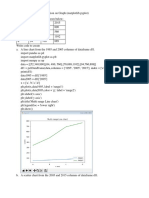
Download as docx, pdf, or txt
You might also like
- Parar RoletaDocument2 pagesParar RoletaMárcia AntonioNo ratings yet
- (Tweaks) (Guide) Build - Prop Tweaks - Android Development and HackingDocument125 pages(Tweaks) (Guide) Build - Prop Tweaks - Android Development and HackingaliftwsNo ratings yet
- MatplotlibDocument15 pagesMatplotlibpatelhemv1143No ratings yet
- Assignement 2 Source CodeDocument2 pagesAssignement 2 Source CodeAvik GhoshNo ratings yet
- Python Crash Course by Ehmatthes 16Document1 pagePython Crash Course by Ehmatthes 16alfonsofdezNo ratings yet
- Formulario - EADocument6 pagesFormulario - EAMARLENE FRANCISCA MARIA FUENTES ROANo ratings yet
- презентаціяDocument7 pagesпрезентаціяfoxmegasmartNo ratings yet
- Number of Orders Eda PartDocument5 pagesNumber of Orders Eda PartPreeti SahuNo ratings yet
- Unit 6 Data Visualization-1Document30 pagesUnit 6 Data Visualization-1jayesh.chordiyaNo ratings yet
- DS100-1 WS 2.6 Enrico, DMDocument8 pagesDS100-1 WS 2.6 Enrico, DMAnalyn EnricoNo ratings yet
- Ngconf 2018 - RoutingDocument50 pagesNgconf 2018 - RoutingκβηξκλκξηNo ratings yet
- Pandas TitanicDocument1 pagePandas TitanicCondéNo ratings yet
- 《Operating Systems》-Experimental instruction-Experiment 7 OPT algorithmDocument6 pages《Operating Systems》-Experimental instruction-Experiment 7 OPT algorithmBRANDY GANYIRENo ratings yet
- Lab Manual MCSE 101Document35 pagesLab Manual MCSE 101Juan JacksonNo ratings yet
- Assignment 1Document5 pagesAssignment 1vasanthvv301506No ratings yet
- Os Lab Manual1Document49 pagesOs Lab Manual1akshatha s.aNo ratings yet
- Main SummaryDocument19 pagesMain Summaryzhangzhongshi91No ratings yet
- CharttttttDocument2 pagesCharttttttbithorthaagamNo ratings yet
- Eco Outlook AxisDocument26 pagesEco Outlook AxisinbanwNo ratings yet
- An Introduction To SeabornDocument42 pagesAn Introduction To SeabornMohammad BangeeNo ratings yet
- Borrao 18 03 MatplotlibDocument14 pagesBorrao 18 03 MatplotlibTennyson Accetti Resende FilhoNo ratings yet
- Ormulate The Data Science ProblemDocument5 pagesOrmulate The Data Science Problemnicebi09No ratings yet
- HinoroneDocument24 pagesHinoroneRudson LimaNo ratings yet
- Airfare ML - Predicting Flight FaresDocument21 pagesAirfare ML - Predicting Flight FaresDavid NovaNo ratings yet
- Ts NotebookDocument22 pagesTs NotebookDanilo Santiago Criollo Chávez100% (1)
- Comff 1Document10 pagesComff 1Ansh bNo ratings yet
- OSDocument15 pagesOSPranay RawatNo ratings yet
- ShivaprojectpythonDocument14 pagesShivaprojectpythonShivashanmukha SivashanmukhaNo ratings yet
- Sys CommandsDocument25 pagesSys CommandsJulián DaríoNo ratings yet
- BDA Lab 4: Python Data Visualization: Your Name: Mohamad Salehuddin Bin Zulkefli Matric No: 17005054Document10 pagesBDA Lab 4: Python Data Visualization: Your Name: Mohamad Salehuddin Bin Zulkefli Matric No: 17005054Saleh ZulNo ratings yet
- Function: Ingresar - Callback (Hobject, Eventdata, Handles)Document5 pagesFunction: Ingresar - Callback (Hobject, Eventdata, Handles)Wilber Carbajal SulcaNo ratings yet
- Prototype 13Document1 pagePrototype 13Yemi TowobolaNo ratings yet
- Dash IntroDocument18 pagesDash IntroTan ChNo ratings yet
- Re Pandas PD Glob Scipy - Cluster.hierarchy Matplotlib Shutil Os PathlibDocument2 pagesRe Pandas PD Glob Scipy - Cluster.hierarchy Matplotlib Shutil Os PathlibMarco LongobardiNo ratings yet
