
Search Engine - HW-module2 - CPEG657
Search Engine - HW-module2 - CPEG657
You might also like
- CableOS 1.15 CLI Reference VersionCDocument781 pagesCableOS 1.15 CLI Reference VersionCAntonio ReneNo ratings yet
- Processor Design From Leon3 Extension Final ReportDocument44 pagesProcessor Design From Leon3 Extension Final ReportTalal KhaliqNo ratings yet
- 10 Minutes To Pandas - Pandas 0.21Document23 pages10 Minutes To Pandas - Pandas 0.21Aditya SinghNo ratings yet
- 10 Minutes To PandasDocument26 pages10 Minutes To Pandastofy79No ratings yet
- Eco No Metrics Assignment 3Document6 pagesEco No Metrics Assignment 3Arpit_Lal_1267No ratings yet
- PS4 Ef 8904 W2016 Ans 4Document7 pagesPS4 Ef 8904 W2016 Ans 4Jeremey Julian PonrajahNo ratings yet
- PandasDocument16 pagesPandaslalkrishna123No ratings yet
- Homework4 1Document10 pagesHomework4 1Yash SirowaNo ratings yet
- Tutorial Pandas Bag-5Document11 pagesTutorial Pandas Bag-5NUR JAYANo ratings yet
- Assignment 1 ContinuedDocument13 pagesAssignment 1 ContinuedPavanKumar DaniNo ratings yet
- Tasks A TreesDocument14 pagesTasks A TreesAmos Keli MutuaNo ratings yet
- Job Information: 30-Nov-15 30-Nov-2015 22:46 KD - STDDocument220 pagesJob Information: 30-Nov-15 30-Nov-2015 22:46 KD - STDGaurav PawarNo ratings yet
- Column Calculation Sheet: 1. Input DataDocument5 pagesColumn Calculation Sheet: 1. Input DataJae Huan YooNo ratings yet
- DCS AssignmentDocument20 pagesDCS AssignmentmerikhanzadaNo ratings yet
- hw1 ML IvanReyesDocument21 pageshw1 ML IvanReyesIván ReyesNo ratings yet
- Sample Exam SolutionsDocument7 pagesSample Exam SolutionsrichardNo ratings yet
- AFM Formulae SheetDocument5 pagesAFM Formulae SheetRudolf WitzigNo ratings yet
- Homework1: Introduction To Computer Organisation and ArchitectureDocument9 pagesHomework1: Introduction To Computer Organisation and Architecturesachinraj2No ratings yet
- Formulae Amendment (5G Latency - RLC)Document6 pagesFormulae Amendment (5G Latency - RLC)shoaib.hadi7355No ratings yet
- Design and Safety FactorsDocument7 pagesDesign and Safety FactorsCristian AndreiNo ratings yet
- Chapter 3: Process Strategy: ProblemsDocument2 pagesChapter 3: Process Strategy: ProblemshugoNo ratings yet
- C1M6 Peer Reviewed SolvedDocument11 pagesC1M6 Peer Reviewed SolvedAshutosh KumarNo ratings yet
- The Role of Distributed Arithmetic in FPGA-based Signal ProcessingDocument15 pagesThe Role of Distributed Arithmetic in FPGA-based Signal Processingsanjay_drdo237No ratings yet
- VIKASYDocument9 pagesVIKASY10SHARMA SUMIT RAMADHINNo ratings yet
- 0483 - Trần Công Sơn - Bài Tập Số 2Document12 pages0483 - Trần Công Sơn - Bài Tập Số 20483Trần Công SơnNo ratings yet
- LAB 5 DSP - pdf2Document11 pagesLAB 5 DSP - pdf2zubair tahirNo ratings yet
- Assignment 2 CONTROL SYSTEMS Name: Prateeth Rao SRN: PES2UG19EC103Document24 pagesAssignment 2 CONTROL SYSTEMS Name: Prateeth Rao SRN: PES2UG19EC103PavanKumar DaniNo ratings yet
- Exercise 4: Simple and Multiple Linear Regression AnalysisDocument15 pagesExercise 4: Simple and Multiple Linear Regression AnalysisBikas C. BhattaraiNo ratings yet
- Assignment 02: PES2UG19EC097Document25 pagesAssignment 02: PES2UG19EC097PavanKumar DaniNo ratings yet
- Machine_Learning_Stock_Time_Series__1700932258Document21 pagesMachine_Learning_Stock_Time_Series__1700932258Luis Martin Valenzuela LeyvaNo ratings yet
