Download as pdf or txt
You might also like
- PipelinerunDocument7 pagesPipelinerunDàk ÔùkyNo ratings yet
- Robert D. Blevins - Flow-Induced Vibration (2001, Krieger Pub Co) PDFDocument254 pagesRobert D. Blevins - Flow-Induced Vibration (2001, Krieger Pub Co) PDFDang Dinh DongNo ratings yet
- Lesson Plan in SwotDocument7 pagesLesson Plan in SwotFlorentina Visto100% (2)
- DevOps. How to build pipelines with Jenkins, Docker container, AWS ECS, JDK 11, git and maven 3?From EverandDevOps. How to build pipelines with Jenkins, Docker container, AWS ECS, JDK 11, git and maven 3?No ratings yet
- Yolov 8Document43 pagesYolov 8vikramkarthick2001No ratings yet
- DV5 - Jupyter Notebook PDFDocument4 pagesDV5 - Jupyter Notebook PDFFS20IF015No ratings yet
- Exp 5Document4 pagesExp 5FS20IF015No ratings yet
- Anjali DV5 - Jupyter NotebookDocument4 pagesAnjali DV5 - Jupyter NotebookFS20IF015No ratings yet
- GNN-02-Augmented NotesDocument8 pagesGNN-02-Augmented NotesvitormeriatNo ratings yet
- Install LogDocument32 pagesInstall LogAhmad RabieNo ratings yet
- 1e2RzvrZ 1SueJwXaVHXb0x25yZtvmI0dDocument5 pages1e2RzvrZ 1SueJwXaVHXb0x25yZtvmI0dh58991888No ratings yet
- Donatus Lee Vinsensius - 3TA04Document3 pagesDonatus Lee Vinsensius - 3TA04Sobah AlhaddadNo ratings yet
- Tugas 1 Anstruk Matriks Rivaldo - Ipynb - ColaboratoryDocument4 pagesTugas 1 Anstruk Matriks Rivaldo - Ipynb - ColaboratoryBimo Ran SaputraNo ratings yet
- Clonamos El Repositorio para Obtener Los Dataset: From ImportDocument23 pagesClonamos El Repositorio para Obtener Los Dataset: From ImportJuan Chavarria AsparrinNo ratings yet
- 3TA04 - Tekrek - M5 - Tree - (1) .Ipynb - ColaboratoryDocument2 pages3TA04 - Tekrek - M5 - Tree - (1) .Ipynb - ColaboratorySobah AlhaddadNo ratings yet
- C1M6L2 Final Project V3Document7 pagesC1M6L2 Final Project V3sahil palNo ratings yet
- InvokeDocument11 pagesInvokeimmiNo ratings yet
- Komputasi Big Data - Pertemuan 7Document7 pagesKomputasi Big Data - Pertemuan 73IA10 Ade Prayoga NugrahaNo ratings yet
- Getting Started With ChromaDB - Lowest Learning Curve Vector Database & Semantic SearchDocument11 pagesGetting Started With ChromaDB - Lowest Learning Curve Vector Database & Semantic SearchalextllamNo ratings yet
- The GPT-4o API Is Finally Available!Document8 pagesThe GPT-4o API Is Finally Available!Kaushik BanerjeeNo ratings yet
- Getting Started With GPT-4 API: May 14,2024 Update To From gpt-4 To Gpt-4oDocument8 pagesGetting Started With GPT-4 API: May 14,2024 Update To From gpt-4 To Gpt-4oGobiNo ratings yet
- Cento 7Document23 pagesCento 7francisco lozadaNo ratings yet
- Benchmarking Runs On CDH5.4 - Detailed ReportDocument9 pagesBenchmarking Runs On CDH5.4 - Detailed ReportheshyNo ratings yet
- Capture D'écran . 2023-05-15 À 16.45.57Document1 pageCapture D'écran . 2023-05-15 À 16.45.57VOTIO TSAYO GUIOVANY JORDYNo ratings yet
- Mini Projects 3-6-Satyaki MitraDocument60 pagesMini Projects 3-6-Satyaki MitraSatyaki MitraNo ratings yet
- PCSC Raspberry PHPDocument8 pagesPCSC Raspberry PHPnier pasambaNo ratings yet
- AsibkaDocument3 pagesAsibkaarseniysmaznov8No ratings yet
- 3.1.12 Lab - Explore Python Development ToolsDocument5 pages3.1.12 Lab - Explore Python Development ToolsVadinhoNo ratings yet
- Configuring Django Enviroment On Server Debian JessieDocument5 pagesConfiguring Django Enviroment On Server Debian JessieEghNo ratings yet
- Yum RepoDocument7 pagesYum Repo19youngyaNo ratings yet
