
EDA Pipeline Final
EDA Pipeline Final
You might also like
- Quiz Coding Question 1Document9 pagesQuiz Coding Question 1Jay PatelNo ratings yet
- Geometric Knit Blankets: 30 Innovative and Fun-to-Knit DesignsFrom EverandGeometric Knit Blankets: 30 Innovative and Fun-to-Knit DesignsRating: 5 out of 5 stars5/5 (2)
- How To Set Up A Suspension (Time) Histogram v2Document13 pagesHow To Set Up A Suspension (Time) Histogram v2Julian Morcillo100% (2)
- Ingersoll Rand Compressor Eiger Part ListDocument70 pagesIngersoll Rand Compressor Eiger Part ListAlpesh Lakhani50% (2)
- David Blueford Gaines - Racial Possibilities As Indicated by The Negroes of Arkansas (1898)Document198 pagesDavid Blueford Gaines - Racial Possibilities As Indicated by The Negroes of Arkansas (1898)chyoungNo ratings yet
- China's Toys IndustriesDocument22 pagesChina's Toys IndustriesPathar MayurNo ratings yet
- Logistic Regression On Titanic DatasetDocument6 pagesLogistic Regression On Titanic DatasetrajNo ratings yet
- MainDocument8 pagesMainbwqsouza.cicNo ratings yet
- LogisticRegressionMLModel - Jupyter NotebookDocument14 pagesLogisticRegressionMLModel - Jupyter Notebooksatyamk86770No ratings yet
- Laporan Titanic Survival Prediction - 132021012Document6 pagesLaporan Titanic Survival Prediction - 132021012kevinNo ratings yet
- Ahamed 123Document7 pagesAhamed 123jbalapragashpathi2005100% (1)
- Making - End - To - End - Project - Without - Pipeline - Jupyter NotebookDocument5 pagesMaking - End - To - End - Project - Without - Pipeline - Jupyter Notebooksatyamk86770No ratings yet
- Import As Import As: Passengerid Survived Pclass Name Sex Age Sibsp Parch Ticket Fare Cabin 0Document5 pagesImport As Import As: Passengerid Survived Pclass Name Sex Age Sibsp Parch Ticket Fare Cabin 0testNo ratings yet
- Data CleaningDocument13 pagesData CleaningPriyanka AhujaNo ratings yet
- Eda and Prediction On Titanic Dataset: Import LibrariesDocument15 pagesEda and Prediction On Titanic Dataset: Import LibrariesRUSHIRAJ DASU100% (1)
- Logistic RegDocument8 pagesLogistic RegMithila RNo ratings yet
- Overview of Data CleaningDocument17 pagesOverview of Data CleaningShobha Kumari ChoudharyNo ratings yet
- Passengerid Survived Pclass Name Sex Age Sibsp Parch TicketDocument16 pagesPassengerid Survived Pclass Name Sex Age Sibsp Parch Ticketrutik9321No ratings yet
- What Are Decision Trees?Document9 pagesWhat Are Decision Trees?eng_mahesh1012No ratings yet
- Arboles y K-NN - Ipynb - ColaboratoryDocument17 pagesArboles y K-NN - Ipynb - ColaboratoryCharles MaldonadoNo ratings yet
- 01-Logistic Regression With PythonDocument12 pages01-Logistic Regression With PythonHellem BiersackNo ratings yet
- Import As: Pandas PD Titanic - Data PD - Read - CSV Titanic - Data - HeadDocument12 pagesImport As: Pandas PD Titanic - Data PD - Read - CSV Titanic - Data - HeadJuniorFerreiraNo ratings yet
- Pyt Manual 1Document85 pagesPyt Manual 1Hrithik KumarNo ratings yet
- 7-8 Feature Engineering 101-NormalizationDocument8 pages7-8 Feature Engineering 101-NormalizationKhan RafiNo ratings yet
- DSS CATIA ELFINI Verification ManualDocument33 pagesDSS CATIA ELFINI Verification ManualPabloNo ratings yet
- Titanic Survival Prediction 1692609491Document15 pagesTitanic Survival Prediction 1692609491Tirthankar GhoshNo ratings yet
- Titanic EdaDocument14 pagesTitanic EdaDeepak SemwalNo ratings yet
- Pertemuan Ke 14.1-Visualisasi Grafik Dengan SeabornDocument9 pagesPertemuan Ke 14.1-Visualisasi Grafik Dengan SeabornGitaartNo ratings yet
