Download as pdf or txt
You might also like
- RPFMForDummies 2019 NovDocument32 pagesRPFMForDummies 2019 NovMartin FRAYSSENo ratings yet
- How To Use A Fillable PDF Worksheet: Step 1Document4 pagesHow To Use A Fillable PDF Worksheet: Step 1sourav goyalNo ratings yet
- Saving and Sharing DocumentDocument10 pagesSaving and Sharing DocumentCon SiosonNo ratings yet
- PDF Creation For CommonDocument7 pagesPDF Creation For CommonBayu SuhermanNo ratings yet
- How To Properly Create Small .PDF Files: It Group Training Initiative: .PDF File CreationDocument7 pagesHow To Properly Create Small .PDF Files: It Group Training Initiative: .PDF File Creationretrospect1000No ratings yet
- How To Properly Create Small .PDF Files: It Group Training Initiative: .PDF File CreationDocument7 pagesHow To Properly Create Small .PDF Files: It Group Training Initiative: .PDF File CreationShurieUNo ratings yet
- Methods To Repair Corrupted or Damaged PDFDocument11 pagesMethods To Repair Corrupted or Damaged PDFgochi bestNo ratings yet
- Jeffrey Torralba 25 Als Ls6Document16 pagesJeffrey Torralba 25 Als Ls6Jep TorralbaNo ratings yet
- ICF - 8-Lesson 3Document14 pagesICF - 8-Lesson 3Val ErosNo ratings yet
- Ms Word Module 3Document13 pagesMs Word Module 3R TECHNo ratings yet
- How To Convert PDFDocument8 pagesHow To Convert PDF1CRYPTICNo ratings yet
- Opening A Pages Format File From Mac in Microsoft WindowsDocument4 pagesOpening A Pages Format File From Mac in Microsoft WindowsrezaNo ratings yet
- Word 2016 Saving and Sharing Documents: Save and Save AsDocument8 pagesWord 2016 Saving and Sharing Documents: Save and Save AsMerlita TuralbaNo ratings yet
- Lesson 3 - Saving, Exporting and SharingDocument11 pagesLesson 3 - Saving, Exporting and SharingdavidNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For Youmds321No ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For Youmds321No ratings yet
- LO3. Saving and SharingDocument13 pagesLO3. Saving and SharingAllan TomasNo ratings yet
- How To Create PDF Files Using Cutepdf: Typical UseDocument2 pagesHow To Create PDF Files Using Cutepdf: Typical UseAlberto CañaverasNo ratings yet
- Powerful File Management: Put Your Windows To Work!Document7 pagesPowerful File Management: Put Your Windows To Work!tam_buiNo ratings yet
- 5th WeekDocument28 pages5th Weekfaith_khp73301No ratings yet
- DriveFS Test CasesDocument12 pagesDriveFS Test CasesyyNo ratings yet
- Fix 1: Start by Resetting Your Default BrowserDocument4 pagesFix 1: Start by Resetting Your Default BrowserTiago SilvaNo ratings yet
- Batch Publisher GuideDocument2 pagesBatch Publisher Guide安斎 幹No ratings yet
- Merge PDFDocument25 pagesMerge PDFAtanu DattaNo ratings yet
- Creating A PDF File From A Microsoft Word ThesisDocument3 pagesCreating A PDF File From A Microsoft Word ThesisNA NANo ratings yet
- Lecture 3 - Saving and Sharing DocumentsDocument28 pagesLecture 3 - Saving and Sharing Documentskookie bunnyNo ratings yet
- Inside Address Bar or Url.: Hindi Font Installation Process: Step1: EnterDocument3 pagesInside Address Bar or Url.: Hindi Font Installation Process: Step1: EnterVishal NigamNo ratings yet
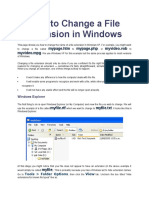
- How To Change A File Extension in WindowsDocument3 pagesHow To Change A File Extension in WindowsZiddi ThakurNo ratings yet
- File and Folders CNIBDocument9 pagesFile and Folders CNIByaminelrustNo ratings yet
- 753 CS 15 Computer Studies I - Lab Manual PDFDocument32 pages753 CS 15 Computer Studies I - Lab Manual PDFmoonde muyatwaNo ratings yet
- CreatDocument5 pagesCreatAbderrahmane SalhaouiNo ratings yet
- Nitro PDF SpecificationDocument8 pagesNitro PDF SpecificationAnonymous eRvc9QENo ratings yet
- How To Batch Convert Your IDWDocument6 pagesHow To Batch Convert Your IDWPierluigiBusettoNo ratings yet
- Homework Week 3 - ITDocument3 pagesHomework Week 3 - ITNguyễn LongNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For Yousakura9999No ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouKeith ChooNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouJhe CastroNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouJhe CastroNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YoubifhihhersNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouRicardo SaizNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouBryan PittmanNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouAlberto FernandezNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouΔημήτρης ΜυλωνόπουλοςNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouMarko StepanovićNo ratings yet
