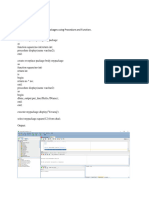
Download as pdf or txt
You might also like
- Dell EMC 2000 Networking 2020Document30 pagesDell EMC 2000 Networking 2020abdulmuizz100% (1)
- CCNA 3 Case Study Spring 2022Document7 pagesCCNA 3 Case Study Spring 2022Mohammed El-SaadiNo ratings yet
- CCNADocument38 pagesCCNAGagan SardanaNo ratings yet
- Advanced IP Services-Assignment QuestionsDocument11 pagesAdvanced IP Services-Assignment QuestionsYuvaraj V, Assistant Professor, BCANo ratings yet
- CCNP SWITCH Implementiong Vlan TrunkDocument43 pagesCCNP SWITCH Implementiong Vlan Trunkchetan666123No ratings yet
- Default GatewayDocument6 pagesDefault GatewayWaqas Ali KhanNo ratings yet
- CCNA Exam Topics - AnswersDocument7 pagesCCNA Exam Topics - AnswerspurkeoreanNo ratings yet
- Implement VLAN and VLAN Trunking Protocols: Switch CLI CodeDocument4 pagesImplement VLAN and VLAN Trunking Protocols: Switch CLI Codeayush sharmaNo ratings yet
- Lecture 7 VLAN VTPDocument17 pagesLecture 7 VLAN VTPSadatur RahmanNo ratings yet
- 20BCS4239 Exp2.2Document7 pages20BCS4239 Exp2.2amanshahwaz023No ratings yet
- En SWITCH v7 Ch01Document26 pagesEn SWITCH v7 Ch01linda guzmanNo ratings yet
- Presentation ON Ccna: TRAINED BY - Kundan Singh (Aptron Solutions PVT LTD)Document36 pagesPresentation ON Ccna: TRAINED BY - Kundan Singh (Aptron Solutions PVT LTD)Akshay Mishra BhardwajNo ratings yet
- Benefits of VLANsand QinQDocument5 pagesBenefits of VLANsand QinQbmaluki1215No ratings yet
- D22CS097 P7 CNDocument8 pagesD22CS097 P7 CNRushabh GoswamiNo ratings yet
- Manual Interface VLAN MikroTikDocument6 pagesManual Interface VLAN MikroTikKarl ClosNo ratings yet
- VLAN TaggingDocument7 pagesVLAN TaggingMohammad SulaimanNo ratings yet
- GECH NT ConfigDocument10 pagesGECH NT ConfigGebrie BeleteNo ratings yet
- University of Gondar College of Informatics Department of Information TechnologyDocument6 pagesUniversity of Gondar College of Informatics Department of Information TechnologyGebrie BeleteNo ratings yet
- Virtual Local Area Network (VLAN)Document5 pagesVirtual Local Area Network (VLAN)ijsretNo ratings yet
- What Is A VLAN?: Technology UpdateDocument2 pagesWhat Is A VLAN?: Technology UpdateMubashir ShahNo ratings yet
- LAN Switching & Wireless NetworksDocument45 pagesLAN Switching & Wireless NetworksAbdullah AmmarNo ratings yet
- Operation Manual - VLAN Quidway S3900 Series Ethernet Switches-Release 1510Document16 pagesOperation Manual - VLAN Quidway S3900 Series Ethernet Switches-Release 1510juliod85No ratings yet
- Layer 3 SwitchingDocument8 pagesLayer 3 SwitchingKaushik DasNo ratings yet
- Lab No.4 CCNDocument6 pagesLab No.4 CCNMaham AkramNo ratings yet
- w7skr3200 PracticalDocument26 pagesw7skr3200 PracticalLaili JamlusNo ratings yet
- Virtual LAN: Applications and TechnologyDocument7 pagesVirtual LAN: Applications and TechnologyJames HeathNo ratings yet
- Ccna3 Final ExamDocument21 pagesCcna3 Final Examshinnok013No ratings yet
- Vlan MohDocument35 pagesVlan MohSantosh SinghNo ratings yet
- Openstack NetworkDocument76 pagesOpenstack NetworksureshkvlNo ratings yet
