
Lecture 2-3 (CMS)
Lecture 2-3 (CMS)
You might also like
- CS3304 9 LanguageSyntax 2 PDFDocument39 pagesCS3304 9 LanguageSyntax 2 PDFrubaNo ratings yet
- Error Control Systems For Digital Communication and Storage (Stephen B. Wicker)Document268 pagesError Control Systems For Digital Communication and Storage (Stephen B. Wicker)sirapu100% (3)
- 3 parser-Intro-L5Document21 pages3 parser-Intro-L5PRANJAL SHARMANo ratings yet
- BITS PilaniDocument21 pagesBITS Pilaniwwpretty faceNo ratings yet
- Lecture#9 - Chap#3 (Lexical Analysis (Part-I) )Document25 pagesLecture#9 - Chap#3 (Lexical Analysis (Part-I) )jmi40724No ratings yet
- ch-2.pdf 2Document27 pagesch-2.pdf 2Salih AkadarNo ratings yet
- Semantic AnalysisDocument74 pagesSemantic Analysissiddharth sasmalNo ratings yet
- Principles of Programming Language: BITS PilaniDocument51 pagesPrinciples of Programming Language: BITS PilaniRutviNo ratings yet
- Week 2 Lec 4 CCDocument28 pagesWeek 2 Lec 4 CCSohaib KashmiriNo ratings yet
- Compiler 6Document28 pagesCompiler 6Tayyab FiazNo ratings yet
- Intermediate Code Generation-17-19Document90 pagesIntermediate Code Generation-17-19AtharvA PagarNo ratings yet
- Cat 1Document150 pagesCat 1Meet mNo ratings yet
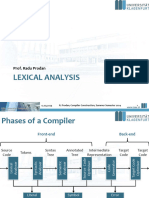
- Phases of A CompilerDocument17 pagesPhases of A CompilerSam AlexNo ratings yet
- Compiler Construction: Tahir IqbalDocument28 pagesCompiler Construction: Tahir IqbalMUHAMMAD RASHIDNo ratings yet
- Lecture 2.1 - Lexical AnalysisDocument24 pagesLecture 2.1 - Lexical AnalysisDivyanshu JainNo ratings yet
- 03 Lex AnalysisDocument61 pages03 Lex Analysisaastha mallaNo ratings yet
- Sytax Directed Translations L14 15Document28 pagesSytax Directed Translations L14 15Vibhum Raj TripathiNo ratings yet
- Chapter 4Document31 pagesChapter 4Arif AbdulelamNo ratings yet
- Compiler ConstructionDocument17 pagesCompiler Constructioncosc100 KFUEITNo ratings yet
- Class 12 Exam Revision MaterialDocument101 pagesClass 12 Exam Revision MaterialhevNo ratings yet
- Lexical Analyzer: Using Flex by Dr. S. M. FarhadDocument22 pagesLexical Analyzer: Using Flex by Dr. S. M. FarhadHM Mahmudul Hasan HridoyNo ratings yet
- Unit 3Document11 pagesUnit 3Ayush SinghNo ratings yet
- Class 12 Exam Revision MaterialDocument101 pagesClass 12 Exam Revision Materialayush pandeyNo ratings yet
- Compilers Thamar Universtiy Lec1 PDFDocument21 pagesCompilers Thamar Universtiy Lec1 PDFhashem AL-shrfiNo ratings yet
- CH1 3Document32 pagesCH1 3sam negroNo ratings yet
- 15Cs314J - Compiler Design: Unit IiiDocument69 pages15Cs314J - Compiler Design: Unit IiiKANCHAN -No ratings yet
- Class 12 Exam Revision MaterialDocument178 pagesClass 12 Exam Revision Materialtpmsomrolc.anirudha9bNo ratings yet
- Getting Started With C++ - 104832Document9 pagesGetting Started With C++ - 104832gogoiabinash300No ratings yet
- Compiler RewindDocument52 pagesCompiler RewindneelamysrNo ratings yet
- CH04Document24 pagesCH04zemikeNo ratings yet
- 11 SemanticDocument22 pages11 SemanticAbdul Jami RuhaniNo ratings yet
- UNIT 4 - Intermediate - Code - Generation NEWDocument205 pagesUNIT 4 - Intermediate - Code - Generation NEWNANDIKHA THARANIKUMARNo ratings yet
- Lectures 6-9Document59 pagesLectures 6-9None NoneNo ratings yet