- Assignment 4: Chitresh KumarDocument7 pagesAssignment 4: Chitresh KumarChitreshKumarNo ratings yet
- 09 Chapter 5Document42 pages09 Chapter 5b.lavanyaNo ratings yet
- Lecture 04Document20 pagesLecture 04Tev WallaceNo ratings yet
- NASTRAN Nonlinear ElementsDocument90 pagesNASTRAN Nonlinear Elementssons01No ratings yet
- EACT533 LCS Lab Work Report Garoma LAB Report-1Document43 pagesEACT533 LCS Lab Work Report Garoma LAB Report-1meseret sisayNo ratings yet
- Assignment 1 Group 11Document13 pagesAssignment 1 Group 11Qianyu GuNo ratings yet
- Lab 5 DSPDocument11 pagesLab 5 DSPzubair tahirNo ratings yet
- Matlab Is A Programming Language Developed by Mathworks. It Started Out As A Matrix Programming Language Where Linear Algebra Programming Was SimpleDocument29 pagesMatlab Is A Programming Language Developed by Mathworks. It Started Out As A Matrix Programming Language Where Linear Algebra Programming Was SimpleLakshmi malladiNo ratings yet
- PE-DC-445-651-C001 R0 Reviewed 20210621Document19 pagesPE-DC-445-651-C001 R0 Reviewed 20210621Prabir PalNo ratings yet
- Document 2Document10 pagesDocument 2Dhanush KumarNo ratings yet
- Activity Event DurationDocument17 pagesActivity Event DurationBasharat SaigalNo ratings yet
- GLM SolDocument11 pagesGLM SolAkshita JainNo ratings yet
- AlphaDecayPanelData LZJ 20210730Document3 pagesAlphaDecayPanelData LZJ 20210730Zuojie LiuNo ratings yet
- M Lab Report 5Document9 pagesM Lab Report 5marryam nawazNo ratings yet
- FEA Code in Matlab For A Truss StructureADocument33 pagesFEA Code in Matlab For A Truss StructureAiScribdRNo ratings yet
- Ee 4314 ComphnvhvnDocument26 pagesEe 4314 ComphnvhvnSALIMSEIF1No ratings yet
- Wall Bearing SystemDocument45 pagesWall Bearing SystemRabi DhakalNo ratings yet
- 2Document60 pages2Al-Amin RazakNo ratings yet
- Home Work Excel SolutionDocument16 pagesHome Work Excel SolutionSunil KumarNo ratings yet
- Lab Manual # 12 (LCS) (2018-CPE-07)Document7 pagesLab Manual # 12 (LCS) (2018-CPE-07)Momel FatimaNo ratings yet
- Ferret 1Document5 pagesFerret 1Apriansyah 'gianluigi Ujang' HakimNo ratings yet
- Financial Test ReportDocument11 pagesFinancial Test ReportAsad GhaffarNo ratings yet
- Multlin 4Document6 pagesMultlin 4Anik RuhulNo ratings yet
- About Scan D Flip FlopsDocument11 pagesAbout Scan D Flip FlopsAishwarya TapadiyaNo ratings yet
- Divergencia PDFDocument8 pagesDivergencia PDFDuane AliagaNo ratings yet
- Ayushi Patel A044 R SoftwareDocument8 pagesAyushi Patel A044 R SoftwareAyushi PatelNo ratings yet
- Valid RealDocument13 pagesValid RealRino CitraNo ratings yet
- Package 2doptimize - : - For UsingDocument8 pagesPackage 2doptimize - : - For UsingAnonymous 0pBRsQXfnxNo ratings yet
- hw3s 04Document9 pageshw3s 04Hasan TahsinNo ratings yet
- Matlab-STATISTICAL MODELS AND METHODS FOR FINANCIAL MARKETSDocument13 pagesMatlab-STATISTICAL MODELS AND METHODS FOR FINANCIAL MARKETSGonzalo SaavedraNo ratings yet
- Projects With Microcontrollers And PICCFrom EverandProjects With Microcontrollers And PICCRating: 5 out of 5 stars5/5 (1)
- The Definitive Guide to Azure Data Engineering: Modern ELT, DevOps, and Analytics on the Azure Cloud PlatformFrom EverandThe Definitive Guide to Azure Data Engineering: Modern ELT, DevOps, and Analytics on the Azure Cloud PlatformNo ratings yet