- SperDocument22 pagesSperAdilson PedroNo ratings yet
- CCNP3 v5.0 BCMSN Mod04 Implementing InterVLAN RoutingDocument76 pagesCCNP3 v5.0 BCMSN Mod04 Implementing InterVLAN RoutingAli ShakerNo ratings yet
- Ch. 9 - VTP: (Trunking, VTP, Inter-VLAN Routing)Document53 pagesCh. 9 - VTP: (Trunking, VTP, Inter-VLAN Routing)rajNo ratings yet
- What Is PPP?Document35 pagesWhat Is PPP?USMANNo ratings yet
- VLAN ManagementDocument10 pagesVLAN Managementmoaz ELZANATYNo ratings yet
- Vlan ConceptsDocument5 pagesVlan ConceptsRahul KumarNo ratings yet
- Virtual Extensible LAN and Ethernet VirtualDocument48 pagesVirtual Extensible LAN and Ethernet VirtualTung TranNo ratings yet
- CSE 4512 Computer Networks-Lab 04Document7 pagesCSE 4512 Computer Networks-Lab 04wurryNo ratings yet
- NEW - Mikrotik - WIKI - Ebook 1 - Basics - Firewall - EthernetDocument114 pagesNEW - Mikrotik - WIKI - Ebook 1 - Basics - Firewall - Ethernethabalforever100% (1)
- Module 3Document2 pagesModule 3Karen JonsonNo ratings yet
- Computer Department Cisco Certified Network AssociateDocument38 pagesComputer Department Cisco Certified Network AssociateMuhamed AtefNo ratings yet
- Lab Exer 8Document8 pagesLab Exer 8Kenth ShiratsuchiNo ratings yet
- Tcp/Ip Model Vlan EthernetDocument18 pagesTcp/Ip Model Vlan EthernetMeena SenthilNo ratings yet
- Module 4Document11 pagesModule 4هبة عمار كاظمNo ratings yet
- Pertemuan 4 VLANDocument21 pagesPertemuan 4 VLANragil suntoroNo ratings yet
- Ccent Study Guide: Vlans and Inter-Vlan RoutingDocument21 pagesCcent Study Guide: Vlans and Inter-Vlan RoutingManuel LoposNo ratings yet
- VLAN Trunking Protocol (VTP)Document12 pagesVLAN Trunking Protocol (VTP)amhosny64No ratings yet
- Module 3Document16 pagesModule 3هبة عمار كاظمNo ratings yet
- Lecture 6Document21 pagesLecture 6Kamran AhmedNo ratings yet
- Layer 2 Switching Vlan Tagging and Compactpci2338Document3 pagesLayer 2 Switching Vlan Tagging and Compactpci2338Patrick AngNo ratings yet
- Exp4 inter-VLAN RoutingDocument9 pagesExp4 inter-VLAN RoutingAbed El Rhman HamedNo ratings yet
- F5-101-Master-Cheat-Sheet YoDocument13 pagesF5-101-Master-Cheat-Sheet YoAmandeep SinghNo ratings yet
- Switching NotesDocument23 pagesSwitching NotesPA2 ksplNo ratings yet
- Mikrotik - VPNDocument92 pagesMikrotik - VPNMusyaffak SNo ratings yet
- VlanDocument46 pagesVlanchitrang_11No ratings yet
- Xiyang 2009Document4 pagesXiyang 2009Rizky Muhammad FauziNo ratings yet
- V-LAN Tagging With DTP ProtocolDocument9 pagesV-LAN Tagging With DTP ProtocolDipayan MaityNo ratings yet
- VLAN DocumentDocument28 pagesVLAN DocumentAjay MathewNo ratings yet
- CCNA Certification All-in-One For DummiesFrom EverandCCNA Certification All-in-One For DummiesRating: 5 out of 5 stars5/5 (1)
- CCST Cisco Certified Support Technician Study Guide: Networking ExamFrom EverandCCST Cisco Certified Support Technician Study Guide: Networking ExamNo ratings yet
- 7.6.3 Exploring IPv6 Addressing On RoutersDocument3 pages7.6.3 Exploring IPv6 Addressing On RoutersYuvaraj V, Assistant Professor, BCANo ratings yet
