
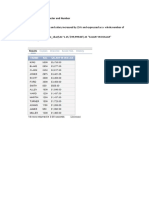
Lab Assignment 1 Ucs551
Lab Assignment 1 Ucs551
You might also like
- Maf651 Seminar 2 ReportDocument13 pagesMaf651 Seminar 2 Report2022908185No ratings yet
- 5.1.3 Journal - Relating To The ClustersDocument2 pages5.1.3 Journal - Relating To The ClustersPatience Lee Anna Gaskins-Epps,No ratings yet
- Examiners' Report 2014: LA3003 Land Law - Zone A Specific Comments On QuestionsDocument15 pagesExaminers' Report 2014: LA3003 Land Law - Zone A Specific Comments On QuestionsAnannya GhoshNo ratings yet
- 5.21. Chemometric Methods Applied To Analytical DataDocument18 pages5.21. Chemometric Methods Applied To Analytical DataAlejandro Romero ValenciaNo ratings yet
- Exercise 3 Character and Number FunctionDocument7 pagesExercise 3 Character and Number FunctionFaqihah SyazwaniNo ratings yet
- Impact Mis in Supply Chain ManagemtDocument16 pagesImpact Mis in Supply Chain Managemtpratap100% (1)
- Part A: AIS615 Test 1Document6 pagesPart A: AIS615 Test 1fareen faridNo ratings yet
- CSC583 Artificial Intelligence Algorithms Group Assignment (30%)Document3 pagesCSC583 Artificial Intelligence Algorithms Group Assignment (30%)harith danishNo ratings yet
- 4A - GROUP 3 - KEDUA by Waks ShakeDocument38 pages4A - GROUP 3 - KEDUA by Waks ShakeWani che joNo ratings yet
- Watt Gearboxes-CatalogueDocument18 pagesWatt Gearboxes-CataloguecakhokheNo ratings yet
- Audit Risk NotesDocument14 pagesAudit Risk NotesRana NadeemNo ratings yet
- Hours of Work - AnswerDocument5 pagesHours of Work - AnswerAida TuahNo ratings yet
- Swot & PestDocument11 pagesSwot & PestMuhammad UsmanNo ratings yet
- Analysis of Hong Leong BankDocument9 pagesAnalysis of Hong Leong BankThai CelineNo ratings yet
- Jobsheet Unit 7Document8 pagesJobsheet Unit 7Na'im FauzanNo ratings yet
- BMS533 Practical Lab Report (Group 6)Document37 pagesBMS533 Practical Lab Report (Group 6)YUSNURDALILA DALINo ratings yet
- Experiment 6 Organic Chemistry ResultDocument4 pagesExperiment 6 Organic Chemistry ResultFariza ZaidanNo ratings yet
- Sample Programming Assignment PDFDocument94 pagesSample Programming Assignment PDFMohamed SabrinNo ratings yet
- (4.0) BSR552 - TIMBER FRAME SYSTEM (GP 4) - 4A FinalizedDocument61 pages(4.0) BSR552 - TIMBER FRAME SYSTEM (GP 4) - 4A FinalizedMuhammad RidzuanNo ratings yet
- Final Test Fin533 January 2024Document13 pagesFinal Test Fin533 January 20242023607226No ratings yet
- Financial Management (FIN401) : Capital BudgetingDocument34 pagesFinancial Management (FIN401) : Capital BudgetingNavid GodilNo ratings yet
- Cit452 Visual Analysis Nur Aliza Akasha 2022964141Document16 pagesCit452 Visual Analysis Nur Aliza Akasha 2022964141Arif FitriNo ratings yet
- 3B Group2 Case StudyDocument8 pages3B Group2 Case Studynatasya hanimNo ratings yet
- Nur Ainina Najwa BT Zamzuri - Test 2Document12 pagesNur Ainina Najwa BT Zamzuri - Test 2harley quinnnNo ratings yet
- Solution Aud589 Feb 2021Document7 pagesSolution Aud589 Feb 2021RABIATULNAZIHAH NAZRINo ratings yet
- Lab Report Agr521 Group 4Document26 pagesLab Report Agr521 Group 4nt2hwj7tphNo ratings yet
- TKP3501 - Individual AssignmentDocument5 pagesTKP3501 - Individual AssignmentNAJWA ASYSIKIN BINTI A.ZANI / UPMNo ratings yet
- DQS259 - Assignment 1Document21 pagesDQS259 - Assignment 1Ahmad NaufalNo ratings yet
- Chapter 6Document15 pagesChapter 6RebelliousRascalNo ratings yet