- ALE IDOC Development Between Two SAP Systems - ALE-IDOCS Development - SAPNutsDocument25 pagesALE IDOC Development Between Two SAP Systems - ALE-IDOCS Development - SAPNutsSidharth KumarNo ratings yet
- Uses Permissions - RAD StudioDocument1 pageUses Permissions - RAD StudioLuis Gustavo Felix GarciaNo ratings yet
- SQLServer Denali SpatialDocument28 pagesSQLServer Denali Spatialamos_evaNo ratings yet
- GST SounderDocument1 pageGST SounderMohammed HaroonNo ratings yet
- APPENDIX A (Source Codes)Document49 pagesAPPENDIX A (Source Codes)kriz anthony zuniegaNo ratings yet
- New LL AcknowledgementDocument1 pageNew LL AcknowledgementNISHKARSH. MAURYANo ratings yet
- UTunit 3 Co MTDocument5 pagesUTunit 3 Co MTchinthaka18389021No ratings yet
- Oracle Ebusiness Suite 11i PDF SysadminDocument696 pagesOracle Ebusiness Suite 11i PDF SysadminShola KayNo ratings yet
- Red Hat Enterprise Linux-7-Virtualization Deployment and Administration Guide-en-US PDFDocument579 pagesRed Hat Enterprise Linux-7-Virtualization Deployment and Administration Guide-en-US PDFouououououNo ratings yet
- DS MP58 - 58T eDocument2 pagesDS MP58 - 58T eNirav PatelNo ratings yet
- Maths M T.3 Game TheoryDocument2 pagesMaths M T.3 Game TheoryKelvin FookNo ratings yet
- Macworld - April 2024 USADocument120 pagesMacworld - April 2024 USAsoufortniteNo ratings yet
- Run-Time Variables Monitoring and Visualization Tool For STM32 DevicesDocument5 pagesRun-Time Variables Monitoring and Visualization Tool For STM32 DevicesLeandro CapitanelliNo ratings yet
- Assignment On DataDocument8 pagesAssignment On DataAtikur Rahman100% (1)
- Email Marketing - ChecklistDocument4 pagesEmail Marketing - ChecklistRahul SharmaNo ratings yet
- How To Set Up ModSecurity With Apache On Debian/UbuntuDocument13 pagesHow To Set Up ModSecurity With Apache On Debian/Ubuntuvpalmar8871No ratings yet
- Digital Light Wave ASA 312Document11 pagesDigital Light Wave ASA 312oanh1985No ratings yet
- Geoda, From The Desktop To An Ecosystem For Exploring Spatial DataDocument38 pagesGeoda, From The Desktop To An Ecosystem For Exploring Spatial DataJohn SmithNo ratings yet
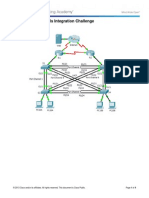
- 3.3.1.2 Packet Tracer - Skills Integration Challenge InstructionsDocument9 pages3.3.1.2 Packet Tracer - Skills Integration Challenge InstructionsIhsan Mastaan100% (2)
- In-Tray / E-Tray Exercises: WWW - Exeter.ac - Uk/careersDocument3 pagesIn-Tray / E-Tray Exercises: WWW - Exeter.ac - Uk/careersAndra Ana-MariaNo ratings yet
- Windows 8 Product Key 100% Working Serial Keys - Latest Free Software DownloadDocument8 pagesWindows 8 Product Key 100% Working Serial Keys - Latest Free Software DownloadMahesh DeodharNo ratings yet
- 3d Inter Net BookDocument23 pages3d Inter Net BookKishore SmartNo ratings yet
- Final ReportDocument33 pagesFinal ReportLalit PrakashNo ratings yet
- Sarah Hollister ResumeDocument1 pageSarah Hollister Resumeapi-351760386No ratings yet
- EWANDocument21 pagesEWANHermann Dejero LozanoNo ratings yet
- Methods For Deadlock HandlingDocument16 pagesMethods For Deadlock HandlingdeadpoolachiNo ratings yet
- Combined Quiz Solutions PDFDocument61 pagesCombined Quiz Solutions PDFanchalNo ratings yet
- AX99100 BriefDocument2 pagesAX99100 BriefQian Zwei ShengNo ratings yet