- Docker Version 19.03.6 Installation Failed. Manual Intervention NeededDocument41 pagesDocker Version 19.03.6 Installation Failed. Manual Intervention Neededaslam_326580186No ratings yet
- Google Code Archive - Long-Term Storage For Google Code Project HostingDocument33 pagesGoogle Code Archive - Long-Term Storage For Google Code Project HostingOsmanNo ratings yet
- EC2 Instance CreationDocument8 pagesEC2 Instance CreationSathish PalanisamyNo ratings yet
- Tensorflow Installation ErrorsDocument23 pagesTensorflow Installation ErrorsbhagirathlNo ratings yet
- Python Library - SpidevDocument6 pagesPython Library - Spidevronald decimus MAD-BONDONo ratings yet
- Python Part 2 Working With Libraries and Virtual Environments PDFDocument28 pagesPython Part 2 Working With Libraries and Virtual Environments PDFmohamedNo ratings yet
- English To Hindi Text TranslationDocument10 pagesEnglish To Hindi Text TranslationcihbhcghhjNo ratings yet
- Comfyui-Upscaling Kaggle - IpynbDocument10 pagesComfyui-Upscaling Kaggle - IpynbeternalsoldiergirlNo ratings yet
- M6 Wayan Agus Budiyanto 17518838Document5 pagesM6 Wayan Agus Budiyanto 175188388wayanNo ratings yet
- Docker StepsDocument16 pagesDocker Stepsraja rajanNo ratings yet
- Instructions To ExecuteDocument108 pagesInstructions To ExecuteKabir MohammedNo ratings yet
- Roop Unleashed 02.ipynbDocument15 pagesRoop Unleashed 02.ipynbeternalsoldiergirlNo ratings yet
- BuildDocument5 pagesBuildJose ToledoNo ratings yet
- Own CloudDocument38 pagesOwn Cloud19youngyaNo ratings yet
- Music Information Retrival WorkDocument25 pagesMusic Information Retrival WorkNitin BhongadeNo ratings yet
- Skrip Install WRFDocument116 pagesSkrip Install WRFHiralal KhatriNo ratings yet
- Package Purpose: Pytroll Scikit Learn ScipyDocument50 pagesPackage Purpose: Pytroll Scikit Learn ScipyOscard KanaNo ratings yet
- Hyperledger Fabric InstallationDocument11 pagesHyperledger Fabric Installationanilmm2006No ratings yet
- Image Detection With Lazarus: Maxbox Starter87 With CaiDocument22 pagesImage Detection With Lazarus: Maxbox Starter87 With CaiMax Kleiner100% (1)
- Laboratorio 07 Conexion RemotaDocument6 pagesLaboratorio 07 Conexion RemotaAnonimo 2911-2No ratings yet
- Docker Class2 PractiseDocument17 pagesDocker Class2 PractiseAman KumarNo ratings yet
- 3) - NasdagDocument4 pages3) - Nasdagdiegogachet1618No ratings yet
- Librerias PythonDocument3 pagesLibrerias PythonJuan VegaNo ratings yet
- Mosquitto Ec2 Ubuntu SetupDocument4 pagesMosquitto Ec2 Ubuntu Setupranjan biswasNo ratings yet
- Docker Installation On Ubuntu OSDocument5 pagesDocker Installation On Ubuntu OSJivan MundeNo ratings yet
- How To Install Sigil Ebook Editor On UbuntuDocument3 pagesHow To Install Sigil Ebook Editor On Ubuntujcpinzon4905No ratings yet
- Como Instalar Certbot en Oracle-Linux 8Document9 pagesComo Instalar Certbot en Oracle-Linux 8Rodrigo BravoNo ratings yet
- How To Install DockerDocument5 pagesHow To Install DockerfaeemNo ratings yet
- TensorFlow Developer Certificate Exam Practice Tests 2024 Made EasyFrom EverandTensorFlow Developer Certificate Exam Practice Tests 2024 Made EasyNo ratings yet
- Buku Keamanan InformasiDocument156 pagesBuku Keamanan InformasiBadruzZamanNo ratings yet
- General Physics Lesson 1 Methods of Electrostatic ChargingDocument46 pagesGeneral Physics Lesson 1 Methods of Electrostatic ChargingLeoj Levamor D. AgumbayNo ratings yet
