Download as docx, pdf, or txt
You might also like
- Financial Statement Analysis of TATA Steel Ltd. of 5 YearsDocument61 pagesFinancial Statement Analysis of TATA Steel Ltd. of 5 Yearsjarvis706704100% (1)
- The Clear Skin Diet by Nina Nelson PDFDocument370 pagesThe Clear Skin Diet by Nina Nelson PDFmia agustina60% (10)
- Hw6 SolutionDocument10 pagesHw6 SolutionMua Lanh100% (1)
- STATS GP1 Assessment2Document24 pagesSTATS GP1 Assessment2NUR AININ SOFIYA OMARNo ratings yet
- SAT Level 2 Practice Test 03Document13 pagesSAT Level 2 Practice Test 03Leonardo FlorenziNo ratings yet
- Bodyweight Sports TrainingDocument56 pagesBodyweight Sports TrainingJoshp3c100% (18)
- Panel Data Analysis Using EViews Chapter - 1 PDFDocument30 pagesPanel Data Analysis Using EViews Chapter - 1 PDFimohamed2No ratings yet
- Inferences For Two Population Standard DeviationsDocument19 pagesInferences For Two Population Standard DeviationsParul MittalNo ratings yet
- Mini CoopDocument324 pagesMini Coopisaisabella.krausNo ratings yet
- Pract 11Document7 pagesPract 11manojNo ratings yet
- Panel Data Analysis Using EViews Chapter - 2 PDFDocument51 pagesPanel Data Analysis Using EViews Chapter - 2 PDFimohamed2No ratings yet
- Ex-01 - Ex-02Document16 pagesEx-01 - Ex-02Navin RaiNo ratings yet
- Introduction To Multiple Regression: Dale E. Berger Claremont Graduate UniversityDocument14 pagesIntroduction To Multiple Regression: Dale E. Berger Claremont Graduate UniversityAhmad Ramadan IqbalNo ratings yet
- Economics (Field of Study Code Ecom (216) ) ADocument31 pagesEconomics (Field of Study Code Ecom (216) ) ANaresh SehdevNo ratings yet
- GE 1 Statistics 2021 CUDocument2 pagesGE 1 Statistics 2021 CUBhaswar ChakrabortyNo ratings yet
- 549 CHPT 2Document166 pages549 CHPT 2Jihan KannaneNo ratings yet
- JNU MA ECO PYQ 2014-21 by NviNomicsDocument147 pagesJNU MA ECO PYQ 2014-21 by NviNomicsniharikayadav1102No ratings yet
- Test ReliabilityDocument41 pagesTest ReliabilityMacky Dacillo100% (1)
- Study of Some Improved Ratio Type Estimators Under Second Order ApproximationDocument18 pagesStudy of Some Improved Ratio Type Estimators Under Second Order ApproximationScience DirectNo ratings yet
- Half Life Tsay NotesDocument25 pagesHalf Life Tsay NotesjezNo ratings yet
- FInalDocument33 pagesFInalShubham JadhavNo ratings yet
- Multipple RegressionDocument17 pagesMultipple RegressionAngger Subagus UtamaNo ratings yet
- A M M e S B S: C e F P R PLSDocument15 pagesA M M e S B S: C e F P R PLSBengt HörbergNo ratings yet
- AIEEE2011 PaperDocument11 pagesAIEEE2011 PaperRavi LorventNo ratings yet
- Formula SheetDocument2 pagesFormula SheetasjadbashirNo ratings yet
- Latent Variable Interactions - Standardization of Random VariablesDocument13 pagesLatent Variable Interactions - Standardization of Random VariablesAntonio Pineda DominguezNo ratings yet
- Amc12 2011Document9 pagesAmc12 2011vq9jhz82gbNo ratings yet
- Vibration: Fundamentals and PracticeDocument8 pagesVibration: Fundamentals and PracticeMuket AgmasNo ratings yet
- 1st Semester Exams - Discrete Structures - April 2019 - DITDocument6 pages1st Semester Exams - Discrete Structures - April 2019 - DITspencerbokor07No ratings yet
- Text - On - Class EconometricsDocument17 pagesText - On - Class EconometricsBao Ngoc PhungNo ratings yet
- 14.1 Notes 2011Document20 pages14.1 Notes 2011elssiechrissNo ratings yet
- Tablas y Formulas Triola 9 EdDocument8 pagesTablas y Formulas Triola 9 EdJhonny Romero RaveloNo ratings yet