- AnalysisDocument14 pagesAnalysisakbar kNo ratings yet
- CnpartaDocument64 pagesCnpartahema manjunathNo ratings yet
- TitanicDocument13 pagesTitanicapi-579641772100% (2)
- Coding TitanicmainDocument58 pagesCoding Titanicmainnaderaqistina23No ratings yet
- SQL Guide (AutoRecovered)Document155 pagesSQL Guide (AutoRecovered)yudhishyudhisthranNo ratings yet
- ML 3Document9 pagesML 3yefigoh133No ratings yet
- CN Lab ManualDocument60 pagesCN Lab ManualJ ShankarNo ratings yet
- Advanced Database OperationDocument8 pagesAdvanced Database OperationfamasyaNo ratings yet
- Dataset and Visualization: Ames Set UCI Machine Learning Datasets (Https://archive - Ics.uci - Edu/ml/index - PHP)Document4 pagesDataset and Visualization: Ames Set UCI Machine Learning Datasets (Https://archive - Ics.uci - Edu/ml/index - PHP)Hamed GholamiNo ratings yet
- hw3 1Document9 pageshw3 1api-595755064No ratings yet
- Titanic DataDocument5 pagesTitanic DataDhanasekarNo ratings yet
- Lab 3Document7 pagesLab 3alishacalista238No ratings yet
- Instructions:: Mltest2question - Jupyter NotebookDocument6 pagesInstructions:: Mltest2question - Jupyter NotebookAniruddha TrivediNo ratings yet
- EDA On Titanic DatasetDocument39 pagesEDA On Titanic DatasetSoumya Saha100% (1)
- AI Final PDFDocument38 pagesAI Final PDFMr. G. Naga ChaitanyaNo ratings yet
- Syllabus and ManualCBCSDocument64 pagesSyllabus and ManualCBCSPreethuraj RoyNo ratings yet
- Computer Network Lab 1Document61 pagesComputer Network Lab 1AkshataNo ratings yet
- CN Lab9900Document42 pagesCN Lab9900sriharshapatilsbNo ratings yet
- Computer NotesDocument47 pagesComputer NotesHarish DNo ratings yet
- Question Paper Xii Cs Pract 2015Document5 pagesQuestion Paper Xii Cs Pract 2015anandarajuNo ratings yet
- NsDocument72 pagesNsStark NessonNo ratings yet
- 10KWp Landscape Structure - 3m Super Structure For 200KmphDocument97 pages10KWp Landscape Structure - 3m Super Structure For 200KmphRajat MarvalNo ratings yet
- 8 Feature EngineeringDocument29 pages8 Feature EngineeringLuka FilipovicNo ratings yet
- ComputerDocument47 pagesComputerHarish DNo ratings yet
- 2003 Prentice Hall, Inc. All Rights ReservedDocument52 pages2003 Prentice Hall, Inc. All Rights ReservedSukhwinder Singh GillNo ratings yet
- CN Manual (5th Sem)Document44 pagesCN Manual (5th Sem)vaishuteju12No ratings yet
- CN ManualDocument57 pagesCN Manualwavovaf945No ratings yet
- STA1040 MidSem ExamDocument12 pagesSTA1040 MidSem ExamgugugagaNo ratings yet
- BC Defgehgfeigiie Hjdefikê EflgmêêfnflnDocument19 pagesBC Defgehgfeigiie Hjdefikê EflgmêêfnflnRenn QamaRennaNo ratings yet
- 221TCS100 Advanced Machine Learning, December 2023Document4 pages221TCS100 Advanced Machine Learning, December 2023mohdsabithtNo ratings yet
- Ccna Commands and LabDocument27 pagesCcna Commands and Labnanash123No ratings yet
- Lab 1Document9 pagesLab 1syedayanali28No ratings yet
- Lecture10 0Document19 pagesLecture10 0Paola RetesNo ratings yet
- Beamer by Example: Willie Dewit Jessie May David Griffiths Conference On Tasteful Presentations, 2007Document10 pagesBeamer by Example: Willie Dewit Jessie May David Griffiths Conference On Tasteful Presentations, 2007Anonymous JB9jZ9TNo ratings yet
- RobiSetiawan - Tugas 4 .IpynbDocument13 pagesRobiSetiawan - Tugas 4 .IpynbROBI SETIAWANNo ratings yet
- Advanced Opensees Algorithms, Volume 1: Probability Analysis Of High Pier Cable-Stayed Bridge Under Multiple-Support Excitations, And LiquefactionFrom EverandAdvanced Opensees Algorithms, Volume 1: Probability Analysis Of High Pier Cable-Stayed Bridge Under Multiple-Support Excitations, And LiquefactionNo ratings yet
