnalysisDocument10 pagesExploratory Data AnalysisStrong ManNo ratings yet
- # Import Plotting Libraries: in (1) : Import Pandas As PDDocument13 pages# Import Plotting Libraries: in (1) : Import Pandas As PDJoe1No ratings yet
- ML LAB Mannual - IndexDocument29 pagesML LAB Mannual - IndexNisahd hiteshNo ratings yet
- DWDM Lab Manual FinalDocument153 pagesDWDM Lab Manual FinalVaahnikaNo ratings yet
- CS ProjectDocument45 pagesCS ProjectRishabh Raj100% (1)
- Final ReportDocument10 pagesFinal ReportDiya ChandnaniNo ratings yet
- Pandas NotesDocument54 pagesPandas NotesSáñtôsh KùmãrNo ratings yet
- Tiktok Review FinaleDocument27 pagesTiktok Review FinaleANIS NABIHAH BINTI MOHD JAISNo ratings yet
- 11 Amazon Fine Food Reviews Analysis - Truncated SVD - WIP - Jupyter NotebookDocument22 pages11 Amazon Fine Food Reviews Analysis - Truncated SVD - WIP - Jupyter Notebooksandeep sasidharanNo ratings yet
- Assignment Instructions:: Import AsDocument1 pageAssignment Instructions:: Import AsTayub khan.ANo ratings yet
- Real EstateDocument10 pagesReal EstateMuskaanNo ratings yet
- TroubleshootingDocument12 pagesTroubleshootingCraig KalinowskiNo ratings yet
- Ananta Tsabita Agustina (06) Second PortofolioDocument8 pagesAnanta Tsabita Agustina (06) Second PortofolioAnanta TsabitaNo ratings yet
- IR7243 en ModuloDocument2 pagesIR7243 en ModuloAitor Tapia SaavedraNo ratings yet
- Load Line and Q-PointDocument3 pagesLoad Line and Q-PointRavi Kanth M NNo ratings yet
- Ansys - WS20 - BladeModelerDocument20 pagesAnsys - WS20 - BladeModelercoolkaisy100% (1)
- Alive Feb 10Document66 pagesAlive Feb 10javed.alam19No ratings yet
- Interface Programming With LED: Ex. No 5aDocument4 pagesInterface Programming With LED: Ex. No 5aPrajwal B NaikNo ratings yet
- City Limits Magazine, November 2000 IssueDocument52 pagesCity Limits Magazine, November 2000 IssueCity Limits (New York)No ratings yet
- Aws WHB2 CH25Document30 pagesAws WHB2 CH25Alex SalasNo ratings yet
- Deep WorkDocument2 pagesDeep Workbama33% (6)
- AMF-120 K4 FenceDocument1 pageAMF-120 K4 FenceAnupam AjayanNo ratings yet
- Resume OF Md. Moshiur Rahman: Higher Secondary Certificate (HSC)Document2 pagesResume OF Md. Moshiur Rahman: Higher Secondary Certificate (HSC)Decor Interior LtdNo ratings yet
- Art 19 RPCDocument5 pagesArt 19 RPCHappynako Wholesome100% (1)
- Vscan Air Product DatasheetDocument6 pagesVscan Air Product DatasheetiosifsorinNo ratings yet
- 520 qs001 - en e PDFDocument36 pages520 qs001 - en e PDFvantiencdtk7No ratings yet
- Thesis Group 2Document6 pagesThesis Group 2Michael Dimayuga100% (8)
- Presentacion IlearnDocument38 pagesPresentacion IlearnAnonymous ffje1rpaNo ratings yet
- Differences Between Hypertext, Hypermedia and MultimediaDocument7 pagesDifferences Between Hypertext, Hypermedia and MultimediaEdison Alarcón90% (20)
- Resume Bryce Geh RlsDocument2 pagesResume Bryce Geh Rlsdylanmore1223No ratings yet
- Materials Science: Material Selection Classes of Material Properties Properties of MaterialsDocument23 pagesMaterials Science: Material Selection Classes of Material Properties Properties of MaterialsAtul PandeyNo ratings yet
- Elections in The Internet AgeDocument30 pagesElections in The Internet AgeMaricel P. GopitaNo ratings yet
- Proceed FormulationsDocument18 pagesProceed FormulationssudhirchughNo ratings yet
- History Themes in Indian History Part 3 Class 12Document188 pagesHistory Themes in Indian History Part 3 Class 12Berlin BerlinNo ratings yet
- F33 - Mall of Emirates Metro To Al Barsha 3 Dubai Bus Service TimetableDocument4 pagesF33 - Mall of Emirates Metro To Al Barsha 3 Dubai Bus Service TimetableDubai Q&ANo ratings yet