- Ch3 - Lexical AnalysisDocument52 pagesCh3 - Lexical Analysisnickdamor1123No ratings yet
- (Week 3) Lecture 5 & 6: Dr. Naseer Ahmed Sajid Email Id: Whatsapp# 0346-5100010Document8 pages(Week 3) Lecture 5 & 6: Dr. Naseer Ahmed Sajid Email Id: Whatsapp# 0346-5100010Muqaddas ZulfiqarNo ratings yet
- Unit 4Document205 pagesUnit 4portgasdjewelNo ratings yet
- CD AssignmentDocument16 pagesCD Assignmentadithyavinod.mecNo ratings yet
- 01 Python BasicsDocument33 pages01 Python BasicsVAIBHAV VASANINo ratings yet
- 2 - ScannerDocument49 pages2 - ScannerAya SaafanNo ratings yet
- Chapter Two LexicalAnalysisDocument16 pagesChapter Two LexicalAnalysisAsfaw BassaNo ratings yet
- Lecture#2 Chap#1 (Compiler Introduction)Document16 pagesLecture#2 Chap#1 (Compiler Introduction)ab2478037No ratings yet
- ATCD Mod 3Document46 pagesATCD Mod 3Prsgnyaban MishraNo ratings yet
- CD KCS502 Unit 1 BDocument12 pagesCD KCS502 Unit 1 Bshivendrasingh43613No ratings yet
- Ognsemantic AnalysisDocument68 pagesOgnsemantic AnalysisHarshit MauryaNo ratings yet
- Mod 1Document24 pagesMod 1Subhashree PradhanNo ratings yet
- Lec3-CompilerConstruction 2Document26 pagesLec3-CompilerConstruction 2Aqsa WarisNo ratings yet
- Compiler ConstructerDocument17 pagesCompiler ConstructerAmjad AliNo ratings yet
- Eex 6335 Tma 1Document12 pagesEex 6335 Tma 1vishwa0% (1)
- CD Full MaterialDocument74 pagesCD Full MaterialAbhishek DirisipoNo ratings yet
- Lec02 Programming Language SpecificationDocument36 pagesLec02 Programming Language SpecificationASTROHALT C4No ratings yet
- Chapter-03: What Is Lexical Analysis?Document6 pagesChapter-03: What Is Lexical Analysis?abu syedNo ratings yet
- Chapter 2 - Lexical AnalysisDocument74 pagesChapter 2 - Lexical Analysissamlegend2217No ratings yet
- BKS Unit II-Syntax Directed Definitions NewDocument35 pagesBKS Unit II-Syntax Directed Definitions NewShivam ChauhanNo ratings yet
- 3a. Context Free GrammarDocument18 pages3a. Context Free GrammarRhymeNo ratings yet
- Compiler Construction: Chapter 1: Introduction To CompilationDocument65 pagesCompiler Construction: Chapter 1: Introduction To CompilationazimkhanNo ratings yet
- SE Compiler Chapter 4-SDTDocument7 pagesSE Compiler Chapter 4-SDTmikiberhanu41No ratings yet
- CP II Unit IIIDocument30 pagesCP II Unit IIIvirat gautamNo ratings yet
- Compiler Design and Construction NoteDocument97 pagesCompiler Design and Construction NoteSam MasNo ratings yet
- Module-4 SyntaxDocument24 pagesModule-4 SyntaxBALA BALANo ratings yet
- Coding for beginners The basic syntax and structure of codingFrom EverandCoding for beginners The basic syntax and structure of codingNo ratings yet
- Lecture 10Document24 pagesLecture 10Kusumanchi AshishNo ratings yet
- Tut 5 QuestionsDocument1 pageTut 5 QuestionsKusumanchi AshishNo ratings yet
- Lecture 4-5Document42 pagesLecture 4-5Kusumanchi AshishNo ratings yet
- POSTMIDSDeadlocks 7Document26 pagesPOSTMIDSDeadlocks 7Kusumanchi AshishNo ratings yet
- CH 04Document14 pagesCH 04Kusumanchi AshishNo ratings yet
- CH 07Document8 pagesCH 07Kusumanchi AshishNo ratings yet
- CH 02Document12 pagesCH 02Kusumanchi AshishNo ratings yet
- CH 06Document23 pagesCH 06Kusumanchi AshishNo ratings yet
- MP4 User Manual PDFDocument32 pagesMP4 User Manual PDFKusumanchi AshishNo ratings yet