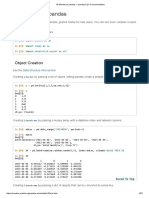







































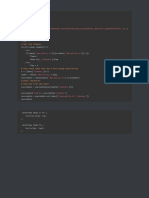














































Download as pdf or txt
You might also like
- CableOS 1.15 CLI Reference VersionCDocument781 pagesCableOS 1.15 CLI Reference VersionCAntonio ReneNo ratings yet
- Processor Design From Leon3 Extension Final ReportDocument44 pagesProcessor Design From Leon3 Extension Final ReportTalal KhaliqNo ratings yet
- 10 Minutes To Pandas - Pandas 0.21Document23 pages10 Minutes To Pandas - Pandas 0.21Aditya SinghNo ratings yet
- 10 Minutes To PandasDocument26 pages10 Minutes To Pandastofy79No ratings yet
- Eco No Metrics Assignment 3Document6 pagesEco No Metrics Assignment 3Arpit_Lal_1267No ratings yet
- PS4 Ef 8904 W2016 Ans 4Document7 pagesPS4 Ef 8904 W2016 Ans 4Jeremey Julian PonrajahNo ratings yet
- PandasDocument16 pagesPandaslalkrishna123No ratings yet
- Homework4 1Document10 pagesHomework4 1Yash SirowaNo ratings yet
- Tutorial Pandas Bag-5Document11 pagesTutorial Pandas Bag-5NUR JAYANo ratings yet
- Assignment 1 ContinuedDocument13 pagesAssignment 1 ContinuedPavanKumar DaniNo ratings yet
- Tasks A TreesDocument14 pagesTasks A TreesAmos Keli MutuaNo ratings yet
- Job Information: 30-Nov-15 30-Nov-2015 22:46 KD - STDDocument220 pagesJob Information: 30-Nov-15 30-Nov-2015 22:46 KD - STDGaurav PawarNo ratings yet
- Column Calculation Sheet: 1. Input DataDocument5 pagesColumn Calculation Sheet: 1. Input DataJae Huan YooNo ratings yet
- DCS AssignmentDocument20 pagesDCS AssignmentmerikhanzadaNo ratings yet
- hw1 ML IvanReyesDocument21 pageshw1 ML IvanReyesIván ReyesNo ratings yet
- Sample Exam SolutionsDocument7 pagesSample Exam SolutionsrichardNo ratings yet
- AFM Formulae SheetDocument5 pagesAFM Formulae SheetRudolf WitzigNo ratings yet
- Homework1: Introduction To Computer Organisation and ArchitectureDocument9 pagesHomework1: Introduction To Computer Organisation and Architecturesachinraj2No ratings yet
- Formulae Amendment (5G Latency - RLC)Document6 pagesFormulae Amendment (5G Latency - RLC)shoaib.hadi7355No ratings yet
- Design and Safety FactorsDocument7 pagesDesign and Safety FactorsCristian AndreiNo ratings yet
- Chapter 3: Process Strategy: ProblemsDocument2 pagesChapter 3: Process Strategy: ProblemshugoNo ratings yet
- C1M6 Peer Reviewed SolvedDocument11 pagesC1M6 Peer Reviewed SolvedAshutosh KumarNo ratings yet
- The Role of Distributed Arithmetic in FPGA-based Signal ProcessingDocument15 pagesThe Role of Distributed Arithmetic in FPGA-based Signal Processingsanjay_drdo237No ratings yet
- VIKASYDocument9 pagesVIKASY10SHARMA SUMIT RAMADHINNo ratings yet
- 0483 - Trần Công Sơn - Bài Tập Số 2Document12 pages0483 - Trần Công Sơn - Bài Tập Số 20483Trần Công SơnNo ratings yet
- LAB 5 DSP - pdf2Document11 pagesLAB 5 DSP - pdf2zubair tahirNo ratings yet
- Assignment 2 CONTROL SYSTEMS Name: Prateeth Rao SRN: PES2UG19EC103Document24 pagesAssignment 2 CONTROL SYSTEMS Name: Prateeth Rao SRN: PES2UG19EC103PavanKumar DaniNo ratings yet
- Exercise 4: Simple and Multiple Linear Regression AnalysisDocument15 pagesExercise 4: Simple and Multiple Linear Regression AnalysisBikas C. BhattaraiNo ratings yet
- Assignment 02: PES2UG19EC097Document25 pagesAssignment 02: PES2UG19EC097PavanKumar DaniNo ratings yet
