
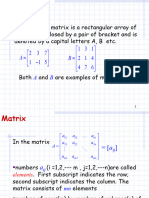
Maatext Template
Maatext Template
You might also like
- Computer Organization and Design Mips Edition 5th Edition Patterson Solutions ManualDocument9 pagesComputer Organization and Design Mips Edition 5th Edition Patterson Solutions Manualmatthewmorrisonsmwqkifnjx94% (17)
- Optimal Filtering With Aerospace Applications: Section 2.1: Linear Algebra and MatricesDocument27 pagesOptimal Filtering With Aerospace Applications: Section 2.1: Linear Algebra and Matricesdayvox10No ratings yet
- Chapter 1Document16 pagesChapter 1holaNo ratings yet
- CS545-Contents II: Adminstrative A Refresher of Linear AlgebraDocument16 pagesCS545-Contents II: Adminstrative A Refresher of Linear AlgebraYIO HINo ratings yet
- Appendix A. Linear AlgebraDocument15 pagesAppendix A. Linear AlgebraFrederico AntoniazziNo ratings yet
- Lesson 11Document12 pagesLesson 11ebi1234No ratings yet
- Algebra NYCUII Course Part 5Document8 pagesAlgebra NYCUII Course Part 5gabriellarataNo ratings yet
- Chapter 09 PDFDocument40 pagesChapter 09 PDFSyed UzairNo ratings yet
- MatrixDocument5 pagesMatrixS KrishnaveniNo ratings yet
- Chap 2Document52 pagesChap 2Lê Vũ Anh NguyễnNo ratings yet
- Chapter3a MatricesDocument28 pagesChapter3a MatricessujjashriNo ratings yet
- Appendix B Matrix AlgebraDocument11 pagesAppendix B Matrix Algebrama yeningNo ratings yet
- Linear AlgebraDocument17 pagesLinear AlgebraTojo MaityNo ratings yet
- Notes For 351Document16 pagesNotes For 351princesskaydee555No ratings yet
- Matrix Methods: Systems of Linear EquationsDocument75 pagesMatrix Methods: Systems of Linear EquationsLJ Asencion CacotNo ratings yet
- Math 0 BookDocument70 pagesMath 0 Bookomared12zxs23No ratings yet
- 340notes PDFDocument34 pages340notes PDFAmit K AwasthiNo ratings yet
- JEE Main 2022 Maths Revision Notes On Matrices and DeterminantsDocument7 pagesJEE Main 2022 Maths Revision Notes On Matrices and DeterminantsherooNo ratings yet
- Mathematical Preliminaries - III: Ça Gatay KayıDocument9 pagesMathematical Preliminaries - III: Ça Gatay KayıAndrew WalkerNo ratings yet
- Chap2 - Determinant 2022Document6 pagesChap2 - Determinant 2022An PhamNo ratings yet
- Matrices PDFDocument2 pagesMatrices PDFAnonymous vRpzQ2BLNo ratings yet
- Eigenvalue Problems: M, N I I M, N I I I, M I, NDocument31 pagesEigenvalue Problems: M, N I I M, N I I I, M I, Nđại phạmNo ratings yet
- Linear AlgebraDocument37 pagesLinear AlgebraFernando BrandoNo ratings yet
- Ch1-1 Matrices InglesDocument10 pagesCh1-1 Matrices InglessempiNo ratings yet
- 19matrices DeterminantsDocument5 pages19matrices DeterminantssatyahbhatNo ratings yet
- 2 Matrix Algebra: 2.1 Basic ConceptsDocument15 pages2 Matrix Algebra: 2.1 Basic ConceptsYanira EspinozaNo ratings yet
- ECON6067 Topic 5 2022Document20 pagesECON6067 Topic 5 2022Mingtao ChenNo ratings yet
- Matrix Day-1Document4 pagesMatrix Day-1mahek.patel.mkNo ratings yet
- Slides VB Inz MM 04 MatrDocument145 pagesSlides VB Inz MM 04 MatrVladimir BalticNo ratings yet
- Mathematics Matrices: Vibrant AcademyDocument26 pagesMathematics Matrices: Vibrant AcademyIndranilNo ratings yet
- Handbook 2019Document86 pagesHandbook 2019PoojitaNo ratings yet
- Notes On Linear Algebra: Asma AlramleDocument14 pagesNotes On Linear Algebra: Asma AlramleEsmaeil AlkhazmiNo ratings yet