- Chapter 1 ExerciseDocument25 pagesChapter 1 ExerciseAfifah HananiNo ratings yet
- Analisis Misi Pengurusan StrategikDocument4 pagesAnalisis Misi Pengurusan StrategikAienYien LengLeng YengYeng PinkyMeNo ratings yet
- Far570 Q Test December 2022Document4 pagesFar570 Q Test December 2022fareen faridNo ratings yet
- 2.4.3 Test (TST) - College Knowledge (Test)Document5 pages2.4.3 Test (TST) - College Knowledge (Test)Ismael Rueda GonzalezNo ratings yet
- Solid and Semi-Solid Media: Discussion: Transfer Culture InoculationDocument2 pagesSolid and Semi-Solid Media: Discussion: Transfer Culture InoculationLeena MuniandyNo ratings yet
- Practical Report C2 Adm665 - Athirah 2021120107Document11 pagesPractical Report C2 Adm665 - Athirah 2021120107Liyana AzizNo ratings yet
- Jabatan Pendaftaran Negara & Ors v. A Child & Ors (Majlis Agama Islam Negeri Johor, Intervener) (2020) 2 MLJ 277 (Federal Court)Document5 pagesJabatan Pendaftaran Negara & Ors v. A Child & Ors (Majlis Agama Islam Negeri Johor, Intervener) (2020) 2 MLJ 277 (Federal Court)HAIFA ALISYA ROSMINNo ratings yet
- 4.4.3 Test (TST) - Financial Aid (Test)Document3 pages4.4.3 Test (TST) - Financial Aid (Test)Nia MitchellNo ratings yet
- Reflective Paper MGT430Document5 pagesReflective Paper MGT430AmmarNo ratings yet
- Maf651 Seminar 2 Sustainability Development & Environmental ManagementDocument33 pagesMaf651 Seminar 2 Sustainability Development & Environmental ManagementAISHAH HUDA AHMAD DAUDNo ratings yet
- The Usability Metrics For User ExperienceDocument6 pagesThe Usability Metrics For User ExperienceVIVA-TECH IJRINo ratings yet
- Final Executive SummaryDocument13 pagesFinal Executive SummaryDeon SmithNo ratings yet
- ITT470 Project Report - Car Security & MonitoringDocument11 pagesITT470 Project Report - Car Security & Monitoring2022491196100% (1)
- Management 111204015409 Phpapp01Document12 pagesManagement 111204015409 Phpapp01syidaluvanimeNo ratings yet
- Lab 4 MIC254Document13 pagesLab 4 MIC254NADIA YASMIN MOHD ZAKINo ratings yet
- Fin533 Group AssignmentDocument23 pagesFin533 Group AssignmentAzwin YusoffNo ratings yet
- Business Law Individual Report, A20a1826, Nurin Atiqah Hanim Binti TalhahDocument8 pagesBusiness Law Individual Report, A20a1826, Nurin Atiqah Hanim Binti TalhahnurinNo ratings yet
- Petronas Website Ims 556Document15 pagesPetronas Website Ims 556Luqman AriefNo ratings yet
- Laboratory3-ITT557-2020878252-SITI FARHANADocument16 pagesLaboratory3-ITT557-2020878252-SITI FARHANAAnna SasakiNo ratings yet
- CSC577 (Test2) - 20222 20220620Document3 pagesCSC577 (Test2) - 20222 20220620yayanariff96No ratings yet
- DQS 251 Assignment 2Document54 pagesDQS 251 Assignment 2izzatul haniNo ratings yet
- MAF653-Group Assignment 2Document11 pagesMAF653-Group Assignment 2nurul syakirinNo ratings yet
- Mat530 - Mini Project - Group 2Document25 pagesMat530 - Mini Project - Group 2NUR DINI HUDANo ratings yet
- MGT162 Individual AssignmentDocument28 pagesMGT162 Individual AssignmentMark RacoonNo ratings yet
- ASM510 - Accss - Assignment 1 - TASNEEM MAISARA&NUR IZZATYDocument14 pagesASM510 - Accss - Assignment 1 - TASNEEM MAISARA&NUR IZZATYZaty RosmiNo ratings yet
- Laboratory5-ITT557-2020878252-SITI FARHANADocument8 pagesLaboratory5-ITT557-2020878252-SITI FARHANAAnna SasakiNo ratings yet
