Download as pdf or txt
You might also like
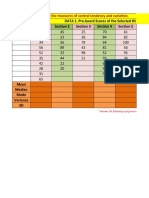
- DATA 1. Pre-Board Scores of The Selected BS Education Students (Per Section) Section 1 Section 2 Section 3 Section 4 Section 5Document10 pagesDATA 1. Pre-Board Scores of The Selected BS Education Students (Per Section) Section 1 Section 2 Section 3 Section 4 Section 5ariane galeno100% (1)
- GigDocument23 pagesGigsmudxxNo ratings yet
- AAEC 6984 / SPRING 2014 Instructor: Klaus MoeltnerDocument9 pagesAAEC 6984 / SPRING 2014 Instructor: Klaus MoeltnerRenato Salazar RiosNo ratings yet
- EM Algorithm: Shu-Ching Chang Hyung Jin Kim December 9, 2007Document10 pagesEM Algorithm: Shu-Ching Chang Hyung Jin Kim December 9, 2007Tomislav PetrušijevićNo ratings yet
- Modelling Meningococcal Disease Using Computer Intensive MethodsDocument10 pagesModelling Meningococcal Disease Using Computer Intensive MethodsRobbiePeckNo ratings yet
- Bispectrum Estimators For Voice Activity Detection and Speech RecognitionDocument12 pagesBispectrum Estimators For Voice Activity Detection and Speech RecognitionSaathiswaran NairNo ratings yet
- Extreme Lp-Quantile Kernel RegressionDocument22 pagesExtreme Lp-Quantile Kernel RegressionАндрей Евгеньевич ЛукьяновNo ratings yet
- Tugas Analisis Data Survival: Kelas BDocument11 pagesTugas Analisis Data Survival: Kelas BTiya OctavianiNo ratings yet
- G.C. Calafiore (Politecnico Di Torino)Document23 pagesG.C. Calafiore (Politecnico Di Torino)Daniel Andres Montoya EspinosaNo ratings yet
- Cra I U Rosenthal Ann RevDocument40 pagesCra I U Rosenthal Ann RevMary GNo ratings yet
- Silvapulle ExistenceMaximumLikelihood 1981Document5 pagesSilvapulle ExistenceMaximumLikelihood 1981jchill2018No ratings yet
- Ps 1Document25 pagesPs 1Khả UyênNo ratings yet
- On The Overestimation of Widely Applicable Bayesian Information CriterionDocument12 pagesOn The Overestimation of Widely Applicable Bayesian Information CriterionGaston GBNo ratings yet
- Risk Backgrounddoc Lqi OptimizationDocument24 pagesRisk Backgrounddoc Lqi OptimizationDimvoulg CivilNo ratings yet
- MNPMDocument15 pagesMNPMJdPrzNo ratings yet
- Bayesian Modelling Tuts-16-18Document3 pagesBayesian Modelling Tuts-16-18ShubhsNo ratings yet
- 2 MS2 (Sampling)Document29 pages2 MS2 (Sampling)hadjiamine93No ratings yet
- Microeconometrie Chapitre2 MultinomialModelsDocument24 pagesMicroeconometrie Chapitre2 MultinomialModelsAstrela MengueNo ratings yet
- 0lecture 18Document104 pages0lecture 18Sandra GilbertNo ratings yet
- Wits ElmajidiDocument11 pagesWits ElmajidielmajidiNo ratings yet
- CET Vol69Document6 pagesCET Vol69minh leNo ratings yet
- Bahan Pelengkap Parametric Dan Semiparametric ModelDocument51 pagesBahan Pelengkap Parametric Dan Semiparametric ModelSteven Wijaksana100% (1)
- HSTS203 Time SeriesDocument22 pagesHSTS203 Time SeriesKeith Tanyaradzwa MushiningaNo ratings yet
- Survival Models ANU Lecture 3Document17 pagesSurvival Models ANU Lecture 3JasonNo ratings yet
- 1.8. Large Deviation and Some Exponential Inequalities.: B R e DX Essinf G (X), T e DX Esssup G (X)Document4 pages1.8. Large Deviation and Some Exponential Inequalities.: B R e DX Essinf G (X), T e DX Esssup G (X)Naveen Kumar SinghNo ratings yet
- IRT Models and Mixed Models: Theory and Lmer Practice: Paul de Boeck Sun-Joo ChoDocument26 pagesIRT Models and Mixed Models: Theory and Lmer Practice: Paul de Boeck Sun-Joo ChoIan CronbachNo ratings yet
- AUZIPREDocument12 pagesAUZIPRENADASHREE BOSE 2248138No ratings yet
- Metrics WT 2023-24 Unit10 Ml+Discrete ChoiceDocument36 pagesMetrics WT 2023-24 Unit10 Ml+Discrete ChoicenoahroosNo ratings yet
- Maquin STA 09Document28 pagesMaquin STA 09p26q8p8xvrNo ratings yet
- Lab6 2023 2024 FallDocument4 pagesLab6 2023 2024 Falldnthrtm3No ratings yet