- Chapter No.1 - Introduction To Personal SellingDocument52 pagesChapter No.1 - Introduction To Personal SellingAyush100% (1)
- ATADU2002 DatasheetDocument3 pagesATADU2002 DatasheethindNo ratings yet
- Section 1 - 1Document22 pagesSection 1 - 1Shan AgharrNo ratings yet
- 6020 & 6040 SERIES Environmental Chambers Operations Manual For Models 6020, 6021, 6022, 6023, 6025, 6027 6040, 6041, 6042, 6043, 6045, 6047Document66 pages6020 & 6040 SERIES Environmental Chambers Operations Manual For Models 6020, 6021, 6022, 6023, 6025, 6027 6040, 6041, 6042, 6043, 6045, 6047Walter RomeroNo ratings yet
- PHY 107 Experiment 1Document6 pagesPHY 107 Experiment 1Aisha AwaisuNo ratings yet
























































































Download as pdf or txt
You might also like
- Machine Learning Project Problem 1 Jupyter Notebook PDFDocument85 pagesMachine Learning Project Problem 1 Jupyter Notebook PDFsonali Pradhan100% (5)
- Uber - Analysis - Jupyter - NotebookDocument10 pagesUber - Analysis - Jupyter - NotebookAnurag Singh100% (1)
- CAF 1 - Accounting For PartnershipDocument48 pagesCAF 1 - Accounting For PartnershipAhsan Kamran100% (1)
- Germany Credit AnalysisDocument41 pagesGermany Credit AnalysisAndrew EngNo ratings yet
- Churn For Bank CustomersDocument28 pagesChurn For Bank CustomersKrutika SapkalNo ratings yet
- Churn Prediction ModelDocument36 pagesChurn Prediction ModelkarthikeyanNo ratings yet
- # Importing: Import From Import Import As Import AsDocument6 pages# Importing: Import From Import Import As Import AsCH VISHNUPRIYA 22111514No ratings yet
- Week 4 LABDocument26 pagesWeek 4 LABtarunbinjadagi18No ratings yet
- Data Visualization On Pandas - Jupyter NotebookDocument7 pagesData Visualization On Pandas - Jupyter Notebookclassfunction9No ratings yet
- 07bRegresionLinealBostonVerdConEstandarizacion - Jupyter NotebookDocument17 pages07bRegresionLinealBostonVerdConEstandarizacion - Jupyter NotebookJIMMY CRISTHIAN CJURO APAZANo ratings yet
- Pembersihan Data ScriptDocument2 pagesPembersihan Data Scriptbagus arimanuNo ratings yet
- 07aRegresionLinealBostonVerdSinEstandarizacion - Jupyter NotebookDocument15 pages07aRegresionLinealBostonVerdSinEstandarizacion - Jupyter NotebookJIMMY CRISTHIAN CJURO APAZANo ratings yet
- Ensemble Techniques ProjectDocument28 pagesEnsemble Techniques ProjectVishweshRaviShrimali100% (2)
- Customer Retention in BankDocument27 pagesCustomer Retention in BankHarun ul Rasheed ShaikNo ratings yet
- Pyt Manual 1Document85 pagesPyt Manual 1Hrithik KumarNo ratings yet
- 27 Jupyter NotebookDocument42 pages27 Jupyter NotebookJonathan VillanuevaNo ratings yet
- DS - Assig-03-Part-I - Jupyter NotebookDocument8 pagesDS - Assig-03-Part-I - Jupyter NotebookYash ShindeNo ratings yet
- SMDM Project Gopala Satish Kumar Jupyter Notebook G8 DSBADocument14 pagesSMDM Project Gopala Satish Kumar Jupyter Notebook G8 DSBASatish Kumar100% (1)
- Loading The Dataset: Import As Import As Import As Import As From Import From Import From Import From Import From ImportDocument3 pagesLoading The Dataset: Import As Import As Import As Import As From Import From Import From Import From Import From ImportDivyani ChavanNo ratings yet
- Reset: Runfile (, Wdir)Document8 pagesReset: Runfile (, Wdir)indreshnaithani40No ratings yet
- Loading The Dataset: 'Churn - Modelling - CSV'Document6 pagesLoading The Dataset: 'Churn - Modelling - CSV'Divyani ChavanNo ratings yet
- Week 6 LABDocument13 pagesWeek 6 LABtarunbinjadagi18No ratings yet
