Download as pdf or txt
You might also like
- Diagramas Electricos Audi A4 B9 8W - EWD (Desde Julio de 2015)Document1,605 pagesDiagramas Electricos Audi A4 B9 8W - EWD (Desde Julio de 2015)javier borrego0% (1)
- NielsenIQ Webinar E Commerce Success in 2023 and BeyondDocument33 pagesNielsenIQ Webinar E Commerce Success in 2023 and BeyondRohit JangidNo ratings yet
- Shaping The Market OfferingsDocument37 pagesShaping The Market OfferingsSuvendu Pratihari100% (3)
- Family Economic Education Financial Literacy and Financial Inclusion Among University Students in IndonesiaDocument4 pagesFamily Economic Education Financial Literacy and Financial Inclusion Among University Students in IndonesiaLmj75 ntNo ratings yet
- Cheese - Consumption Per Capita Worldwide Country Comparison 2022 - StatistaDocument4 pagesCheese - Consumption Per Capita Worldwide Country Comparison 2022 - Statistasydmm7No ratings yet
- Guillen Book 2030 - Feb 1, 2021Document32 pagesGuillen Book 2030 - Feb 1, 2021Praveen undruNo ratings yet
- Teste de Idade MentalDocument1 pageTeste de Idade MentalsamyazuyNo ratings yet
- Teste de Idade MentalDocument1 pageTeste de Idade Mentaleloah.anogueiraNo ratings yet
- Teste de Idade MentalDocument1 pageTeste de Idade MentalbatatfritaoucozidaNo ratings yet
- Teste de Idade MentalDocument1 pageTeste de Idade MentalamordocebellababNo ratings yet
- Teste de Idade MentalDocument1 pageTeste de Idade MentalniuandsomcardozoNo ratings yet
- I Just Took The Mental Age Test. I Have A Mental Age of 45! Check Yours Now!Document1 pageI Just Took The Mental Age Test. I Have A Mental Age of 45! Check Yours Now!Iammuhammad SyafiqNo ratings yet
- Teste de Idade MentalDocument1 pageTeste de Idade MentalfjmnfqkbwwNo ratings yet
- Teste de Idade MentalDocument1 pageTeste de Idade Mentaldutragabriela177No ratings yet
- I Just Took The Mental Age Test. I Have A MentalDocument1 pageI Just Took The Mental Age Test. I Have A MentalAmir HamzahNo ratings yet
- Teste de Idade Mental 2Document1 pageTeste de Idade Mental 2eloah.anogueiraNo ratings yet
- Teste de Idade MentalDocument1 pageTeste de Idade Mentalcsvr8j6xc4No ratings yet
- Minha Idade Mental É 39Document1 pageMinha Idade Mental É 39Maria ClaraNo ratings yet
- World PopulationDocument1 pageWorld PopulationBryan CambroneroNo ratings yet
- Captura de Tela 2023-04-29 À(s) 00.17.00Document1 pageCaptura de Tela 2023-04-29 À(s) 00.17.00welterisabella388No ratings yet
- Teste de Idade MentalDocument1 pageTeste de Idade Mentaltaylane.lima1No ratings yet
- ProjetoDocument1 pageProjetocleislagriffoNo ratings yet
- 8 7 Clothing LandonDocument2 pages8 7 Clothing Landonapi-377077673No ratings yet
- Teste de Idade MentalDocument1 pageTeste de Idade Mental88b5m4znmfNo ratings yet
- Over Worried: Personality Disorder JournalDocument1 pageOver Worried: Personality Disorder JournalDamia ShafiyyahNo ratings yet
- Demographic Details of Crack Brigade Website November 2021Document1 pageDemographic Details of Crack Brigade Website November 2021Bangali FilmsNo ratings yet
- Analytics All Web Site Data Audience Overview 20220507 20220605Document1 pageAnalytics All Web Site Data Audience Overview 20220507 20220605pamiphone53No ratings yet
- Very Mature: Personality Disorder JournalDocument1 pageVery Mature: Personality Disorder JournalJeff VieiraNo ratings yet
- Repot On SmokingDocument9 pagesRepot On Smokinghamayun03488023063No ratings yet
- Very Mature: Personality Disorder JournalDocument1 pageVery Mature: Personality Disorder JournalCaio LucasNo ratings yet