- Ada Final Lab PGDocument12 pagesAda Final Lab PGAlok KumarNo ratings yet
- Test - Parallel: Experiment 5 To Perform Parallel Port InterfacingDocument19 pagesTest - Parallel: Experiment 5 To Perform Parallel Port InterfacingAtit PatelNo ratings yet
- Message: - 2022 10 10 10 32Document36 pagesMessage: - 2022 10 10 10 32Duy DatNo ratings yet
- Cab Booking System - SonaliDocument11 pagesCab Booking System - SonaliRitesh Kumar MishraNo ratings yet
- Deancil E Zinyengere R202004C Outlet m3sDocument5 pagesDeancil E Zinyengere R202004C Outlet m3sTeddy MukadzamboNo ratings yet
- Shaheed Zulfikar Ali Bhutto Institute of Science & TechnologyDocument12 pagesShaheed Zulfikar Ali Bhutto Institute of Science & TechnologyJia AliNo ratings yet
- Time Series BasicsDocument21 pagesTime Series BasicsChopra Shubham100% (1)
- Codes of IntegrationDocument2 pagesCodes of IntegrationpkdscdubaiNo ratings yet
- Nafiz - Toll 1Document12 pagesNafiz - Toll 1NAFIZ AHMED NAHINNo ratings yet
- AI-MAJOR-AUGUST - Aryal AshishDocument16 pagesAI-MAJOR-AUGUST - Aryal AshishAshish AryalNo ratings yet
- AUTO CLAIM FREEBITCOIN FAUCET (2022) - Freebitcoin by BitcoinbeesDocument2 pagesAUTO CLAIM FREEBITCOIN FAUCET (2022) - Freebitcoin by Bitcoinbeeshasky2330No ratings yet
- CodingDocument3 pagesCodingAjue RamliNo ratings yet
- Grafik - Init - : Import From Import From Import Import As Import AsDocument5 pagesGrafik - Init - : Import From Import From Import Import As Import AsAdhiva YuliantoNo ratings yet
- Assignment 4 On Visualization On Graph With SolutionDocument14 pagesAssignment 4 On Visualization On Graph With Solutionvikas_2No ratings yet
- MLRecordDocument24 pagesMLRecordranadheer5221No ratings yet
- Sum 1 JqueryDocument8 pagesSum 1 JqueryTrevorsNo ratings yet
- Fds SlipsDocument6 pagesFds Slipskaranka103No ratings yet
- Content Text HTML Charset Utf-8 Title Gmail Title Meta Httpequiv X-Ua-CompatibleDocument146 pagesContent Text HTML Charset Utf-8 Title Gmail Title Meta Httpequiv X-Ua-CompatibleIttr GreyNo ratings yet
- Fundamentals of Data VisualizationDocument14 pagesFundamentals of Data Visualizationssakhare2001No ratings yet
- Calculus For OptimizationDocument5 pagesCalculus For OptimizationROHIT ARORANo ratings yet
- Deancil E Zinyengere R202004C Nosa m3sDocument5 pagesDeancil E Zinyengere R202004C Nosa m3sTeddy MukadzamboNo ratings yet
- Week1-SPT2 Descriptive StatisticsDocument8 pagesWeek1-SPT2 Descriptive StatisticsRamiz JavedNo ratings yet
- MATH2070 Computer Project: Organise Porject FoldDocument4 pagesMATH2070 Computer Project: Organise Porject FoldAbdul Muqsait KenyeNo ratings yet
- 《Operating Systems》-Experimental instruction-Experiment 5 FIFO algorithmDocument6 pages《Operating Systems》-Experimental instruction-Experiment 5 FIFO algorithmBRANDY GANYIRENo ratings yet
- AD3301 - Visualization - Ipynb - ColaboratoryDocument15 pagesAD3301 - Visualization - Ipynb - Colaboratorypalaniappan.cseNo ratings yet
- Angular Portfolio App Development: Building Modern and Engaging PortfoliosFrom EverandAngular Portfolio App Development: Building Modern and Engaging PortfoliosNo ratings yet
- SLEM - PC11AG - Quarter1 - Week6Document30 pagesSLEM - PC11AG - Quarter1 - Week6Madz MaitsNo ratings yet
- Lesson Plans WK 26Document7 pagesLesson Plans WK 26api-280840865No ratings yet