- Definition of MatricesDocument70 pagesDefinition of Matrices37 S.M Shahriar RifatNo ratings yet
- Matrix Workbook 2Document10 pagesMatrix Workbook 2Utsab DasNo ratings yet
- Lecture9 Math 102Document21 pagesLecture9 Math 102radhikaseelam1No ratings yet
- Prezentace Hnetynkova PDFDocument33 pagesPrezentace Hnetynkova PDFM Chandan ShankarNo ratings yet
- G.B Sir: Key Concepts MatricesDocument12 pagesG.B Sir: Key Concepts MatricesAmal SutradharNo ratings yet
- Matrices 2Document54 pagesMatrices 2Lydia WalkerNo ratings yet
- Lecture Note 01BDocument3 pagesLecture Note 01BRAJ MEENANo ratings yet
- For More Study Material & Test Papers: Manoj Chauhan Sir (Iit-Delhi) Ex. Sr. Faculty (Bansal Classes)Document15 pagesFor More Study Material & Test Papers: Manoj Chauhan Sir (Iit-Delhi) Ex. Sr. Faculty (Bansal Classes)Vivek DasNo ratings yet
- Flo Oved 1669 MatricesDocument8 pagesFlo Oved 1669 MatricesvahidNo ratings yet
- ONeil7 7th Matrices and Linear SystemsDocument92 pagesONeil7 7th Matrices and Linear Systems김민성No ratings yet
- Linear Algebra: Chapter HighlightsDocument17 pagesLinear Algebra: Chapter HighlightsAKASH PALNo ratings yet
- SMA1102 Linear Algebra Matrices Updated1Document15 pagesSMA1102 Linear Algebra Matrices Updated1creamgamingplayzNo ratings yet
- A Review of Linear AlgebraDocument19 pagesA Review of Linear AlgebraOsman Abdul-MuminNo ratings yet
- Linear Algebra Review: Appendix EDocument28 pagesLinear Algebra Review: Appendix EBhushan RaneNo ratings yet
- Introduction To Matrices: Dr. Ammar IsamDocument31 pagesIntroduction To Matrices: Dr. Ammar IsamYasser HashimNo ratings yet
- Chapter 3: System of Linear EquationDocument60 pagesChapter 3: System of Linear Equationyohannes wendwesenNo ratings yet
- Chapter 1. Matrix Algebra - Ver3.2.22 - NopauseDocument63 pagesChapter 1. Matrix Algebra - Ver3.2.22 - NopauseNam NguyễnNo ratings yet
- Iitjee MathsDocument78 pagesIitjee MathsSanjay GuptaNo ratings yet
- Unit2 SystemsDocument40 pagesUnit2 SystemsNaiara Fernández FernándezNo ratings yet
- (A K Ray S K Gupta) Mathematical Methods in ChemiDocument53 pages(A K Ray S K Gupta) Mathematical Methods in ChemiKapilSahuNo ratings yet
- Matrix in EnglishDocument15 pagesMatrix in EnglishRafael Ramon VBNo ratings yet
- Math 1 PDFDocument146 pagesMath 1 PDFAbdo ElbrenceNo ratings yet
- Matrices and Determinants Exercise Solutions With TheoryDocument140 pagesMatrices and Determinants Exercise Solutions With Theoryaviverma654321No ratings yet
- Section4 8Document23 pagesSection4 8Amna OmerNo ratings yet
- LA KeyDocument6 pagesLA Keysubhampadhi980No ratings yet
- Linear Algebra in 4 Pages PDFDocument4 pagesLinear Algebra in 4 Pages PDFRAPID M&ENo ratings yet
- Lecture 5Document5 pagesLecture 5laxmivandanaNo ratings yet
- Matrix Theory and Applications for Scientists and EngineersFrom EverandMatrix Theory and Applications for Scientists and EngineersNo ratings yet
- Constructing and Writing Mathematical Proofs - A Guide For MathemaDocument80 pagesConstructing and Writing Mathematical Proofs - A Guide For MathemaJaime Andres Aranguren CardonaNo ratings yet
- Using The FFT As An Arbitrary Function GeneratorDocument5 pagesUsing The FFT As An Arbitrary Function GeneratorJaime Andres Aranguren CardonaNo ratings yet