- CP Embedding FontsDocument4 pagesCP Embedding FontsAdi KelongNo ratings yet
- Changing Your Default PDF Program On Your Windows XP DesktopDocument6 pagesChanging Your Default PDF Program On Your Windows XP DesktopongelukNo ratings yet
- AXI Howto Create PDFDocument2 pagesAXI Howto Create PDFQ brgNo ratings yet
- Lesson2 PDFDocument6 pagesLesson2 PDFVvkps SonarNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YoumihirthakkarNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouNulerNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouAmbuj PandeyNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For Youtimos71No ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouVinod MishraNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouMária ZselinszkyNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouAashishh PatilNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For Youim tsoyNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouurwithnitinpalNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouЦ. УчралNo ratings yet
- Create A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouDocument6 pagesCreate A PDF File: Exercise 1 and Exercise 2 Produce The Same Result. Choose The One That Works Best For YouvadriangmailNo ratings yet
- EFI127 Matan Iq Brochure - WEBDocument4 pagesEFI127 Matan Iq Brochure - WEBIulianNo ratings yet
- Project ManagementDocument5 pagesProject ManagementSaadNo ratings yet
- BelFone ProChat Trunking System Dispatcher ManualDocument23 pagesBelFone ProChat Trunking System Dispatcher ManualPT.tikicom sinergiutamaNo ratings yet
- How To Install Brushes in Adobe Photoshop CS3Document15 pagesHow To Install Brushes in Adobe Photoshop CS3Subhanshu MathurNo ratings yet
- Intcom: Computer SystemDocument2 pagesIntcom: Computer SystemGenie Claire GuiuoNo ratings yet
- Wolfenstein 3D PC ManualDocument8 pagesWolfenstein 3D PC ManualMiguelMatuteNo ratings yet
- TN864 - V6.0 Manually Uninstalling Wonderware System Platform (WSP) 2014 and 2014R2Document10 pagesTN864 - V6.0 Manually Uninstalling Wonderware System Platform (WSP) 2014 and 2014R2PeterNo ratings yet
- EVAMANv 875Document50 pagesEVAMANv 875prajapativiren1992No ratings yet
- 45 - JAVA - Text To SpeechDocument6 pages45 - JAVA - Text To Speechnational coursesNo ratings yet
- Lesson 1: Important Changes Made in The Sage 300 2017 TextbookDocument12 pagesLesson 1: Important Changes Made in The Sage 300 2017 TextbookMuhammad Bilal Ahmad100% (1)
- DisplayPort-1 2Document515 pagesDisplayPort-1 2A HNo ratings yet
- FewewrDocument6 pagesFewewrMúamar HáykalNo ratings yet
- How+I+rewrote+my+C+++game+engine+or+framework+in+CDocument6 pagesHow+I+rewrote+my+C+++game+engine+or+framework+in+CMuhammad AliNo ratings yet
- Oxford 20th Century History Textbook PDFDocument428 pagesOxford 20th Century History Textbook PDFqaz xswNo ratings yet
- Projet de WiesharkDocument7 pagesProjet de Wiesharkyellow hNo ratings yet
- Umax Umax Umax Umax Umax: ASTRA 1220 Series Addendum To The Owner's GuideDocument20 pagesUmax Umax Umax Umax Umax: ASTRA 1220 Series Addendum To The Owner's GuideHojas VientoNo ratings yet
- Module 2Document3 pagesModule 2warkisa fileNo ratings yet
- How To Slipstream AMD SATA Drivers With XPDocument13 pagesHow To Slipstream AMD SATA Drivers With XPSattittecInfomáticaNo ratings yet
- Csongor Dobos - PC Config.Document62 pagesCsongor Dobos - PC Config.Csongor DobosNo ratings yet
- DR Drive: (VST, Vst3, Au, Aax)Document12 pagesDR Drive: (VST, Vst3, Au, Aax)Luca CapozziNo ratings yet
- Library Management: ProjectDocument9 pagesLibrary Management: ProjectIraj AhmedNo ratings yet
- Samsung LN46D550K1FXZA Fast Track Guide (SM)Document4 pagesSamsung LN46D550K1FXZA Fast Track Guide (SM)Carlos OdilonNo ratings yet
- Quiz Title SEDocument65 pagesQuiz Title SEquyenNo ratings yet
- Aomei Backupper: User ManualDocument85 pagesAomei Backupper: User ManualnicoNo ratings yet
- COA Assignment Part-2Document7 pagesCOA Assignment Part-2sajan gcNo ratings yet
- LCR - Iq Upgrade From 1.10 To 1.16 2023 FinalDocument3 pagesLCR - Iq Upgrade From 1.10 To 1.16 2023 FinalokdienNo ratings yet
- Getting Started With Silver Notebooks: Installation of Jupyter NotebookDocument10 pagesGetting Started With Silver Notebooks: Installation of Jupyter NotebookyeiaNo ratings yet
- 3D Digital Twin Models For Bridge MaintenanceDocument10 pages3D Digital Twin Models For Bridge MaintenanceMARIANo ratings yet
- EmbeddedSPARKandAda WebDocument220 pagesEmbeddedSPARKandAda WebJosemar PedrosoNo ratings yet