- Top 5 Strumming Patterns OK PDFDocument6 pagesTop 5 Strumming Patterns OK PDFjumpin_around100% (1)
- Bullock Cart: Aarushree KhobragadeDocument13 pagesBullock Cart: Aarushree KhobragadeAzure MidoriyaNo ratings yet
- Information and Communications Technology Skills and Digital Literacy of Senior High School StudentsDocument12 pagesInformation and Communications Technology Skills and Digital Literacy of Senior High School StudentsPsychology and Education: A Multidisciplinary JournalNo ratings yet
- Solar Power PlantDocument23 pagesSolar Power Plantmadhu_bedi12No ratings yet
- 322 Dynamic Demographic Characteristic Slum Population in Nashik City With Special Reference From 2011Document6 pages322 Dynamic Demographic Characteristic Slum Population in Nashik City With Special Reference From 2011B-15 Keyur BhanushaliNo ratings yet
- The Metaphysics of The Upanishads VicharDocument461 pagesThe Metaphysics of The Upanishads VicharAyush GaikwadNo ratings yet
- Dwadasa Nama of KartaveeryaDocument4 pagesDwadasa Nama of KartaveeryaVijaya BhaskarNo ratings yet
- Erba BilubrinDocument2 pagesErba BilubrinOjie SarojieNo ratings yet
- Iphone DissertationDocument7 pagesIphone DissertationPapersWritingServiceCanada100% (1)
- National Simultaneous Earthquake and Fire DrillsDocument2 pagesNational Simultaneous Earthquake and Fire DrillsCatherine TamayoNo ratings yet
- Pregnancy-Related Pelvic Girdle Pain: Second Stage of LabourDocument4 pagesPregnancy-Related Pelvic Girdle Pain: Second Stage of LabourSravan Ganji100% (1)
- Egger Nursery's in KeralaDocument6 pagesEgger Nursery's in KeralanidhinpillaiNo ratings yet
- Gas/Liquid Separators: Quantifying Separation Performance - Part 1Document10 pagesGas/Liquid Separators: Quantifying Separation Performance - Part 1sara25dec689288No ratings yet
- Free Bhel Transformer Book PDFDocument4 pagesFree Bhel Transformer Book PDFMilan ShahNo ratings yet
- Toad For OracleDocument1,157 pagesToad For OraclesatsriniNo ratings yet
- Sentences, Fragments, & Run-OnsDocument6 pagesSentences, Fragments, & Run-Onslu liu100% (1)
- Blockchain Based Car-Sharing Platform: September 2019Document5 pagesBlockchain Based Car-Sharing Platform: September 2019Chiraz Elhog0% (1)
- Three Phase Induction Motor - Squirrel Cage: Data SheetDocument6 pagesThree Phase Induction Motor - Squirrel Cage: Data Sheetjulio100% (1)
- InTek UC-504G RTU+ Brochure R5Document2 pagesInTek UC-504G RTU+ Brochure R5Harisman MuhammadNo ratings yet
- Braintree 15Document6 pagesBraintree 15paypaltrexNo ratings yet
- Loss Tangent of High Resistive Silicon Substrate in HFSSDocument2 pagesLoss Tangent of High Resistive Silicon Substrate in HFSSNam ChamNo ratings yet
- Marketing Plan: GoldilocksDocument18 pagesMarketing Plan: GoldilocksAkhia Visitacion100% (1)
- ISC 2016 Chemistry Paper 2 Practical SolvedDocument12 pagesISC 2016 Chemistry Paper 2 Practical SolvedMritunjay Kumar SharmaNo ratings yet
- PunctuationsDocument5 pagesPunctuationsPrincess De VegaNo ratings yet
- Gerund NounDocument15 pagesGerund NounNanda PutriNo ratings yet
- Lesson PlanDocument2 pagesLesson PlanVîrforeanu Nicolae AlinNo ratings yet
- Problem Statement SubhanDocument5 pagesProblem Statement SubhanTech UniverseNo ratings yet
- Bendix Actuator Competitive Cross Reference ListDocument1 pageBendix Actuator Competitive Cross Reference ListFernando PadillaNo ratings yet