- Support Vector Machines and Perceptrons Learning, Optimization, Classification, and Application To Social NetworksDocument103 pagesSupport Vector Machines and Perceptrons Learning, Optimization, Classification, and Application To Social NetworksJaime Andres Aranguren CardonaNo ratings yet
- The Structure of The Real Number System: "The Integers God Made All The Rest Is The Work of Man. " L. KroneckerDocument10 pagesThe Structure of The Real Number System: "The Integers God Made All The Rest Is The Work of Man. " L. KroneckerJaime Andres Aranguren CardonaNo ratings yet
- HT45F0074Document1 pageHT45F0074Jaime Andres Aranguren CardonaNo ratings yet
- HHUDocument10 pagesHHUJaime Andres Aranguren CardonaNo ratings yet
- ADSP21990 Board ManualDocument60 pagesADSP21990 Board ManualJaime Andres Aranguren CardonaNo ratings yet
- Updated PI 20230307Document1 pageUpdated PI 20230307Jaime Andres Aranguren CardonaNo ratings yet
- ADSP-2189M ADocument32 pagesADSP-2189M AJaime Andres Aranguren CardonaNo ratings yet
- ADSP-21992 PraDocument48 pagesADSP-21992 PraJaime Andres Aranguren CardonaNo ratings yet
- AttendeelistDocument37 pagesAttendeelistJaime Andres Aranguren CardonaNo ratings yet
- NVKlee Digital BOMDocument2 pagesNVKlee Digital BOMJaime Andres Aranguren CardonaNo ratings yet
- Kodomo No Hihongo I - 008Document1 pageKodomo No Hihongo I - 008Jaime Andres Aranguren CardonaNo ratings yet
- RPi SetupDocument1 pageRPi SetupJaime Andres Aranguren CardonaNo ratings yet
- AXP209Document49 pagesAXP209Jaime Andres Aranguren CardonaNo ratings yet
- Kodomo No Hihongo I - 002Document1 pageKodomo No Hihongo I - 002Jaime Andres Aranguren CardonaNo ratings yet
- Allwinner AXP203 Datasheet V1.0Document55 pagesAllwinner AXP203 Datasheet V1.0Jaime Andres Aranguren CardonaNo ratings yet
- Kodomo No Hihongo I - 003Document1 pageKodomo No Hihongo I - 003Jaime Andres Aranguren CardonaNo ratings yet
- 164Document10 pages164Jaime Andres Aranguren CardonaNo ratings yet
- Kodomo No Hihongo I - 009Document1 pageKodomo No Hihongo I - 009Jaime Andres Aranguren CardonaNo ratings yet
- L14 SVDDocument8 pagesL14 SVDJaime Andres Aranguren CardonaNo ratings yet
- SSPv1.7.0 Additional Usage Note (R11ut0064eu0101 Synergy Sspv170 Additional Usage Note)Document18 pagesSSPv1.7.0 Additional Usage Note (R11ut0064eu0101 Synergy Sspv170 Additional Usage Note)Jaime Andres Aranguren CardonaNo ratings yet
- Calculation of Stabilizing Resistor in High Impedance Differential Protection - Electrical ConceptsDocument13 pagesCalculation of Stabilizing Resistor in High Impedance Differential Protection - Electrical ConceptsABHINAV SAURAVNo ratings yet
- Capacitor Switching Transients ProblemsDocument5 pagesCapacitor Switching Transients Problemsaris09yekofNo ratings yet
- MODULE 2 - EEConDocument27 pagesMODULE 2 - EEConMark Anthony GarciaNo ratings yet
- Respiratory System: Breathing, Gaseous Exchange and Respiration Grade 10Document27 pagesRespiratory System: Breathing, Gaseous Exchange and Respiration Grade 10Big HeadNo ratings yet
- FinitosDocument772 pagesFinitosVictor Jesus Rios100% (5)
- Bosch Pressure Sensor ManualDocument1 pageBosch Pressure Sensor ManualVladimirAgeevNo ratings yet
- Final PaperDocument14 pagesFinal Paperebinsams007No ratings yet