- Entrega de Productos Wings Mobile 14-09-2021Document18 pagesEntrega de Productos Wings Mobile 14-09-2021claudiaNo ratings yet
- Indian School of Business (ISB) PGP (Intended Major: Finance) - GMAT: 740Document1 pageIndian School of Business (ISB) PGP (Intended Major: Finance) - GMAT: 740Suprateek BoseNo ratings yet
- sjp810m Manual BookDocument12 pagessjp810m Manual BookMegNo ratings yet
- What Is The Power ElectronicsDocument16 pagesWhat Is The Power ElectronicsashammoudaNo ratings yet
- Gun Rights Groups Sue Over California Carry Permit Requirements - CRPA v. LASD ComplaintDocument41 pagesGun Rights Groups Sue Over California Carry Permit Requirements - CRPA v. LASD ComplaintAmmoLand Shooting Sports NewsNo ratings yet
- AnneCecile RABINE - PortfolioDocument20 pagesAnneCecile RABINE - PortfolioAnne-Cécile RabineNo ratings yet
- MENINGITIS Lesson PlanDocument12 pagesMENINGITIS Lesson PlannidhiNo ratings yet
- Darkness Detector Circuit'Document12 pagesDarkness Detector Circuit'Divya PatilNo ratings yet
- Data Link Protocol PDFDocument24 pagesData Link Protocol PDFAndima Jeff HardyNo ratings yet
- Foundation Lecture (Abdulhafiz)Document4 pagesFoundation Lecture (Abdulhafiz)desigandNo ratings yet
- Jadual Final Exam - 2 Mei 2024Document6 pagesJadual Final Exam - 2 Mei 2024amirularifkbrNo ratings yet
- Practical Work in Geography Ch-6 Gis NewDocument44 pagesPractical Work in Geography Ch-6 Gis NewSooraj ChoukseyNo ratings yet
- Letter of TransmittalDocument7 pagesLetter of TransmittalGolam Samdanee TaneemNo ratings yet
- PEOPLE vs. Lacson, October 7, 2003Document1 pagePEOPLE vs. Lacson, October 7, 2003Thea Thei YaNo ratings yet
- Lenoir, Frederic. - Breve Tratado de Historia de Las Religiones (2018)Document47 pagesLenoir, Frederic. - Breve Tratado de Historia de Las Religiones (2018)Kike EspinozaNo ratings yet
- K Delimitation Error at Plant (New)Document30 pagesK Delimitation Error at Plant (New)ricardo cruzNo ratings yet
- S. No. Title Primary Subject Area Journal Code Impact FactorDocument6 pagesS. No. Title Primary Subject Area Journal Code Impact FactorRohitKumarSahuNo ratings yet
- Masidlak Eagles Form 2Document2 pagesMasidlak Eagles Form 2Rubie Anne SaducosNo ratings yet
- Research MethodologyDocument7 pagesResearch MethodologyJERICO IGNACIONo ratings yet
- Q9. A Proforma Cost Sheet of A Company Provides The Following ParticularsDocument2 pagesQ9. A Proforma Cost Sheet of A Company Provides The Following ParticularsGourav SharmaNo ratings yet
- MT - Aplikasi SPL Pada TrussDocument3 pagesMT - Aplikasi SPL Pada TrussRivan SeptianNo ratings yet
- Combining The ISO 10006 and PMBOK To Ensure Successful ProjectsDocument8 pagesCombining The ISO 10006 and PMBOK To Ensure Successful ProjectsMohamed Abdel-RazekNo ratings yet
- Ytg M 0512 PDFDocument128 pagesYtg M 0512 PDFAndres Felipe TapiaNo ratings yet
- 7.7.1 PROFIBUS FMS With SIMATIC NET Software 05/2000 + SP2Document56 pages7.7.1 PROFIBUS FMS With SIMATIC NET Software 05/2000 + SP2SaasiNo ratings yet
- Cloud Security Training and Awareness Programs For OrganizationsDocument2 pagesCloud Security Training and Awareness Programs For OrganizationsdeeNo ratings yet
- Proxmox Mail Gateway 5.1 Datasheet PDFDocument4 pagesProxmox Mail Gateway 5.1 Datasheet PDFRey TmoNo ratings yet














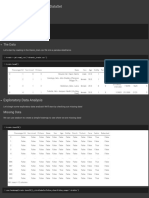



































