
MOD-3 Dap
MOD-3 Dap
You might also like
- Pandas What Can Pandas Do For You ?: Statsmodels SM Seaborn SnsDocument9 pagesPandas What Can Pandas Do For You ?: Statsmodels SM Seaborn SnsNohaM.No ratings yet
- Importing Files Through PandasDocument16 pagesImporting Files Through Pandasfatimamaryam882No ratings yet
- Exp1 - Manipulating Datasets Using PandasDocument15 pagesExp1 - Manipulating Datasets Using PandasmnbatrawiNo ratings yet
- Csc-322a (Week 11) Lab No 10Document25 pagesCsc-322a (Week 11) Lab No 10Osama AshrafNo ratings yet
- CHP 8 PandasDocument49 pagesCHP 8 PandasHeshalini Raja GopalNo ratings yet
- PandasDocument29 pagesPandasVineet SaraswatNo ratings yet
- PandasDocument41 pagesPandasGabriel ChakhvashviliNo ratings yet
- Python LibrariesDocument27 pagesPython LibrariesNaitik JainNo ratings yet
- PandasDocument16 pagesPandasHoneyNo ratings yet
- Unit-2 BdaDocument11 pagesUnit-2 Bdaclaritysubhash55No ratings yet
- Pandas Dataframe Export The CSV FileDocument9 pagesPandas Dataframe Export The CSV Fileammouna bengNo ratings yet
- Pandas BasicsDocument21 pagesPandas BasicsDhruv BhardwajNo ratings yet
- Exercise and Experiment 3Document14 pagesExercise and Experiment 3h8792670No ratings yet
- Introduction To Pandas - Ipynb - ColaboratoryDocument7 pagesIntroduction To Pandas - Ipynb - ColaboratoryVincent GiangNo ratings yet
- Learn Python Pandas For Data Science Quick TutorialExamples For All Primary Operations of DataFramesDocument37 pagesLearn Python Pandas For Data Science Quick TutorialExamples For All Primary Operations of DataFramesJuanito AlimañaNo ratings yet
- Pandas: ImportDocument13 pagesPandas: Importhello100% (1)
- Lab3 - Python - Pandas DataFrame - GeeksforGeeksDocument20 pagesLab3 - Python - Pandas DataFrame - GeeksforGeekssa00059No ratings yet
- Data Analysis With Pandas - Introduction To Pandas Cheatsheet - Codecademy PDFDocument3 pagesData Analysis With Pandas - Introduction To Pandas Cheatsheet - Codecademy PDFTawsif Hasan100% (1)
- Data Analysis With Pandas - Introduction To Pandas Cheatsheet - Codecademy PDFDocument3 pagesData Analysis With Pandas - Introduction To Pandas Cheatsheet - Codecademy PDFTawsif HasanNo ratings yet
- Data Analysis With Pandas - Introduction To Pandas Cheatsheet - Codecademy PDFDocument3 pagesData Analysis With Pandas - Introduction To Pandas Cheatsheet - Codecademy PDFTawsif HasanNo ratings yet
- Intro To PandasDocument7 pagesIntro To PandasThe path to AllahNo ratings yet
- Python For DS Cheat SheetDocument6 pagesPython For DS Cheat SheetSebastián Emdef100% (2)
- Unit 4Document36 pagesUnit 4anurajyellurkar29No ratings yet
- PandasDocument4 pagesPandassumitpython.41No ratings yet
- Machine LearningDocument20 pagesMachine LearningSu EpimoodNo ratings yet
- DA0101EN-Review-Introduction - Jupyter NotebookDocument8 pagesDA0101EN-Review-Introduction - Jupyter NotebookSohail DoulahNo ratings yet
- All Document Reader 1715619870900Document6 pagesAll Document Reader 1715619870900Veer BahadurNo ratings yet
- Aman Ai Primers Pandas PDFDocument130 pagesAman Ai Primers Pandas PDFS MahapatraNo ratings yet
- Chapter 4 - Import-Export DataDocument30 pagesChapter 4 - Import-Export DataAnjanaNo ratings yet
- 1 Pandas BasicsDocument13 pages1 Pandas BasicsBikuNo ratings yet