- Data Compression (Rcs087) Assignment Unit-5Document6 pagesData Compression (Rcs087) Assignment Unit-5Death gamingNo ratings yet
- SRM Valliammai Engineering College (An Autonomous Institution)Document9 pagesSRM Valliammai Engineering College (An Autonomous Institution)sureshNo ratings yet
- Pushdown Automata (PDA) : Reading: Chapter 6Document34 pagesPushdown Automata (PDA) : Reading: Chapter 6Mehedi Hasan EmonNo ratings yet
- Cs3491 - Aiml - Unit III - Linear Regression ModelsDocument34 pagesCs3491 - Aiml - Unit III - Linear Regression ModelsSobanNo ratings yet
- Lecture 04 (3hrs) Neural Network and Deep Learning-Part ADocument76 pagesLecture 04 (3hrs) Neural Network and Deep Learning-Part AEngr. Md. Borhan UddinNo ratings yet
- Unit-3 TOCDocument42 pagesUnit-3 TOCsageranimesh20No ratings yet
- Solutions To Algorithms PS 4Document20 pagesSolutions To Algorithms PS 4Juan DuchimazaNo ratings yet
- String Matching AlgorithmsDocument46 pagesString Matching AlgorithmsTauseef NawazNo ratings yet
- Performance Task E-PortfolioDocument2 pagesPerformance Task E-Portfolioapi-482110307No ratings yet
- BSC C.S (H) 6th Semester SyllabusDocument6 pagesBSC C.S (H) 6th Semester Syllabusnyksolution rimitNo ratings yet
- Deep Copy and ShallowDocument6 pagesDeep Copy and ShallowAbhishek SrivastavaNo ratings yet
- Mad101 Chap 10Document147 pagesMad101 Chap 10Anagram SwipeNo ratings yet
- GEC 104 ReportDocument66 pagesGEC 104 ReportTALAN, KURT FLORENCE L.No ratings yet
- Convolutional Code (II)Document115 pagesConvolutional Code (II)Atef Al-Kotafi Al-AbdiNo ratings yet
- Shivansh Bhat - 19116071: Experiment-2Document20 pagesShivansh Bhat - 19116071: Experiment-2Parth SinghNo ratings yet
- AbstractDocument4 pagesAbstractdjankopanniNo ratings yet
- خوارزمية جدولة مقترحة للمعالجات المتعددةDocument12 pagesخوارزمية جدولة مقترحة للمعالجات المتعددةgestion opeNo ratings yet
- Hassan Synpsis SlidesDocument14 pagesHassan Synpsis SlidesOmar DaudaNo ratings yet
- Graph Homomorphisms: Open Problems: L Aszl o Lov Asz June 2008Document10 pagesGraph Homomorphisms: Open Problems: L Aszl o Lov Asz June 2008vanaj123No ratings yet
- Linear Programming (LP) : Georgia Institute of Technology Systems Realization Laboratory 1Document25 pagesLinear Programming (LP) : Georgia Institute of Technology Systems Realization Laboratory 1Radu HăbăşescuNo ratings yet
- MAD Blooms Taxonomy Question Paper FormatDocument3 pagesMAD Blooms Taxonomy Question Paper FormatnarikitsNo ratings yet
- DSA Labmanual PDFDocument72 pagesDSA Labmanual PDFANIMESH ANANDNo ratings yet
- Brandes 2008Document17 pagesBrandes 2008DeepakNo ratings yet
- Asymptotic NotationDocument20 pagesAsymptotic NotationAbhishek ChauhanNo ratings yet
- Week 01 - 1 - Propositoinal LogicDocument23 pagesWeek 01 - 1 - Propositoinal LogicabeNo ratings yet
- CD Unit-3 Part-2Document21 pagesCD Unit-3 Part-2dartionjpNo ratings yet
- QueuesDocument21 pagesQueuesSameh UlhaqNo ratings yet
- Trabajo 1Document8 pagesTrabajo 1jhonNo ratings yet
- ENGIN 112 Intro To Electrical and Computer Engineering: Circuit Analysis ProcedureDocument13 pagesENGIN 112 Intro To Electrical and Computer Engineering: Circuit Analysis ProcedureIsrar UllahNo ratings yet

































































