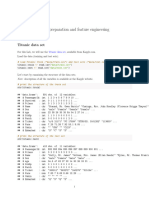







































Download as pdf or txt
You might also like
- Quiz Coding Question 1Document9 pagesQuiz Coding Question 1Jay PatelNo ratings yet
- Geometric Knit Blankets: 30 Innovative and Fun-to-Knit DesignsFrom EverandGeometric Knit Blankets: 30 Innovative and Fun-to-Knit DesignsRating: 5 out of 5 stars5/5 (2)
- How To Set Up A Suspension (Time) Histogram v2Document13 pagesHow To Set Up A Suspension (Time) Histogram v2Julian Morcillo100% (2)
- Ingersoll Rand Compressor Eiger Part ListDocument70 pagesIngersoll Rand Compressor Eiger Part ListAlpesh Lakhani50% (2)
- David Blueford Gaines - Racial Possibilities As Indicated by The Negroes of Arkansas (1898)Document198 pagesDavid Blueford Gaines - Racial Possibilities As Indicated by The Negroes of Arkansas (1898)chyoungNo ratings yet
- China's Toys IndustriesDocument22 pagesChina's Toys IndustriesPathar MayurNo ratings yet
- Logistic Regression On Titanic DatasetDocument6 pagesLogistic Regression On Titanic DatasetrajNo ratings yet
- MainDocument8 pagesMainbwqsouza.cicNo ratings yet
- LogisticRegressionMLModel - Jupyter NotebookDocument14 pagesLogisticRegressionMLModel - Jupyter Notebooksatyamk86770No ratings yet
- Laporan Titanic Survival Prediction - 132021012Document6 pagesLaporan Titanic Survival Prediction - 132021012kevinNo ratings yet
- Ahamed 123Document7 pagesAhamed 123jbalapragashpathi2005100% (1)
- Making - End - To - End - Project - Without - Pipeline - Jupyter NotebookDocument5 pagesMaking - End - To - End - Project - Without - Pipeline - Jupyter Notebooksatyamk86770No ratings yet
- Import As Import As: Passengerid Survived Pclass Name Sex Age Sibsp Parch Ticket Fare Cabin 0Document5 pagesImport As Import As: Passengerid Survived Pclass Name Sex Age Sibsp Parch Ticket Fare Cabin 0testNo ratings yet
- Data CleaningDocument13 pagesData CleaningPriyanka AhujaNo ratings yet
- Eda and Prediction On Titanic Dataset: Import LibrariesDocument15 pagesEda and Prediction On Titanic Dataset: Import LibrariesRUSHIRAJ DASU100% (1)
- Logistic RegDocument8 pagesLogistic RegMithila RNo ratings yet
- Overview of Data CleaningDocument17 pagesOverview of Data CleaningShobha Kumari ChoudharyNo ratings yet
- Passengerid Survived Pclass Name Sex Age Sibsp Parch TicketDocument16 pagesPassengerid Survived Pclass Name Sex Age Sibsp Parch Ticketrutik9321No ratings yet
- What Are Decision Trees?Document9 pagesWhat Are Decision Trees?eng_mahesh1012No ratings yet
- Arboles y K-NN - Ipynb - ColaboratoryDocument17 pagesArboles y K-NN - Ipynb - ColaboratoryCharles MaldonadoNo ratings yet
- 01-Logistic Regression With PythonDocument12 pages01-Logistic Regression With PythonHellem BiersackNo ratings yet
- Import As: Pandas PD Titanic - Data PD - Read - CSV Titanic - Data - HeadDocument12 pagesImport As: Pandas PD Titanic - Data PD - Read - CSV Titanic - Data - HeadJuniorFerreiraNo ratings yet
- Pyt Manual 1Document85 pagesPyt Manual 1Hrithik KumarNo ratings yet
- 7-8 Feature Engineering 101-NormalizationDocument8 pages7-8 Feature Engineering 101-NormalizationKhan RafiNo ratings yet
- DSS CATIA ELFINI Verification ManualDocument33 pagesDSS CATIA ELFINI Verification ManualPabloNo ratings yet
- Titanic Survival Prediction 1692609491Document15 pagesTitanic Survival Prediction 1692609491Tirthankar GhoshNo ratings yet
- Titanic EdaDocument14 pagesTitanic EdaDeepak SemwalNo ratings yet