- Photoelastic Unit: Technical Teaching EquipmentDocument5 pagesPhotoelastic Unit: Technical Teaching EquipmentpondpakkaNo ratings yet
- ReplicationDocument625 pagesReplicationpilabaNo ratings yet
- How To Install and Configure SMP in A Cluster Env 3.x With SP05 - FinalDocument97 pagesHow To Install and Configure SMP in A Cluster Env 3.x With SP05 - FinaljigchinNo ratings yet
- Adminbalitbangda,+4 +Artikel+Budi+TeguhDocument16 pagesAdminbalitbangda,+4 +Artikel+Budi+Teguhhenie inamortaNo ratings yet
- ProjectS 2Document25 pagesProjectS 2Ngân Võ Trần TuyếtNo ratings yet
- Statistical Process Control (SPC) : Praful MehtaDocument66 pagesStatistical Process Control (SPC) : Praful MehtaAsawari JoshiNo ratings yet
- IQAN Accessories Brochure HY33-8319 UKDocument12 pagesIQAN Accessories Brochure HY33-8319 UKabdelhadi houssinNo ratings yet
- NSCV Part C-6a-Intact Stability RequirementsDocument111 pagesNSCV Part C-6a-Intact Stability RequirementsNgoc BangNo ratings yet
- Configure IP Address For Ethernet Port PrintersDocument6 pagesConfigure IP Address For Ethernet Port Printersjairson MonteiroNo ratings yet
- Cavitation PaperDocument6 pagesCavitation PaperTony KadatzNo ratings yet
- ESA BAT 0113 Gasket Tightness 3 New EU Standards PDFDocument2 pagesESA BAT 0113 Gasket Tightness 3 New EU Standards PDFJosmar CristelloNo ratings yet
- Notes Lower Form 2023Document93 pagesNotes Lower Form 2023NORIDAH BINTI RAHMAT MoeNo ratings yet
- Algorithm - Writing Lab ReportsDocument2 pagesAlgorithm - Writing Lab ReportsPratiksh PatelNo ratings yet
- Section 2.3.5: Latex TestDocument5 pagesSection 2.3.5: Latex TestLeydi Yudith Angarita BautistaNo ratings yet
- Lieber 1961 Human Values and Science Art and MathematicsDocument74 pagesLieber 1961 Human Values and Science Art and MathematicsaNo ratings yet
- SPE-191827-18ERM-MS Application of Machine Learning Algorithms For Optimizing Future Production in Marcellus Shale, Case Study of Southwestern PennsylvaniaDocument14 pagesSPE-191827-18ERM-MS Application of Machine Learning Algorithms For Optimizing Future Production in Marcellus Shale, Case Study of Southwestern PennsylvaniaTurqay İsgəndərliNo ratings yet
- Chapter 3 - The Playing Area: Dimensions and Lines Worksheet No. 4 The Playing Area Learning OutcomesDocument5 pagesChapter 3 - The Playing Area: Dimensions and Lines Worksheet No. 4 The Playing Area Learning OutcomesMc Kevin Jade MadambaNo ratings yet
- SPE 71517 Decline Curve Analysis Using Type Curves - Evaluation of Well Performance Behavior in A Multiwell Reservoir SystemDocument15 pagesSPE 71517 Decline Curve Analysis Using Type Curves - Evaluation of Well Performance Behavior in A Multiwell Reservoir SystemGHIFFARI PARAMANTA ELBEESNo ratings yet
- Distance Learning Programme: Pre-Medical: Leader Test Series / Joint Package CourseDocument48 pagesDistance Learning Programme: Pre-Medical: Leader Test Series / Joint Package Courseunacademy neetNo ratings yet
- Product Information: Sic at Sheet Membranes and ModulesDocument29 pagesProduct Information: Sic at Sheet Membranes and ModulesNitin KurupNo ratings yet
- Lecture 1 (Refrigeration Engineering)Document19 pagesLecture 1 (Refrigeration Engineering)Aldwin DuroNo ratings yet













































































