- Quickstart Guide: EnglishDocument10 pagesQuickstart Guide: EnglishAnnekiNo ratings yet
- Kaeser - Service TechnicianDocument3 pagesKaeser - Service TechnicianpunujcNo ratings yet
- Forces and Motion Using Part 2 - FrictionDocument3 pagesForces and Motion Using Part 2 - FrictionEDuardo MaflaNo ratings yet
- Logo VariationsDocument7 pagesLogo Variationsks438406No ratings yet
- Ainscow, Farrell y Tweddle IJIE - 00 Developing Policies For Inclusive EducationDocument19 pagesAinscow, Farrell y Tweddle IJIE - 00 Developing Policies For Inclusive EducationMatías Reviriego RomeroNo ratings yet
- Bus Body Construction and RegulationsDocument6 pagesBus Body Construction and RegulationsAghil Buddy100% (1)
- E38 DSC System PDFDocument32 pagesE38 DSC System PDFjoker63000No ratings yet
- Creating Barcodes in OfficeDocument24 pagesCreating Barcodes in OfficeMaxi Rambi RuntuweneNo ratings yet
- Reference Manual: Power Factor Regulator BLR-CX-R / BLR-CX-TDocument40 pagesReference Manual: Power Factor Regulator BLR-CX-R / BLR-CX-Tbaharuddin amnurNo ratings yet
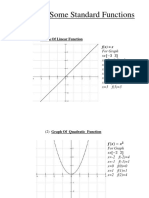
- Lecture 2 Graphs of Some Standard Functions, Shifting of GraphsDocument12 pagesLecture 2 Graphs of Some Standard Functions, Shifting of Graphsghazi membersNo ratings yet
- Flat Sheets and FacadesDocument41 pagesFlat Sheets and FacadesSarisha HarrychundNo ratings yet
- A Description of Dzә (Jenjo) Nouns and Noun PhrasesDocument15 pagesA Description of Dzә (Jenjo) Nouns and Noun PhrasesSamuel EkpoNo ratings yet
- Guide Card: Casa Del Niño Montessori School Guinatan, City of Ilagan, IsabelaDocument5 pagesGuide Card: Casa Del Niño Montessori School Guinatan, City of Ilagan, IsabelaManAsseh EustaceNo ratings yet
- David J. A. Clines The Theme of The Pentateuch Jsot Supplement Series, 10 1997 PDFDocument177 pagesDavid J. A. Clines The Theme of The Pentateuch Jsot Supplement Series, 10 1997 PDFVeteris Testamenti Lector100% (14)
- 3.remaining Life Prediction of Lithium Ion Batteries Base - 2023 - Journal of EnerDocument17 pages3.remaining Life Prediction of Lithium Ion Batteries Base - 2023 - Journal of Enertimilsina.biratNo ratings yet
- 2012 KCSE Physics Paper 3Document5 pages2012 KCSE Physics Paper 3lixus mwangiNo ratings yet
- Overview of The Real Estate Industry - Evolution and Trends - SAP Flexible Real Estate Management - InglesDocument5 pagesOverview of The Real Estate Industry - Evolution and Trends - SAP Flexible Real Estate Management - InglesAdriano MesadriNo ratings yet
- Ford Focus Mk3 SpecifikacijeDocument14 pagesFord Focus Mk3 Specifikacijemisterno27No ratings yet
- DESTINATIONS 1 WebDocument38 pagesDESTINATIONS 1 WebRodrigo MartinezNo ratings yet
- Roboti (E) 42Document8 pagesRoboti (E) 42pc100xohmNo ratings yet
- Ficha Tecnica Inverter Mini SplitDocument1 pageFicha Tecnica Inverter Mini SplitpabloabelgilsotoNo ratings yet
- Cocubes Coding Assignment 2Document4 pagesCocubes Coding Assignment 2Amanpreet DuttaNo ratings yet
- CATIA V5 Design With Analysis: (Tutorial 3 - Deep Fry Basket)Document136 pagesCATIA V5 Design With Analysis: (Tutorial 3 - Deep Fry Basket)Oscar Al KantNo ratings yet
- Chapter 8 Thermal LoadsDocument2 pagesChapter 8 Thermal LoadsCarlo DizonNo ratings yet
- Petroleum Geomechanics Assignment 3Document6 pagesPetroleum Geomechanics Assignment 3Binish KhanNo ratings yet
- Analysis of Urban Heat Island IntensityDocument14 pagesAnalysis of Urban Heat Island IntensityItishree RanaNo ratings yet