- Pertemuan Ke 14.1-Visualisasi Grafik Dengan SeabornDocument9 pagesPertemuan Ke 14.1-Visualisasi Grafik Dengan SeabornGitaartNo ratings yet
- AnalysisDocument14 pagesAnalysisakbar kNo ratings yet
- CnpartaDocument64 pagesCnpartahema manjunathNo ratings yet
- TitanicDocument13 pagesTitanicapi-579641772100% (2)
- Coding TitanicmainDocument58 pagesCoding Titanicmainnaderaqistina23No ratings yet
- SQL Guide (AutoRecovered)Document155 pagesSQL Guide (AutoRecovered)yudhishyudhisthranNo ratings yet
- ML 3Document9 pagesML 3yefigoh133No ratings yet
- CN Lab ManualDocument60 pagesCN Lab ManualJ ShankarNo ratings yet
- Advanced Database OperationDocument8 pagesAdvanced Database OperationfamasyaNo ratings yet
- Dataset and Visualization: Ames Set UCI Machine Learning Datasets (Https://archive - Ics.uci - Edu/ml/index - PHP)Document4 pagesDataset and Visualization: Ames Set UCI Machine Learning Datasets (Https://archive - Ics.uci - Edu/ml/index - PHP)Hamed GholamiNo ratings yet
- hw3 1Document9 pageshw3 1api-595755064No ratings yet
- Titanic DataDocument5 pagesTitanic DataDhanasekarNo ratings yet
- Lab 3Document7 pagesLab 3alishacalista238No ratings yet
- Instructions:: Mltest2question - Jupyter NotebookDocument6 pagesInstructions:: Mltest2question - Jupyter NotebookAniruddha TrivediNo ratings yet
- EDA On Titanic DatasetDocument39 pagesEDA On Titanic DatasetSoumya Saha100% (1)
- AI Final PDFDocument38 pagesAI Final PDFMr. G. Naga ChaitanyaNo ratings yet
- Syllabus and ManualCBCSDocument64 pagesSyllabus and ManualCBCSPreethuraj RoyNo ratings yet
- Computer Network Lab 1Document61 pagesComputer Network Lab 1AkshataNo ratings yet
- CN Lab9900Document42 pagesCN Lab9900sriharshapatilsbNo ratings yet
- Computer NotesDocument47 pagesComputer NotesHarish DNo ratings yet
- Question Paper Xii Cs Pract 2015Document5 pagesQuestion Paper Xii Cs Pract 2015anandarajuNo ratings yet
- NsDocument72 pagesNsStark NessonNo ratings yet
- 10KWp Landscape Structure - 3m Super Structure For 200KmphDocument97 pages10KWp Landscape Structure - 3m Super Structure For 200KmphRajat MarvalNo ratings yet
- 8 Feature EngineeringDocument29 pages8 Feature EngineeringLuka FilipovicNo ratings yet
- ComputerDocument47 pagesComputerHarish DNo ratings yet
- 2003 Prentice Hall, Inc. All Rights ReservedDocument52 pages2003 Prentice Hall, Inc. All Rights ReservedSukhwinder Singh GillNo ratings yet
- CN Manual (5th Sem)Document44 pagesCN Manual (5th Sem)vaishuteju12No ratings yet
- CN ManualDocument57 pagesCN Manualwavovaf945No ratings yet
- STA1040 MidSem ExamDocument12 pagesSTA1040 MidSem ExamgugugagaNo ratings yet
- BC Defgehgfeigiie Hjdefikê EflgmêêfnflnDocument19 pagesBC Defgehgfeigiie Hjdefikê EflgmêêfnflnRenn QamaRennaNo ratings yet
- 221TCS100 Advanced Machine Learning, December 2023Document4 pages221TCS100 Advanced Machine Learning, December 2023mohdsabithtNo ratings yet
- Ccna Commands and LabDocument27 pagesCcna Commands and Labnanash123No ratings yet
- Lab 1Document9 pagesLab 1syedayanali28No ratings yet
- Lecture10 0Document19 pagesLecture10 0Paola RetesNo ratings yet
- Beamer by Example: Willie Dewit Jessie May David Griffiths Conference On Tasteful Presentations, 2007Document10 pagesBeamer by Example: Willie Dewit Jessie May David Griffiths Conference On Tasteful Presentations, 2007Anonymous JB9jZ9TNo ratings yet
- RobiSetiawan - Tugas 4 .IpynbDocument13 pagesRobiSetiawan - Tugas 4 .IpynbROBI SETIAWANNo ratings yet