- Determination of Solids in WaterDocument7 pagesDetermination of Solids in WaterManoj KarmakarNo ratings yet
- PACEDocument3 pagesPACEKimNo ratings yet
- Field Report Pac671 - Nur AzreenDocument16 pagesField Report Pac671 - Nur Azreen2021117961No ratings yet
- MGT400 Test - July 2022 NATASHA NABILA M1 2020459196Document16 pagesMGT400 Test - July 2022 NATASHA NABILA M1 2020459196natashabasryNo ratings yet
- ITEC244 ClientSideValidation 202310Document4 pagesITEC244 ClientSideValidation 202310priyankaNo ratings yet
- BSC in Information Technology - Semester 1, 2018 Distributed Computing Assignment 2 - Rest ApiDocument4 pagesBSC in Information Technology - Semester 1, 2018 Distributed Computing Assignment 2 - Rest ApiAruna Sujith KarunarathnaNo ratings yet
- Gologit 2Document26 pagesGologit 2José Eronides JuniorNo ratings yet
- Strategies For Extending High Capacity Students Reading ComprehensionDocument43 pagesStrategies For Extending High Capacity Students Reading ComprehensionKelpie LangNo ratings yet
- Python Machine Learning - Logistic RegressionDocument1 pagePython Machine Learning - Logistic Regressionahmed salemNo ratings yet
- The Impact of Non-Performing Loans On Bank Lending Behavior: Evidence From The Italian Banking SectorDocument13 pagesThe Impact of Non-Performing Loans On Bank Lending Behavior: Evidence From The Italian Banking SectorabhinavatripathiNo ratings yet
- Luttik Et Al-2007-European Journal of Heart FailureDocument7 pagesLuttik Et Al-2007-European Journal of Heart FailureSiti lestarinurhamidahNo ratings yet
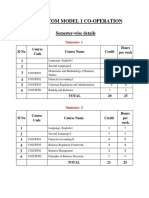
- B Com Model 1 Co OperationDocument37 pagesB Com Model 1 Co OperationHvffNo ratings yet
- 10-1108 - Ijmf-12-2014-0187 (Jurnal Audit)Document21 pages10-1108 - Ijmf-12-2014-0187 (Jurnal Audit)indri retnoningtyasNo ratings yet
- Perspectives On System IdentificationDocument17 pagesPerspectives On System Identificationpladott19678No ratings yet
- Functional Form and Prediction: OLS Estimation - AssumptionsDocument37 pagesFunctional Form and Prediction: OLS Estimation - AssumptionsVikas NehraNo ratings yet
- Correlations Between MRI Brain Volumetric Measurements and IQ ScoresDocument10 pagesCorrelations Between MRI Brain Volumetric Measurements and IQ ScoresJemima ChanNo ratings yet
- Prerequisites, MFE Program, Berkeley-HaasDocument3 pagesPrerequisites, MFE Program, Berkeley-HaasAbynMathewScariaNo ratings yet
- State-Sponsored Mass MurderDocument31 pagesState-Sponsored Mass MurderStéphanie ThomsonNo ratings yet
- MBA 2 YearDocument120 pagesMBA 2 YearvishalmehandirattaNo ratings yet
- RegressionDocument35 pagesRegressionkarvaminNo ratings yet
- Analysis of Factors Influencing Consumer Behavior and Purchasing Decision Making at Coffe ShopDocument5 pagesAnalysis of Factors Influencing Consumer Behavior and Purchasing Decision Making at Coffe ShopInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- TRANSPORTATION ENGINEERING - SW 1Document5 pagesTRANSPORTATION ENGINEERING - SW 1Geojanni PangibitanNo ratings yet
- 1997 Majumdar - Modularity and Productivity, Impact of Digital Technology in Telcom IndustryDocument15 pages1997 Majumdar - Modularity and Productivity, Impact of Digital Technology in Telcom IndustryAnugerah Sukses NusantaraNo ratings yet
- SAS - Modeling Trend, Cycles, and Seasonality in Time Series Data Using PROC UCMDocument3 pagesSAS - Modeling Trend, Cycles, and Seasonality in Time Series Data Using PROC UCMONSITENo ratings yet