Download as pdf or txt
You might also like
- CS3304 9 LanguageSyntax 2 PDFDocument39 pagesCS3304 9 LanguageSyntax 2 PDFrubaNo ratings yet
- Error Control Systems For Digital Communication and Storage (Stephen B. Wicker)Document268 pagesError Control Systems For Digital Communication and Storage (Stephen B. Wicker)sirapu100% (3)
- 3 parser-Intro-L5Document21 pages3 parser-Intro-L5PRANJAL SHARMANo ratings yet
- BITS PilaniDocument21 pagesBITS Pilaniwwpretty faceNo ratings yet
- Lecture#9 - Chap#3 (Lexical Analysis (Part-I) )Document25 pagesLecture#9 - Chap#3 (Lexical Analysis (Part-I) )jmi40724No ratings yet
- ch-2.pdf 2Document27 pagesch-2.pdf 2Salih AkadarNo ratings yet
- Semantic AnalysisDocument74 pagesSemantic Analysissiddharth sasmalNo ratings yet
- Principles of Programming Language: BITS PilaniDocument51 pagesPrinciples of Programming Language: BITS PilaniRutviNo ratings yet
- Week 2 Lec 4 CCDocument28 pagesWeek 2 Lec 4 CCSohaib KashmiriNo ratings yet
- Compiler 6Document28 pagesCompiler 6Tayyab FiazNo ratings yet
- Intermediate Code Generation-17-19Document90 pagesIntermediate Code Generation-17-19AtharvA PagarNo ratings yet
- Cat 1Document150 pagesCat 1Meet mNo ratings yet
- Phases of A CompilerDocument17 pagesPhases of A CompilerSam AlexNo ratings yet
- Compiler Construction: Tahir IqbalDocument28 pagesCompiler Construction: Tahir IqbalMUHAMMAD RASHIDNo ratings yet
- Lecture 2.1 - Lexical AnalysisDocument24 pagesLecture 2.1 - Lexical AnalysisDivyanshu JainNo ratings yet
- 03 Lex AnalysisDocument61 pages03 Lex Analysisaastha mallaNo ratings yet
- Sytax Directed Translations L14 15Document28 pagesSytax Directed Translations L14 15Vibhum Raj TripathiNo ratings yet
- Chapter 4Document31 pagesChapter 4Arif AbdulelamNo ratings yet
- Compiler ConstructionDocument17 pagesCompiler Constructioncosc100 KFUEITNo ratings yet
- Class 12 Exam Revision MaterialDocument101 pagesClass 12 Exam Revision MaterialhevNo ratings yet
- Lexical Analyzer: Using Flex by Dr. S. M. FarhadDocument22 pagesLexical Analyzer: Using Flex by Dr. S. M. FarhadHM Mahmudul Hasan HridoyNo ratings yet
- Unit 3Document11 pagesUnit 3Ayush SinghNo ratings yet
- Class 12 Exam Revision MaterialDocument101 pagesClass 12 Exam Revision Materialayush pandeyNo ratings yet
- Compilers Thamar Universtiy Lec1 PDFDocument21 pagesCompilers Thamar Universtiy Lec1 PDFhashem AL-shrfiNo ratings yet
- CH1 3Document32 pagesCH1 3sam negroNo ratings yet
- 15Cs314J - Compiler Design: Unit IiiDocument69 pages15Cs314J - Compiler Design: Unit IiiKANCHAN -No ratings yet
- Class 12 Exam Revision MaterialDocument178 pagesClass 12 Exam Revision Materialtpmsomrolc.anirudha9bNo ratings yet
- Getting Started With C++ - 104832Document9 pagesGetting Started With C++ - 104832gogoiabinash300No ratings yet
- Compiler RewindDocument52 pagesCompiler RewindneelamysrNo ratings yet
- CH04Document24 pagesCH04zemikeNo ratings yet
- 11 SemanticDocument22 pages11 SemanticAbdul Jami RuhaniNo ratings yet
- UNIT 4 - Intermediate - Code - Generation NEWDocument205 pagesUNIT 4 - Intermediate - Code - Generation NEWNANDIKHA THARANIKUMARNo ratings yet
- Lectures 6-9Document59 pagesLectures 6-9None NoneNo ratings yet