- Pip3 Install JupyterDocument16 pagesPip3 Install Jupyterblah blNo ratings yet
- Python LibrariesDocument53 pagesPython Libraries0321-1741No ratings yet
- Comprehensive Guide Data Exploration Sas Using Python Numpy Scipy Matplotlib PandasDocument12 pagesComprehensive Guide Data Exploration Sas Using Python Numpy Scipy Matplotlib PandasAhsan Ahmad Beg100% (1)
- PJT Explanation of Code Line by LineDocument2 pagesPJT Explanation of Code Line by LineShruthika S 21BLC1498No ratings yet
- Data Manipulation With Pandas - Introduction To Pandas Reference Guide - CodecademyDocument3 pagesData Manipulation With Pandas - Introduction To Pandas Reference Guide - CodecademyYash PurandareNo ratings yet
- CO-367 Machine Learning Lab File: Submitted To: Submitted byDocument12 pagesCO-367 Machine Learning Lab File: Submitted To: Submitted byShubham AnandNo ratings yet
- Pandas LibraryDocument5 pagesPandas LibrarynoneNo ratings yet
- On Data Handling Using Pandas-IDocument64 pagesOn Data Handling Using Pandas-IRayansh Chauhan100% (2)
- On Data Handling Using Pandas-IDocument63 pagesOn Data Handling Using Pandas-Ianagha100% (2)
- Chapter 10 Python PandasDocument40 pagesChapter 10 Python PandasHarshit DayalNo ratings yet
- Class Notes: Class: XII Date: 7-Apr-2020 Subject: Informatics Practices Topic: 2. Python PandasDocument4 pagesClass Notes: Class: XII Date: 7-Apr-2020 Subject: Informatics Practices Topic: 2. Python PandasRavi RamrakhaniNo ratings yet
- 20 Pandas Functions For 80% of Your Data ScienceDocument22 pages20 Pandas Functions For 80% of Your Data ScienceHARRYNo ratings yet
- Unit - V Introduction To Pandas in PythonDocument21 pagesUnit - V Introduction To Pandas in PythonLindsey WhiteNo ratings yet
- Python PandasDocument230 pagesPython PandasArun NarasimhanNo ratings yet
- Exp7 11 Data ScienceDocument23 pagesExp7 11 Data ScienceNikhil Ranjan 211No ratings yet
- Python Pandas Interview QuestionsDocument17 pagesPython Pandas Interview Questionshasnain qureshi100% (1)
- Fds MannualDocument39 pagesFds MannualsudhaNo ratings yet
- Unit 4 PandasDocument8 pagesUnit 4 PandasPriya S BNo ratings yet
- Freda Song Drechsler - Maneuvering WRDS DataDocument8 pagesFreda Song Drechsler - Maneuvering WRDS DataRicardoHenriquezNo ratings yet
- Mastering Pandas - Important Pandas Functions For Your Next ProjectDocument5 pagesMastering Pandas - Important Pandas Functions For Your Next Projectdchandra15No ratings yet
- ML FileDocument12 pagesML Filehdofficial2003No ratings yet
- Pandas Module (Part-I)Document36 pagesPandas Module (Part-I)Aditya ChauhanNo ratings yet
- Data AnalysisDocument4 pagesData AnalysisSereti CodeproNo ratings yet
- Assingment-3 NLPDocument5 pagesAssingment-3 NLPmukesh shahNo ratings yet
- Eda Unit 2Document65 pagesEda Unit 260 Vibha Shree.SNo ratings yet
- Python Pandas-Series-newwDocument80 pagesPython Pandas-Series-newwp100% (1)
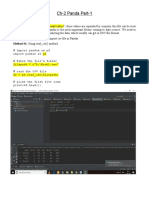
- Ch-2 - Panda - Part-1 - 3rd - DayDocument5 pagesCh-2 - Panda - Part-1 - 3rd - DayRC SharmaNo ratings yet
- Numpy&pandasDocument17 pagesNumpy&pandasSaif Ali KhanNo ratings yet
- Python: Advanced Guide to Programming Code with Python: Python Computer Programming, #4From EverandPython: Advanced Guide to Programming Code with Python: Python Computer Programming, #4No ratings yet



























