- Heart Disease Classification ML Assignment - Jupyter NotebookDocument7 pagesHeart Disease Classification ML Assignment - Jupyter Notebookfurole sammyceNo ratings yet
- Import Numpy As NP Import Pandas As PDDocument7 pagesImport Numpy As NP Import Pandas As PDShripad HNo ratings yet
- Amazon Product Review - Ipynb - ColaboratoryDocument7 pagesAmazon Product Review - Ipynb - ColaboratoryThomas ShelbyNo ratings yet
- ML File FinalDocument11 pagesML File FinalGautam SharmaNo ratings yet
- Sakthi Vinayakar Hindu Vidyalaya: Academic Year 2021-22Document21 pagesSakthi Vinayakar Hindu Vidyalaya: Academic Year 2021-22Nithesh MNo ratings yet
- Assignment 2 - Jupyter NotebookDocument8 pagesAssignment 2 - Jupyter NotebookMahakNo ratings yet
- Ip Project On Credit Card AnalysisDocument48 pagesIp Project On Credit Card Analysisshikhaashish1587No ratings yet
- PandasDocument82 pagesPandasaacharyadhruv1310No ratings yet
- C2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsDocument38 pagesC2M2 - Assignment: 1 Risk Models Using Tree-Based ModelsSarah Mendes100% (1)
- Bits Pilani, Dubai CampusDocument11 pagesBits Pilani, Dubai CampussatyaNo ratings yet
- Unit10 QB VHADocument36 pagesUnit10 QB VHAdaku5246No ratings yet
- 1.diagnosis Using MLDocument69 pages1.diagnosis Using MLChoral WealthNo ratings yet
- Bank Term Deposit 877b04Document61 pagesBank Term Deposit 877b0420BEC098 PANKAJNo ratings yet
- Modulo 4 - EDA - Ipynb - ColaboratoryDocument21 pagesModulo 4 - EDA - Ipynb - ColaboratoryJardeilson NascimentoNo ratings yet
- ML0101EN Clas K Nearest Neighbors CustCat Py v1Document11 pagesML0101EN Clas K Nearest Neighbors CustCat Py v1banicx100% (1)
- Statistical Learning Project: Ques 1 - Import The Necessary LibrariesDocument16 pagesStatistical Learning Project: Ques 1 - Import The Necessary LibrariesHarsh SinghNo ratings yet
- Customer Segmentation With K-Means and RMFDocument13 pagesCustomer Segmentation With K-Means and RMFmoinNo ratings yet
- DL (Pra 01)Document9 pagesDL (Pra 01)Dhanashri SalunkheNo ratings yet
- Coding TitanicmainDocument58 pagesCoding Titanicmainnaderaqistina23No ratings yet
- 4c Sklearn-Classification-Regression-Bkhw-Spring 2019Document20 pages4c Sklearn-Classification-Regression-Bkhw-Spring 2019Radhika KhandelwalNo ratings yet
- Bangluru IpDocument6 pagesBangluru IpNamita SahuNo ratings yet
- Decision TreeDocument12 pagesDecision TreeKagade AjinkyaNo ratings yet
- Ip Worksheet 2 XiiDocument4 pagesIp Worksheet 2 XiiIndu GoyalNo ratings yet
- Computer Science ProjectDocument104 pagesComputer Science ProjectShashank KumarNo ratings yet
- Record DSCP508 - DV-1-1Document89 pagesRecord DSCP508 - DV-1-1cse2021criteria3No ratings yet
- Ip Project (Ekagra & Naman)Document23 pagesIp Project (Ekagra & Naman)satpal singhNo ratings yet
- Logistic Regression - Session 6 & 7Document15 pagesLogistic Regression - Session 6 & 7Vinayak KharbandaNo ratings yet
- Exploratory Data AnalysisDocument10 pagesExploratory Data AnalysisStrong ManNo ratings yet
- # Import Plotting Libraries: in (1) : Import Pandas As PDDocument13 pages# Import Plotting Libraries: in (1) : Import Pandas As PDJoe1No ratings yet
- ML LAB Mannual - IndexDocument29 pagesML LAB Mannual - IndexNisahd hiteshNo ratings yet
- DWDM Lab Manual FinalDocument153 pagesDWDM Lab Manual FinalVaahnikaNo ratings yet
- CS ProjectDocument45 pagesCS ProjectRishabh Raj100% (1)
- Final ReportDocument10 pagesFinal ReportDiya ChandnaniNo ratings yet
- Pandas NotesDocument54 pagesPandas NotesSáñtôsh KùmãrNo ratings yet
- Tiktok Review FinaleDocument27 pagesTiktok Review FinaleANIS NABIHAH BINTI MOHD JAISNo ratings yet