- Econ 512 Box Jenkins SlidesDocument31 pagesEcon 512 Box Jenkins SlidesMithilesh KumarNo ratings yet
- Examples Comparing Importance Sampling and The MetDocument26 pagesExamples Comparing Importance Sampling and The MetRafalel JupioNo ratings yet
- Improved Estimators of Tail Index and Extreme Quantiles Under Dependence SerialsDocument21 pagesImproved Estimators of Tail Index and Extreme Quantiles Under Dependence SerialsHugo BrangoNo ratings yet
- Short MCMC SupplementaryDocument5 pagesShort MCMC SupplementaryccsunfanNo ratings yet
- LogisticDocument14 pagesLogisticMe ShaadNo ratings yet
- GLM Project 2Document5 pagesGLM Project 2peaceugbedeNo ratings yet
- Learning Curves, Model Selection and Complexity of Neural NetworksDocument9 pagesLearning Curves, Model Selection and Complexity of Neural NetworksluiskNo ratings yet
- CS6785 HW2Document4 pagesCS6785 HW2darklanxNo ratings yet
- 08 Bej137Document39 pages08 Bej137christoumpingfotsoNo ratings yet
- Analysis of Complex Sample Survey Data: Multinomial and Ordinal Logistic Regression For Complex SamplesDocument39 pagesAnalysis of Complex Sample Survey Data: Multinomial and Ordinal Logistic Regression For Complex SamplesCamilo Gutiérrez PatiñoNo ratings yet
- Risks 01 00192Document21 pagesRisks 01 00192Lester SaquerNo ratings yet
- Intervention Analysis For Low Count Time Series With Applications in Public HealthDocument36 pagesIntervention Analysis For Low Count Time Series With Applications in Public HealthmrallmanNo ratings yet
- Gretl Guide (401 450)Document50 pagesGretl Guide (401 450)Taha NajidNo ratings yet
- Basic Statistical ConceptsDocument14 pagesBasic Statistical ConceptsVedha ThangavelNo ratings yet
- 211MAT1302 Unit-4Document11 pages211MAT1302 Unit-4Thor OdinsonNo ratings yet
- CS 229, Summer 2020 Problem Set #1Document14 pagesCS 229, Summer 2020 Problem Set #1nhungNo ratings yet
- 3 Bayesian Deep LearningDocument33 pages3 Bayesian Deep LearningNishanth ManikandanNo ratings yet
- Taller 3 (A. NG.) - Introducción Al Aprendizaje SupervisadoDocument8 pagesTaller 3 (A. NG.) - Introducción Al Aprendizaje SupervisadoangieNo ratings yet
- Threshold TobitDocument15 pagesThreshold TobitPino BacadaNo ratings yet
- Biostats GibbsDocument41 pagesBiostats GibbsjustdlsNo ratings yet
- Solutions Advanced Econometrics 1 Midterm 2013Document3 pagesSolutions Advanced Econometrics 1 Midterm 2013Esmée WinnubstNo ratings yet
- Quasi Maximum Likelihood Theory - Lecture NotesDocument119 pagesQuasi Maximum Likelihood Theory - Lecture NotesAnonymous tsTtieMHDNo ratings yet
- 1-Probabilidades e DistribuicoesDocument38 pages1-Probabilidades e Distribuicoesstr0k33No ratings yet
- SemUVF2013 Olivier 70thDocument35 pagesSemUVF2013 Olivier 70thWado Del CimaNo ratings yet
- 2.MIT18 650F16 Parametric InfDocument12 pages2.MIT18 650F16 Parametric InfbobNo ratings yet
- 7.4 Expectation-Maximization AlgorithmDocument6 pages7.4 Expectation-Maximization AlgorithmHarsh GokhruNo ratings yet
- ProbaDocument23 pagesProbaAbhiraj RanjanNo ratings yet
- SupplementalMaterial ECCV2022Document40 pagesSupplementalMaterial ECCV2022asri roselyNo ratings yet
- Econometrics 07 00017 v2Document23 pagesEconometrics 07 00017 v2Pierre-Cécil KönigNo ratings yet
- Chi square文章2Document72 pagesChi square文章2Haiying MaoNo ratings yet
- Green's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)From EverandGreen's Function Estimates for Lattice Schrödinger Operators and Applications. (AM-158)No ratings yet
- Nonmem Users Guide Introduction To Nonmem 7 Robert J. Bauer ICON Development Solutions Ellicott City, Maryland February 26, 2010Document61 pagesNonmem Users Guide Introduction To Nonmem 7 Robert J. Bauer ICON Development Solutions Ellicott City, Maryland February 26, 2010gshgssgNo ratings yet