Download as pdf or txt
You might also like
- Pandas What Can Pandas Do For You ?: Statsmodels SM Seaborn SnsDocument9 pagesPandas What Can Pandas Do For You ?: Statsmodels SM Seaborn SnsNohaM.No ratings yet
- Importing Files Through PandasDocument16 pagesImporting Files Through Pandasfatimamaryam882No ratings yet
- Exp1 - Manipulating Datasets Using PandasDocument15 pagesExp1 - Manipulating Datasets Using PandasmnbatrawiNo ratings yet
- Csc-322a (Week 11) Lab No 10Document25 pagesCsc-322a (Week 11) Lab No 10Osama AshrafNo ratings yet
- CHP 8 PandasDocument49 pagesCHP 8 PandasHeshalini Raja GopalNo ratings yet
- PandasDocument29 pagesPandasVineet SaraswatNo ratings yet
- PandasDocument41 pagesPandasGabriel ChakhvashviliNo ratings yet
- Python LibrariesDocument27 pagesPython LibrariesNaitik JainNo ratings yet
- PandasDocument16 pagesPandasHoneyNo ratings yet
- Unit-2 BdaDocument11 pagesUnit-2 Bdaclaritysubhash55No ratings yet
- Pandas Dataframe Export The CSV FileDocument9 pagesPandas Dataframe Export The CSV Fileammouna bengNo ratings yet
- Pandas BasicsDocument21 pagesPandas BasicsDhruv BhardwajNo ratings yet
- Exercise and Experiment 3Document14 pagesExercise and Experiment 3h8792670No ratings yet
- Introduction To Pandas - Ipynb - ColaboratoryDocument7 pagesIntroduction To Pandas - Ipynb - ColaboratoryVincent GiangNo ratings yet
- Learn Python Pandas For Data Science Quick TutorialExamples For All Primary Operations of DataFramesDocument37 pagesLearn Python Pandas For Data Science Quick TutorialExamples For All Primary Operations of DataFramesJuanito AlimañaNo ratings yet
- Pandas: ImportDocument13 pagesPandas: Importhello100% (1)
- Lab3 - Python - Pandas DataFrame - GeeksforGeeksDocument20 pagesLab3 - Python - Pandas DataFrame - GeeksforGeekssa00059No ratings yet
- Data Analysis With Pandas - Introduction To Pandas Cheatsheet - Codecademy PDFDocument3 pagesData Analysis With Pandas - Introduction To Pandas Cheatsheet - Codecademy PDFTawsif Hasan100% (1)
- Data Analysis With Pandas - Introduction To Pandas Cheatsheet - Codecademy PDFDocument3 pagesData Analysis With Pandas - Introduction To Pandas Cheatsheet - Codecademy PDFTawsif HasanNo ratings yet
- Data Analysis With Pandas - Introduction To Pandas Cheatsheet - Codecademy PDFDocument3 pagesData Analysis With Pandas - Introduction To Pandas Cheatsheet - Codecademy PDFTawsif HasanNo ratings yet
- Intro To PandasDocument7 pagesIntro To PandasThe path to AllahNo ratings yet
- Python For DS Cheat SheetDocument6 pagesPython For DS Cheat SheetSebastián Emdef100% (2)
- Unit 4Document36 pagesUnit 4anurajyellurkar29No ratings yet
- PandasDocument4 pagesPandassumitpython.41No ratings yet
- Machine LearningDocument20 pagesMachine LearningSu EpimoodNo ratings yet
- DA0101EN-Review-Introduction - Jupyter NotebookDocument8 pagesDA0101EN-Review-Introduction - Jupyter NotebookSohail DoulahNo ratings yet
- All Document Reader 1715619870900Document6 pagesAll Document Reader 1715619870900Veer BahadurNo ratings yet
- Aman Ai Primers Pandas PDFDocument130 pagesAman Ai Primers Pandas PDFS MahapatraNo ratings yet
- Chapter 4 - Import-Export DataDocument30 pagesChapter 4 - Import-Export DataAnjanaNo ratings yet
- 1 Pandas BasicsDocument13 pages1 Pandas BasicsBikuNo ratings yet