- 18mit13c U2Document13 pages18mit13c U2Yuvaraj V, Assistant Professor, BCANo ratings yet
- 7.2.3 Routing Troubleshooting ToolsDocument7 pages7.2.3 Routing Troubleshooting ToolsYuvaraj V, Assistant Professor, BCANo ratings yet
- Elective-I-Fundamental of Networks-AssignmentDocument42 pagesElective-I-Fundamental of Networks-AssignmentYuvaraj V, Assistant Professor, BCANo ratings yet
- IPV-4 ROUTING-Assignment Questions With SolutionsDocument15 pagesIPV-4 ROUTING-Assignment Questions With SolutionsYuvaraj V, Assistant Professor, BCANo ratings yet
- Basic IP Servies - AssignmentDocument20 pagesBasic IP Servies - AssignmentYuvaraj V, Assistant Professor, BCANo ratings yet
- B.SC - IT-UG-CBCS-2019-STRUCTURE & SCHEME-19.3.21 (WITHOUT COP) - Merged-MergedDocument54 pagesB.SC - IT-UG-CBCS-2019-STRUCTURE & SCHEME-19.3.21 (WITHOUT COP) - Merged-MergedYuvaraj V, Assistant Professor, BCANo ratings yet
- Os Unit IiDocument69 pagesOs Unit IiYuvaraj V, Assistant Professor, BCANo ratings yet
- 7.2.1 IPv4 Routing OverviewDocument5 pages7.2.1 IPv4 Routing OverviewYuvaraj V, Assistant Professor, BCANo ratings yet
- Dse-Iv E (Theory-Programming) : BATCH: 2019Document11 pagesDse-Iv E (Theory-Programming) : BATCH: 2019Yuvaraj V, Assistant Professor, BCANo ratings yet
- Lecture 17Document136 pagesLecture 17Yuvaraj V, Assistant Professor, BCANo ratings yet
- Open Ele-Cyber Security-II-NAAC HoursDocument7 pagesOpen Ele-Cyber Security-II-NAAC HoursYuvaraj V, Assistant Professor, BCANo ratings yet
- Programme:: B.Sc. CS/IT/CADocument12 pagesProgramme:: B.Sc. CS/IT/CAYuvaraj V, Assistant Professor, BCANo ratings yet
- LECT3Document87 pagesLECT3Yuvaraj V, Assistant Professor, BCANo ratings yet
- C - Unit-IiiDocument25 pagesC - Unit-IiiYuvaraj V, Assistant Professor, BCANo ratings yet
- Cyber Security-Unit-IDocument64 pagesCyber Security-Unit-IYuvaraj V, Assistant Professor, BCANo ratings yet
- Operators in SQLDocument6 pagesOperators in SQLYuvaraj V, Assistant Professor, BCANo ratings yet
- Cyber Security-Unit-IIDocument29 pagesCyber Security-Unit-IIYuvaraj V, Assistant Professor, BCANo ratings yet
- Os Unit IvDocument62 pagesOs Unit IvYuvaraj V, Assistant Professor, BCANo ratings yet
- Unit III SEDocument99 pagesUnit III SEYuvaraj V, Assistant Professor, BCANo ratings yet
- I-Mha - Unit-IiiDocument23 pagesI-Mha - Unit-IiiYuvaraj V, Assistant Professor, BCANo ratings yet
- Hive Lecture NotesDocument17 pagesHive Lecture NotesYuvaraj V, Assistant Professor, BCA100% (1)
- I-Mha - Unit-VDocument6 pagesI-Mha - Unit-VYuvaraj V, Assistant Professor, BCANo ratings yet
- DBMS Functions ProgramDocument8 pagesDBMS Functions ProgramYuvaraj V, Assistant Professor, BCANo ratings yet
- Package ProgramDocument1 pagePackage ProgramYuvaraj V, Assistant Professor, BCANo ratings yet
- Unit I NormalizationDocument51 pagesUnit I NormalizationYuvaraj V, Assistant Professor, BCANo ratings yet
- EDU 705 Handout UploadDocument102 pagesEDU 705 Handout Uploadasabahat774No ratings yet
- Magsaysay v. AganDocument2 pagesMagsaysay v. Agand2015memberNo ratings yet