Download as pdf or txt
You might also like
- Computer Organization and Design Mips Edition 5th Edition Patterson Solutions ManualDocument9 pagesComputer Organization and Design Mips Edition 5th Edition Patterson Solutions Manualmatthewmorrisonsmwqkifnjx94% (17)
- Optimal Filtering With Aerospace Applications: Section 2.1: Linear Algebra and MatricesDocument27 pagesOptimal Filtering With Aerospace Applications: Section 2.1: Linear Algebra and Matricesdayvox10No ratings yet
- Chapter 1Document16 pagesChapter 1holaNo ratings yet
- CS545-Contents II: Adminstrative A Refresher of Linear AlgebraDocument16 pagesCS545-Contents II: Adminstrative A Refresher of Linear AlgebraYIO HINo ratings yet
- Appendix A. Linear AlgebraDocument15 pagesAppendix A. Linear AlgebraFrederico AntoniazziNo ratings yet
- Lesson 11Document12 pagesLesson 11ebi1234No ratings yet
- Algebra NYCUII Course Part 5Document8 pagesAlgebra NYCUII Course Part 5gabriellarataNo ratings yet
- Chapter 09 PDFDocument40 pagesChapter 09 PDFSyed UzairNo ratings yet
- MatrixDocument5 pagesMatrixS KrishnaveniNo ratings yet
- Chap 2Document52 pagesChap 2Lê Vũ Anh NguyễnNo ratings yet
- Chapter3a MatricesDocument28 pagesChapter3a MatricessujjashriNo ratings yet
- Appendix B Matrix AlgebraDocument11 pagesAppendix B Matrix Algebrama yeningNo ratings yet
- Linear AlgebraDocument17 pagesLinear AlgebraTojo MaityNo ratings yet
- Notes For 351Document16 pagesNotes For 351princesskaydee555No ratings yet
- Matrix Methods: Systems of Linear EquationsDocument75 pagesMatrix Methods: Systems of Linear EquationsLJ Asencion CacotNo ratings yet
- Math 0 BookDocument70 pagesMath 0 Bookomared12zxs23No ratings yet
- 340notes PDFDocument34 pages340notes PDFAmit K AwasthiNo ratings yet
- JEE Main 2022 Maths Revision Notes On Matrices and DeterminantsDocument7 pagesJEE Main 2022 Maths Revision Notes On Matrices and DeterminantsherooNo ratings yet
- Mathematical Preliminaries - III: Ça Gatay KayıDocument9 pagesMathematical Preliminaries - III: Ça Gatay KayıAndrew WalkerNo ratings yet
- Chap2 - Determinant 2022Document6 pagesChap2 - Determinant 2022An PhamNo ratings yet
- Matrices PDFDocument2 pagesMatrices PDFAnonymous vRpzQ2BLNo ratings yet
- Eigenvalue Problems: M, N I I M, N I I I, M I, NDocument31 pagesEigenvalue Problems: M, N I I M, N I I I, M I, Nđại phạmNo ratings yet
- Linear AlgebraDocument37 pagesLinear AlgebraFernando BrandoNo ratings yet
- Ch1-1 Matrices InglesDocument10 pagesCh1-1 Matrices InglessempiNo ratings yet
- 19matrices DeterminantsDocument5 pages19matrices DeterminantssatyahbhatNo ratings yet
- 2 Matrix Algebra: 2.1 Basic ConceptsDocument15 pages2 Matrix Algebra: 2.1 Basic ConceptsYanira EspinozaNo ratings yet
- ECON6067 Topic 5 2022Document20 pagesECON6067 Topic 5 2022Mingtao ChenNo ratings yet
- Matrix Day-1Document4 pagesMatrix Day-1mahek.patel.mkNo ratings yet
- Slides VB Inz MM 04 MatrDocument145 pagesSlides VB Inz MM 04 MatrVladimir BalticNo ratings yet
- Mathematics Matrices: Vibrant AcademyDocument26 pagesMathematics Matrices: Vibrant AcademyIndranilNo ratings yet
- Handbook 2019Document86 pagesHandbook 2019PoojitaNo ratings yet