- Family-Owned Businesses - Determinants of Business Success and ProDocument97 pagesFamily-Owned Businesses - Determinants of Business Success and ProCarla AmosNo ratings yet
- Moringa School DS Fulltime Flatiron Brochure Mobile Brochure 2022 1Document6 pagesMoringa School DS Fulltime Flatiron Brochure Mobile Brochure 2022 1DENISNo ratings yet
- Carleton University ECON 5027: Econometrics I: General InformationDocument9 pagesCarleton University ECON 5027: Econometrics I: General InformationMotasem K. QaddouraNo ratings yet
- MGMT E-104: Quantitative Methods For Economics and Finance: Course OverviewDocument7 pagesMGMT E-104: Quantitative Methods For Economics and Finance: Course OverviewmiguelNo ratings yet
- Data Analysis Project 2 Due 5:00 PM Nov 21 1 InstructionsDocument3 pagesData Analysis Project 2 Due 5:00 PM Nov 21 1 InstructionsSNo ratings yet
- Paper - Analysing Remote Sensing Data in RDocument25 pagesPaper - Analysing Remote Sensing Data in Rvickneshj9406No ratings yet
- 36-401 Modern Regression HW #5 Solutions: Air - FlowDocument7 pages36-401 Modern Regression HW #5 Solutions: Air - FlowSNo ratings yet
- ECON 10: Introduction To Statistical Methods Final Exam (Part 2)Document1 pageECON 10: Introduction To Statistical Methods Final Exam (Part 2)RC WillenbrockNo ratings yet
- MeiseDocument62 pagesMeiseafnene1No ratings yet
- A Predictor For Movie Success: 2.1 Data CollectionDocument5 pagesA Predictor For Movie Success: 2.1 Data CollectionSeung Pyo SonNo ratings yet
- Course Title - Public Policy AnalysisDocument116 pagesCourse Title - Public Policy AnalysisKdropsNo ratings yet
























































































Download as docx, pdf, or txt
You might also like
- Maf651 Seminar 2 ReportDocument13 pagesMaf651 Seminar 2 Report2022908185No ratings yet
- 5.1.3 Journal - Relating To The ClustersDocument2 pages5.1.3 Journal - Relating To The ClustersPatience Lee Anna Gaskins-Epps,No ratings yet
- Examiners' Report 2014: LA3003 Land Law - Zone A Specific Comments On QuestionsDocument15 pagesExaminers' Report 2014: LA3003 Land Law - Zone A Specific Comments On QuestionsAnannya GhoshNo ratings yet
- 5.21. Chemometric Methods Applied To Analytical DataDocument18 pages5.21. Chemometric Methods Applied To Analytical DataAlejandro Romero ValenciaNo ratings yet
- Exercise 3 Character and Number FunctionDocument7 pagesExercise 3 Character and Number FunctionFaqihah SyazwaniNo ratings yet
- Impact Mis in Supply Chain ManagemtDocument16 pagesImpact Mis in Supply Chain Managemtpratap100% (1)
- Part A: AIS615 Test 1Document6 pagesPart A: AIS615 Test 1fareen faridNo ratings yet
- CSC583 Artificial Intelligence Algorithms Group Assignment (30%)Document3 pagesCSC583 Artificial Intelligence Algorithms Group Assignment (30%)harith danishNo ratings yet
- 4A - GROUP 3 - KEDUA by Waks ShakeDocument38 pages4A - GROUP 3 - KEDUA by Waks ShakeWani che joNo ratings yet
- Watt Gearboxes-CatalogueDocument18 pagesWatt Gearboxes-CataloguecakhokheNo ratings yet
- Audit Risk NotesDocument14 pagesAudit Risk NotesRana NadeemNo ratings yet
- Hours of Work - AnswerDocument5 pagesHours of Work - AnswerAida TuahNo ratings yet
- Swot & PestDocument11 pagesSwot & PestMuhammad UsmanNo ratings yet