- India Map and Urbanization RatesDocument1 pageIndia Map and Urbanization Ratesnitin pandeyNo ratings yet
- I Just Took The Mental Age Test. I Have A Mental Age of 27! Check Yours Now!Document1 pageI Just Took The Mental Age Test. I Have A Mental Age of 27! Check Yours Now!Fatin NabilahNo ratings yet
- Top Tweenty Import CountriesDocument2 pagesTop Tweenty Import CountriesFaisal QuaiyyumNo ratings yet
- Case Study 3 Asean 2024Document4 pagesCase Study 3 Asean 2024hestia.hemeraNo ratings yet
- India - This DecadeDocument2 pagesIndia - This DecadeAbdeali NajmiPatanwalaNo ratings yet
- AF3 VIOD IFC-Presentation ENDocument14 pagesAF3 VIOD IFC-Presentation ENThien LeNo ratings yet
- On The Glimpse of Insolvency and Bankruptcy Code, 2016 and Its RegulationsDocument22 pagesOn The Glimpse of Insolvency and Bankruptcy Code, 2016 and Its RegulationsprasannashenoyNo ratings yet
- Overview of Pakistan's EconomyDocument18 pagesOverview of Pakistan's Economyaqil khanNo ratings yet
- Sophisticated: Personal Tarot PredictionsDocument1 pageSophisticated: Personal Tarot PredictionsThao neeeNo ratings yet
- Global Views On Sports and Exercise IpsosDocument26 pagesGlobal Views On Sports and Exercise IpsosLuiz BalioliNo ratings yet
- Julia Macfadyen Lab 8 1Document2 pagesJulia Macfadyen Lab 8 1api-405005664No ratings yet
- Option ScienceDocument1 pageOption ScienceÉmile GervaisNo ratings yet
- Presentacion PAF 2022 EngDocument21 pagesPresentacion PAF 2022 EngDossier RabagoNo ratings yet
- On The Glimpse of Insolvency and Bankruptcy Code, 2016 and Its RegulationsDocument14 pagesOn The Glimpse of Insolvency and Bankruptcy Code, 2016 and Its RegulationsAnonymous LXbdzsgKigNo ratings yet
- Lista 2.1 - AFADocument167 pagesLista 2.1 - AFASlaslasla SlaslaslaNo ratings yet
- Vũ Duy Quân - 21070138 - 3.24, 3.28Document8 pagesVũ Duy Quân - 21070138 - 3.24, 3.28mix quanNo ratings yet
- 8fyp 282-289Document8 pages8fyp 282-289Md. Tariqul IslamNo ratings yet
- Study - Id101447 - Social Media in VietnamDocument74 pagesStudy - Id101447 - Social Media in VietnamNguyễn ChiNo ratings yet
- Study - Id101447 - Social Media in VietnamDocument74 pagesStudy - Id101447 - Social Media in VietnamChiNo ratings yet
- UntitledDocument5 pagesUntitledVilaivun VonglaNo ratings yet
- Next Release: 15 December 2020Document94 pagesNext Release: 15 December 2020DVSVsfNo ratings yet
- Worldwide Reit Regimes Nov 2019Document105 pagesWorldwide Reit Regimes Nov 2019Diego FernandezNo ratings yet
- Big Mac Index Worldwide 2017 - StatistaDocument1 pageBig Mac Index Worldwide 2017 - Statistaismun nadhifahNo ratings yet
- M5-Entrepreneurship-Lectures 21 To 25 FinlDocument76 pagesM5-Entrepreneurship-Lectures 21 To 25 FinlSYED ADNAN ALAMNo ratings yet
- ComScore State of The Internet Australia February 2011Document37 pagesComScore State of The Internet Australia February 2011wiiiiseyNo ratings yet
- Chapter-5 HighlightsDocument4 pagesChapter-5 Highlightskri satNo ratings yet
- 8 5 Clothing Brianna BrostDocument1 page8 5 Clothing Brianna Brostapi-334890970No ratings yet
- Lec - Framwork To Identify Next Emerging Markets KKmVMrIJePDocument5 pagesLec - Framwork To Identify Next Emerging Markets KKmVMrIJePJavedNo ratings yet
- Connectivity Continues To Bring More and More Activities OnlineDocument1 pageConnectivity Continues To Bring More and More Activities OnlineAbu HurairaNo ratings yet
- Teste de Idade MentalDocument1 pageTeste de Idade Mentalvilasboassarah620No ratings yet