- Ch3 - Lexical AnalysisDocument52 pagesCh3 - Lexical Analysisnickdamor1123No ratings yet
- (Week 3) Lecture 5 & 6: Dr. Naseer Ahmed Sajid Email Id: Whatsapp# 0346-5100010Document8 pages(Week 3) Lecture 5 & 6: Dr. Naseer Ahmed Sajid Email Id: Whatsapp# 0346-5100010Muqaddas ZulfiqarNo ratings yet
- Unit 4Document205 pagesUnit 4portgasdjewelNo ratings yet
- CD AssignmentDocument16 pagesCD Assignmentadithyavinod.mecNo ratings yet
- 01 Python BasicsDocument33 pages01 Python BasicsVAIBHAV VASANINo ratings yet
- 2 - ScannerDocument49 pages2 - ScannerAya SaafanNo ratings yet
- Chapter Two LexicalAnalysisDocument16 pagesChapter Two LexicalAnalysisAsfaw BassaNo ratings yet
- Lecture#2 Chap#1 (Compiler Introduction)Document16 pagesLecture#2 Chap#1 (Compiler Introduction)ab2478037No ratings yet
- ATCD Mod 3Document46 pagesATCD Mod 3Prsgnyaban MishraNo ratings yet
- CD KCS502 Unit 1 BDocument12 pagesCD KCS502 Unit 1 Bshivendrasingh43613No ratings yet
- Ognsemantic AnalysisDocument68 pagesOgnsemantic AnalysisHarshit MauryaNo ratings yet
- Mod 1Document24 pagesMod 1Subhashree PradhanNo ratings yet
- Lec3-CompilerConstruction 2Document26 pagesLec3-CompilerConstruction 2Aqsa WarisNo ratings yet
- Compiler ConstructerDocument17 pagesCompiler ConstructerAmjad AliNo ratings yet
- Eex 6335 Tma 1Document12 pagesEex 6335 Tma 1vishwa0% (1)
- CD Full MaterialDocument74 pagesCD Full MaterialAbhishek DirisipoNo ratings yet
- Lec02 Programming Language SpecificationDocument36 pagesLec02 Programming Language SpecificationASTROHALT C4No ratings yet
- Chapter-03: What Is Lexical Analysis?Document6 pagesChapter-03: What Is Lexical Analysis?abu syedNo ratings yet
- Chapter 2 - Lexical AnalysisDocument74 pagesChapter 2 - Lexical Analysissamlegend2217No ratings yet
- BKS Unit II-Syntax Directed Definitions NewDocument35 pagesBKS Unit II-Syntax Directed Definitions NewShivam ChauhanNo ratings yet
- 3a. Context Free GrammarDocument18 pages3a. Context Free GrammarRhymeNo ratings yet
- Compiler Construction: Chapter 1: Introduction To CompilationDocument65 pagesCompiler Construction: Chapter 1: Introduction To CompilationazimkhanNo ratings yet
- SE Compiler Chapter 4-SDTDocument7 pagesSE Compiler Chapter 4-SDTmikiberhanu41No ratings yet
- CP II Unit IIIDocument30 pagesCP II Unit IIIvirat gautamNo ratings yet
- Compiler Design and Construction NoteDocument97 pagesCompiler Design and Construction NoteSam MasNo ratings yet
- Module-4 SyntaxDocument24 pagesModule-4 SyntaxBALA BALANo ratings yet
- Coding for beginners The basic syntax and structure of codingFrom EverandCoding for beginners The basic syntax and structure of codingNo ratings yet
- Lecture 10Document24 pagesLecture 10Kusumanchi AshishNo ratings yet
- Tut 5 QuestionsDocument1 pageTut 5 QuestionsKusumanchi AshishNo ratings yet
- Lecture 4-5Document42 pagesLecture 4-5Kusumanchi AshishNo ratings yet
- POSTMIDSDeadlocks 7Document26 pagesPOSTMIDSDeadlocks 7Kusumanchi AshishNo ratings yet
- CH 04Document14 pagesCH 04Kusumanchi AshishNo ratings yet
- CH 07Document8 pagesCH 07Kusumanchi AshishNo ratings yet
- CH 02Document12 pagesCH 02Kusumanchi AshishNo ratings yet
- CH 06Document23 pagesCH 06Kusumanchi AshishNo ratings yet