- Analysis of Hong Leong BankDocument9 pagesAnalysis of Hong Leong BankThai CelineNo ratings yet
- Jobsheet Unit 7Document8 pagesJobsheet Unit 7Na'im FauzanNo ratings yet
- BMS533 Practical Lab Report (Group 6)Document37 pagesBMS533 Practical Lab Report (Group 6)YUSNURDALILA DALINo ratings yet
- Experiment 6 Organic Chemistry ResultDocument4 pagesExperiment 6 Organic Chemistry ResultFariza ZaidanNo ratings yet
- Sample Programming Assignment PDFDocument94 pagesSample Programming Assignment PDFMohamed SabrinNo ratings yet
- (4.0) BSR552 - TIMBER FRAME SYSTEM (GP 4) - 4A FinalizedDocument61 pages(4.0) BSR552 - TIMBER FRAME SYSTEM (GP 4) - 4A FinalizedMuhammad RidzuanNo ratings yet
- Final Test Fin533 January 2024Document13 pagesFinal Test Fin533 January 20242023607226No ratings yet
- Financial Management (FIN401) : Capital BudgetingDocument34 pagesFinancial Management (FIN401) : Capital BudgetingNavid GodilNo ratings yet
- Cit452 Visual Analysis Nur Aliza Akasha 2022964141Document16 pagesCit452 Visual Analysis Nur Aliza Akasha 2022964141Arif FitriNo ratings yet
- 3B Group2 Case StudyDocument8 pages3B Group2 Case Studynatasya hanimNo ratings yet
- Nur Ainina Najwa BT Zamzuri - Test 2Document12 pagesNur Ainina Najwa BT Zamzuri - Test 2harley quinnnNo ratings yet
- Solution Aud589 Feb 2021Document7 pagesSolution Aud589 Feb 2021RABIATULNAZIHAH NAZRINo ratings yet
- Lab Report Agr521 Group 4Document26 pagesLab Report Agr521 Group 4nt2hwj7tphNo ratings yet
- TKP3501 - Individual AssignmentDocument5 pagesTKP3501 - Individual AssignmentNAJWA ASYSIKIN BINTI A.ZANI / UPMNo ratings yet
- DQS259 - Assignment 1Document21 pagesDQS259 - Assignment 1Ahmad NaufalNo ratings yet
- Chapter 6Document15 pagesChapter 6RebelliousRascalNo ratings yet
- Chapter 1 ExerciseDocument25 pagesChapter 1 ExerciseAfifah HananiNo ratings yet
- Analisis Misi Pengurusan StrategikDocument4 pagesAnalisis Misi Pengurusan StrategikAienYien LengLeng YengYeng PinkyMeNo ratings yet
- Far570 Q Test December 2022Document4 pagesFar570 Q Test December 2022fareen faridNo ratings yet
- 2.4.3 Test (TST) - College Knowledge (Test)Document5 pages2.4.3 Test (TST) - College Knowledge (Test)Ismael Rueda GonzalezNo ratings yet
- Solid and Semi-Solid Media: Discussion: Transfer Culture InoculationDocument2 pagesSolid and Semi-Solid Media: Discussion: Transfer Culture InoculationLeena MuniandyNo ratings yet
- Practical Report C2 Adm665 - Athirah 2021120107Document11 pagesPractical Report C2 Adm665 - Athirah 2021120107Liyana AzizNo ratings yet
- Jabatan Pendaftaran Negara & Ors v. A Child & Ors (Majlis Agama Islam Negeri Johor, Intervener) (2020) 2 MLJ 277 (Federal Court)Document5 pagesJabatan Pendaftaran Negara & Ors v. A Child & Ors (Majlis Agama Islam Negeri Johor, Intervener) (2020) 2 MLJ 277 (Federal Court)HAIFA ALISYA ROSMINNo ratings yet
- 4.4.3 Test (TST) - Financial Aid (Test)Document3 pages4.4.3 Test (TST) - Financial Aid (Test)Nia MitchellNo ratings yet
- Reflective Paper MGT430Document5 pagesReflective Paper MGT430AmmarNo ratings yet
- Maf651 Seminar 2 Sustainability Development & Environmental ManagementDocument33 pagesMaf651 Seminar 2 Sustainability Development & Environmental ManagementAISHAH HUDA AHMAD DAUDNo ratings yet
- The Usability Metrics For User ExperienceDocument6 pagesThe Usability Metrics For User ExperienceVIVA-TECH IJRINo ratings yet