- Notes On Linear Algebra: Asma AlramleDocument14 pagesNotes On Linear Algebra: Asma AlramleEsmaeil AlkhazmiNo ratings yet
- Definition of MatricesDocument70 pagesDefinition of Matrices37 S.M Shahriar RifatNo ratings yet
- Matrix Workbook 2Document10 pagesMatrix Workbook 2Utsab DasNo ratings yet
- Lecture9 Math 102Document21 pagesLecture9 Math 102radhikaseelam1No ratings yet
- Prezentace Hnetynkova PDFDocument33 pagesPrezentace Hnetynkova PDFM Chandan ShankarNo ratings yet
- G.B Sir: Key Concepts MatricesDocument12 pagesG.B Sir: Key Concepts MatricesAmal SutradharNo ratings yet
- Matrices 2Document54 pagesMatrices 2Lydia WalkerNo ratings yet
- Lecture Note 01BDocument3 pagesLecture Note 01BRAJ MEENANo ratings yet
- For More Study Material & Test Papers: Manoj Chauhan Sir (Iit-Delhi) Ex. Sr. Faculty (Bansal Classes)Document15 pagesFor More Study Material & Test Papers: Manoj Chauhan Sir (Iit-Delhi) Ex. Sr. Faculty (Bansal Classes)Vivek DasNo ratings yet
- Flo Oved 1669 MatricesDocument8 pagesFlo Oved 1669 MatricesvahidNo ratings yet
- ONeil7 7th Matrices and Linear SystemsDocument92 pagesONeil7 7th Matrices and Linear Systems김민성No ratings yet
- Linear Algebra: Chapter HighlightsDocument17 pagesLinear Algebra: Chapter HighlightsAKASH PALNo ratings yet
- SMA1102 Linear Algebra Matrices Updated1Document15 pagesSMA1102 Linear Algebra Matrices Updated1creamgamingplayzNo ratings yet
- A Review of Linear AlgebraDocument19 pagesA Review of Linear AlgebraOsman Abdul-MuminNo ratings yet
- Linear Algebra Review: Appendix EDocument28 pagesLinear Algebra Review: Appendix EBhushan RaneNo ratings yet
- Introduction To Matrices: Dr. Ammar IsamDocument31 pagesIntroduction To Matrices: Dr. Ammar IsamYasser HashimNo ratings yet
- Chapter 3: System of Linear EquationDocument60 pagesChapter 3: System of Linear Equationyohannes wendwesenNo ratings yet
- Chapter 1. Matrix Algebra - Ver3.2.22 - NopauseDocument63 pagesChapter 1. Matrix Algebra - Ver3.2.22 - NopauseNam NguyễnNo ratings yet
- Iitjee MathsDocument78 pagesIitjee MathsSanjay GuptaNo ratings yet
- Unit2 SystemsDocument40 pagesUnit2 SystemsNaiara Fernández FernándezNo ratings yet
- (A K Ray S K Gupta) Mathematical Methods in ChemiDocument53 pages(A K Ray S K Gupta) Mathematical Methods in ChemiKapilSahuNo ratings yet
- Matrix in EnglishDocument15 pagesMatrix in EnglishRafael Ramon VBNo ratings yet
- Math 1 PDFDocument146 pagesMath 1 PDFAbdo ElbrenceNo ratings yet
- Matrices and Determinants Exercise Solutions With TheoryDocument140 pagesMatrices and Determinants Exercise Solutions With Theoryaviverma654321No ratings yet
- Section4 8Document23 pagesSection4 8Amna OmerNo ratings yet
- LA KeyDocument6 pagesLA Keysubhampadhi980No ratings yet
- Linear Algebra in 4 Pages PDFDocument4 pagesLinear Algebra in 4 Pages PDFRAPID M&ENo ratings yet
- Lecture 5Document5 pagesLecture 5laxmivandanaNo ratings yet
- Matrix Theory and Applications for Scientists and EngineersFrom EverandMatrix Theory and Applications for Scientists and EngineersNo ratings yet
- Constructing and Writing Mathematical Proofs - A Guide For MathemaDocument80 pagesConstructing and Writing Mathematical Proofs - A Guide For MathemaJaime Andres Aranguren CardonaNo ratings yet
- Using The FFT As An Arbitrary Function GeneratorDocument5 pagesUsing The FFT As An Arbitrary Function GeneratorJaime Andres Aranguren CardonaNo ratings yet