- Pip3 Install JupyterDocument16 pagesPip3 Install Jupyterblah blNo ratings yet
- Python LibrariesDocument53 pagesPython Libraries0321-1741No ratings yet
- Comprehensive Guide Data Exploration Sas Using Python Numpy Scipy Matplotlib PandasDocument12 pagesComprehensive Guide Data Exploration Sas Using Python Numpy Scipy Matplotlib PandasAhsan Ahmad Beg100% (1)
- PJT Explanation of Code Line by LineDocument2 pagesPJT Explanation of Code Line by LineShruthika S 21BLC1498No ratings yet
- Data Manipulation With Pandas - Introduction To Pandas Reference Guide - CodecademyDocument3 pagesData Manipulation With Pandas - Introduction To Pandas Reference Guide - CodecademyYash PurandareNo ratings yet
- CO-367 Machine Learning Lab File: Submitted To: Submitted byDocument12 pagesCO-367 Machine Learning Lab File: Submitted To: Submitted byShubham AnandNo ratings yet
- Pandas LibraryDocument5 pagesPandas LibrarynoneNo ratings yet
- On Data Handling Using Pandas-IDocument64 pagesOn Data Handling Using Pandas-IRayansh Chauhan100% (2)
- On Data Handling Using Pandas-IDocument63 pagesOn Data Handling Using Pandas-Ianagha100% (2)
- Chapter 10 Python PandasDocument40 pagesChapter 10 Python PandasHarshit DayalNo ratings yet
- Class Notes: Class: XII Date: 7-Apr-2020 Subject: Informatics Practices Topic: 2. Python PandasDocument4 pagesClass Notes: Class: XII Date: 7-Apr-2020 Subject: Informatics Practices Topic: 2. Python PandasRavi RamrakhaniNo ratings yet
- 20 Pandas Functions For 80% of Your Data ScienceDocument22 pages20 Pandas Functions For 80% of Your Data ScienceHARRYNo ratings yet
- Unit - V Introduction To Pandas in PythonDocument21 pagesUnit - V Introduction To Pandas in PythonLindsey WhiteNo ratings yet
- Python PandasDocument230 pagesPython PandasArun NarasimhanNo ratings yet
- Exp7 11 Data ScienceDocument23 pagesExp7 11 Data ScienceNikhil Ranjan 211No ratings yet
- Python Pandas Interview QuestionsDocument17 pagesPython Pandas Interview Questionshasnain qureshi100% (1)
- Fds MannualDocument39 pagesFds MannualsudhaNo ratings yet
- Unit 4 PandasDocument8 pagesUnit 4 PandasPriya S BNo ratings yet
- Freda Song Drechsler - Maneuvering WRDS DataDocument8 pagesFreda Song Drechsler - Maneuvering WRDS DataRicardoHenriquezNo ratings yet
- Mastering Pandas - Important Pandas Functions For Your Next ProjectDocument5 pagesMastering Pandas - Important Pandas Functions For Your Next Projectdchandra15No ratings yet
- ML FileDocument12 pagesML Filehdofficial2003No ratings yet
- Pandas Module (Part-I)Document36 pagesPandas Module (Part-I)Aditya ChauhanNo ratings yet
- Data AnalysisDocument4 pagesData AnalysisSereti CodeproNo ratings yet
- Assingment-3 NLPDocument5 pagesAssingment-3 NLPmukesh shahNo ratings yet
- Eda Unit 2Document65 pagesEda Unit 260 Vibha Shree.SNo ratings yet
- Python Pandas-Series-newwDocument80 pagesPython Pandas-Series-newwp100% (1)
- Ch-2 - Panda - Part-1 - 3rd - DayDocument5 pagesCh-2 - Panda - Part-1 - 3rd - DayRC SharmaNo ratings yet
- Numpy&pandasDocument17 pagesNumpy&pandasSaif Ali KhanNo ratings yet
- Python: Advanced Guide to Programming Code with Python: Python Computer Programming, #4From EverandPython: Advanced Guide to Programming Code with Python: Python Computer Programming, #4No ratings yet