Download as docx, pdf, or txt
You might also like
- ASTM C-40 Tester: Ordering InformationDocument1 pageASTM C-40 Tester: Ordering InformationImber Rene Salgueiro HuancaNo ratings yet
- Electromagnetic Lab Write-UpDocument5 pagesElectromagnetic Lab Write-Upapi-375748727No ratings yet
- Module-02 AIML 21CS54Document27 pagesModule-02 AIML 21CS54Deepali Konety67% (3)
- Informed Search: Prepared by Dr. Megharani PatilDocument22 pagesInformed Search: Prepared by Dr. Megharani PatilPrashantNo ratings yet
- Module 3Document94 pagesModule 31rn21cd008.chandanmNo ratings yet
- Shayantan Kabiraj Company TarDocument12 pagesShayantan Kabiraj Company Tar22Shayantan KabirajNo ratings yet
- Unit 2Document26 pagesUnit 2skraoNo ratings yet
- SearchDocument17 pagesSearchHusayaNo ratings yet
- Module 2 UpdatedDocument46 pagesModule 2 Updatedrithusagar5No ratings yet
- Greedy NoteDocument20 pagesGreedy NoteNitishJalanNo ratings yet
- Informed Search Algorithm Group1Document8 pagesInformed Search Algorithm Group1Yis AlNo ratings yet
- Artificial Intelligence Questions SolvedDocument17 pagesArtificial Intelligence Questions SolvedAlima NasaNo ratings yet
- Unit 2Document66 pagesUnit 2meghanaghogareNo ratings yet
- Informed Search Algorithms in AI - JavatpointDocument10 pagesInformed Search Algorithms in AI - JavatpointNahla khanNo ratings yet
- AI Search AlgorithmDocument38 pagesAI Search AlgorithmRajat KumarNo ratings yet
- Module-02 AIML NOTESDocument29 pagesModule-02 AIML NOTESbabureddybn262003No ratings yet
- AI AssgmntDocument18 pagesAI Assgmntrobel damiseNo ratings yet
- Unit - 1Document20 pagesUnit - 1Riya jainNo ratings yet
- Lecture Notes - 4Document16 pagesLecture Notes - 412112004itNo ratings yet
- Module 7 Uninformed and Informed Searches 2Document20 pagesModule 7 Uninformed and Informed Searches 2Clash Of ClanesNo ratings yet
- ML Unit-4Document9 pagesML Unit-4AnshuNo ratings yet
- 2-1 CAI Unit II Q & ADocument6 pages2-1 CAI Unit II Q & Aluciferk0405No ratings yet
- 21CS54 Aiml Module3 PPTDocument102 pages21CS54 Aiml Module3 PPTsneha s PatelNo ratings yet
- AI AssgmntDocument18 pagesAI Assgmntrobel damiseNo ratings yet
- Dsa NotesDocument98 pagesDsa NotesVarsha yadavNo ratings yet
- Oup AssignmentDocument16 pagesOup AssignmentAyano BoresaNo ratings yet
- Data StructureDocument97 pagesData StructureKibru AberaNo ratings yet
- AI Imp QuestionsDocument33 pagesAI Imp Questionsumaimaaakhan0143No ratings yet
- Module 3 Probem SolvingDocument64 pagesModule 3 Probem Solvingafrozbhati1111No ratings yet
- Unit-2 Artificial IntelligenceDocument12 pagesUnit-2 Artificial Intelligencerajputakshay8940No ratings yet
- DATA Struct NotesDocument65 pagesDATA Struct NotesVaruna NikamNo ratings yet
- Informed Search AlgorithmsDocument16 pagesInformed Search AlgorithmsPriyansh GuptaNo ratings yet
- DSA Notes-1Document112 pagesDSA Notes-1GOVIND MANDGENo ratings yet
- 5 - AIML - Module3 - PPTDocument37 pages5 - AIML - Module3 - PPTDeepak B LNo ratings yet
- Module 3 - AIMLDocument134 pagesModule 3 - AIMLharinisk32No ratings yet
- Ai Notes by MatinDocument7 pagesAi Notes by MatinMatin MullaNo ratings yet
- Heuristic in Ai: BY-Chiranjeev Sharma A2324717001 Suraj Kumar Ojha A2324717007 7cse3 MbaDocument14 pagesHeuristic in Ai: BY-Chiranjeev Sharma A2324717001 Suraj Kumar Ojha A2324717007 7cse3 Mbachiranjeev sharmaNo ratings yet
- Test2 PortionsDocument115 pagesTest2 PortionsAshwath GuptaNo ratings yet
- Algorithm Unit 1Document9 pagesAlgorithm Unit 1PrakashNo ratings yet
- Informed Search AlgorithmsDocument12 pagesInformed Search AlgorithmsphaniNo ratings yet
- BFS AlgorithmDocument14 pagesBFS AlgorithmSupriya NevewaniNo ratings yet
- DSA Students Reference NotesDocument96 pagesDSA Students Reference NotesAbdul Azeez 312No ratings yet
- AI&ML Module 3Document63 pagesAI&ML Module 3Its MeNo ratings yet
- Algorithm Analysis and DesignDocument83 pagesAlgorithm Analysis and DesignkalaraijuNo ratings yet
- Module3 PPTDocument132 pagesModule3 PPTIflaNo ratings yet
- Lecture-07 Search TechniquesDocument7 pagesLecture-07 Search TechniquesHema KashyapNo ratings yet
- Earching Lgorithms: (I, H F, B F, H C, B S)Document61 pagesEarching Lgorithms: (I, H F, B F, H C, B S)Prakhar PathakNo ratings yet
- Module 1 DAADocument46 pagesModule 1 DAATUSHAR GUPTANo ratings yet
- Unit 3Document68 pagesUnit 3Aditya SrivastavaNo ratings yet