- Parametric & Non-Parametric TestsDocument34 pagesParametric & Non-Parametric TestsohlyanaartiNo ratings yet
- Aams1773 Quantitative Studies: This Question Paper Consists of 4 Questions On 11 Printed PagesDocument11 pagesAams1773 Quantitative Studies: This Question Paper Consists of 4 Questions On 11 Printed PagesCRYSTAL NGNo ratings yet
- Nurs 211Document2 pagesNurs 211Julia ThindNo ratings yet
- P. G Department Ofstatistics: Sardar Patel UniversityDocument36 pagesP. G Department Ofstatistics: Sardar Patel UniversitySunny PanditNo ratings yet
- Elementary Statistics A Step by Step Approach 7th Edition Bluman Test BankDocument14 pagesElementary Statistics A Step by Step Approach 7th Edition Bluman Test Bankfelicitycurtis9fhmt7100% (37)
- Math 1280 - Learning Journal Unit 8Document2 pagesMath 1280 - Learning Journal Unit 8habib oyeroNo ratings yet
- Econometrics QuestionsDocument3 pagesEconometrics QuestionstabetsingyannfNo ratings yet
- Variance of Discrete Random Variables Class 5, 18.05 Jeremy Orloff and Jonathan Bloom 1 Learning GoalsDocument7 pagesVariance of Discrete Random Variables Class 5, 18.05 Jeremy Orloff and Jonathan Bloom 1 Learning Goalsanwer fadelNo ratings yet
- Exploratory Data Analysis - Komorowski PDFDocument20 pagesExploratory Data Analysis - Komorowski PDFEdinssonRamosNo ratings yet
- Data Pre Test Post TestDocument4 pagesData Pre Test Post TestELI KUSUMANo ratings yet
- Stat 362 Study GuideDocument88 pagesStat 362 Study GuideMills KofiNo ratings yet
- Which Test Should I Use (Revised)Document1 pageWhich Test Should I Use (Revised)RAISHANo ratings yet
- A Classification of Experimental DesignsDocument15 pagesA Classification of Experimental Designssony21100% (1)
- International SeasDocument135 pagesInternational SeasHʌɩɗɘʀ AɭɩNo ratings yet
- Sas/Stat Software: BenefitsDocument4 pagesSas/Stat Software: BenefitsAyoub TahiriNo ratings yet
- PSM Estimation Confidence IntervalDocument55 pagesPSM Estimation Confidence IntervalNay LinNo ratings yet
- Birla Institute of Technology and Science, Pilani: Pilani Campus AUGS/ AGSR DivisionDocument3 pagesBirla Institute of Technology and Science, Pilani: Pilani Campus AUGS/ AGSR DivisionNOAH GEORGENo ratings yet
- Introduction To Sampling and Sampling Designs: University of BaguioDocument41 pagesIntroduction To Sampling and Sampling Designs: University of BaguioJason Vi LucasNo ratings yet
- Common Technical Definition: QuantificationDocument2 pagesCommon Technical Definition: QuantificationNidaNo ratings yet
- STS 401 e (Ex. 8)Document2 pagesSTS 401 e (Ex. 8)MostafaMimoNo ratings yet
- Bivariate Exponential DistributionDocument11 pagesBivariate Exponential DistributionFeli Mathipi IINo ratings yet
- Unit 05 Propagation of ErrorsDocument14 pagesUnit 05 Propagation of ErrorsMichael MutaleNo ratings yet
- Ec35a5 Simulation of Communication Systems Question PaperDocument2 pagesEc35a5 Simulation of Communication Systems Question Paperanilnv.itdNo ratings yet
- NCERT Solutions For Class 11 Maths Chapter - 15 StatisticsDocument6 pagesNCERT Solutions For Class 11 Maths Chapter - 15 StatisticsMukund YadavNo ratings yet
- Asymptotic Properties of Maximum Likelihood Estimators For The Independent Not Identically Distributed CaseDocument16 pagesAsymptotic Properties of Maximum Likelihood Estimators For The Independent Not Identically Distributed Case林宗霖No ratings yet
- Stochastic Modeling and Mathematical StatisticsDocument21 pagesStochastic Modeling and Mathematical StatisticsALEXANDER PAUL OBLITAS TACONo ratings yet
- DF-GLS vs. Augmented Dickey-Fuller: Elliott, Rothenberg, and Stock 1996Document3 pagesDF-GLS vs. Augmented Dickey-Fuller: Elliott, Rothenberg, and Stock 1996Shahabuddin ProdhanNo ratings yet