- On The Total Edge Irregularity Strength of Generalized Butterfly GraphDocument6 pagesOn The Total Edge Irregularity Strength of Generalized Butterfly GraphAfwan AhsabNo ratings yet
- Test Bank Questions Chapter 4 - Ed4 - PADocument2 pagesTest Bank Questions Chapter 4 - Ed4 - PAHòa NguyễnNo ratings yet
- Lecture 8+9 Multicollinearity and Heteroskedasticity Exercise 10.2Document3 pagesLecture 8+9 Multicollinearity and Heteroskedasticity Exercise 10.2Amelia TranNo ratings yet
- 1 Onyeka s189 200Document12 pages1 Onyeka s189 200nida pervaizNo ratings yet
- 2023 JEE Main-1 - 30 March 2021 PDFDocument11 pages2023 JEE Main-1 - 30 March 2021 PDFSERIAL HUBNo ratings yet
- GATE 2022 General Aptitude (GA)Document42 pagesGATE 2022 General Aptitude (GA)Abhigyan MitraNo ratings yet
- 2022 2021 MergedDocument67 pages2022 2021 MergedAk TNo ratings yet
- Multiple Choice Questions 64 PointsDocument16 pagesMultiple Choice Questions 64 PointsSurat SatsangiNo ratings yet
- 2x2 Contingency Tables: Handy Reference Sheet - Hrp/Stats 261, Discrete DataDocument6 pages2x2 Contingency Tables: Handy Reference Sheet - Hrp/Stats 261, Discrete DataKristine How Sta CruzNo ratings yet
- Activity No.7 - Chi Square and Binomial Probability-LEPASANADocument4 pagesActivity No.7 - Chi Square and Binomial Probability-LEPASANAMichael Clyde lepasana100% (2)
- Lab 5 CointegrationDocument4 pagesLab 5 CointegrationRay HeNo ratings yet
- State Equations & Mixed Domain SystemsDocument18 pagesState Equations & Mixed Domain Systemsshoaibsaleem001No ratings yet
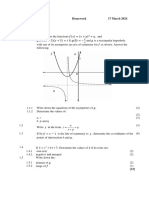
- Functions & Graphs - Homework March 2024Document5 pagesFunctions & Graphs - Homework March 2024davidmajutla87No ratings yet
- Solutions To Final1Document12 pagesSolutions To Final1Joe BloeNo ratings yet
- 2019 Moderation SEM AsparouhovDocument46 pages2019 Moderation SEM AsparouhovUsman BaigNo ratings yet
- Geometry Reference Sheet: Linear QuadraticDocument16 pagesGeometry Reference Sheet: Linear QuadraticLizbeth Velasco TorresNo ratings yet
- PHYS-30021J-ElectronsInCrystals-Exam-2012-2013-Jan-final 2Document5 pagesPHYS-30021J-ElectronsInCrystals-Exam-2012-2013-Jan-final 2jrigg055No ratings yet
- UntitledDocument7 pagesUntitledMaan Karate KamalNo ratings yet
- MathsDocument30 pagesMathsNethmi PabasaraNo ratings yet
- SM Cie 2Document2 pagesSM Cie 2vaishaliNo ratings yet
- Iecep Math 5Document5 pagesIecep Math 5Julio Gabriel AseronNo ratings yet
- Iit 2008Document34 pagesIit 2008skbothNo ratings yet
- Weekend Workshop I: Proc MixedDocument23 pagesWeekend Workshop I: Proc MixedptscribNo ratings yet
- GATE 2022 General Aptitude (GA)Document52 pagesGATE 2022 General Aptitude (GA)Buchupalli Vimala ReddyNo ratings yet
- GATE 2022 General Aptitude (GA)Document52 pagesGATE 2022 General Aptitude (GA)Sinkjoint LeeNo ratings yet
- Factorial ExperimentsDocument42 pagesFactorial ExperimentsFantahunNo ratings yet
- Functions and SequenceDocument13 pagesFunctions and SequenceVanshika WadhwaniNo ratings yet
- The Biostatistics of Aging: From Gompertzian Mortality to an Index of Aging-RelatednessFrom EverandThe Biostatistics of Aging: From Gompertzian Mortality to an Index of Aging-RelatednessNo ratings yet
- Experimentation, Validation, and Uncertainty Analysis for EngineersFrom EverandExperimentation, Validation, and Uncertainty Analysis for EngineersNo ratings yet