- DATA STRUCTURE NotesDocument101 pagesDATA STRUCTURE Notesrockmeena127No ratings yet
- Daa Lab FileDocument36 pagesDaa Lab Fileshriyaagupta18No ratings yet
- Zeyu Tan AI Assessment ReportDocument14 pagesZeyu Tan AI Assessment ReportAnna LionNo ratings yet
- Informed Search AI MID2 Unit 2Document8 pagesInformed Search AI MID2 Unit 2ks.umashankerNo ratings yet
- Greedy AlgorithmsDocument94 pagesGreedy AlgorithmsRythmNo ratings yet
- Artificial IntelligenceDocument18 pagesArtificial IntelligenceAlima NasaNo ratings yet
- Data Structures and Algorithms NotesDocument95 pagesData Structures and Algorithms NoteshiteshmehtaudemyNo ratings yet
- Algorithm Design and Analyisis NotesDocument37 pagesAlgorithm Design and Analyisis Notesnazamsingla5No ratings yet
- Ai 5Document6 pagesAi 5PhilNo ratings yet
- Unit 1Document17 pagesUnit 1ArsalanNo ratings yet
- Script 1 2Document11 pagesScript 1 2sanNo ratings yet
- AI Unit-2Document8 pagesAI Unit-2Vatan JainNo ratings yet
- SOLIDserver Administrator Guide 5.0.3Document1,041 pagesSOLIDserver Administrator Guide 5.0.3proutNo ratings yet
- Final Examination (Open Book) Koc3466 (Corporate Writing)Document9 pagesFinal Examination (Open Book) Koc3466 (Corporate Writing)Shar KhanNo ratings yet
- The Truth About The Truth MovementDocument68 pagesThe Truth About The Truth MovementgordoneastNo ratings yet
- Genshin AchievementsDocument31 pagesGenshin AchievementsHilmawan WibawantoNo ratings yet
- Unit I (Magnetic Field and Circuits - Electromagnetic Force and Torque)Document43 pagesUnit I (Magnetic Field and Circuits - Electromagnetic Force and Torque)UpasnaNo ratings yet
- SIP Presentation On MSMEDocument15 pagesSIP Presentation On MSMEShradha KhandareNo ratings yet
- Full Research Terrarium in A BottleDocument28 pagesFull Research Terrarium in A BottleBethzaida Jean RamirezNo ratings yet
- TXVs - All You Need To KnowDocument4 pagesTXVs - All You Need To KnowOmar ArdilaNo ratings yet
- DisabilityDocument34 pagesDisabilitymeghnaumNo ratings yet
- SSL Stripping Technique DHCP Snooping and ARP Spoofing InspectionDocument7 pagesSSL Stripping Technique DHCP Snooping and ARP Spoofing InspectionRMNo ratings yet
- Database SecurityDocument19 pagesDatabase SecurityVinay VenkatramanNo ratings yet
- Finding Solar Potential Using QGISDocument4 pagesFinding Solar Potential Using QGISJailly AceNo ratings yet
- Journaling PDFDocument1 pageJournaling PDFMargarita Maria Botero PerezNo ratings yet
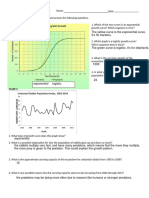
- L - Logistic and Exponential Graphs WorksheetDocument2 pagesL - Logistic and Exponential Graphs WorksheetHexagon LyricsNo ratings yet
- Kodedkloud Instalation HardwayDocument153 pagesKodedkloud Instalation HardwayJuca LocoNo ratings yet
- Good To Great in Gods Eyes. Good To Great in God's Eyes (Part 1) Think Great Thoughts 10 Practices Great Christians Have in CommonDocument4 pagesGood To Great in Gods Eyes. Good To Great in God's Eyes (Part 1) Think Great Thoughts 10 Practices Great Christians Have in Commonad.adNo ratings yet
- Phi Theta Kappa Sued by HonorSociety - Org Lawsuit Details 2024 False AdvertisingDocument47 pagesPhi Theta Kappa Sued by HonorSociety - Org Lawsuit Details 2024 False AdvertisinghonorsocietyorgNo ratings yet
- Mathematics Grade 10Document270 pagesMathematics Grade 10TammanurRaviNo ratings yet
- VR-Research Paper: August 2021Document66 pagesVR-Research Paper: August 2021Shashank YadavNo ratings yet
- ASTM D2041 aashto T209 ефект процент битума PDFDocument4 pagesASTM D2041 aashto T209 ефект процент битума PDFanon_711474514No ratings yet
- Classification of FinishesDocument5 pagesClassification of FinishesOjasvee Kashyap100% (1)
- Sports and Entertainment Marketing: Sample Role PlaysDocument36 pagesSports and Entertainment Marketing: Sample Role PlaysTAHA GABRNo ratings yet
- 01 eLMS Activity 1 Network TechnologyDocument2 pages01 eLMS Activity 1 Network Technologybasahara sengokuNo ratings yet
- Standard Electrode Potentials & CellsDocument3 pagesStandard Electrode Potentials & Cellsmy nameNo ratings yet
- DzireDocument324 pagesDzireDaniel Lopez VenancioNo ratings yet
- Des-F1025p-E DSDocument3 pagesDes-F1025p-E DSNaing Win ZawNo ratings yet
- Porter's Five Forces Model of Competition-1Document14 pagesPorter's Five Forces Model of Competition-1Kanika RustagiNo ratings yet
- Villa As ParadigmDocument4 pagesVilla As ParadigmPaul Turner100% (1)