- Machine_Learning_Stock_Time_Series__1700932258Document21 pagesMachine_Learning_Stock_Time_Series__1700932258Luis Martin Valenzuela LeyvaNo ratings yet
- Assignment 4: Chitresh KumarDocument7 pagesAssignment 4: Chitresh KumarChitreshKumarNo ratings yet
- 09 Chapter 5Document42 pages09 Chapter 5b.lavanyaNo ratings yet
- Lecture 04Document20 pagesLecture 04Tev WallaceNo ratings yet
- NASTRAN Nonlinear ElementsDocument90 pagesNASTRAN Nonlinear Elementssons01No ratings yet
- EACT533 LCS Lab Work Report Garoma LAB Report-1Document43 pagesEACT533 LCS Lab Work Report Garoma LAB Report-1meseret sisayNo ratings yet
- Assignment 1 Group 11Document13 pagesAssignment 1 Group 11Qianyu GuNo ratings yet
- Lab 5 DSPDocument11 pagesLab 5 DSPzubair tahirNo ratings yet
- Matlab Is A Programming Language Developed by Mathworks. It Started Out As A Matrix Programming Language Where Linear Algebra Programming Was SimpleDocument29 pagesMatlab Is A Programming Language Developed by Mathworks. It Started Out As A Matrix Programming Language Where Linear Algebra Programming Was SimpleLakshmi malladiNo ratings yet
- PE-DC-445-651-C001 R0 Reviewed 20210621Document19 pagesPE-DC-445-651-C001 R0 Reviewed 20210621Prabir PalNo ratings yet
- Document 2Document10 pagesDocument 2Dhanush KumarNo ratings yet
- Activity Event DurationDocument17 pagesActivity Event DurationBasharat SaigalNo ratings yet
- GLM SolDocument11 pagesGLM SolAkshita JainNo ratings yet
- AlphaDecayPanelData LZJ 20210730Document3 pagesAlphaDecayPanelData LZJ 20210730Zuojie LiuNo ratings yet
- M Lab Report 5Document9 pagesM Lab Report 5marryam nawazNo ratings yet
- FEA Code in Matlab For A Truss StructureADocument33 pagesFEA Code in Matlab For A Truss StructureAiScribdRNo ratings yet
- Ee 4314 ComphnvhvnDocument26 pagesEe 4314 ComphnvhvnSALIMSEIF1No ratings yet
- Wall Bearing SystemDocument45 pagesWall Bearing SystemRabi DhakalNo ratings yet
- 2Document60 pages2Al-Amin RazakNo ratings yet
- Home Work Excel SolutionDocument16 pagesHome Work Excel SolutionSunil KumarNo ratings yet
- Lab Manual # 12 (LCS) (2018-CPE-07)Document7 pagesLab Manual # 12 (LCS) (2018-CPE-07)Momel FatimaNo ratings yet
- Ferret 1Document5 pagesFerret 1Apriansyah 'gianluigi Ujang' HakimNo ratings yet
- Financial Test ReportDocument11 pagesFinancial Test ReportAsad GhaffarNo ratings yet
- Multlin 4Document6 pagesMultlin 4Anik RuhulNo ratings yet
- About Scan D Flip FlopsDocument11 pagesAbout Scan D Flip FlopsAishwarya TapadiyaNo ratings yet
- Divergencia PDFDocument8 pagesDivergencia PDFDuane AliagaNo ratings yet
- Ayushi Patel A044 R SoftwareDocument8 pagesAyushi Patel A044 R SoftwareAyushi PatelNo ratings yet
- Valid RealDocument13 pagesValid RealRino CitraNo ratings yet
- Package 2doptimize - : - For UsingDocument8 pagesPackage 2doptimize - : - For UsingAnonymous 0pBRsQXfnxNo ratings yet
- hw3s 04Document9 pageshw3s 04Hasan TahsinNo ratings yet
- Matlab-STATISTICAL MODELS AND METHODS FOR FINANCIAL MARKETSDocument13 pagesMatlab-STATISTICAL MODELS AND METHODS FOR FINANCIAL MARKETSGonzalo SaavedraNo ratings yet
- Projects With Microcontrollers And PICCFrom EverandProjects With Microcontrollers And PICCRating: 5 out of 5 stars5/5 (1)
- The Definitive Guide to Azure Data Engineering: Modern ELT, DevOps, and Analytics on the Azure Cloud PlatformFrom EverandThe Definitive Guide to Azure Data Engineering: Modern ELT, DevOps, and Analytics on the Azure Cloud PlatformNo ratings yet