- Final Executive SummaryDocument13 pagesFinal Executive SummaryDeon SmithNo ratings yet
- ITT470 Project Report - Car Security & MonitoringDocument11 pagesITT470 Project Report - Car Security & Monitoring2022491196100% (1)
- Management 111204015409 Phpapp01Document12 pagesManagement 111204015409 Phpapp01syidaluvanimeNo ratings yet
- Lab 4 MIC254Document13 pagesLab 4 MIC254NADIA YASMIN MOHD ZAKINo ratings yet
- Fin533 Group AssignmentDocument23 pagesFin533 Group AssignmentAzwin YusoffNo ratings yet
- Business Law Individual Report, A20a1826, Nurin Atiqah Hanim Binti TalhahDocument8 pagesBusiness Law Individual Report, A20a1826, Nurin Atiqah Hanim Binti TalhahnurinNo ratings yet
- Petronas Website Ims 556Document15 pagesPetronas Website Ims 556Luqman AriefNo ratings yet
- Laboratory3-ITT557-2020878252-SITI FARHANADocument16 pagesLaboratory3-ITT557-2020878252-SITI FARHANAAnna SasakiNo ratings yet
- CSC577 (Test2) - 20222 20220620Document3 pagesCSC577 (Test2) - 20222 20220620yayanariff96No ratings yet
- DQS 251 Assignment 2Document54 pagesDQS 251 Assignment 2izzatul haniNo ratings yet
- MAF653-Group Assignment 2Document11 pagesMAF653-Group Assignment 2nurul syakirinNo ratings yet
- Mat530 - Mini Project - Group 2Document25 pagesMat530 - Mini Project - Group 2NUR DINI HUDANo ratings yet
- MGT162 Individual AssignmentDocument28 pagesMGT162 Individual AssignmentMark RacoonNo ratings yet
- ASM510 - Accss - Assignment 1 - TASNEEM MAISARA&NUR IZZATYDocument14 pagesASM510 - Accss - Assignment 1 - TASNEEM MAISARA&NUR IZZATYZaty RosmiNo ratings yet
- Laboratory5-ITT557-2020878252-SITI FARHANADocument8 pagesLaboratory5-ITT557-2020878252-SITI FARHANAAnna SasakiNo ratings yet
- Determination of Solids in WaterDocument7 pagesDetermination of Solids in WaterManoj KarmakarNo ratings yet
- PACEDocument3 pagesPACEKimNo ratings yet
- Field Report Pac671 - Nur AzreenDocument16 pagesField Report Pac671 - Nur Azreen2021117961No ratings yet
- MGT400 Test - July 2022 NATASHA NABILA M1 2020459196Document16 pagesMGT400 Test - July 2022 NATASHA NABILA M1 2020459196natashabasryNo ratings yet
- ITEC244 ClientSideValidation 202310Document4 pagesITEC244 ClientSideValidation 202310priyankaNo ratings yet
- BSC in Information Technology - Semester 1, 2018 Distributed Computing Assignment 2 - Rest ApiDocument4 pagesBSC in Information Technology - Semester 1, 2018 Distributed Computing Assignment 2 - Rest ApiAruna Sujith KarunarathnaNo ratings yet
- Gologit 2Document26 pagesGologit 2José Eronides JuniorNo ratings yet
- Strategies For Extending High Capacity Students Reading ComprehensionDocument43 pagesStrategies For Extending High Capacity Students Reading ComprehensionKelpie LangNo ratings yet
- Python Machine Learning - Logistic RegressionDocument1 pagePython Machine Learning - Logistic Regressionahmed salemNo ratings yet
- The Impact of Non-Performing Loans On Bank Lending Behavior: Evidence From The Italian Banking SectorDocument13 pagesThe Impact of Non-Performing Loans On Bank Lending Behavior: Evidence From The Italian Banking SectorabhinavatripathiNo ratings yet
- Luttik Et Al-2007-European Journal of Heart FailureDocument7 pagesLuttik Et Al-2007-European Journal of Heart FailureSiti lestarinurhamidahNo ratings yet
- B Com Model 1 Co OperationDocument37 pagesB Com Model 1 Co OperationHvffNo ratings yet