- MCGPI 2020 Executive SummaryDocument4 pagesMCGPI 2020 Executive SummaryStratos PourzitakisNo ratings yet
- BZF79D591 ChuangchidDocument9 pagesBZF79D591 Chuangchidwill bNo ratings yet
- FNB Ghana Q3 Unaudited Financial Statements - September 2021 - V2Document2 pagesFNB Ghana Q3 Unaudited Financial Statements - September 2021 - V2Fuaad DodooNo ratings yet
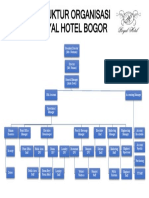
- Struktur Organisasi RHBDocument1 pageStruktur Organisasi RHBiksan rmdnNo ratings yet
- Annex-V Commodity CodeDocument399 pagesAnnex-V Commodity CodemirzanadeembaigNo ratings yet
- Deposit Slip-Examinations SectionDocument2 pagesDeposit Slip-Examinations SectionAhmad TaimurNo ratings yet
- Chapter 1 PreliminariesDocument34 pagesChapter 1 PreliminariesKama QaqNo ratings yet
- Work Measurement: V.Ramesh Babu Asst - ProfDocument22 pagesWork Measurement: V.Ramesh Babu Asst - Profthiruvel75No ratings yet
- HDMANN Project ReferenceDocument50 pagesHDMANN Project Referenceandy limNo ratings yet
- ACK148945220210324Document1 pageACK148945220210324chandasoumik2002No ratings yet
- Aklan State Univeristy School of Management SchoolDocument4 pagesAklan State Univeristy School of Management SchoolKenneth Christian WilburNo ratings yet
- Analisa Struktur Kos Tri SuyaDocument32 pagesAnalisa Struktur Kos Tri SuyafaisalNo ratings yet
- Crochet Pattern DearDocument34 pagesCrochet Pattern DearMaria Bursan100% (1)
- EP-2022-07 Delegation of Powers 1712919888Document16 pagesEP-2022-07 Delegation of Powers 1712919888sukbabNo ratings yet
- EMS 003 Class B (HTHW) - Piping Materials Fabrication and Line ClassesDocument3 pagesEMS 003 Class B (HTHW) - Piping Materials Fabrication and Line ClassesclintNo ratings yet
- Solitaire Pharmacia Pvt. LTD.: Restricted Circulation Authorised Persons OnlyDocument7 pagesSolitaire Pharmacia Pvt. LTD.: Restricted Circulation Authorised Persons OnlyNgoc Sang HuynhNo ratings yet
- Chapter 1 - IntroductionDocument11 pagesChapter 1 - IntroductionChelsea Anne VidalloNo ratings yet
- Club Factory Everything Unbeaten PriceDocument1 pageClub Factory Everything Unbeaten PriceshyamaNo ratings yet
- Topics in Structural VAR EconometricsDocument20 pagesTopics in Structural VAR EconometricsAndres EretzaNo ratings yet
- SapoDocument13 pagesSaporeforcenNo ratings yet
- Cheat Sheet Quantitative Methods in Finance Nova Cheat Sheet Quantitative Methods in Finance NovaDocument3 pagesCheat Sheet Quantitative Methods in Finance Nova Cheat Sheet Quantitative Methods in Finance Novabassirou ndao0% (1)
- Datasheet For Pressure Transmitter - Stg74S: (No. RP19-009)Document4 pagesDatasheet For Pressure Transmitter - Stg74S: (No. RP19-009)Dhananjay BhaldandNo ratings yet
- Kumwell Code No - REVISI.Document1 pageKumwell Code No - REVISI.Ahmad ZulkarnaenNo ratings yet
- Hotelling Model - Vertical Differenciation - ExampleDocument5 pagesHotelling Model - Vertical Differenciation - ExampleibsonsNo ratings yet
- Solution Manual For Economics 4th Edition by Hubbard Obrien ISBN 013281725X 9780132817257Document29 pagesSolution Manual For Economics 4th Edition by Hubbard Obrien ISBN 013281725X 9780132817257joyceNo ratings yet
- SMG Mock Examinations: Uganda Advanced Certificate of EducationDocument3 pagesSMG Mock Examinations: Uganda Advanced Certificate of Education20/21-5B-(05) HoMeiYi/何美誼No ratings yet
- Inequality-Adjusted Human Development IndexDocument4 pagesInequality-Adjusted Human Development IndexVũ Phan Đông PhươngNo ratings yet
- Gipe BGG 1894 11 01 PVDocument61 pagesGipe BGG 1894 11 01 PVAamir MugheriNo ratings yet