- Birla Organization StructureDocument19 pagesBirla Organization StructureSouravsapPPNo ratings yet
- Career Readiness ReflectionDocument2 pagesCareer Readiness Reflectionapi-597414151No ratings yet
- Chapter 4 - Behaviour and AttitudesDocument24 pagesChapter 4 - Behaviour and AttitudesmNo ratings yet
- Bremer Bank - Chief Marketing Officer - Erin DadyDocument1 pageBremer Bank - Chief Marketing Officer - Erin DadyLars LeafbladNo ratings yet
- Poll Crosstabs - EconomyDocument73 pagesPoll Crosstabs - EconomyLas Vegas Review-JournalNo ratings yet
- Informant Policies & Practices Evaluation Committee ReportDocument47 pagesInformant Policies & Practices Evaluation Committee ReportLisa Bartley100% (1)
- Chapter1 FinalDocument21 pagesChapter1 FinalGelo MoralNo ratings yet
- United States Court of Appeals: in TheDocument59 pagesUnited States Court of Appeals: in TheTimothy BurkeNo ratings yet
- FloraPark 1 IntroductionDocument33 pagesFloraPark 1 IntroductionTin TranNo ratings yet
- November 26 Shabbat AnnouncementsDocument4 pagesNovember 26 Shabbat AnnouncementsgnswebNo ratings yet
- Rabor Vs CSCDocument36 pagesRabor Vs CSCNiel S. DefensorNo ratings yet
- Sarahdibou FinaldraftturninDocument5 pagesSarahdibou Finaldraftturninapi-359327548No ratings yet
- Nfpa 13D Fire Sprinkler Systems (Installation of Sprinkler Systems in One-And Two-Family Dwellings and Manufactured Homes)Document5 pagesNfpa 13D Fire Sprinkler Systems (Installation of Sprinkler Systems in One-And Two-Family Dwellings and Manufactured Homes)kklikojiNo ratings yet
- NL2122404156290 HolidayBookingCardDocument15 pagesNL2122404156290 HolidayBookingCard1cf20at115No ratings yet
- Coursework Is More Important Than Examination DebateDocument5 pagesCoursework Is More Important Than Examination Debatezug0badej0n2100% (1)
- Knowledge As Salvation - A Study in Early BuddhismDocument299 pagesKnowledge As Salvation - A Study in Early BuddhismGuhyaprajñāmitra3No ratings yet
- Crim III DigestsDocument18 pagesCrim III DigestsErika PotianNo ratings yet
- FAQ (For BEM's Website) (May 2023)Document21 pagesFAQ (For BEM's Website) (May 2023)hnzmalaysiaNo ratings yet
- Interest or Pressure GroupsDocument3 pagesInterest or Pressure GroupsCryslerNo ratings yet
- IT Governance Essentials PDFDocument1 pageIT Governance Essentials PDFfpokoo_aikinsNo ratings yet
- Kunci TitmanDocument98 pagesKunci TitmanFadhil AlamsyahNo ratings yet
- MOTILALDocument17 pagesMOTILALvinodhji5No ratings yet
- Dorothy Cheung Debating Championship InvitationDocument4 pagesDorothy Cheung Debating Championship Invitationapi-26055767No ratings yet
- Assignment of Uloom Ul Quran For Ph-1Document11 pagesAssignment of Uloom Ul Quran For Ph-1Ibtisam Elahi Zaheer0% (3)
- Eurekahedge Asian Hedge Fund Awards 2010: WinnersDocument9 pagesEurekahedge Asian Hedge Fund Awards 2010: WinnersEurekahedgeNo ratings yet
- FPBDocument2 pagesFPBJavier GalianoNo ratings yet
- Foi Mtcu-100025 Bargaining Expenses Thu Aug 26 2010 08-26-27.142-1Document5 pagesFoi Mtcu-100025 Bargaining Expenses Thu Aug 26 2010 08-26-27.142-1Rob HorganNo ratings yet