- Support Vector Machines and Perceptrons Learning, Optimization, Classification, and Application To Social NetworksDocument103 pagesSupport Vector Machines and Perceptrons Learning, Optimization, Classification, and Application To Social NetworksJaime Andres Aranguren CardonaNo ratings yet
- The Structure of The Real Number System: "The Integers God Made All The Rest Is The Work of Man. " L. KroneckerDocument10 pagesThe Structure of The Real Number System: "The Integers God Made All The Rest Is The Work of Man. " L. KroneckerJaime Andres Aranguren CardonaNo ratings yet
- HT45F0074Document1 pageHT45F0074Jaime Andres Aranguren CardonaNo ratings yet
- HHUDocument10 pagesHHUJaime Andres Aranguren CardonaNo ratings yet
- ADSP21990 Board ManualDocument60 pagesADSP21990 Board ManualJaime Andres Aranguren CardonaNo ratings yet
- Updated PI 20230307Document1 pageUpdated PI 20230307Jaime Andres Aranguren CardonaNo ratings yet
- ADSP-2189M ADocument32 pagesADSP-2189M AJaime Andres Aranguren CardonaNo ratings yet
- ADSP-21992 PraDocument48 pagesADSP-21992 PraJaime Andres Aranguren CardonaNo ratings yet
- AttendeelistDocument37 pagesAttendeelistJaime Andres Aranguren CardonaNo ratings yet
- NVKlee Digital BOMDocument2 pagesNVKlee Digital BOMJaime Andres Aranguren CardonaNo ratings yet
- Kodomo No Hihongo I - 008Document1 pageKodomo No Hihongo I - 008Jaime Andres Aranguren CardonaNo ratings yet
- RPi SetupDocument1 pageRPi SetupJaime Andres Aranguren CardonaNo ratings yet
- AXP209Document49 pagesAXP209Jaime Andres Aranguren CardonaNo ratings yet
- Kodomo No Hihongo I - 002Document1 pageKodomo No Hihongo I - 002Jaime Andres Aranguren CardonaNo ratings yet
- Allwinner AXP203 Datasheet V1.0Document55 pagesAllwinner AXP203 Datasheet V1.0Jaime Andres Aranguren CardonaNo ratings yet
- Kodomo No Hihongo I - 003Document1 pageKodomo No Hihongo I - 003Jaime Andres Aranguren CardonaNo ratings yet
- 164Document10 pages164Jaime Andres Aranguren CardonaNo ratings yet
- Kodomo No Hihongo I - 009Document1 pageKodomo No Hihongo I - 009Jaime Andres Aranguren CardonaNo ratings yet
- L14 SVDDocument8 pagesL14 SVDJaime Andres Aranguren CardonaNo ratings yet
- SSPv1.7.0 Additional Usage Note (R11ut0064eu0101 Synergy Sspv170 Additional Usage Note)Document18 pagesSSPv1.7.0 Additional Usage Note (R11ut0064eu0101 Synergy Sspv170 Additional Usage Note)Jaime Andres Aranguren CardonaNo ratings yet
- Calculation of Stabilizing Resistor in High Impedance Differential Protection - Electrical ConceptsDocument13 pagesCalculation of Stabilizing Resistor in High Impedance Differential Protection - Electrical ConceptsABHINAV SAURAVNo ratings yet
- Capacitor Switching Transients ProblemsDocument5 pagesCapacitor Switching Transients Problemsaris09yekofNo ratings yet
- MODULE 2 - EEConDocument27 pagesMODULE 2 - EEConMark Anthony GarciaNo ratings yet
- Respiratory System: Breathing, Gaseous Exchange and Respiration Grade 10Document27 pagesRespiratory System: Breathing, Gaseous Exchange and Respiration Grade 10Big HeadNo ratings yet
- FinitosDocument772 pagesFinitosVictor Jesus Rios100% (5)
- Bosch Pressure Sensor ManualDocument1 pageBosch Pressure Sensor ManualVladimirAgeevNo ratings yet