- MP4 User Manual PDFDocument32 pagesMP4 User Manual PDFKusumanchi AshishNo ratings yet
- Data Compression (Rcs087) Assignment Unit-5Document6 pagesData Compression (Rcs087) Assignment Unit-5Death gamingNo ratings yet
- SRM Valliammai Engineering College (An Autonomous Institution)Document9 pagesSRM Valliammai Engineering College (An Autonomous Institution)sureshNo ratings yet
- Pushdown Automata (PDA) : Reading: Chapter 6Document34 pagesPushdown Automata (PDA) : Reading: Chapter 6Mehedi Hasan EmonNo ratings yet
- Cs3491 - Aiml - Unit III - Linear Regression ModelsDocument34 pagesCs3491 - Aiml - Unit III - Linear Regression ModelsSobanNo ratings yet
- Lecture 04 (3hrs) Neural Network and Deep Learning-Part ADocument76 pagesLecture 04 (3hrs) Neural Network and Deep Learning-Part AEngr. Md. Borhan UddinNo ratings yet
- Unit-3 TOCDocument42 pagesUnit-3 TOCsageranimesh20No ratings yet
- Solutions To Algorithms PS 4Document20 pagesSolutions To Algorithms PS 4Juan DuchimazaNo ratings yet
- String Matching AlgorithmsDocument46 pagesString Matching AlgorithmsTauseef NawazNo ratings yet
- Performance Task E-PortfolioDocument2 pagesPerformance Task E-Portfolioapi-482110307No ratings yet
- BSC C.S (H) 6th Semester SyllabusDocument6 pagesBSC C.S (H) 6th Semester Syllabusnyksolution rimitNo ratings yet
- Deep Copy and ShallowDocument6 pagesDeep Copy and ShallowAbhishek SrivastavaNo ratings yet
- Mad101 Chap 10Document147 pagesMad101 Chap 10Anagram SwipeNo ratings yet
- GEC 104 ReportDocument66 pagesGEC 104 ReportTALAN, KURT FLORENCE L.No ratings yet
- Convolutional Code (II)Document115 pagesConvolutional Code (II)Atef Al-Kotafi Al-AbdiNo ratings yet
- Shivansh Bhat - 19116071: Experiment-2Document20 pagesShivansh Bhat - 19116071: Experiment-2Parth SinghNo ratings yet
- AbstractDocument4 pagesAbstractdjankopanniNo ratings yet
- خوارزمية جدولة مقترحة للمعالجات المتعددةDocument12 pagesخوارزمية جدولة مقترحة للمعالجات المتعددةgestion opeNo ratings yet
- Hassan Synpsis SlidesDocument14 pagesHassan Synpsis SlidesOmar DaudaNo ratings yet
- Graph Homomorphisms: Open Problems: L Aszl o Lov Asz June 2008Document10 pagesGraph Homomorphisms: Open Problems: L Aszl o Lov Asz June 2008vanaj123No ratings yet
- Linear Programming (LP) : Georgia Institute of Technology Systems Realization Laboratory 1Document25 pagesLinear Programming (LP) : Georgia Institute of Technology Systems Realization Laboratory 1Radu HăbăşescuNo ratings yet
- MAD Blooms Taxonomy Question Paper FormatDocument3 pagesMAD Blooms Taxonomy Question Paper FormatnarikitsNo ratings yet
- DSA Labmanual PDFDocument72 pagesDSA Labmanual PDFANIMESH ANANDNo ratings yet
- Brandes 2008Document17 pagesBrandes 2008DeepakNo ratings yet
- Asymptotic NotationDocument20 pagesAsymptotic NotationAbhishek ChauhanNo ratings yet
- Week 01 - 1 - Propositoinal LogicDocument23 pagesWeek 01 - 1 - Propositoinal LogicabeNo ratings yet
- CD Unit-3 Part-2Document21 pagesCD Unit-3 Part-2dartionjpNo ratings yet
- QueuesDocument21 pagesQueuesSameh UlhaqNo ratings yet
- Trabajo 1Document8 pagesTrabajo 1jhonNo ratings yet
- ENGIN 112 Intro To Electrical and Computer Engineering: Circuit Analysis ProcedureDocument13 pagesENGIN 112 Intro To Electrical and Computer Engineering: Circuit Analysis ProcedureIsrar UllahNo ratings yet