- ALE IDOC Development Between Two SAP Systems - ALE-IDOCS Development - SAPNutsDocument25 pagesALE IDOC Development Between Two SAP Systems - ALE-IDOCS Development - SAPNutsSidharth KumarNo ratings yet
- Uses Permissions - RAD StudioDocument1 pageUses Permissions - RAD StudioLuis Gustavo Felix GarciaNo ratings yet
- SQLServer Denali SpatialDocument28 pagesSQLServer Denali Spatialamos_evaNo ratings yet
- GST SounderDocument1 pageGST SounderMohammed HaroonNo ratings yet
- APPENDIX A (Source Codes)Document49 pagesAPPENDIX A (Source Codes)kriz anthony zuniegaNo ratings yet
- New LL AcknowledgementDocument1 pageNew LL AcknowledgementNISHKARSH. MAURYANo ratings yet
- UTunit 3 Co MTDocument5 pagesUTunit 3 Co MTchinthaka18389021No ratings yet
- Oracle Ebusiness Suite 11i PDF SysadminDocument696 pagesOracle Ebusiness Suite 11i PDF SysadminShola KayNo ratings yet
- Red Hat Enterprise Linux-7-Virtualization Deployment and Administration Guide-en-US PDFDocument579 pagesRed Hat Enterprise Linux-7-Virtualization Deployment and Administration Guide-en-US PDFouououououNo ratings yet
- DS MP58 - 58T eDocument2 pagesDS MP58 - 58T eNirav PatelNo ratings yet
- Maths M T.3 Game TheoryDocument2 pagesMaths M T.3 Game TheoryKelvin FookNo ratings yet
- Macworld - April 2024 USADocument120 pagesMacworld - April 2024 USAsoufortniteNo ratings yet
- Run-Time Variables Monitoring and Visualization Tool For STM32 DevicesDocument5 pagesRun-Time Variables Monitoring and Visualization Tool For STM32 DevicesLeandro CapitanelliNo ratings yet
- Assignment On DataDocument8 pagesAssignment On DataAtikur Rahman100% (1)
- Email Marketing - ChecklistDocument4 pagesEmail Marketing - ChecklistRahul SharmaNo ratings yet
- How To Set Up ModSecurity With Apache On Debian/UbuntuDocument13 pagesHow To Set Up ModSecurity With Apache On Debian/Ubuntuvpalmar8871No ratings yet
- Digital Light Wave ASA 312Document11 pagesDigital Light Wave ASA 312oanh1985No ratings yet
- Geoda, From The Desktop To An Ecosystem For Exploring Spatial DataDocument38 pagesGeoda, From The Desktop To An Ecosystem For Exploring Spatial DataJohn SmithNo ratings yet
- 3.3.1.2 Packet Tracer - Skills Integration Challenge InstructionsDocument9 pages3.3.1.2 Packet Tracer - Skills Integration Challenge InstructionsIhsan Mastaan100% (2)
- In-Tray / E-Tray Exercises: WWW - Exeter.ac - Uk/careersDocument3 pagesIn-Tray / E-Tray Exercises: WWW - Exeter.ac - Uk/careersAndra Ana-MariaNo ratings yet
- Windows 8 Product Key 100% Working Serial Keys - Latest Free Software DownloadDocument8 pagesWindows 8 Product Key 100% Working Serial Keys - Latest Free Software DownloadMahesh DeodharNo ratings yet
- 3d Inter Net BookDocument23 pages3d Inter Net BookKishore SmartNo ratings yet
- Final ReportDocument33 pagesFinal ReportLalit PrakashNo ratings yet
- Sarah Hollister ResumeDocument1 pageSarah Hollister Resumeapi-351760386No ratings yet
- EWANDocument21 pagesEWANHermann Dejero LozanoNo ratings yet
- Methods For Deadlock HandlingDocument16 pagesMethods For Deadlock HandlingdeadpoolachiNo ratings yet
- Combined Quiz Solutions PDFDocument61 pagesCombined Quiz Solutions PDFanchalNo ratings yet
- AX99100 BriefDocument2 pagesAX99100 BriefQian Zwei ShengNo ratings yet