- Final PaperDocument14 pagesFinal Paperebinsams007No ratings yet
- Photoelastic Unit: Technical Teaching EquipmentDocument5 pagesPhotoelastic Unit: Technical Teaching EquipmentpondpakkaNo ratings yet
- ReplicationDocument625 pagesReplicationpilabaNo ratings yet
- How To Install and Configure SMP in A Cluster Env 3.x With SP05 - FinalDocument97 pagesHow To Install and Configure SMP in A Cluster Env 3.x With SP05 - FinaljigchinNo ratings yet
- Adminbalitbangda,+4 +Artikel+Budi+TeguhDocument16 pagesAdminbalitbangda,+4 +Artikel+Budi+Teguhhenie inamortaNo ratings yet
- ProjectS 2Document25 pagesProjectS 2Ngân Võ Trần TuyếtNo ratings yet
- Statistical Process Control (SPC) : Praful MehtaDocument66 pagesStatistical Process Control (SPC) : Praful MehtaAsawari JoshiNo ratings yet
- IQAN Accessories Brochure HY33-8319 UKDocument12 pagesIQAN Accessories Brochure HY33-8319 UKabdelhadi houssinNo ratings yet
- NSCV Part C-6a-Intact Stability RequirementsDocument111 pagesNSCV Part C-6a-Intact Stability RequirementsNgoc BangNo ratings yet
- Configure IP Address For Ethernet Port PrintersDocument6 pagesConfigure IP Address For Ethernet Port Printersjairson MonteiroNo ratings yet
- Cavitation PaperDocument6 pagesCavitation PaperTony KadatzNo ratings yet
- ESA BAT 0113 Gasket Tightness 3 New EU Standards PDFDocument2 pagesESA BAT 0113 Gasket Tightness 3 New EU Standards PDFJosmar CristelloNo ratings yet
- Notes Lower Form 2023Document93 pagesNotes Lower Form 2023NORIDAH BINTI RAHMAT MoeNo ratings yet
- Algorithm - Writing Lab ReportsDocument2 pagesAlgorithm - Writing Lab ReportsPratiksh PatelNo ratings yet
- Section 2.3.5: Latex TestDocument5 pagesSection 2.3.5: Latex TestLeydi Yudith Angarita BautistaNo ratings yet
- Lieber 1961 Human Values and Science Art and MathematicsDocument74 pagesLieber 1961 Human Values and Science Art and MathematicsaNo ratings yet
- SPE-191827-18ERM-MS Application of Machine Learning Algorithms For Optimizing Future Production in Marcellus Shale, Case Study of Southwestern PennsylvaniaDocument14 pagesSPE-191827-18ERM-MS Application of Machine Learning Algorithms For Optimizing Future Production in Marcellus Shale, Case Study of Southwestern PennsylvaniaTurqay İsgəndərliNo ratings yet
- Chapter 3 - The Playing Area: Dimensions and Lines Worksheet No. 4 The Playing Area Learning OutcomesDocument5 pagesChapter 3 - The Playing Area: Dimensions and Lines Worksheet No. 4 The Playing Area Learning OutcomesMc Kevin Jade MadambaNo ratings yet
- SPE 71517 Decline Curve Analysis Using Type Curves - Evaluation of Well Performance Behavior in A Multiwell Reservoir SystemDocument15 pagesSPE 71517 Decline Curve Analysis Using Type Curves - Evaluation of Well Performance Behavior in A Multiwell Reservoir SystemGHIFFARI PARAMANTA ELBEESNo ratings yet
- Distance Learning Programme: Pre-Medical: Leader Test Series / Joint Package CourseDocument48 pagesDistance Learning Programme: Pre-Medical: Leader Test Series / Joint Package Courseunacademy neetNo ratings yet
- Product Information: Sic at Sheet Membranes and ModulesDocument29 pagesProduct Information: Sic at Sheet Membranes and ModulesNitin KurupNo ratings yet
- Lecture 1 (Refrigeration Engineering)Document19 pagesLecture 1 (Refrigeration Engineering)Aldwin DuroNo ratings yet