- 11 Amazon Fine Food Reviews Analysis - Truncated SVD - WIP - Jupyter NotebookDocument22 pages11 Amazon Fine Food Reviews Analysis - Truncated SVD - WIP - Jupyter Notebooksandeep sasidharanNo ratings yet
- Assignment Instructions:: Import AsDocument1 pageAssignment Instructions:: Import AsTayub khan.ANo ratings yet
- Real EstateDocument10 pagesReal EstateMuskaanNo ratings yet
- TroubleshootingDocument12 pagesTroubleshootingCraig KalinowskiNo ratings yet
- Ananta Tsabita Agustina (06) Second PortofolioDocument8 pagesAnanta Tsabita Agustina (06) Second PortofolioAnanta TsabitaNo ratings yet
- IR7243 en ModuloDocument2 pagesIR7243 en ModuloAitor Tapia SaavedraNo ratings yet
- Load Line and Q-PointDocument3 pagesLoad Line and Q-PointRavi Kanth M NNo ratings yet
- Ansys - WS20 - BladeModelerDocument20 pagesAnsys - WS20 - BladeModelercoolkaisy100% (1)
- Alive Feb 10Document66 pagesAlive Feb 10javed.alam19No ratings yet
- Interface Programming With LED: Ex. No 5aDocument4 pagesInterface Programming With LED: Ex. No 5aPrajwal B NaikNo ratings yet
- City Limits Magazine, November 2000 IssueDocument52 pagesCity Limits Magazine, November 2000 IssueCity Limits (New York)No ratings yet
- Aws WHB2 CH25Document30 pagesAws WHB2 CH25Alex SalasNo ratings yet
- Deep WorkDocument2 pagesDeep Workbama33% (6)
- AMF-120 K4 FenceDocument1 pageAMF-120 K4 FenceAnupam AjayanNo ratings yet
- Resume OF Md. Moshiur Rahman: Higher Secondary Certificate (HSC)Document2 pagesResume OF Md. Moshiur Rahman: Higher Secondary Certificate (HSC)Decor Interior LtdNo ratings yet
- Art 19 RPCDocument5 pagesArt 19 RPCHappynako Wholesome100% (1)
- Vscan Air Product DatasheetDocument6 pagesVscan Air Product DatasheetiosifsorinNo ratings yet
- 520 qs001 - en e PDFDocument36 pages520 qs001 - en e PDFvantiencdtk7No ratings yet
- Thesis Group 2Document6 pagesThesis Group 2Michael Dimayuga100% (8)
- Presentacion IlearnDocument38 pagesPresentacion IlearnAnonymous ffje1rpaNo ratings yet
- Differences Between Hypertext, Hypermedia and MultimediaDocument7 pagesDifferences Between Hypertext, Hypermedia and MultimediaEdison Alarcón90% (20)
- Resume Bryce Geh RlsDocument2 pagesResume Bryce Geh Rlsdylanmore1223No ratings yet
- Materials Science: Material Selection Classes of Material Properties Properties of MaterialsDocument23 pagesMaterials Science: Material Selection Classes of Material Properties Properties of MaterialsAtul PandeyNo ratings yet
- Elections in The Internet AgeDocument30 pagesElections in The Internet AgeMaricel P. GopitaNo ratings yet
- Proceed FormulationsDocument18 pagesProceed FormulationssudhirchughNo ratings yet
- History Themes in Indian History Part 3 Class 12Document188 pagesHistory Themes in Indian History Part 3 Class 12Berlin BerlinNo ratings yet
- F33 - Mall of Emirates Metro To Al Barsha 3 Dubai Bus Service TimetableDocument4 pagesF33 - Mall of Emirates Metro To Al Barsha 3 Dubai Bus Service TimetableDubai Q&ANo ratings yet
- Chapter No.1 - Introduction To Personal SellingDocument52 pagesChapter No.1 - Introduction To Personal SellingAyush100% (1)
- ATADU2002 DatasheetDocument3 pagesATADU2002 DatasheethindNo ratings yet
- Section 1 - 1Document22 pagesSection 1 - 1Shan AgharrNo ratings yet
- 6020 & 6040 SERIES Environmental Chambers Operations Manual For Models 6020, 6021, 6022, 6023, 6025, 6027 6040, 6041, 6042, 6043, 6045, 6047Document66 pages6020 & 6040 SERIES Environmental Chambers Operations Manual For Models 6020, 6021, 6022, 6023, 6025, 6027 6040, 6041, 6042, 6043, 6045, 6047Walter RomeroNo ratings yet
- PHY 107 Experiment 1Document6 pagesPHY 107 Experiment 1Aisha AwaisuNo ratings yet