- 10-1108 - Ijmf-12-2014-0187 (Jurnal Audit)Document21 pages10-1108 - Ijmf-12-2014-0187 (Jurnal Audit)indri retnoningtyasNo ratings yet
- Perspectives On System IdentificationDocument17 pagesPerspectives On System Identificationpladott19678No ratings yet
- Functional Form and Prediction: OLS Estimation - AssumptionsDocument37 pagesFunctional Form and Prediction: OLS Estimation - AssumptionsVikas NehraNo ratings yet
- Correlations Between MRI Brain Volumetric Measurements and IQ ScoresDocument10 pagesCorrelations Between MRI Brain Volumetric Measurements and IQ ScoresJemima ChanNo ratings yet
- Prerequisites, MFE Program, Berkeley-HaasDocument3 pagesPrerequisites, MFE Program, Berkeley-HaasAbynMathewScariaNo ratings yet
- State-Sponsored Mass MurderDocument31 pagesState-Sponsored Mass MurderStéphanie ThomsonNo ratings yet
- MBA 2 YearDocument120 pagesMBA 2 YearvishalmehandirattaNo ratings yet
- RegressionDocument35 pagesRegressionkarvaminNo ratings yet
- Analysis of Factors Influencing Consumer Behavior and Purchasing Decision Making at Coffe ShopDocument5 pagesAnalysis of Factors Influencing Consumer Behavior and Purchasing Decision Making at Coffe ShopInternational Journal of Innovative Science and Research TechnologyNo ratings yet
- TRANSPORTATION ENGINEERING - SW 1Document5 pagesTRANSPORTATION ENGINEERING - SW 1Geojanni PangibitanNo ratings yet
- 1997 Majumdar - Modularity and Productivity, Impact of Digital Technology in Telcom IndustryDocument15 pages1997 Majumdar - Modularity and Productivity, Impact of Digital Technology in Telcom IndustryAnugerah Sukses NusantaraNo ratings yet
- SAS - Modeling Trend, Cycles, and Seasonality in Time Series Data Using PROC UCMDocument3 pagesSAS - Modeling Trend, Cycles, and Seasonality in Time Series Data Using PROC UCMONSITENo ratings yet
- Family-Owned Businesses - Determinants of Business Success and ProDocument97 pagesFamily-Owned Businesses - Determinants of Business Success and ProCarla AmosNo ratings yet
- Moringa School DS Fulltime Flatiron Brochure Mobile Brochure 2022 1Document6 pagesMoringa School DS Fulltime Flatiron Brochure Mobile Brochure 2022 1DENISNo ratings yet
- Carleton University ECON 5027: Econometrics I: General InformationDocument9 pagesCarleton University ECON 5027: Econometrics I: General InformationMotasem K. QaddouraNo ratings yet
- MGMT E-104: Quantitative Methods For Economics and Finance: Course OverviewDocument7 pagesMGMT E-104: Quantitative Methods For Economics and Finance: Course OverviewmiguelNo ratings yet
- Data Analysis Project 2 Due 5:00 PM Nov 21 1 InstructionsDocument3 pagesData Analysis Project 2 Due 5:00 PM Nov 21 1 InstructionsSNo ratings yet
- Paper - Analysing Remote Sensing Data in RDocument25 pagesPaper - Analysing Remote Sensing Data in Rvickneshj9406No ratings yet
- 36-401 Modern Regression HW #5 Solutions: Air - FlowDocument7 pages36-401 Modern Regression HW #5 Solutions: Air - FlowSNo ratings yet
- ECON 10: Introduction To Statistical Methods Final Exam (Part 2)Document1 pageECON 10: Introduction To Statistical Methods Final Exam (Part 2)RC WillenbrockNo ratings yet
- MeiseDocument62 pagesMeiseafnene1No ratings yet
- A Predictor For Movie Success: 2.1 Data CollectionDocument5 pagesA Predictor For Movie Success: 2.1 Data CollectionSeung Pyo SonNo ratings yet
- Course Title - Public Policy AnalysisDocument116 pagesCourse Title - Public Policy AnalysisKdropsNo ratings yet