- Analytic Geometry: Graphic Solutions Using Matlab LanguageFrom EverandAnalytic Geometry: Graphic Solutions Using Matlab LanguageNo ratings yet
- Accounting For Spoilage, Defective Units and Scrap: 1. TerminologyDocument13 pagesAccounting For Spoilage, Defective Units and Scrap: 1. TerminologyWegene Benti UmaNo ratings yet
- Cambridge IGCSE: Information and Communication Technology 0417/03Document8 pagesCambridge IGCSE: Information and Communication Technology 0417/03EffNo ratings yet
- As An Employee of The Foreign Exchange Department For A LargeDocument1 pageAs An Employee of The Foreign Exchange Department For A Largetrilocksp SinghNo ratings yet
- EA and HalachaDocument63 pagesEA and HalachaAvraham EisenbergNo ratings yet
- Integrated Management of Childhood Illness (IMCI)Document10 pagesIntegrated Management of Childhood Illness (IMCI)Najia Sajjad KhanNo ratings yet
- Job Advert - Programme Officer - Land Rights & Land GovernanceDocument2 pagesJob Advert - Programme Officer - Land Rights & Land GovernanceK'odieny HillaryNo ratings yet
- Discourse Society - The Ideological Construction of Solidarity in Translation ComentariesDocument31 pagesDiscourse Society - The Ideological Construction of Solidarity in Translation ComentariesThiago OliveiraNo ratings yet
- Colour Magazine - London 1Document103 pagesColour Magazine - London 1iccang arsenal100% (1)
- Handout Bonjour PDFDocument2 pagesHandout Bonjour PDFdart_2000No ratings yet
- Venice, A History Built On RuinsDocument18 pagesVenice, A History Built On RuinsHeavensThunderHammerNo ratings yet
- Clean and Unclean Among Jews Christians Brahmins of Kerala: Pollution IdeaDocument13 pagesClean and Unclean Among Jews Christians Brahmins of Kerala: Pollution IdeaGeorge MenacheryNo ratings yet
- 96Document1 page96hiteshsachaniNo ratings yet
- Static RelaysDocument24 pagesStatic RelaysifaNo ratings yet
- Business Law ModuleDocument177 pagesBusiness Law ModulePatricia Jiti100% (1)
- Asbasjsm College of Pharmacy BelaDocument23 pagesAsbasjsm College of Pharmacy Belaimrujlaskar111No ratings yet
- P1-E (7-09) - Personnel InductionDocument4 pagesP1-E (7-09) - Personnel InductionDhotNo ratings yet
- Chapter 4 Referenes Arranged AlphabeticalDocument5 pagesChapter 4 Referenes Arranged AlphabeticalJoselito GelarioNo ratings yet
- LAB 2 EmbeddedDocument21 pagesLAB 2 EmbeddedLeonelNo ratings yet
- Definition of Science FictionDocument21 pagesDefinition of Science FictionIrene ShatekNo ratings yet
- Accy 211 - Week 8 Tut HWDocument2 pagesAccy 211 - Week 8 Tut HWIsaac ElhageNo ratings yet
- Love Marriage or Arranged Marriage Choice Rights and Empowerment For Educated Muslim Women From Rural and Low Income Pakistani Communities PDFDocument18 pagesLove Marriage or Arranged Marriage Choice Rights and Empowerment For Educated Muslim Women From Rural and Low Income Pakistani Communities PDFminaNo ratings yet
- Fortinet OT - PublishedDocument59 pagesFortinet OT - PublishedCryptonesia IndonesiaNo ratings yet
- Fiora Ravenheart: Human Neutral GoodDocument3 pagesFiora Ravenheart: Human Neutral GoodNagadowNo ratings yet
- HUAWEI HiSecEngine USG6500E Series Firewalls (Fixed-Configuration) DatasheetDocument9 pagesHUAWEI HiSecEngine USG6500E Series Firewalls (Fixed-Configuration) DatasheethugobiarNo ratings yet
- Achievement+sheet Ver+01Document1 pageAchievement+sheet Ver+01pl4yerr1No ratings yet
- Visual Music EbookDocument30 pagesVisual Music EbookAlessandro RatociNo ratings yet