- Advanced Opensees Algorithms, Volume 1: Probability Analysis Of High Pier Cable-Stayed Bridge Under Multiple-Support Excitations, And LiquefactionFrom EverandAdvanced Opensees Algorithms, Volume 1: Probability Analysis Of High Pier Cable-Stayed Bridge Under Multiple-Support Excitations, And LiquefactionNo ratings yet
- Entrega de Productos Wings Mobile 14-09-2021Document18 pagesEntrega de Productos Wings Mobile 14-09-2021claudiaNo ratings yet
- Indian School of Business (ISB) PGP (Intended Major: Finance) - GMAT: 740Document1 pageIndian School of Business (ISB) PGP (Intended Major: Finance) - GMAT: 740Suprateek BoseNo ratings yet
- sjp810m Manual BookDocument12 pagessjp810m Manual BookMegNo ratings yet
- What Is The Power ElectronicsDocument16 pagesWhat Is The Power ElectronicsashammoudaNo ratings yet
- Gun Rights Groups Sue Over California Carry Permit Requirements - CRPA v. LASD ComplaintDocument41 pagesGun Rights Groups Sue Over California Carry Permit Requirements - CRPA v. LASD ComplaintAmmoLand Shooting Sports NewsNo ratings yet
- AnneCecile RABINE - PortfolioDocument20 pagesAnneCecile RABINE - PortfolioAnne-Cécile RabineNo ratings yet
- MENINGITIS Lesson PlanDocument12 pagesMENINGITIS Lesson PlannidhiNo ratings yet
- Darkness Detector Circuit'Document12 pagesDarkness Detector Circuit'Divya PatilNo ratings yet
- Data Link Protocol PDFDocument24 pagesData Link Protocol PDFAndima Jeff HardyNo ratings yet
- Foundation Lecture (Abdulhafiz)Document4 pagesFoundation Lecture (Abdulhafiz)desigandNo ratings yet
- Jadual Final Exam - 2 Mei 2024Document6 pagesJadual Final Exam - 2 Mei 2024amirularifkbrNo ratings yet
- Practical Work in Geography Ch-6 Gis NewDocument44 pagesPractical Work in Geography Ch-6 Gis NewSooraj ChoukseyNo ratings yet
- Letter of TransmittalDocument7 pagesLetter of TransmittalGolam Samdanee TaneemNo ratings yet
- PEOPLE vs. Lacson, October 7, 2003Document1 pagePEOPLE vs. Lacson, October 7, 2003Thea Thei YaNo ratings yet
- Lenoir, Frederic. - Breve Tratado de Historia de Las Religiones (2018)Document47 pagesLenoir, Frederic. - Breve Tratado de Historia de Las Religiones (2018)Kike EspinozaNo ratings yet
- K Delimitation Error at Plant (New)Document30 pagesK Delimitation Error at Plant (New)ricardo cruzNo ratings yet
- S. No. Title Primary Subject Area Journal Code Impact FactorDocument6 pagesS. No. Title Primary Subject Area Journal Code Impact FactorRohitKumarSahuNo ratings yet
- Masidlak Eagles Form 2Document2 pagesMasidlak Eagles Form 2Rubie Anne SaducosNo ratings yet
- Research MethodologyDocument7 pagesResearch MethodologyJERICO IGNACIONo ratings yet
- Q9. A Proforma Cost Sheet of A Company Provides The Following ParticularsDocument2 pagesQ9. A Proforma Cost Sheet of A Company Provides The Following ParticularsGourav SharmaNo ratings yet
- MT - Aplikasi SPL Pada TrussDocument3 pagesMT - Aplikasi SPL Pada TrussRivan SeptianNo ratings yet
- Combining The ISO 10006 and PMBOK To Ensure Successful ProjectsDocument8 pagesCombining The ISO 10006 and PMBOK To Ensure Successful ProjectsMohamed Abdel-RazekNo ratings yet
- Ytg M 0512 PDFDocument128 pagesYtg M 0512 PDFAndres Felipe TapiaNo ratings yet
- 7.7.1 PROFIBUS FMS With SIMATIC NET Software 05/2000 + SP2Document56 pages7.7.1 PROFIBUS FMS With SIMATIC NET Software 05/2000 + SP2SaasiNo ratings yet
- Cloud Security Training and Awareness Programs For OrganizationsDocument2 pagesCloud Security Training and Awareness Programs For OrganizationsdeeNo ratings yet
- Proxmox Mail Gateway 5.1 Datasheet PDFDocument4 pagesProxmox Mail Gateway 5.1 Datasheet PDFRey TmoNo ratings yet